 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking
May 15, 2023
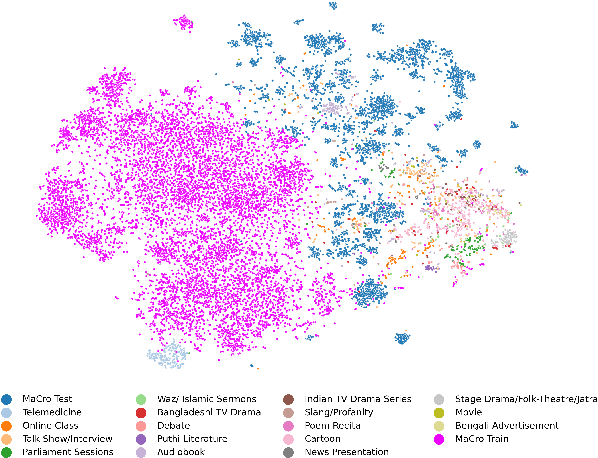
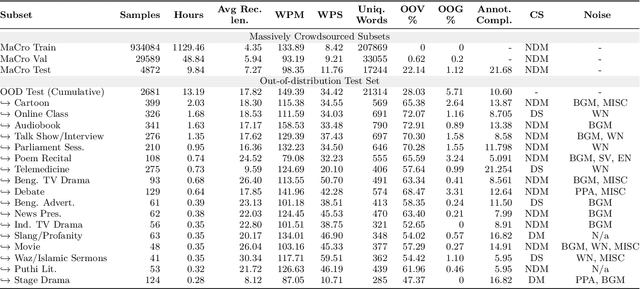
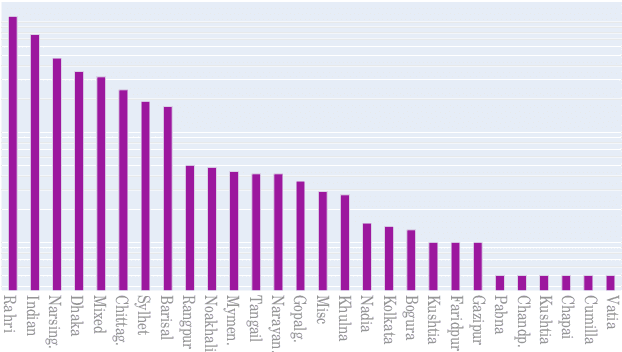
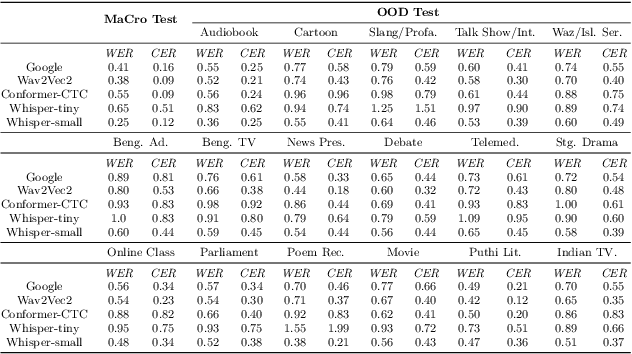
We present OOD-Speech, the first out-of-distribution (OOD) benchmarking dataset for Bengali automatic speech recognition (ASR). Being one of the most spoken languages globally, Bengali portrays large diversity in dialects and prosodic features, which demands ASR frameworks to be robust towards distribution shifts. For example, islamic religious sermons in Bengali are delivered with a tonality that is significantly different from regular speech. Our training dataset is collected via massively online crowdsourcing campaigns which resulted in 1177.94 hours collected and curated from $22,645$ native Bengali speakers from South Asia. Our test dataset comprises 23.03 hours of speech collected and manually annotated from 17 different sources, e.g., Bengali TV drama, Audiobook, Talk show, Online class, and Islamic sermons to name a few. OOD-Speech is jointly the largest publicly available speech dataset, as well as the first out-of-distribution ASR benchmarking dataset for Bengali.
