 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
TLT-school: a Corpus of Non Native Children Speech
Jan 22, 2020
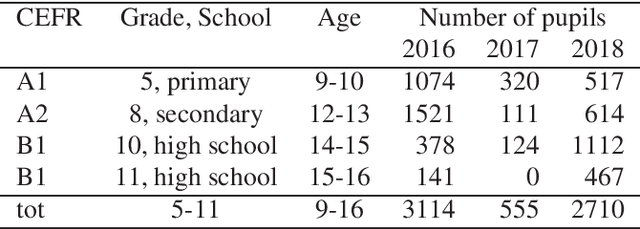
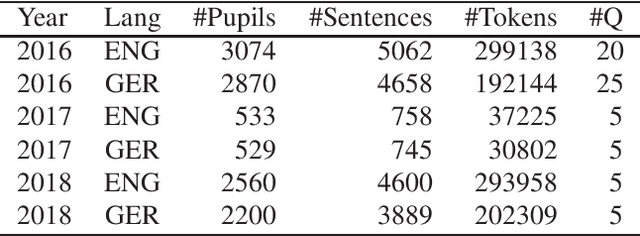
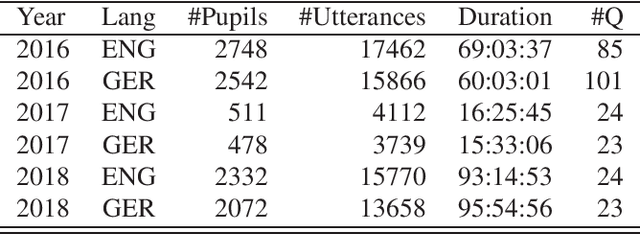
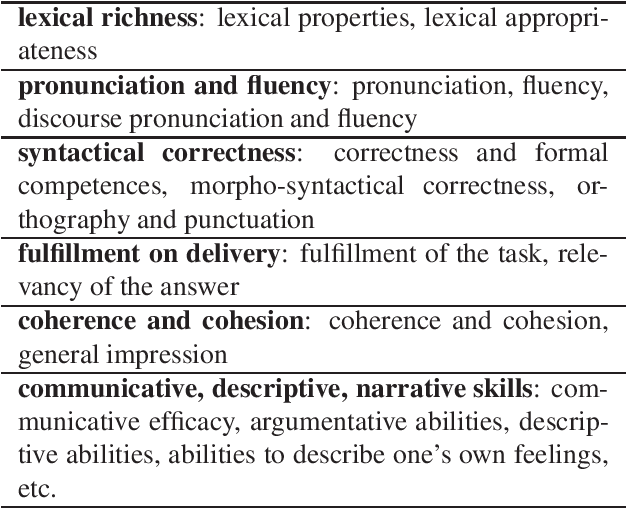
This paper describes "TLT-school" a corpus of speech utterances collected in schools of northern Italy for assessing the performance of students learning both English and German. The corpus was recorded in the years 2017 and 2018 from students aged between nine and sixteen years, attending primary, middle and high school. All utterances have been scored, in terms of some predefined proficiency indicators, by human experts. In addition, most of utterances recorded in 2017 have been manually transcribed carefully. Guidelines and procedures used for manual transcriptions of utterances will be described in detail, as well as results achieved by means of an automatic speech recognition system developed by us. Part of the corpus is going to be freely distributed to scientific community particularly interested both in non-native speech recognition and automatic assessment of second language proficiency.
