 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
UnifySpeech: A Unified Framework for Zero-shot Text-to-Speech and Voice Conversion
Jan 10, 2023
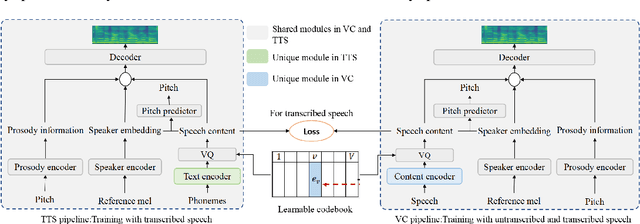

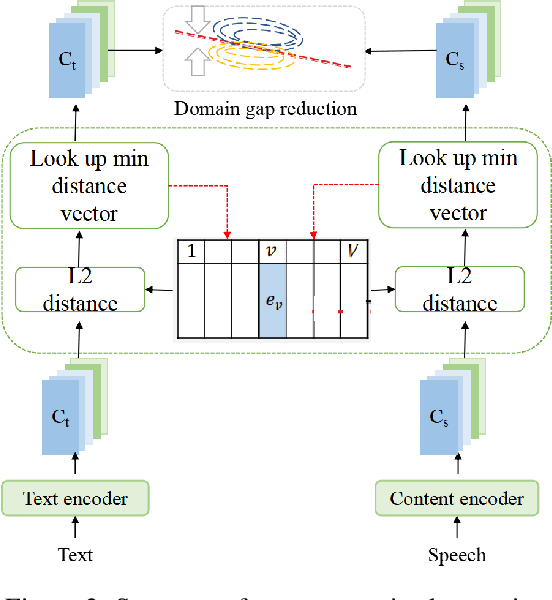
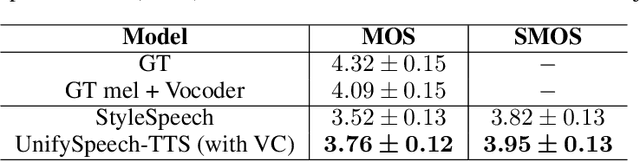
Text-to-speech (TTS) and voice conversion (VC) are two different tasks both aiming at generating high quality speaking voice according to different input modality. Due to their similarity, this paper proposes UnifySpeech, which brings TTS and VC into a unified framework for the first time. The model is based on the assumption that speech can be decoupled into three independent components: content information, speaker information, prosody information. Both TTS and VC can be regarded as mining these three parts of information from the input and completing the reconstruction of speech. For TTS, the speech content information is derived from the text, while in VC it's derived from the source speech, so all the remaining units are shared except for the speech content extraction module in the two tasks. We applied vector quantization and domain constrain to bridge the gap between the content domains of TTS and VC. Objective and subjective evaluation shows that by combining the two task, TTS obtains better speaker modeling ability while VC gets hold of impressive speech content decoupling capability.
Language Control in Robotics
May 04, 2023
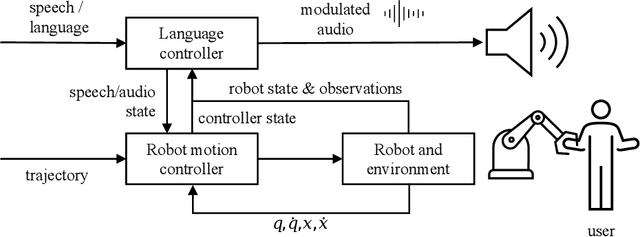
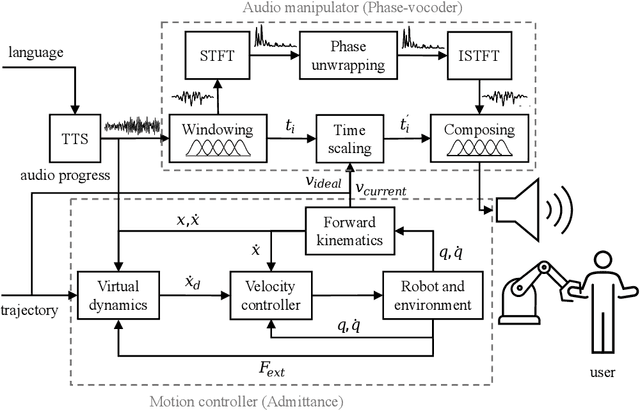
For robots performing a assistive tasks for the humans, it is crucial to synchronize their speech with their motions, in order to achieve natural and effective human-robot interaction. When a robot's speech is out of sync with their motions, it can cause confusion, frustration, and misinterpretation of the robot's intended meaning. Humans are accustomed to using both verbal and nonverbal cues to understand and coordinate with each other, and robots that can align their speech with their actions can tap into this natural mode of communication. In this research, we propose a language controller for robots to control the pace, tone, and pauses of their speech along with it's motion in the trajectory. The robot's speed is adjusted using an admittance controller based on the force input from the user, and the robot's speech speed is modulated using phase-vocoders.