t-SOT FNT: Streaming Multi-talker ASR with Text-only Domain Adaptation Capability
Sep 15, 2023
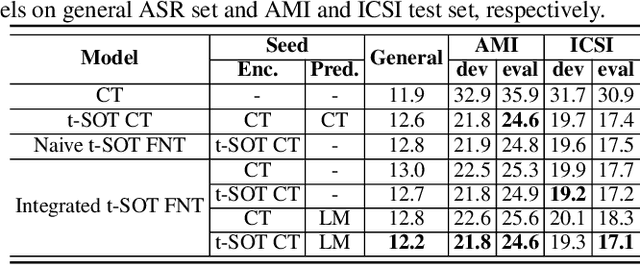
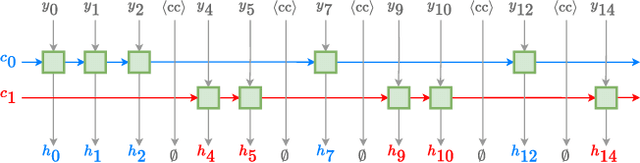

Token-level serialized output training (t-SOT) was recently proposed to address the challenge of streaming multi-talker automatic speech recognition (ASR). T-SOT effectively handles overlapped speech by representing multi-talker transcriptions as a single token stream with $\langle \text{cc}\rangle$ symbols interspersed. However, the use of a naive neural transducer architecture significantly constrained its applicability for text-only adaptation. To overcome this limitation, we propose a novel t-SOT model structure that incorporates the idea of factorized neural transducers (FNT). The proposed method separates a language model (LM) from the transducer's predictor and handles the unnatural token order resulting from the use of $\langle \text{cc}\rangle$ symbols in t-SOT. We achieve this by maintaining multiple hidden states and introducing special handling of the $\langle \text{cc}\rangle$ tokens within the LM. The proposed t-SOT FNT model achieves comparable performance to the original t-SOT model while retaining the ability to reduce word error rate (WER) on both single and multi-talker datasets through text-only adaptation.
Factual Consistency Oriented Speech Recognition
Feb 24, 2023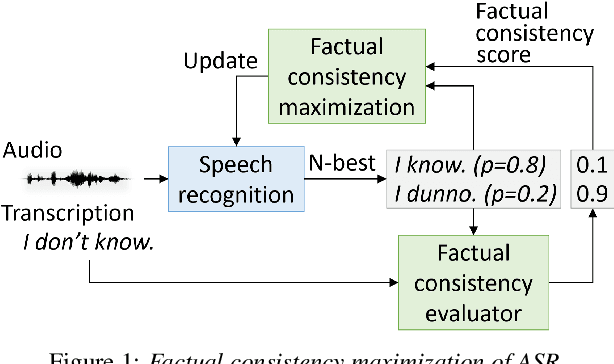
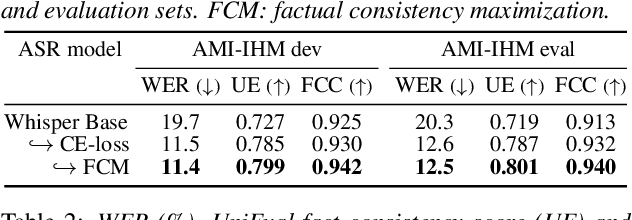
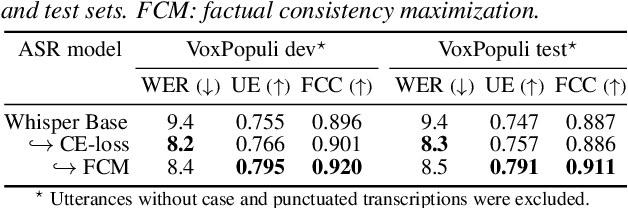

This paper presents a novel optimization framework for automatic speech recognition (ASR) with the aim of reducing hallucinations produced by an ASR model. The proposed framework optimizes the ASR model to maximize an expected factual consistency score between ASR hypotheses and ground-truth transcriptions, where the factual consistency score is computed by a separately trained estimator. Experimental results using the AMI meeting corpus and the VoxPopuli corpus show that the ASR model trained with the proposed framework generates ASR hypotheses that have significantly higher consistency scores with ground-truth transcriptions while maintaining the word error rates close to those of cross entropy-trained ASR models. Furthermore, it is shown that training the ASR models with the proposed framework improves the speech summarization quality as measured by the factual consistency of meeting conversation summaries generated by a large language model.
