 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Content Understanding With Effective Use of Multi-task Contrastive Learning
May 21, 2024



In enhancing LinkedIn core content recommendation models, a significant challenge lies in improving their semantic understanding capabilities. This paper addresses the problem by leveraging multi-task learning, a method that has shown promise in various domains. We fine-tune a pre-trained, transformer-based LLM using multi-task contrastive learning with data from a diverse set of semantic labeling tasks. We observe positive transfer, leading to superior performance across all tasks when compared to training independently on each. Our model outperforms the baseline on zero shot learning and offers improved multilingual support, highlighting its potential for broader application. The specialized content embeddings produced by our model outperform generalized embeddings offered by OpenAI on Linkedin dataset and tasks. This work provides a robust foundation for vertical teams across LinkedIn to customize and fine-tune the LLM to their specific applications. Our work offers insights and best practices for the field to build on.
Streaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
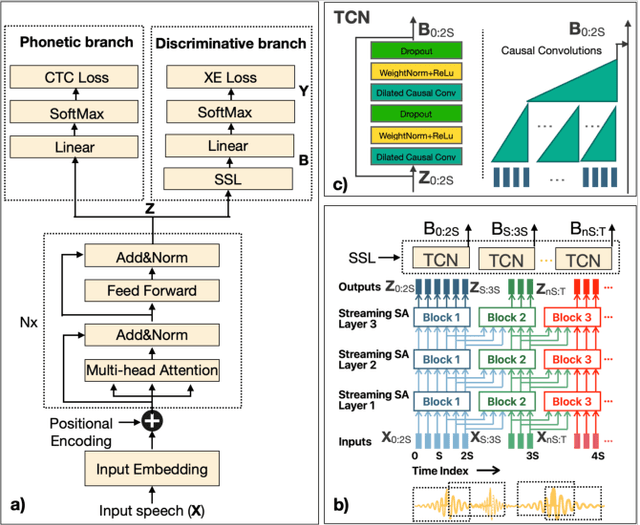
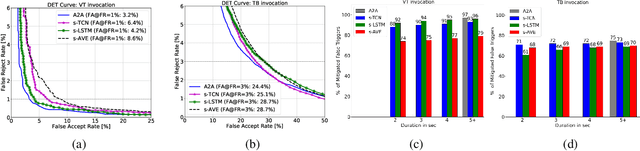
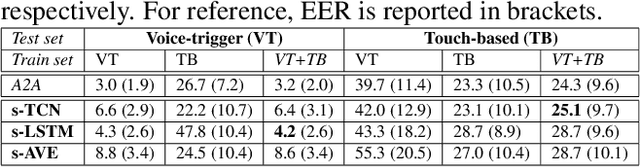
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Generating Natural Questions from Images for Multimodal Assistants
Nov 17, 2020
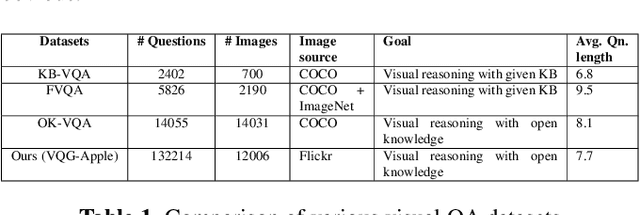

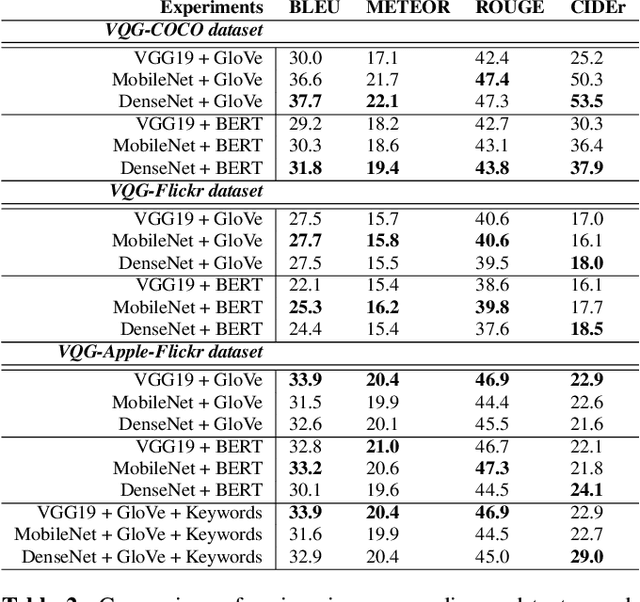
Generating natural, diverse, and meaningful questions from images is an essential task for multimodal assistants as it confirms whether they have understood the object and scene in the images properly. The research in visual question answering (VQA) and visual question generation (VQG) is a great step. However, this research does not capture questions that a visually-abled person would ask multimodal assistants. Recently published datasets such as KB-VQA, FVQA, and OK-VQA try to collect questions that look for external knowledge which makes them appropriate for multimodal assistants. However, they still contain many obvious and common-sense questions that humans would not usually ask a digital assistant. In this paper, we provide a new benchmark dataset that contains questions generated by human annotators keeping in mind what they would ask multimodal digital assistants. Large scale annotations for several hundred thousand images are expensive and time-consuming, so we also present an effective way of automatically generating questions from unseen images. In this paper, we present an approach for generating diverse and meaningful questions that consider image content and metadata of image (e.g., location, associated keyword). We evaluate our approach using standard evaluation metrics such as BLEU, METEOR, ROUGE, and CIDEr to show the relevance of generated questions with human-provided questions. We also measure the diversity of generated questions using generative strength and inventiveness metrics. We report new state-of-the-art results on the public and our datasets.