IMaSC -- ICFOSS Malayalam Speech Corpus
Nov 23, 2022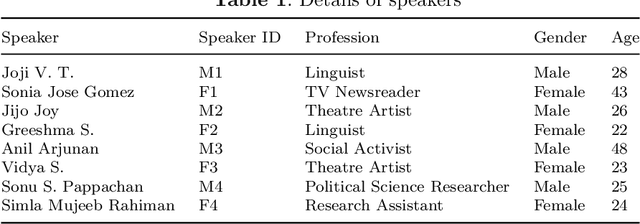

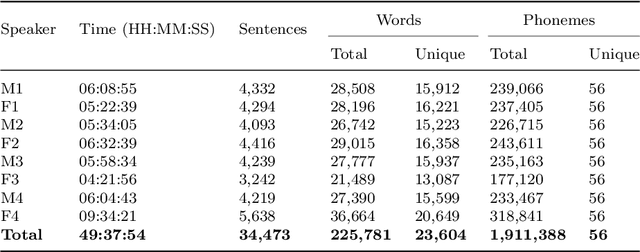
Modern text-to-speech (TTS) systems use deep learning to synthesize speech increasingly approaching human quality, but they require a database of high quality audio-text sentence pairs for training. Malayalam, the official language of the Indian state of Kerala and spoken by 35+ million people, is a low resource language in terms of available corpora for TTS systems. In this paper, we present IMaSC, a Malayalam text and speech corpora containing approximately 50 hours of recorded speech. With 8 speakers and a total of 34,473 text-audio pairs, IMaSC is larger than every other publicly available alternative. We evaluated the database by using it to train TTS models for each speaker based on a modern deep learning architecture. Via subjective evaluation, we show that our models perform significantly better in terms of naturalness compared to previous studies and publicly available models, with an average mean opinion score of 4.50, indicating that the synthesized speech is close to human quality.
PAMP: A unified framework boosting low resource automatic speech recognition
Feb 05, 2023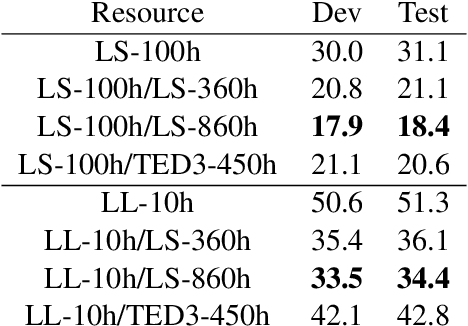
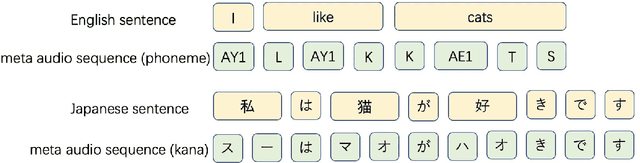
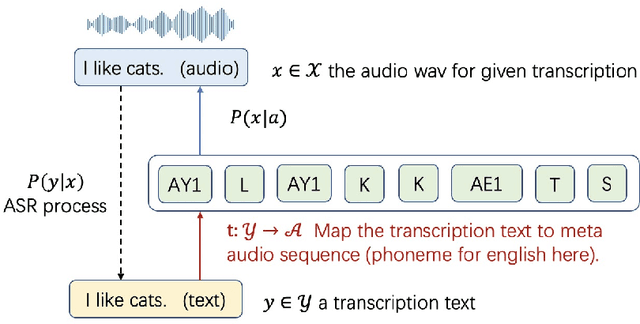
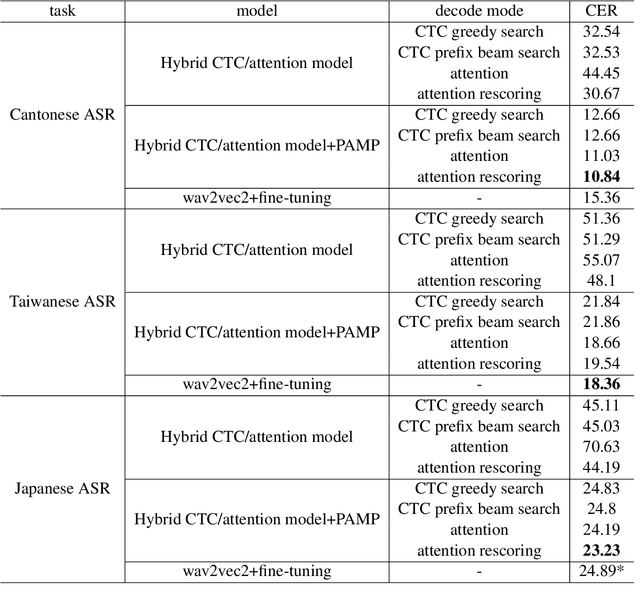
