 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Zero-Shot Cross-lingual Aphasia Detection using Automatic Speech Recognition
Apr 01, 2022
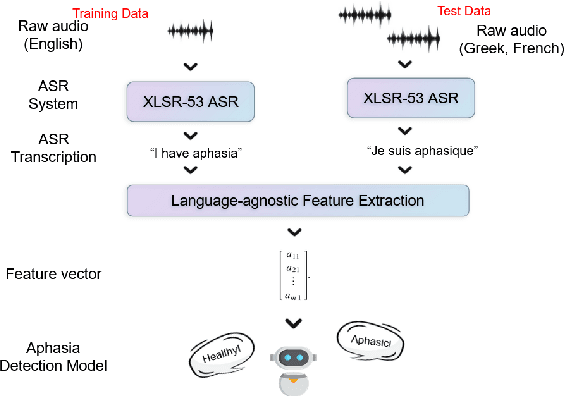
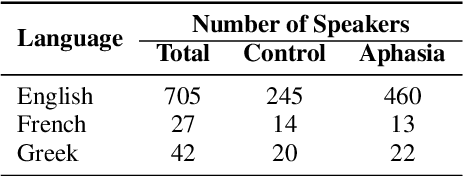
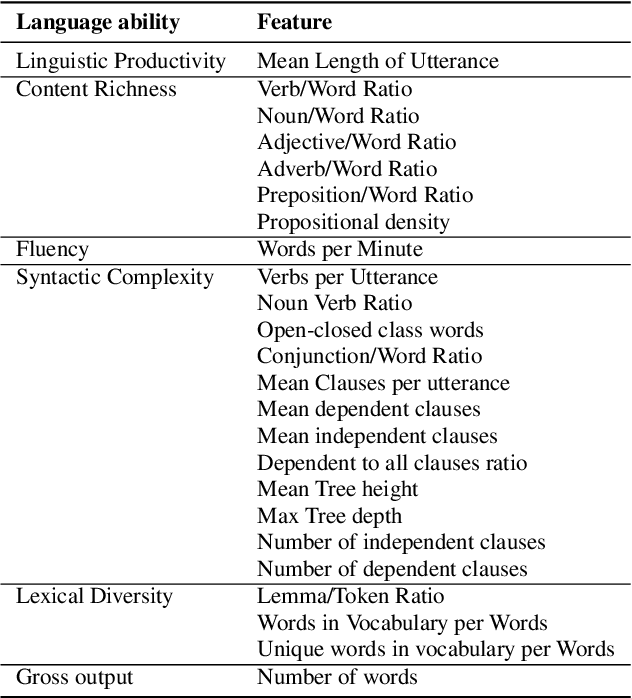
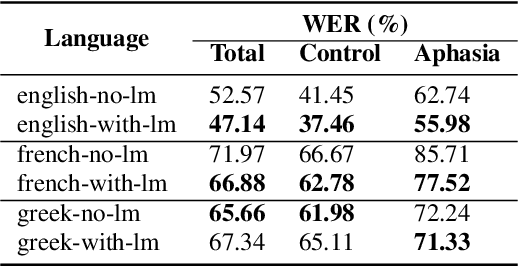
Aphasia is a common speech and language disorder, typically caused by a brain injury or a stroke, that affects millions of people worldwide. Detecting and assessing Aphasia in patients is a difficult, time-consuming process, and numerous attempts to automate it have been made, the most successful using machine learning models trained on aphasic speech data. Like in many medical applications, aphasic speech data is scarce and the problem is exacerbated in so-called "low resource" languages, which are, for this task, most languages excluding English. We attempt to leverage available data in English and achieve zero-shot aphasia detection in low-resource languages such as Greek and French, by using language-agnostic linguistic features. Current cross-lingual aphasia detection approaches rely on manually extracted transcripts. We propose an end-to-end pipeline using pre-trained Automatic Speech Recognition (ASR) models that share cross-lingual speech representations and are fine-tuned for our desired low-resource languages. To further boost our ASR model's performance, we also combine it with a language model. We show that our ASR-based end-to-end pipeline offers comparable results to previous setups using human-annotated transcripts.