Multimodal Speech Emotion Recognition and Ambiguity Resolution
Apr 12, 2019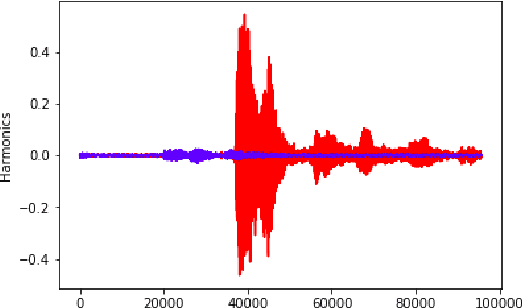
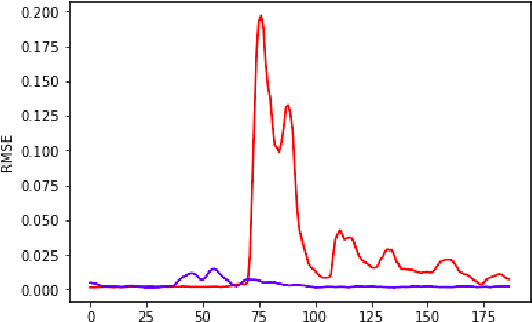
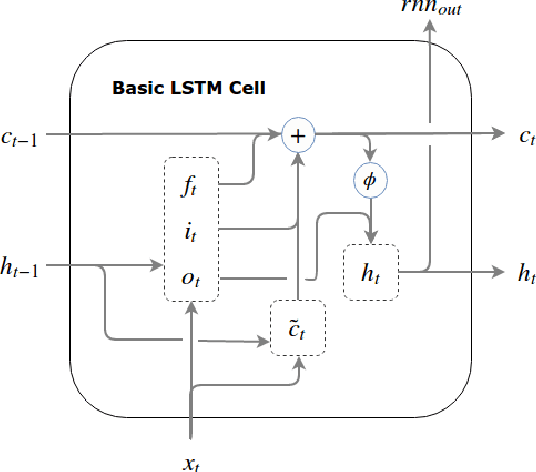
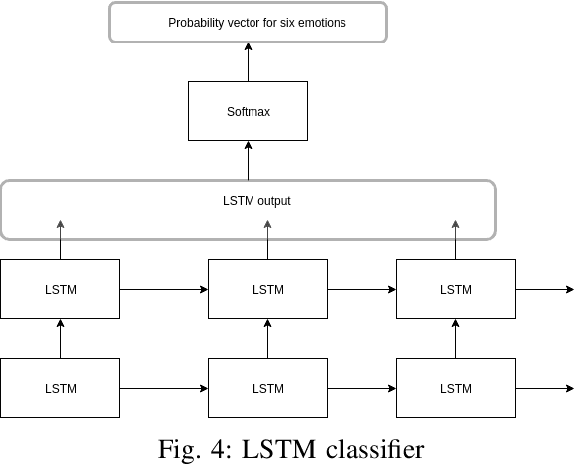
Identifying emotion from speech is a non-trivial task pertaining to the ambiguous definition of emotion itself. In this work, we adopt a feature-engineering based approach to tackle the task of speech emotion recognition. Formalizing our problem as a multi-class classification problem, we compare the performance of two categories of models. For both, we extract eight hand-crafted features from the audio signal. In the first approach, the extracted features are used to train six traditional machine learning classifiers, whereas the second approach is based on deep learning wherein a baseline feed-forward neural network and an LSTM-based classifier are trained over the same features. In order to resolve ambiguity in communication, we also include features from the text domain. We report accuracy, f-score, precision, and recall for the different experiment settings we evaluated our models in. Overall, we show