We propose a novel text-to-speech (TTS) data augmentation framework for low resource automatic speech recognition (ASR) tasks, named phoneme audio mix up (PAMP). The PAMP method is highly interpretable and can incorporate prior knowledge of pronunciation rules. Furthermore, PAMP can be easily deployed in almost any language, extremely for low resource ASR tasks. Extensive experiments have demonstrated the great effectiveness of PAMP on low resource ASR tasks: we achieve a \textbf{10.84\%} character error rate (CER) on the common voice Cantonese ASR task, bringing a great relative improvement of about \textbf{30\%} compared to the previous state-of-the-art which was achieved by fine-tuning the wav2vec2 pretrained model.
DasFormer: Deep Alternating Spectrogram Transformer for Multi/Single-Channel Speech Separation
Feb 21, 2023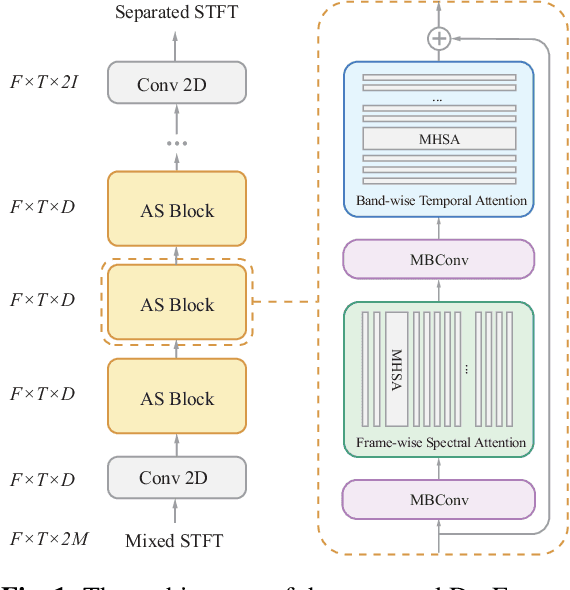
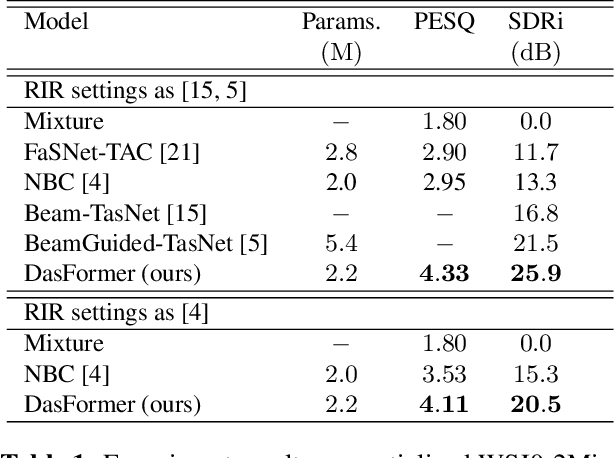
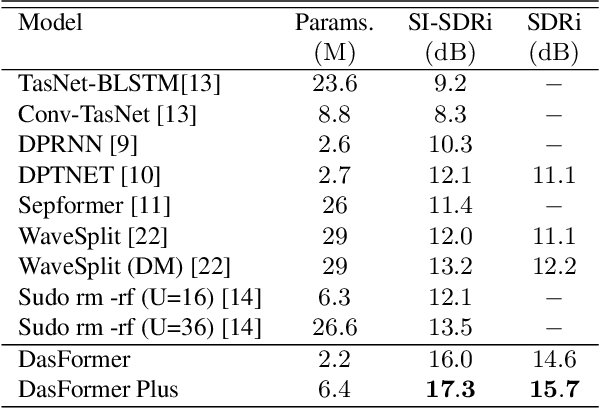
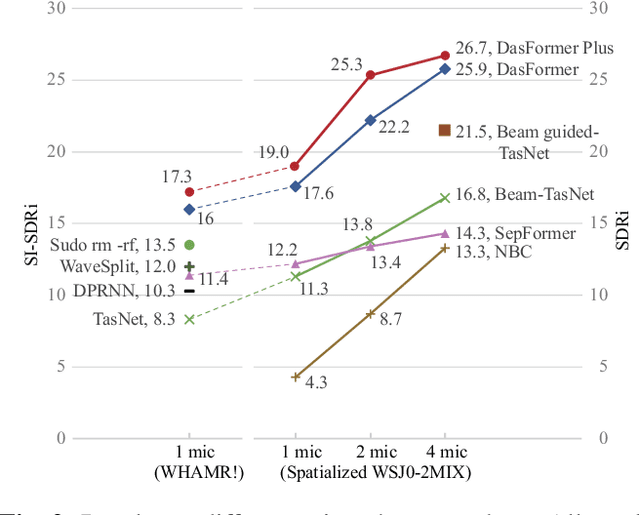
For the task of speech separation, previous study usually treats multi-channel and single-channel scenarios as two research tracks with specialized solutions developed respectively. Instead, we propose a simple and unified architecture - DasFormer (Deep alternating spectrogram transFormer) to handle both of them in the challenging reverberant environments. Unlike frame-wise sequence modeling, each TF-bin in the spectrogram is assigned with an embedding encoding spectral and spatial information. With such input, DasFormer is then formed by multiple repetition of simple blocks each of which integrates 1) two multi-head self-attention (MHSA) modules alternately processing within each frequency bin & temporal frame of the spectrogram 2) MBConv before