ECAPA-TDNN for Multi-speaker Text-to-speech Synthesis
Mar 26, 2022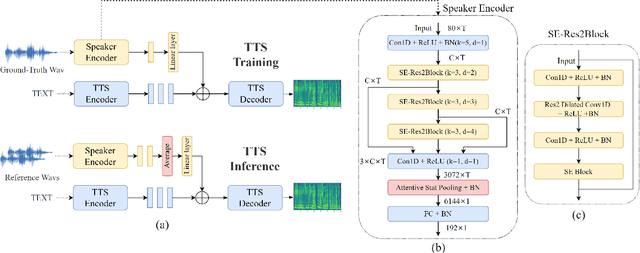
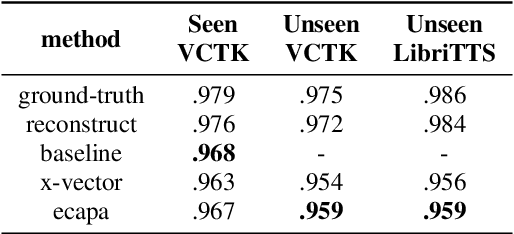
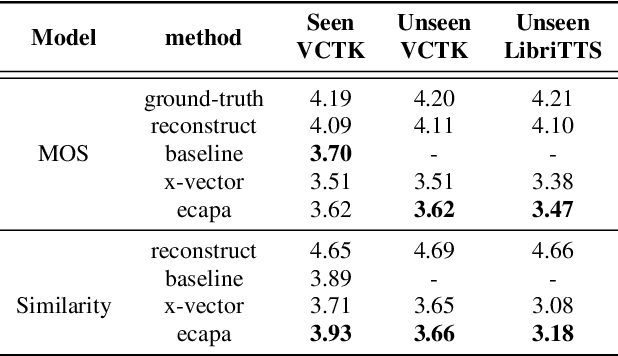
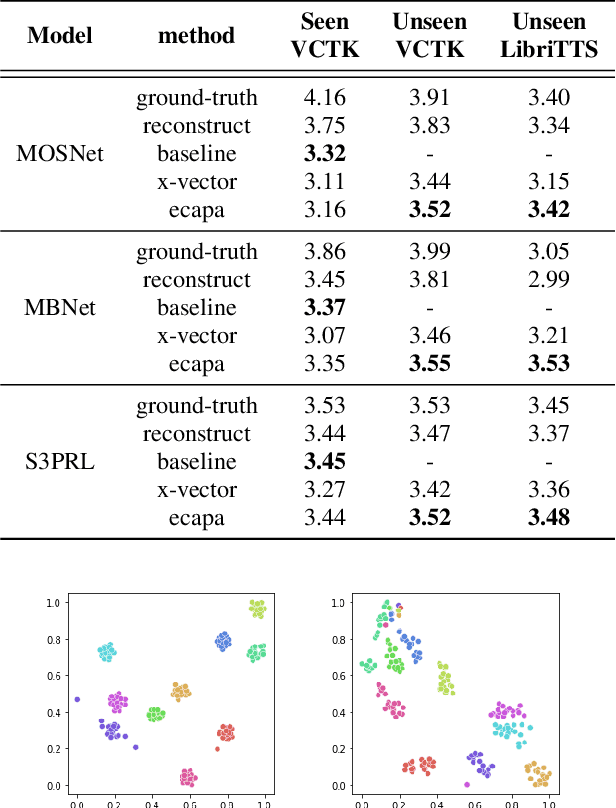
In recent years, neural network based methods for multi-speaker text-to-speech synthesis (TTS) have made significant progress. However, the current speaker encoder models used in these methods still cannot capture enough speaker information. In this paper, we focus on accurate speaker encoder modeling and propose an end-to-end method that can generate high-quality speech and better similarity for both seen and unseen speakers. The proposed architecture consists of three separately trained components: a speaker encoder based on the state-of-the-art ECAPA-TDNN model which is derived from speaker verification task, a FastSpeech2 based synthesizer, and a HiFi-GAN vocoder. The comparison among different speaker encoder models shows our proposed method can achieve better naturalness and similarity. To efficiently evaluate our synthesized speech, we are the first to adopt deep learning based automatic MOS evaluation methods to assess our results, and these methods show great potential in automatic speech quality assessment.