that lighter machine learning based models trained over a few hand-crafted features are able to achieve performance comparable to the current deep learning based state-of-the-art method for emotion recognition.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021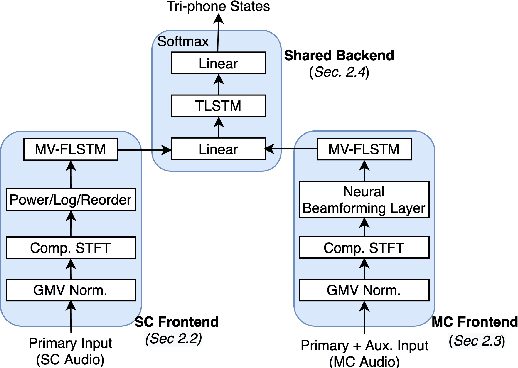
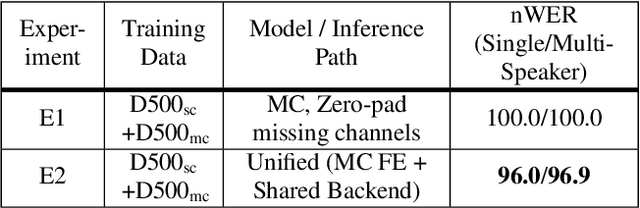
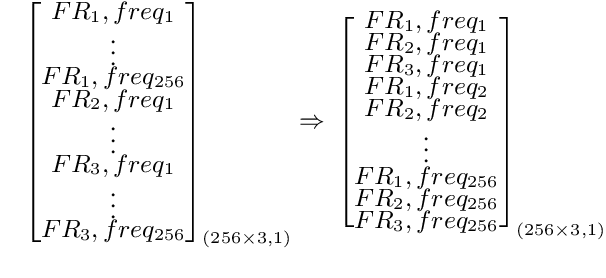
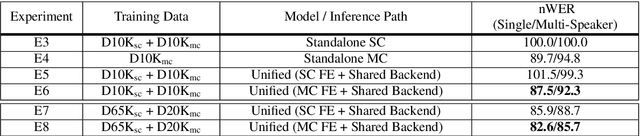
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021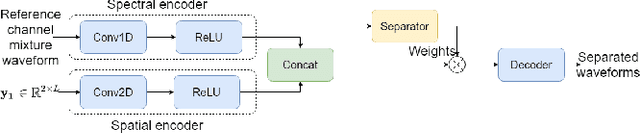
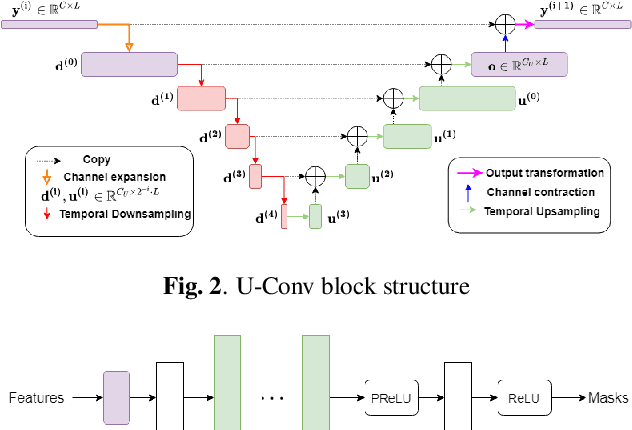
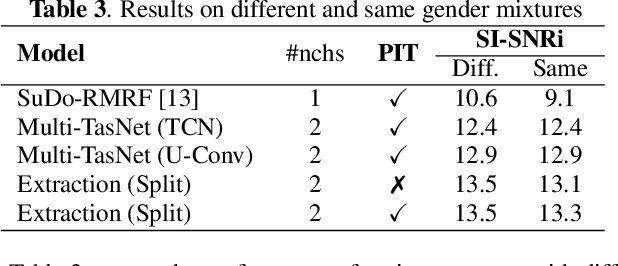

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Apr 09, 2021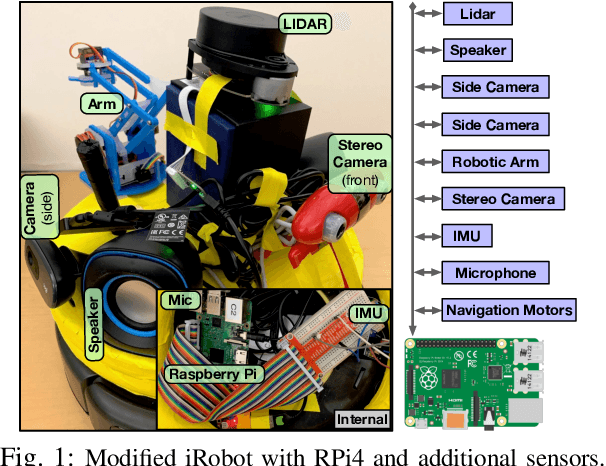
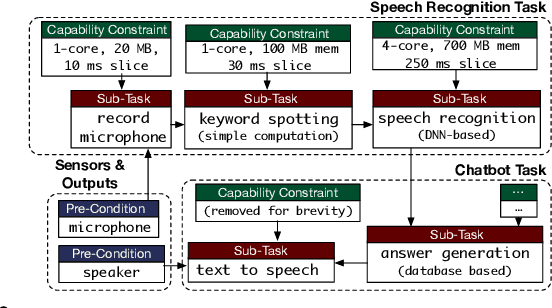
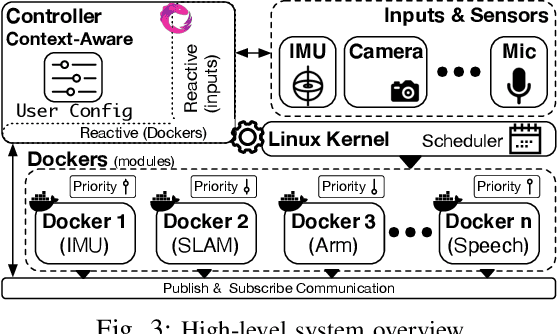
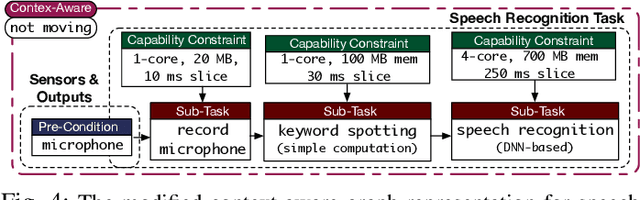
Intelligent mobile robots are critical in several scenarios. However, as their computational resources are limited, mobile robots struggle to handle several tasks concurrently and yet guaranteeing real-timeliness. To address this challenge and improve the real-timeliness of critical tasks under resource constraints, we