 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Referential Analytic Assessment: A Profile-Based Approach to L2 Writing Evaluation with LLMs
May 05, 2026Automated essay scoring (AES) research often relies on rank-based correlation metrics to validate analytic assessment. However, such metrics obscure both intrinsic intercorrelations among analytic dimensions that arise from the structure of writing proficiency itself and halo effects, whereby holistic impressions bleed into fine-grained component scores. As a result, high correlations may mask a system's true diagnostic behaviour. In this study, we propose a novel self-referential assessment evaluation framework that focuses on identifying intra-learner strengths and weaknesses rather than assessing inter-learner rankings. We conduct experiments on the publicly available ICNALE GRA, a uniquely dense second-language writing dataset annotated holistically and analytically by up to 80 trained raters. To obtain reliable reference scores, we apply two-facet Rasch modelling to calibrate rater severity and derive fair average scores across ten analytic aspects and holistic proficiency. We compare the analytic scoring performance of human operational raters and three large language models (LLMs) in a zero-shot setting. Our results show that LLMs tend to outperform single human raters in identifying relative weaknesses (negative feedback) across several proficiency aspects, while human raters remain stronger at identifying relative strengths (positive feedback). Overall, our findings highlight the limitations of rank-based evaluation for analytic assessment and demonstrate the value of intra-learner, profile-based methods for assessing and deploying LLMs in AES.
Exploiting the English Grammar Profile for L2 grammatical analysis with LLMs
Mar 17, 2026Evaluating the grammatical competence of second language (L2) learners is essential both for providing targeted feedback and for assessing proficiency. To achieve this, we propose a novel framework leveraging the English Grammar Profile (EGP), a taxonomy of grammatical constructs mapped to the proficiency levels of the Common European Framework of Reference (CEFR), to detect learners' attempts at grammatical constructs and classify them as successful or unsuccessful. This detection can then be used to provide fine-grained feedback. Moreover, the grammatical constructs are used as predictors of proficiency assessment by using automatically detected attempts as predictors of holistic CEFR proficiency. For the selection of grammatical constructs derived from the EGP, rule-based and LLM-based classifiers are compared. We show that LLMs outperform rule-based methods on semantically and pragmatically nuanced constructs, while rule-based approaches remain competitive for constructs that rely purely on morphological or syntactic features and do not require semantic interpretation. For proficiency assessment, we evaluate both rule-based and hybrid pipelines and show that a hybrid approach combining a rule-based pre-filter with an LLM consistently yields the strongest performance. Since our framework operates on pairs of original learner sentences and their corrected counterparts, we also evaluate a fully automated pipeline using automatic grammatical error correction. This pipeline closely approaches the performance of semi-automated systems based on manual corrections, particularly for the detection of successful attempts at grammatical constructs. Overall, our framework emphasises learners' successful attempts in addition to unsuccessful ones, enabling positive, formative feedback and providing actionable insights into grammatical development.
Opportunities and Challenges of LLMs in Education: An NLP Perspective
Jul 30, 2025



Interest in the role of large language models (LLMs) in education is increasing, considering the new opportunities they offer for teaching, learning, and assessment. In this paper, we examine the impact of LLMs on educational NLP in the context of two main application scenarios: {\em assistance} and {\em assessment}, grounding them along the four dimensions -- reading, writing, speaking, and tutoring. We then present the new directions enabled by LLMs, and the key challenges to address. We envision that this holistic overview would be useful for NLP researchers and practitioners interested in exploring the role of LLMs in developing language-focused and NLP-enabled educational applications of the future.