DiffPhase: Generative Diffusion-based STFT Phase Retrieval
Nov 08, 2022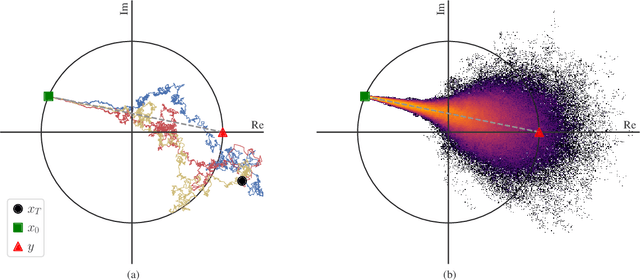

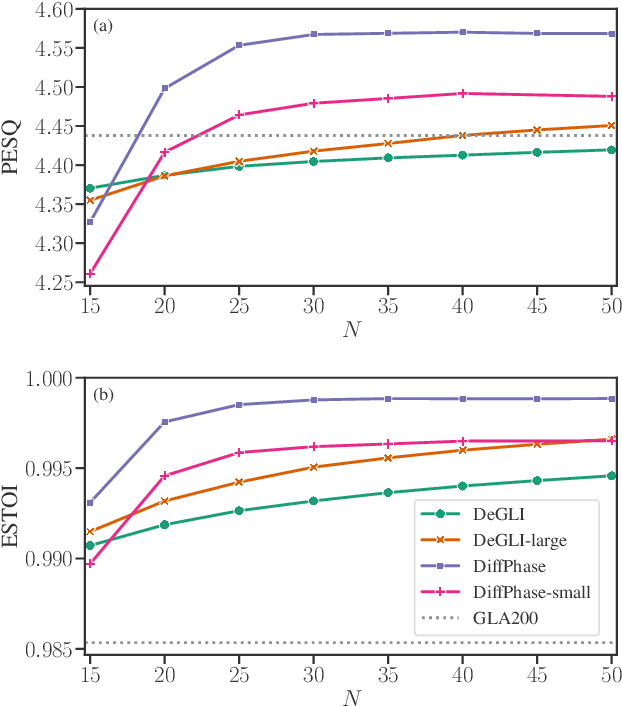
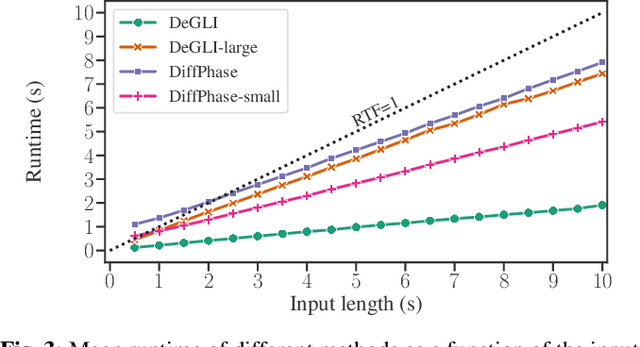
Diffusion probabilistic models have been recently used in a variety of tasks, including speech enhancement and synthesis. As a generative approach, diffusion models have been shown to be especially suitable for imputation problems, where missing data is generated based on existing data. Phase retrieval is inherently an imputation problem, where phase information has to be generated based on the given magnitude. In this work we build upon previous work in the speech domain, adapting a speech enhancement diffusion model specifically for STFT phase retrieval. Evaluation using speech quality and intelligibility metrics shows the diffusion approach is well-suited to the phase retrieval task, with performance surpassing both classical and modern methods.
Massively Multilingual Shallow Fusion with Large Language Models
Feb 17, 2023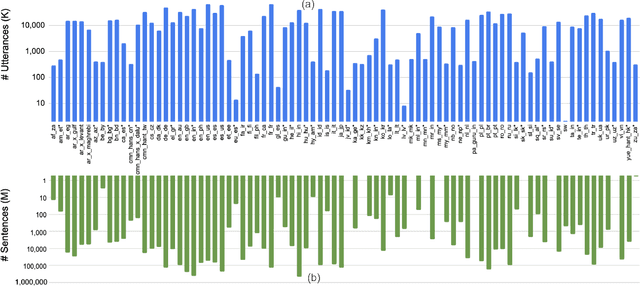
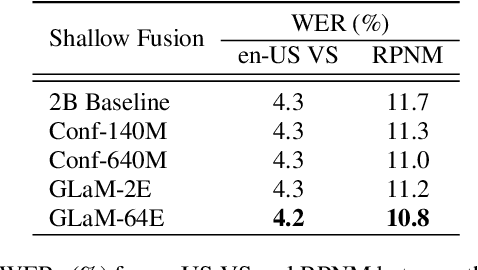
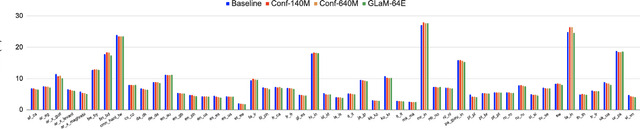

While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.