Improving Frame-level Classifier for Word Timings with Non-peaky CTC in End-to-End Automatic Speech Recognition
Jun 09, 2023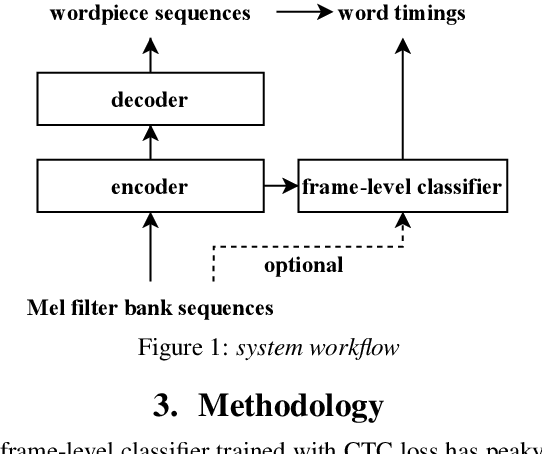
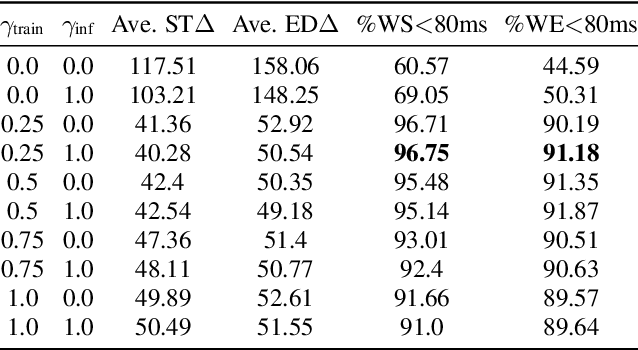
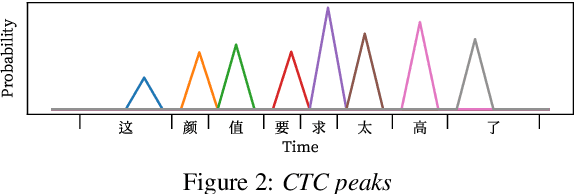
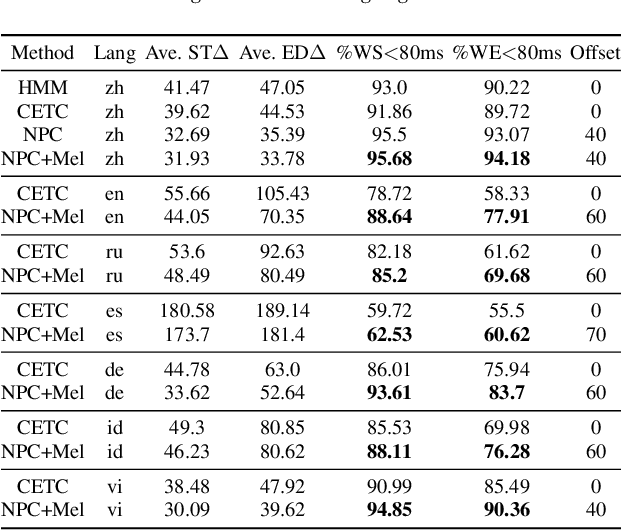
End-to-end (E2E) systems have shown comparable performance to hybrid systems for automatic speech recognition (ASR). Word timings, as a by-product of ASR, are essential in many applications, especially for subtitling and computer-aided pronunciation training. In this paper, we improve the frame-level classifier for word timings in E2E system by introducing label priors in connectionist temporal classification (CTC) loss, which is adopted from prior works, and combining low-level Mel-scale filter banks with high-level ASR encoder output as input feature. On the internal Chinese corpus, the proposed method achieves 95.68%/94.18% compared to the hybrid system 93.0%/90.22% on the word timing accuracy metrics. It also surpass a previous E2E approach with an absolute increase of 4.80%/8.02% on the metrics on 7 languages. In addition, we further improve word timing accuracy by delaying CTC peaks with frame-wise knowledge distillation, though only experimenting on LibriSpeech.