each MHSA for modeling local features on the spectrogram. Experiments show that DasFormer has a powerful ability to model the time-frequency representation, whose performance far exceeds the current SOTA models in multi-channel speech separation, and also single-channel SOTA in the more challenging yet realistic reverberation scenario.
Speech-to-Speech Translation For A Real-world Unwritten Language
Nov 11, 2022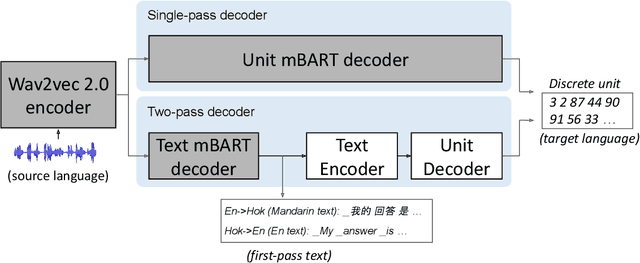
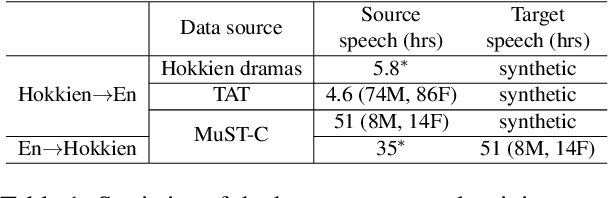
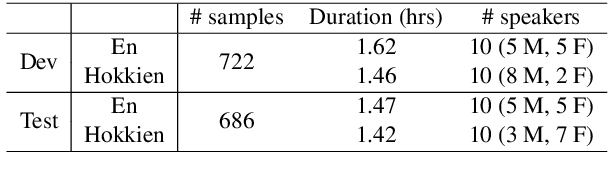
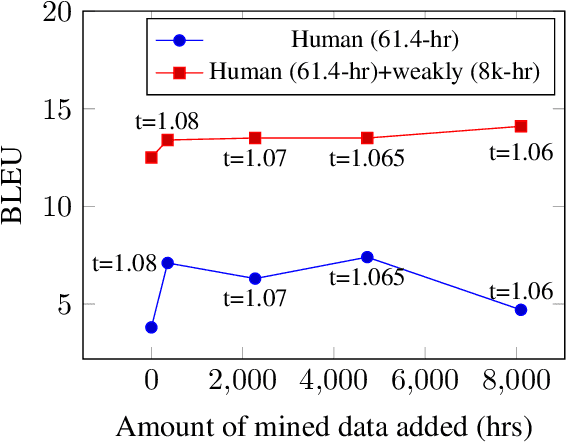
We study speech-to-speech translation (S2ST) that translates speech from one language into another language and focuses on building systems to support languages without standard text writing systems. We use English-Taiwanese Hokkien as a case study, and present an end-to-end solution from training data collection, modeling choices to benchmark dataset release. First, we present efforts on creating human annotated data, automatically mining data from large unlabeled speech datasets, and adopting pseudo-labeling to produce weakly supervised data. On the modeling, we take advantage of recent advances in applying self-supervised discrete representations as target for prediction in S2ST and show the effectiveness of leveraging additional text supervision from Mandarin, a language similar to Hokkien, in model training. Finally, we release an S2ST benchmark set to facilitate future research in this field. The demo can be found at https://huggingface.co/spaces/facebook/Hokkien_Translation .