Information-Restricted Neural Language Models Reveal Different Brain Regions' Sensitivity to Semantics, Syntax and Context
Feb 28, 2023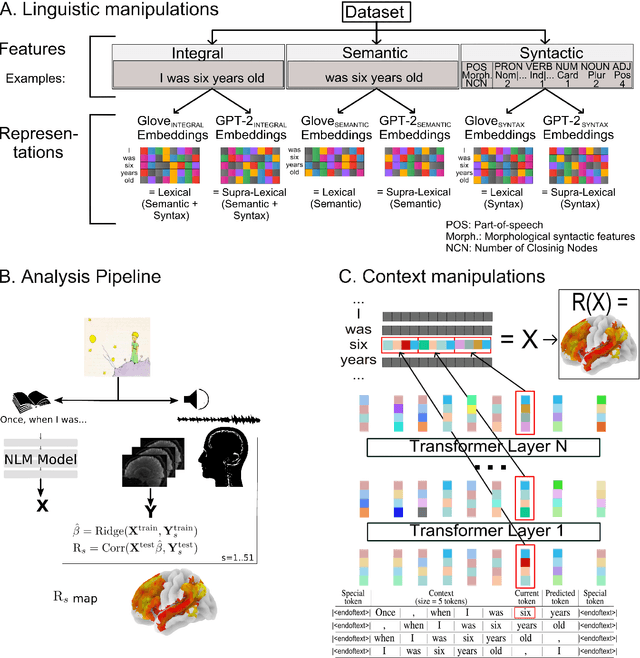
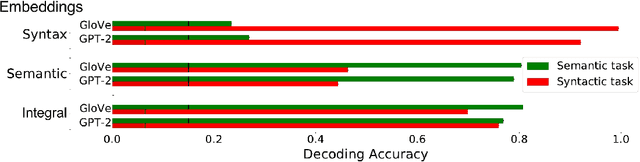
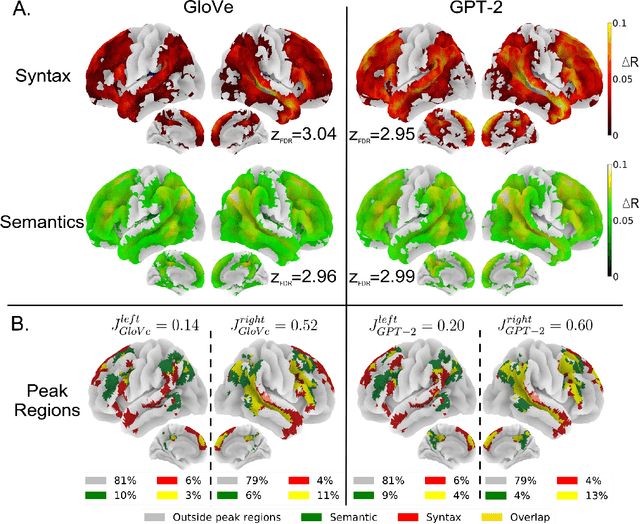
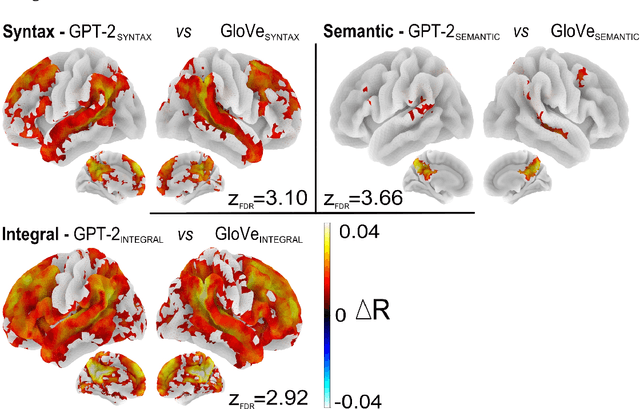
A fundamental question in neurolinguistics concerns the brain regions involved in syntactic and semantic processing during speech comprehension, both at the lexical (word processing) and supra-lexical levels (sentence and discourse processing). To what extent are these regions separated or intertwined? To address this question, we trained a lexical language model, Glove, and a supra-lexical language model, GPT-2, on a text corpus from which we selectively removed either syntactic or semantic information. We then assessed to what extent these information-restricted models were able to predict the time-courses of fMRI signal of humans listening to naturalistic text. We also manipulated the size of contextual information provided to GPT-2 in order to determine the windows of integration of brain regions involved in supra-lexical processing. Our analyses show that, while most brain regions involved in language are sensitive to both syntactic and semantic variables, the relative magnitudes of these effects vary a lot across these regions. Furthermore, we found an asymmetry between the left and right hemispheres, with semantic and syntactic processing being more dissociated in the left hemisphere than in the right, and the left and right hemispheres showing respectively greater sensitivity to short and long contexts. The use of information-restricted NLP models thus shed new light on the spatial organization of syntactic processing, semantic processing and compositionality.