propose a fast context-aware task handling technique. To effectively handling tasks in real-time, our proposed context-aware technique comprises of three main ingredients: (i) a dynamic time-sharing mechanism, coupled with (ii) an event-driven task scheduling using reactive programming paradigm to mindfully use the limited resources; and, (iii) a lightweight virtualized execution to easily integrate functionalities and their dependencies. We showcase our technique on a Raspberry-Pi-based robot with a variety of tasks such as Simultaneous localization and mapping (SLAM), sign detection, and speech recognition with a 42% speedup in total execution time compared to the common Linux scheduler.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 17, 2021
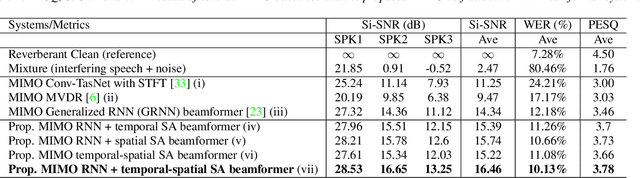

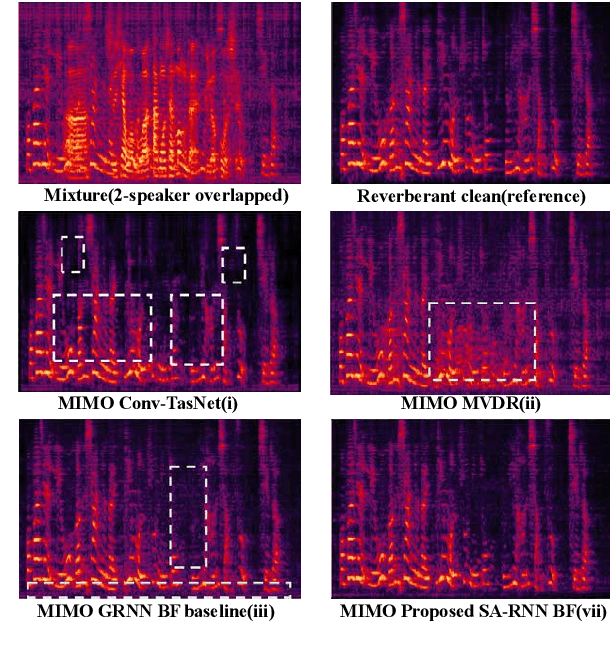
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two RNNs.In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency.The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
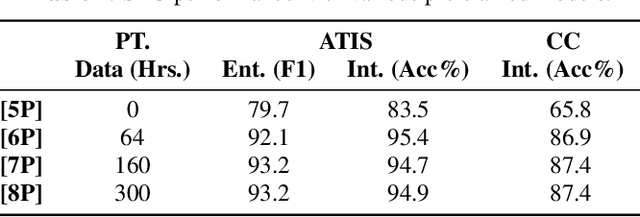


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
Talk, Don't Write: A Study of Direct Speech-Based Image Retrieval