A Comprehensive Review of Data-Driven Co-Speech Gesture Generation
Jan 13, 2023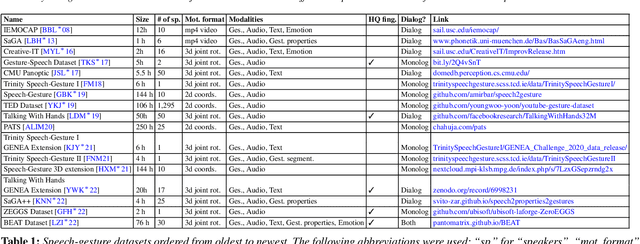

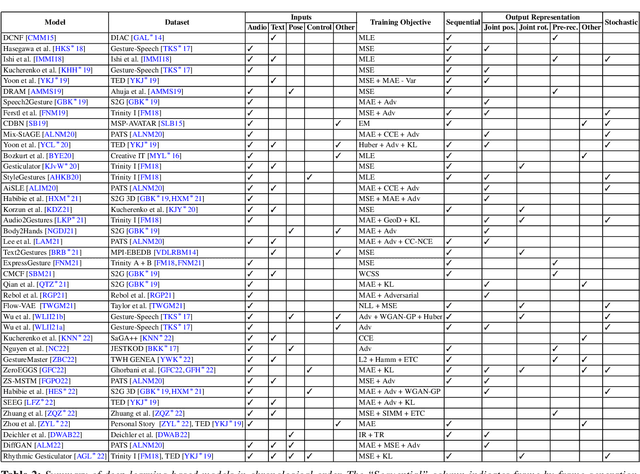
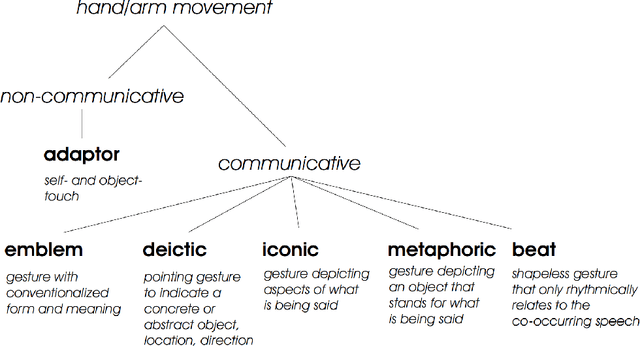
Gestures that accompany speech are an essential part of natural and efficient embodied human communication. The automatic generation of such co-speech gestures is a long-standing problem in computer animation and is considered an enabling technology in film, games, virtual social spaces, and for interaction with social robots. The problem is made challenging by the idiosyncratic and non-periodic nature of human co-speech gesture motion, and by the great diversity of communicative functions that gestures encompass. Gesture generation has seen surging interest recently, owing to the emergence of more and larger datasets of human gesture motion, combined with strides in deep-learning-based generative models, that benefit from the growing availability of data. This review article summarizes co-speech gesture generation research, with a particular focus on deep generative models. First, we articulate the theory describing human gesticulation and how it complements speech. Next, we briefly discuss rule-based and classical statistical gesture synthesis, before delving into deep learning approaches. We employ the choice of input modalities as an organizing principle, examining systems that generate gestures from audio, text, and non-linguistic input. We also chronicle the evolution of the related training data sets in terms of size, diversity, motion quality, and collection method. Finally, we identify key research challenges in gesture generation, including data availability and quality; producing human-like motion; grounding the gesture in the co-occurring speech in interaction with other speakers, and in the environment; performing gesture evaluation; and integration of gesture synthesis into applications. We highlight recent approaches to tackling the various key challenges, as well as the limitations of these approaches, and point toward areas of future development.