What can Speech and Language Tell us About the Working Alliance in Psychotherapy
Jun 17, 2022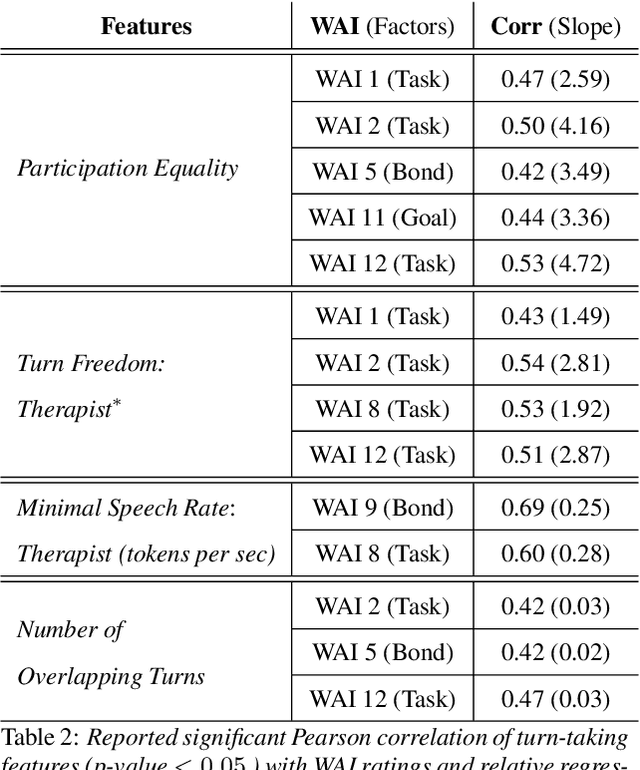
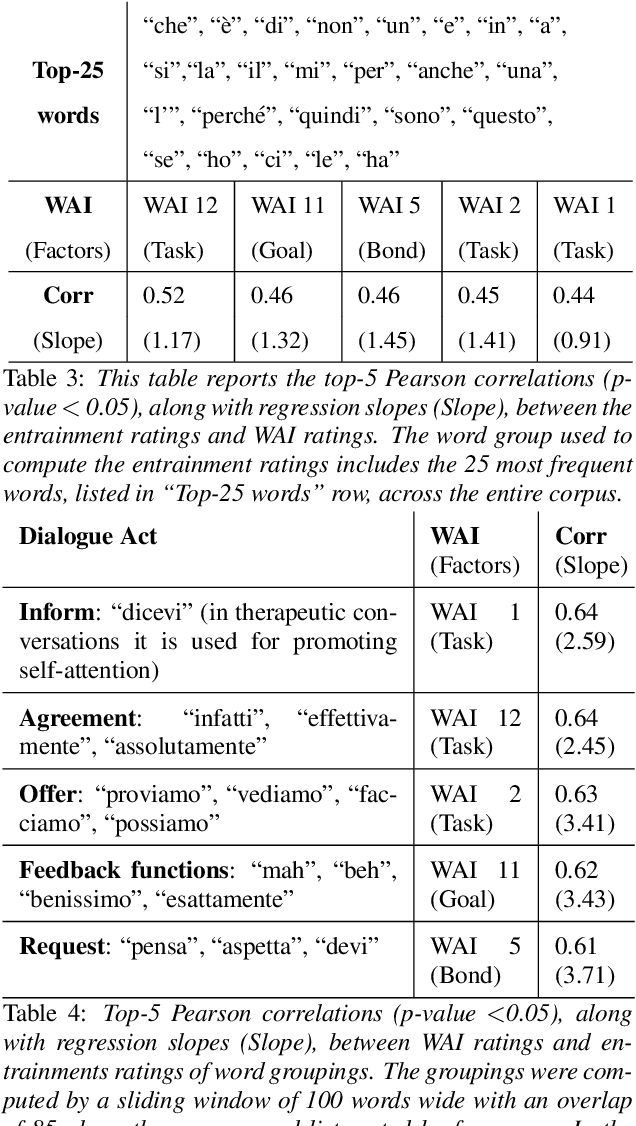
We are interested in the problem of conversational analysis and its application to the health domain. Cognitive Behavioral Therapy is a structured approach in psychotherapy, allowing the therapist to help the patient to identify and modify the malicious thoughts, behavior, or actions. This cooperative effort can be evaluated using the Working Alliance Inventory Observer-rated Shortened - a 12 items inventory covering task, goal, and relationship - which has a relevant influence on therapeutic outcomes. In this work, we investigate the relation between this alliance inventory and the spoken conversations (sessions) between the patient and the psychotherapist. We have delivered eight weeks of e-therapy, collected their audio and video call sessions, and manually transcribed them. The spoken conversations have been annotated and evaluated with WAI ratings by professional therapists. We have investigated speech and language features and their association with WAI items. The feature types include turn dynamics, lexical entrainment, and conversational descriptors extracted from the speech and language signals. Our findings provide strong evidence that a subset of these features are strong indicators of working alliance. To the best of our knowledge, this is the first and a novel study to exploit speech and language for characterising working alliance.