Apr 08, 2021
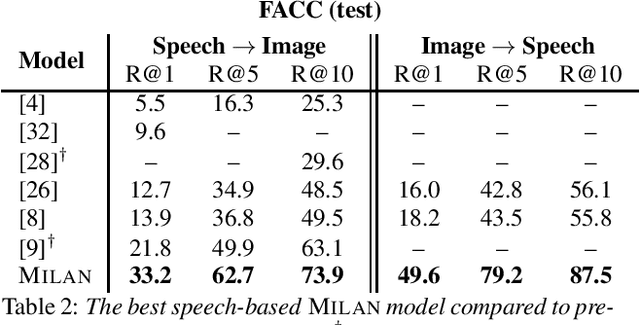
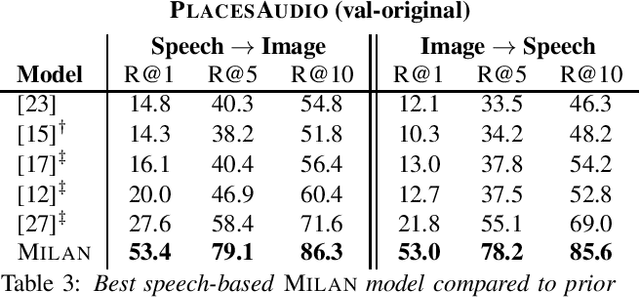
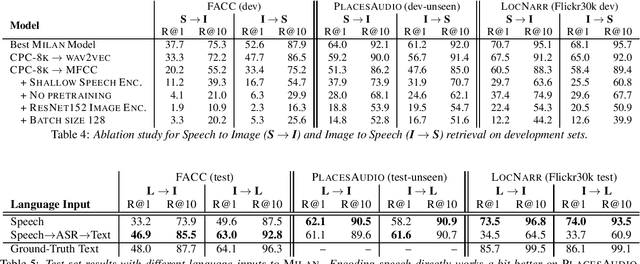
Speech-based image retrieval has been studied as a proxy for joint representation learning, usually without emphasis on retrieval itself. As such, it is unclear how well speech-based retrieval can work in practice -- both in an absolute sense and versus alternative strategies that combine automatic speech recognition (ASR) with strong text encoders. In this work, we extensively study and expand choices of encoder architectures, training methodology (including unimodal and multimodal pretraining), and other factors. Our experiments cover different types of speech in three datasets: Flickr Audio, Places Audio, and Localized Narratives. Our best model configuration achieves large gains over state of the art, e.g., pushing recall-at-one from 21.8% to 33.2% for Flickr Audio and 27.6% to 53.4% for Places Audio. We also show our best speech-based models can match or exceed cascaded ASR-to-text encoding when speech is spontaneous, accented, or otherwise hard to automatically transcribe.