An automated method for the ontological representation of security directives
Jun 30, 2023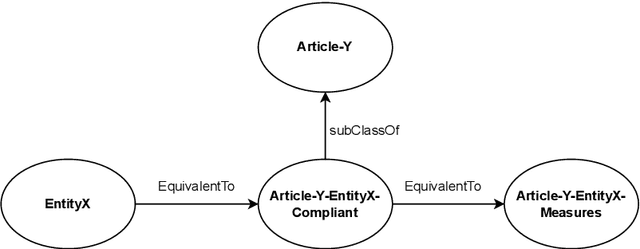
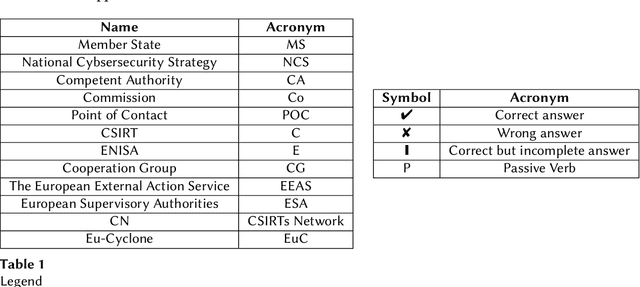
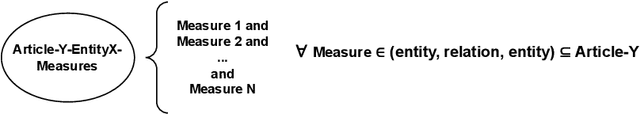

Large documents written in juridical language are difficult to interpret, with long sentences leading to intricate and intertwined relations between the nouns. The present paper frames this problem in the context of recent European security directives. The complexity of their language is here thwarted by automating the extraction of the relevant information, namely of the parts of speech from each clause, through a specific tailoring of Natural Language Processing (NLP) techniques. These contribute, in combination with ontology development principles, to the design of our automated method for the representation of security directives as ontologies. The method is showcased on a practical problem, namely to derive an ontology representing the NIS 2 directive, which is the peak of cybersecurity prescripts at the European level. Although the NLP techniques adopted showed some limitations and had to be complemented by manual analysis, the overall results provide valid support for directive compliance in general and for ontology development in particular.
CASEIN: Cascading Explicit and Implicit Control for Fine-grained Emotion Intensity Regulation
Jun 27, 2023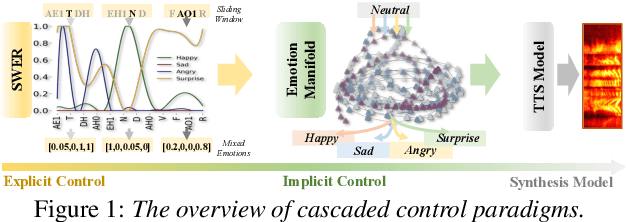
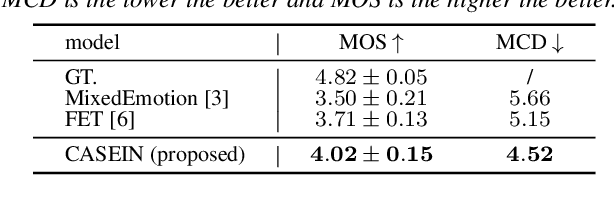
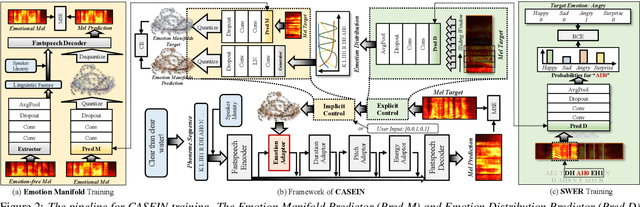

Existing fine-grained intensity regulation methods rely on explicit control through predicted emotion probabilities. However, these high-level semantic probabilities are often inaccurate and unsmooth at the phoneme level, leading to bias in learning. Especially when we attempt to mix multiple emotion intensities for specific phonemes, resulting in markedly reduced controllability and naturalness of the synthesis. To address this issue, we propose the CAScaded Explicit and Implicit coNtrol framework (CASEIN), which leverages accurate disentanglement of emotion manifolds from the reference speech to learn the implicit representation at a lower semantic level. This representation bridges the semantical gap between explicit probabilities and the synthesis model, reducing bias in learning. In experiments, our CASEIN surpasses existing methods in both controllability and naturalness. Notably, we are the first to achieve fine-grained control over the mixed intensity of multiple emotions.