Proactively Reducing the Hate Intensity of Online Posts via Hate Speech Normalization
Jun 08, 2022
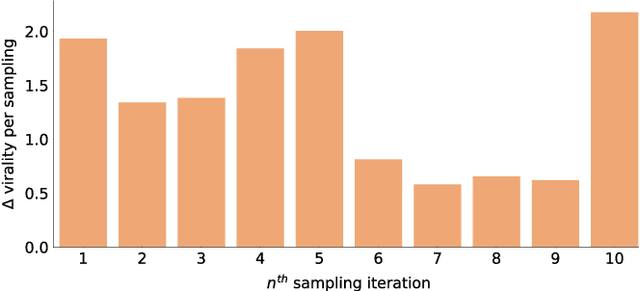
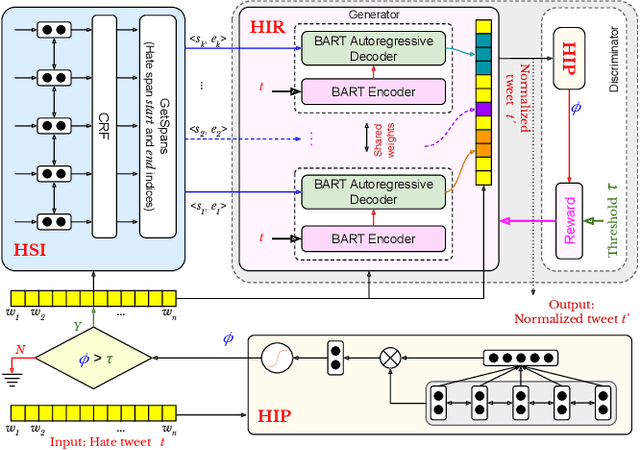
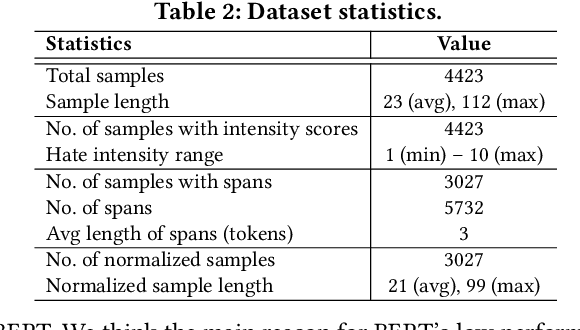
Curbing online hate speech has become the need of the hour; however, a blanket ban on such activities is infeasible for several geopolitical and cultural reasons. To reduce the severity of the problem, in this paper, we introduce a novel task, hate speech normalization, that aims to weaken the intensity of hatred exhibited by an online post. The intention of hate speech normalization is not to support hate but instead to provide the users with a stepping stone towards non-hate while giving online platforms more time to monitor any improvement in the user's behavior. To this end, we manually curated a parallel corpus - hate texts and their normalized counterparts (a normalized text is less hateful and more benign). We introduce NACL, a simple yet efficient hate speech normalization model that operates in three stages - first, it measures the hate intensity of the original sample; second, it identifies the hate span(s) within it; and finally, it reduces hate intensity by paraphrasing the hate spans. We perform extensive experiments to measure the efficacy of NACL via three-way evaluation (intrinsic, extrinsic, and human-study). We observe that NACL outperforms six baselines - NACL yields a score of 0.1365 RMSE for the intensity prediction, 0.622 F1-score in the span identification, and 82.27 BLEU and 80.05 perplexity for the normalized text generation. We further show the generalizability of NACL across other platforms (Reddit, Facebook, Gab). An interactive prototype of NACL was put together for the user study. Further, the tool is being deployed in a real-world setting at Wipro AI as a part of its mission to tackle harmful content on online platforms.