LT-LM: a novel non-autoregressive language model for single-shot lattice rescoring
Apr 06, 2021
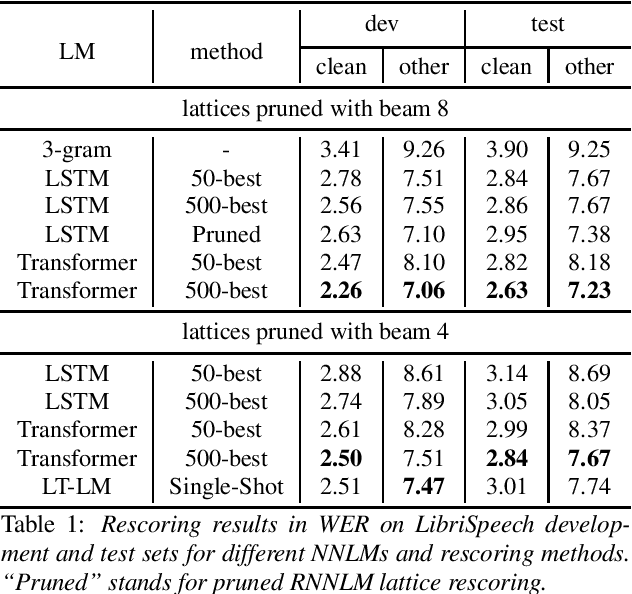
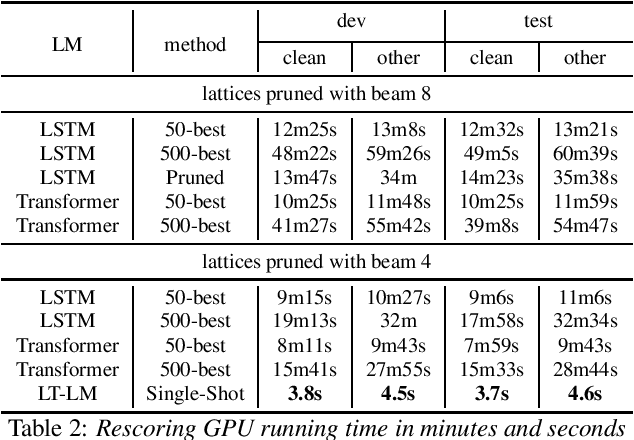
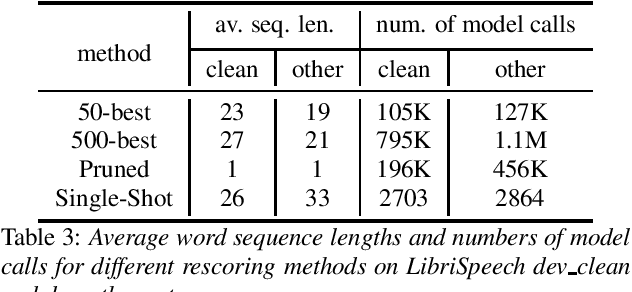
Neural network-based language models are commonly used in rescoring approaches to improve the quality of modern automatic speech recognition (ASR) systems. Most of the existing methods are computationally expensive since they use autoregressive language models. We propose a novel rescoring approach, which processes the entire lattice in a single call to the model. The key feature of our rescoring policy is a novel non-autoregressive Lattice Transformer Language Model (LT-LM). This model takes the whole lattice as an input and predicts a new language score for each arc. Additionally, we propose the artificial lattices generation approach to incorporate a large amount of text data in the LT-LM training process. Our single-shot rescoring performs orders of magnitude faster than other rescoring methods in our experiments. It is more than 300 times faster than pruned RNNLM lattice rescoring and N-best rescoring while slightly inferior in terms of WER.