Contextual Biasing of Named-Entities with Large Language Models
Sep 22, 2023
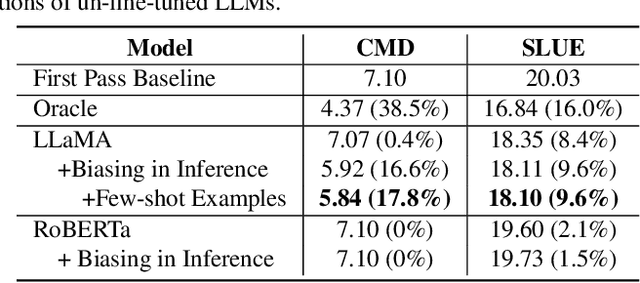
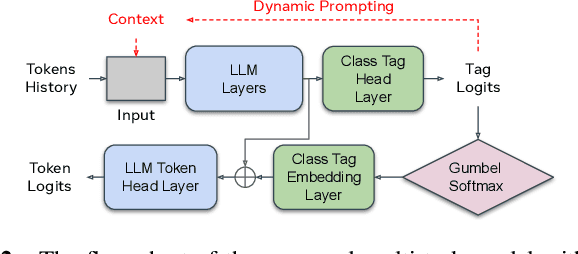
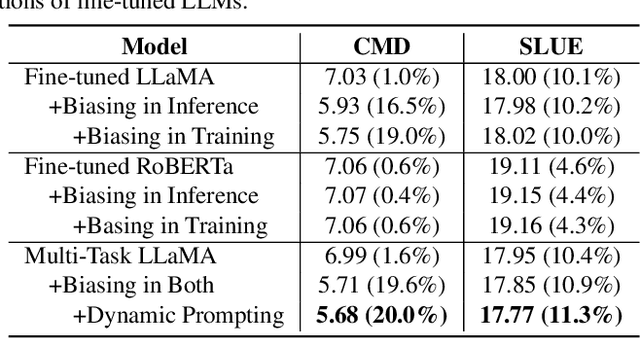
This paper studies contextual biasing with Large Language Models (LLMs), where during second-pass rescoring additional contextual information is provided to a LLM to boost Automatic Speech Recognition (ASR) performance. We propose to leverage prompts for a LLM without fine tuning during rescoring which incorporate a biasing list and few-shot examples to serve as additional information when calculating the score for the hypothesis. In addition to few-shot prompt learning, we propose multi-task training of the LLM to predict both the entity class and the next token. To improve the efficiency for contextual biasing and to avoid exceeding LLMs' maximum sequence lengths, we propose dynamic prompting, where we select the most likely class using the class tag prediction, and only use entities in this class as contexts for next token prediction. Word Error Rate (WER) evaluation is performed on i) an internal calling, messaging, and dictation dataset, and ii) the SLUE-Voxpopuli dataset. Results indicate that biasing lists and few-shot examples can achieve 17.8% and 9.6% relative improvement compared to first pass ASR, and that multi-task training and dynamic prompting can achieve 20.0% and 11.3% relative WER improvement, respectively.
Joint Audio and Speech Understanding
Oct 02, 2023Humans are surrounded by audio signals that include both speech and non-speech sounds. The recognition and understanding of speech and non-speech audio events, along with a profound comprehension of the relationship between them, constitute fundamental cognitive capabilities. For the first time, we build a machine learning model, called LTU-AS, that has a conceptually similar universal audio perception and advanced reasoning ability. Specifically, by integrating Whisper as a perception module and LLaMA as a reasoning module, LTU-AS can simultaneously recognize and jointly understand spoken text, speech paralinguistics, and non-speech audio events - almost everything perceivable from audio signals.