Deep Learning for Hate Speech Detection: A Comparative Study
Feb 19, 2022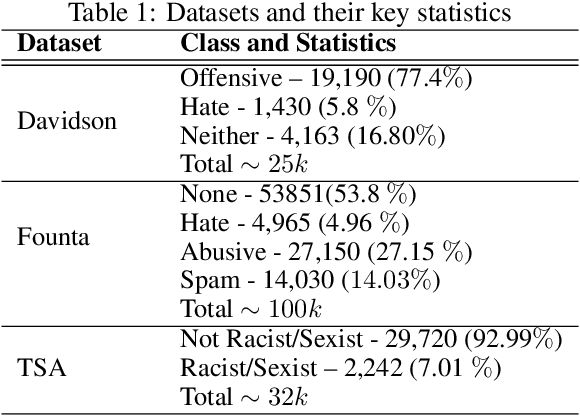
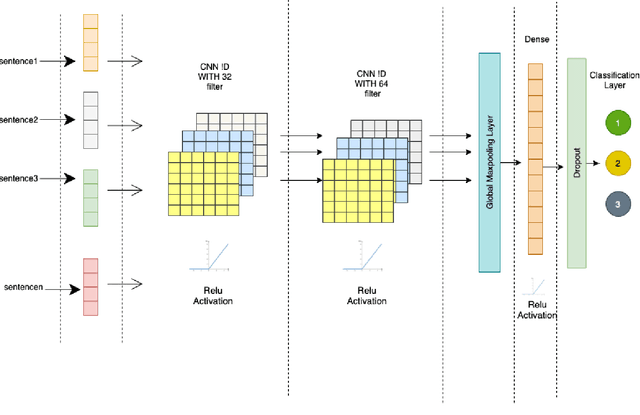
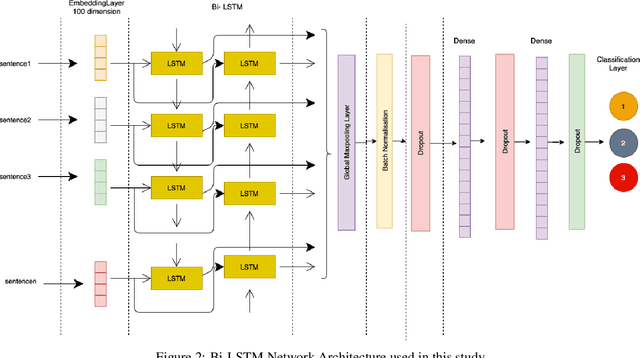
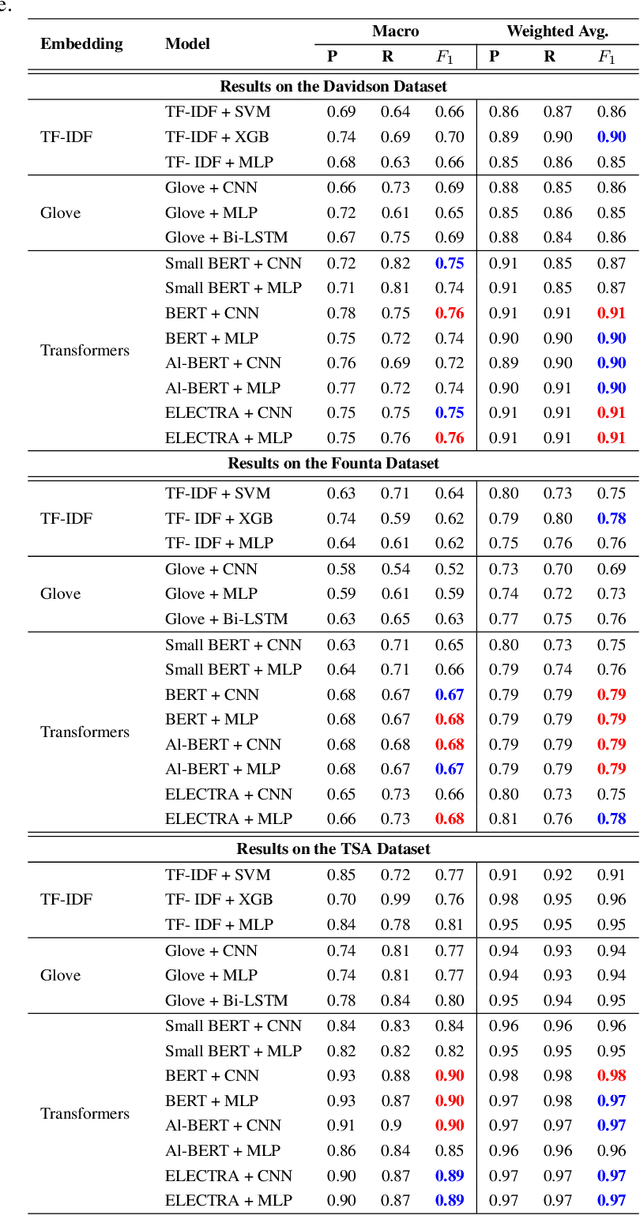
Automated hate speech detection is an important tool in combating the spread of hate speech, particularly in social media. Numerous methods have been developed for the task, including a recent proliferation of deep-learning based approaches. A variety of datasets have also been developed, exemplifying various manifestations of the hate-speech detection problem. We present here a large-scale empirical comparison of deep and shallow hate-speech detection methods, mediated through the three most commonly used datasets. Our goal is to illuminate progress in the area, and identify strengths and weaknesses in the current state-of-the-art. We particularly focus our analysis on measures of practical performance, including detection accuracy, computational efficiency, capability in using pre-trained models, and domain generalization. In doing so we aim to provide guidance as to the use of hate-speech detection in practice, quantify the state-of-the-art, and identify future research directions. Code and dataset are available at https://github.com/jmjmalik22/Hate-Speech-Detection.