Scaling and Prompting for Improved End-to-End Spoken Grammatical Error Correction
May 27, 2025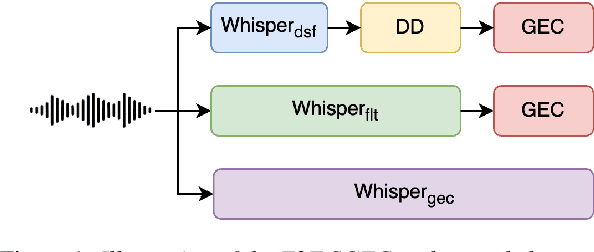
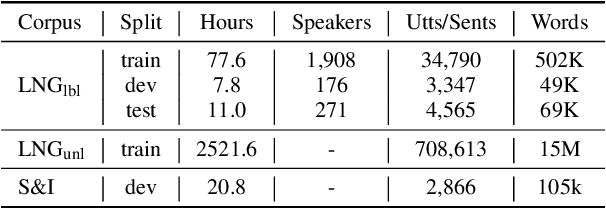
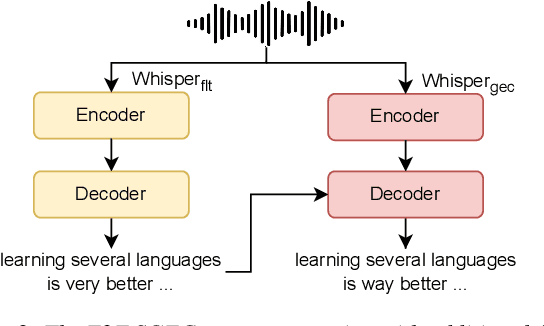
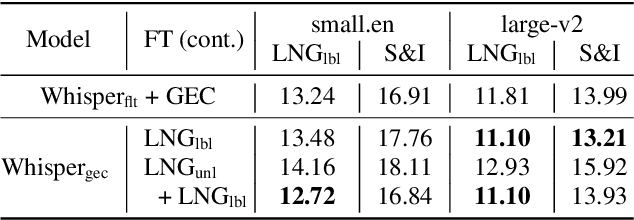
Spoken Grammatical Error Correction (SGEC) and Feedback (SGECF) are crucial for second language learners, teachers and test takers. Traditional SGEC systems rely on a cascaded pipeline consisting of an ASR, a module for disfluency detection (DD) and removal and one for GEC. With the rise of end-to-end (E2E) speech foundation models, we investigate their effectiveness in SGEC and feedback generation. This work introduces a pseudo-labelling process to address the challenge of limited labelled data, expanding the training data size from 77 hours to approximately 2500 hours, leading to improved performance. Additionally, we prompt an E2E Whisper-based SGEC model with fluent transcriptions, showing a slight improvement in SGEC performance, with more significant gains in feedback generation. Finally, we assess the impact of increasing model size, revealing that while pseudo-labelled data does not yield performance gain for a larger Whisper model, training with prompts proves beneficial.
Assessment of L2 Oral Proficiency using Speech Large Language Models
May 27, 2025



The growing population of L2 English speakers has increased the demand for developing automatic graders for spoken language assessment (SLA). Historically, statistical models, text encoders, and self-supervised speech models have been utilised for this task. However, cascaded systems suffer from the loss of information, while E2E graders also have limitations. With the recent advancements of multi-modal large language models (LLMs), we aim to explore their potential as L2 oral proficiency graders and overcome these issues. In this work, we compare various training strategies using regression and classification targets. Our results show that speech LLMs outperform all previous competitive baselines, achieving superior performance on two datasets. Furthermore, the trained grader demonstrates strong generalisation capabilities in the cross-part or cross-task evaluation, facilitated by the audio understanding knowledge acquired during LLM pre-training.
LLMs in Education: Novel Perspectives, Challenges, and Opportunities
Sep 18, 2024The role of large language models (LLMs) in education is an increasing area of interest today, considering the new opportunities they offer for teaching, learning, and assessment. This cutting-edge tutorial provides an overview of the educational applications of NLP and the impact that the recent advances in LLMs have had on this field. We will discuss the key challenges and opportunities presented by LLMs, grounding them in the context of four major educational applications: reading, writing, and speaking skills, and intelligent tutoring systems (ITS). This COLING 2025 tutorial is designed for researchers and practitioners interested in the educational applications of NLP and the role LLMs have to play in this area. It is the first of its kind to address this timely topic.