Multiscale Contextual Learning for Speech Emotion Recognition in Emergency Call Center Conversations
Aug 28, 2023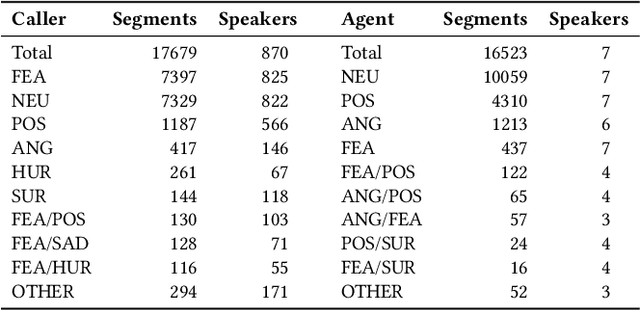
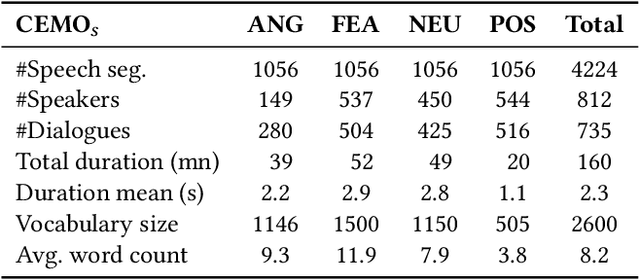
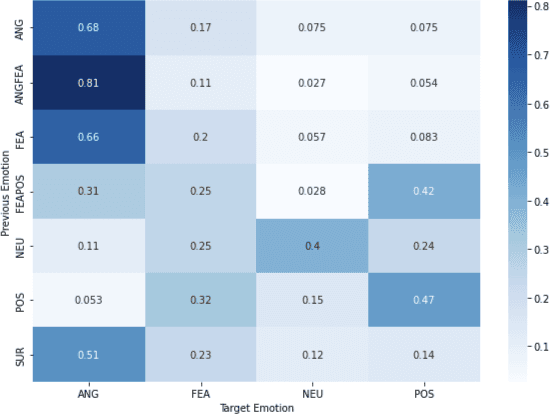
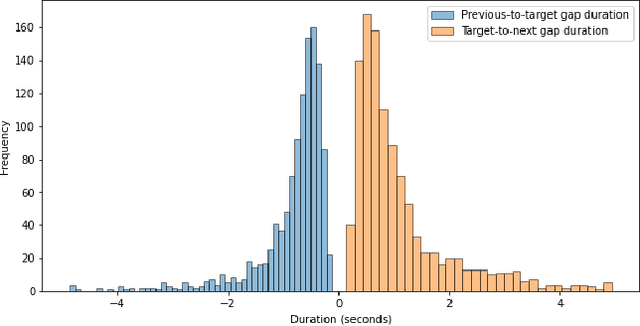
Emotion recognition in conversations is essential for ensuring advanced human-machine interactions. However, creating robust and accurate emotion recognition systems in real life is challenging, mainly due to the scarcity of emotion datasets collected in the wild and the inability to take into account the dialogue context. The CEMO dataset, composed of conversations between agents and patients during emergency calls to a French call center, fills this gap. The nature of these interactions highlights the role of the emotional flow of the conversation in predicting patient emotions, as context can often make a difference in understanding actual feelings. This paper presents a multi-scale conversational context learning approach for speech emotion recognition, which takes advantage of this hypothesis. We investigated this approach on both speech transcriptions and acoustic segments. Experimentally, our method uses the previous or next information of the targeted segment. In the text domain, we tested the context window using a wide range of tokens (from 10 to 100) and at the speech turns level, considering inputs from both the same and opposing speakers. According to our tests, the context derived from previous tokens has a more significant influence on accurate prediction than the following tokens. Furthermore, taking the last speech turn of the same speaker in the conversation seems useful. In the acoustic domain, we conducted an in-depth analysis of the impact of the surrounding emotions on the prediction. While multi-scale conversational context learning using Transformers can enhance performance in the textual modality for emergency call recordings, incorporating acoustic context is more challenging.