A light-weight full-band speech enhancement model
Jun 29, 2022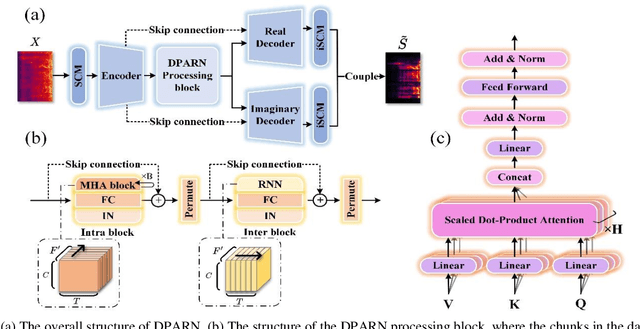
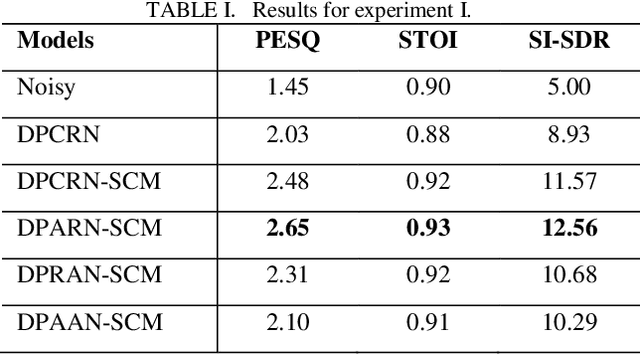
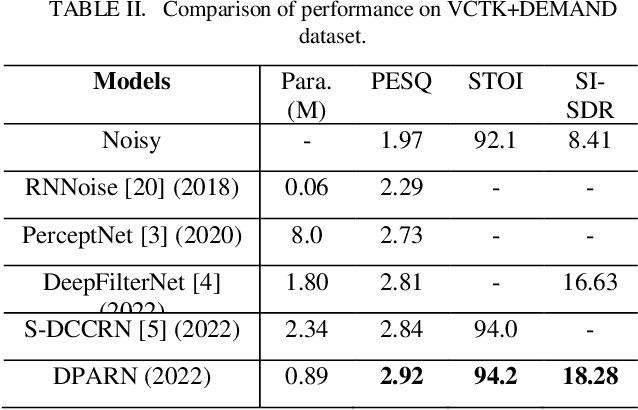
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
Large Raw Emotional Dataset with Aggregation Mechanism
Dec 23, 2022


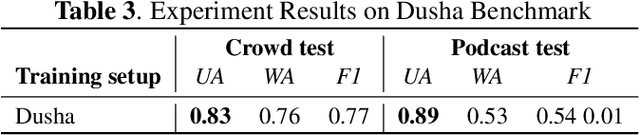
We present a new data set for speech emotion recognition (SER) tasks called Dusha. The corpus contains approximately 350 hours of data, more than 300 000 audio recordings with Russian speech and their transcripts. Therefore it is the biggest open bi-modal data collection for SER task nowadays. It is annotated using a crowd-sourcing platform and includes two subsets: acted and real-life. Acted subset has a more balanced class distribution than the unbalanced real-life part consisting of audio podcasts. So the first one is suitable for model pre-training, and the second is elaborated for fine-tuning purposes, model approbation, and validation. This paper describes pre-processing routine, annotation, and experiment with a baseline model to demonstrate some actual metrics which could be obtained with the Dusha data set.