Grammatical Error Feedback: An Implicit Evaluation Approach
Aug 18, 2024Grammatical feedback is crucial for consolidating second language (L2) learning. Most research in computer-assisted language learning has focused on feedback through grammatical error correction (GEC) systems, rather than examining more holistic feedback that may be more useful for learners. This holistic feedback will be referred to as grammatical error feedback (GEF). In this paper, we present a novel implicit evaluation approach to GEF that eliminates the need for manual feedback annotations. Our method adopts a grammatical lineup approach where the task is to pair feedback and essay representations from a set of possible alternatives. This matching process can be performed by appropriately prompting a large language model (LLM). An important aspect of this process, explored here, is the form of the lineup, i.e., the selection of foils. This paper exploits this framework to examine the quality and need for GEC to generate feedback, as well as the system used to generate feedback, using essays from the Cambridge Learner Corpus.
Can GPT-4 do L2 analytic assessment?
Apr 29, 2024Automated essay scoring (AES) to evaluate second language (L2) proficiency has been a firmly established technology used in educational contexts for decades. Although holistic scoring has seen advancements in AES that match or even exceed human performance, analytic scoring still encounters issues as it inherits flaws and shortcomings from the human scoring process. The recent introduction of large language models presents new opportunities for automating the evaluation of specific aspects of L2 writing proficiency. In this paper, we perform a series of experiments using GPT-4 in a zero-shot fashion on a publicly available dataset annotated with holistic scores based on the Common European Framework of Reference and aim to extract detailed information about their underlying analytic components. We observe significant correlations between the automatically predicted analytic scores and multiple features associated with the individual proficiency components.
Towards End-to-End Spoken Grammatical Error Correction
Nov 09, 2023Grammatical feedback is crucial for L2 learners, teachers, and testers. Spoken grammatical error correction (GEC) aims to supply feedback to L2 learners on their use of grammar when speaking. This process usually relies on a cascaded pipeline comprising an ASR system, disfluency removal, and GEC, with the associated concern of propagating errors between these individual modules. In this paper, we introduce an alternative "end-to-end" approach to spoken GEC, exploiting a speech recognition foundation model, Whisper. This foundation model can be used to replace the whole framework or part of it, e.g., ASR and disfluency removal. These end-to-end approaches are compared to more standard cascaded approaches on the data obtained from a free-speaking spoken language assessment test, Linguaskill. Results demonstrate that end-to-end spoken GEC is possible within this architecture, but the lack of available data limits current performance compared to a system using large quantities of text-based GEC data. Conversely, end-to-end disfluency detection and removal, which is easier for the attention-based Whisper to learn, does outperform cascaded approaches. Additionally, the paper discusses the challenges of providing feedback to candidates when using end-to-end systems for spoken GEC.
L2 proficiency assessment using self-supervised speech representations
Nov 16, 2022There has been a growing demand for automated spoken language assessment systems in recent years. A standard pipeline for this process is to start with a speech recognition system and derive features, either hand-crafted or based on deep-learning, that exploit the transcription and audio. Though these approaches can yield high performance systems, they require speech recognition systems that can be used for L2 speakers, and preferably tuned to the specific form of test being deployed. Recently a self-supervised speech representation based scheme, requiring no speech recognition, was proposed. This work extends the initial analysis conducted on this approach to a large scale proficiency test, Linguaskill, that comprises multiple parts, each designed to assess different attributes of a candidate's speaking proficiency. The performance of the self-supervised, wav2vec 2.0, system is compared to a high performance hand-crafted assessment system and a BERT-based text system both of which use speech transcriptions. Though the wav2vec 2.0 based system is found to be sensitive to the nature of the response, it can be configured to yield comparable performance to systems requiring a speech transcription, and yields gains when appropriately combined with standard approaches.