Mingling or Misalignment? Temporal Shift for Speech Emotion Recognition with Pre-trained Representations
Mar 01, 2023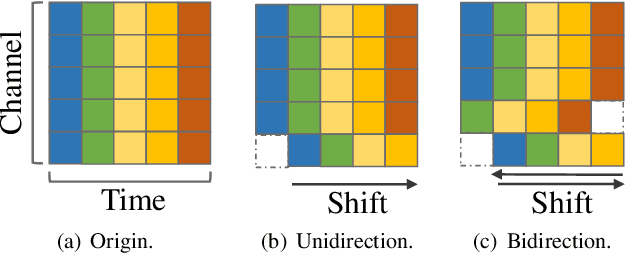
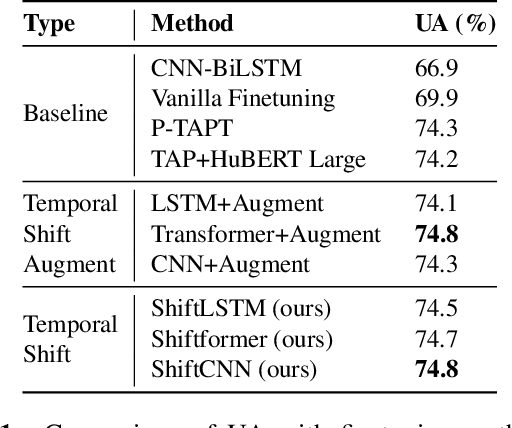
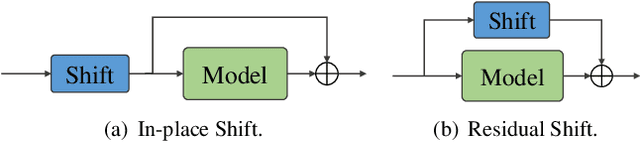
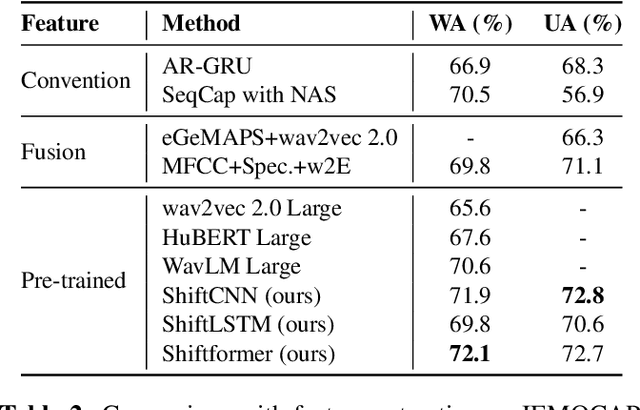
Fueled by recent advances of self-supervised models, pre-trained speech representations proved effective for the downstream speech emotion recognition (SER) task. Most prior works mainly focus on exploiting pre-trained representations and just adopt a linear head on top of the pre-trained model, neglecting the design of the downstream network. In this paper, we propose a temporal shift module to mingle channel-wise information without introducing any parameter or FLOP. With the temporal shift module, three designed baseline building blocks evolve into corresponding shift variants, i.e. ShiftCNN, ShiftLSTM, and Shiftformer. Moreover, to balance the trade-off between mingling and misalignment, we propose two technical strategies, placement of shift and proportion of shift. The family of temporal shift models all outperforms the state-of-the-art methods on the benchmark IEMOCAP dataset under both finetuning and feature extraction settings. Our code is available at https://github.com/ECNU-Cross-Innovation-Lab/ShiftSER.