PromptASR for contextualized ASR with controllable style
Sep 14, 2023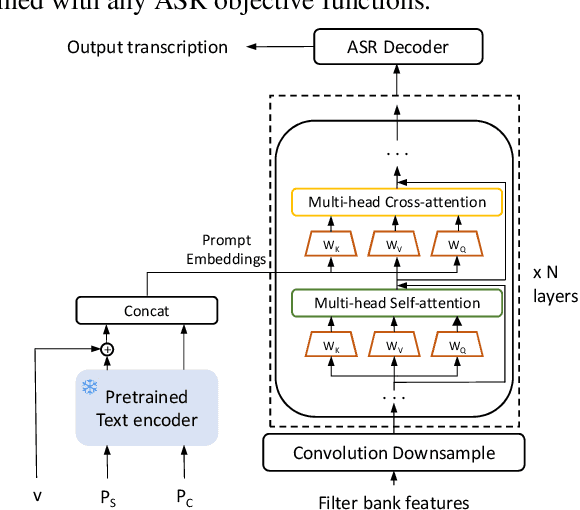
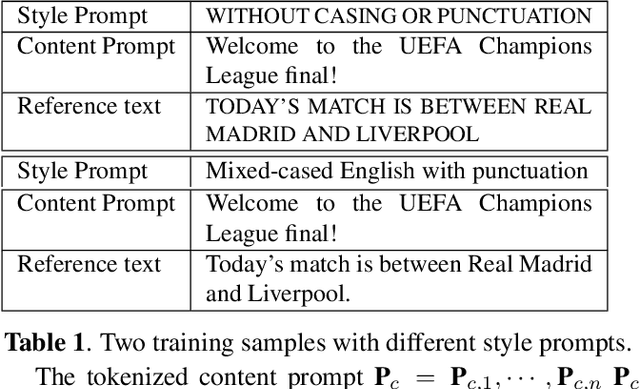
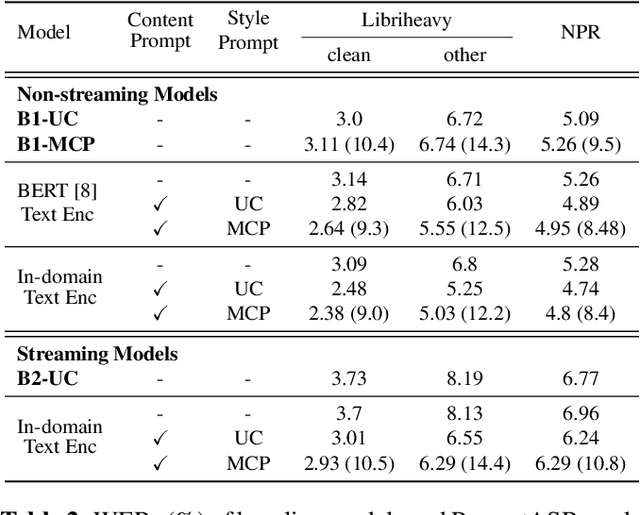
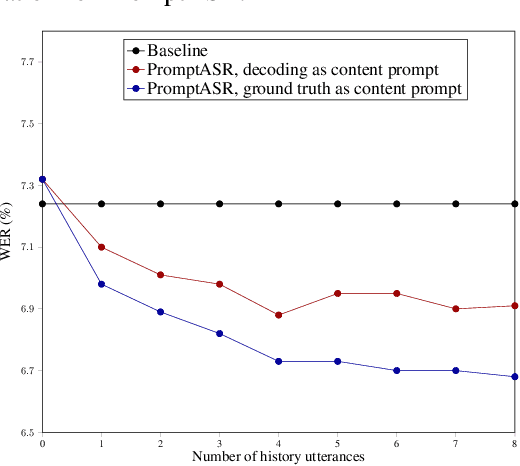
Prompts are crucial to large language models as they provide context information such as topic or logical relationships. Inspired by this, we propose PromptASR, a framework that integrates prompts in end-to-end automatic speech recognition (E2E ASR) systems to achieve contextualized ASR with controllable style of transcriptions. Specifically, a dedicated text encoder encodes the text prompts and the encodings are injected into the speech encoder by cross-attending the features from two modalities. When using the ground truth text from preceding utterances as content prompt, the proposed system achieves 21.9% and 6.8% relative word error rate reductions on a book reading dataset and an in-house dataset compared to a baseline ASR system. The system can also take word-level biasing lists as prompt to improve recognition accuracy on rare words. An additional style prompt can be given to the text encoder and guide the ASR system to output different styles of transcriptions. The code is available at icefall.
Speech enhancement with frequency domain auto-regressive modeling
Sep 24, 2023Speech applications in far-field real world settings often deal with signals that are corrupted by reverberation. The task of dereverberation constitutes an important step to improve the audible quality and to reduce the error rates in applications like automatic speech recognition (ASR). We propose a unified framework of speech dereverberation for improving the speech quality and the ASR performance using the approach of envelope-carrier decomposition provided by an autoregressive (AR) model. The AR model is applied in the frequency domain of the sub-band speech signals to separate the envelope and carrier parts. A novel neural architecture based on dual path long short term memory (DPLSTM) model is proposed, which jointly enhances the sub-band envelope and carrier components. The dereverberated envelope-carrier signals are modulated and the sub-band signals are synthesized to reconstruct the audio signal back. The DPLSTM model for dereverberation of envelope and carrier components also allows the joint learning of the network weights for the down stream ASR task. In the ASR tasks on the REVERB challenge dataset as well as on the VOiCES dataset, we illustrate that the joint learning of speech dereverberation network and the E2E ASR model yields significant performance improvements over the baseline ASR system trained on log-mel spectrogram as well as other benchmarks for dereverberation (average relative improvements of 10-24% over the baseline system). The speech quality improvements, evaluated using subjective listening tests, further highlight the improved quality of the reconstructed audio.
* 10 pages
End-to-End Speech Recognition and Disfluency Removal with Acoustic Language Model Pretraining
Sep 08, 2023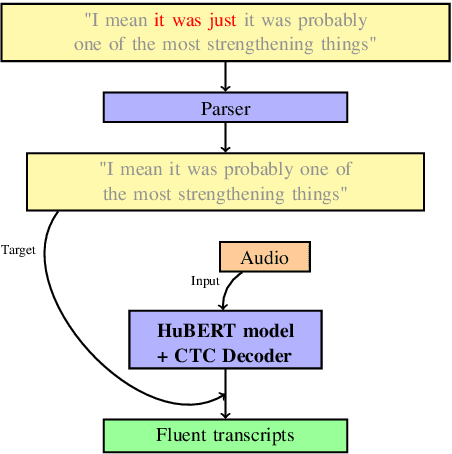
The SOTA in transcription of disfluent and conversational speech has in recent years favored two-stage models, with separate transcription and cleaning stages. We believe that previous attempts at end-to-end disfluency removal have fallen short because of the representational advantage that large-scale language model pretraining has given to lexical models. Until recently, the high dimensionality and limited availability of large audio datasets inhibited the development of large-scale self-supervised pretraining objectives for learning effective audio representations, giving a relative advantage to the two-stage approach, which utilises pretrained representations for lexical tokens. In light of recent successes in large scale audio pretraining, we revisit the performance comparison between two-stage and end-to-end model and find that audio based language models pretrained using weak self-supervised objectives match or exceed the performance of similarly trained two-stage models, and further, that the choice of pretraining objective substantially effects a model's ability to be adapted to the disfluency removal task.