 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Attributed Automatic Speech Recognition Using Speech Aware LLMS
Apr 13, 2026Speaker-Attributed Automatic Speech Recognition (SAA) enhances traditional ASR systems by incorporating relative speaker identity tags directly into the transcript (e.g., [Speaker 1]:, [Speaker 2]:). In this work, we extend the capabilities of Granite-speech, a state-of-the-art speech-aware Large Language Model (LLM) originally trained for transcription and translation. We demonstrate that it can be effectively adapted for SAA with only minimal architectural changes. Our core contribution is the introduction of speaker cluster identification tags (e.g., [Speaker 1 cluster 42]:) which are jointly trained with SAA to significantly improve accuracy. To address limitations in training data, we propose a data augmentation method that uses artificially concatenated multi-speaker conversations. Our approach is evaluated across multiple benchmarks and shows superior performance compared to conventional pipelines that sequentially perform speaker diarization followed by ASR.
Spoken question answering for visual queries
May 29, 2025Question answering (QA) systems are designed to answer natural language questions. Visual QA (VQA) and Spoken QA (SQA) systems extend the textual QA system to accept visual and spoken input respectively. This work aims to create a system that enables user interaction through both speech and images. That is achieved through the fusion of text, speech, and image modalities to tackle the task of spoken VQA (SVQA). The resulting multi-modal model has textual, visual, and spoken inputs and can answer spoken questions on images. Training and evaluating SVQA models requires a dataset for all three modalities, but no such dataset currently exists. We address this problem by synthesizing VQA datasets using two zero-shot TTS models. Our initial findings indicate that a model trained only with synthesized speech nearly reaches the performance of the upper-bounding model trained on textual QAs. In addition, we show that the choice of the TTS model has a minor impact on accuracy.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Speak While You Think: Streaming Speech Synthesis During Text Generation
Sep 20, 2023



Large Language Models (LLMs) demonstrate impressive capabilities, yet interaction with these models is mostly facilitated through text. Using Text-To-Speech to synthesize LLM outputs typically results in notable latency, which is impractical for fluent voice conversations. We propose LLM2Speech, an architecture to synthesize speech while text is being generated by an LLM which yields significant latency reduction. LLM2Speech mimics the predictions of a non-streaming teacher model while limiting the exposure to future context in order to enable streaming. It exploits the hidden embeddings of the LLM, a by-product of the text generation that contains informative semantic context. Experimental results show that LLM2Speech maintains the teacher's quality while reducing the latency to enable natural conversations.
Extending RNN-T-based speech recognition systems with emotion and language classification
Jul 28, 2022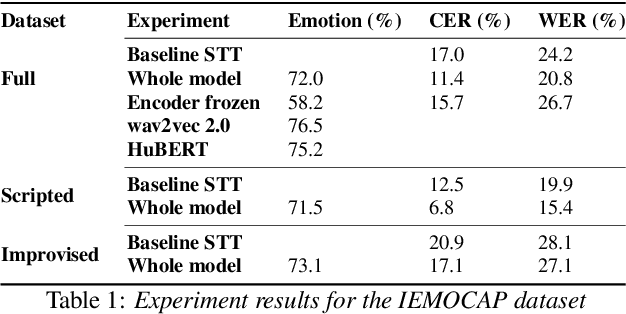
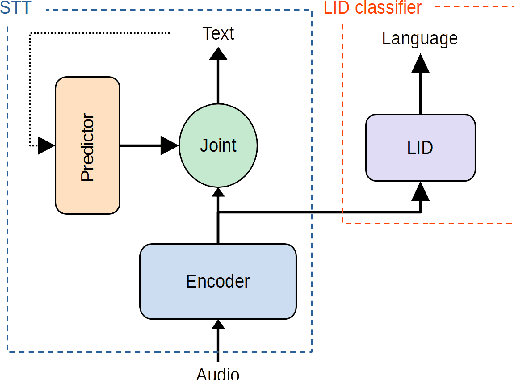
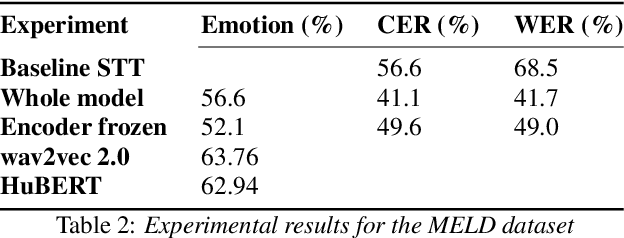
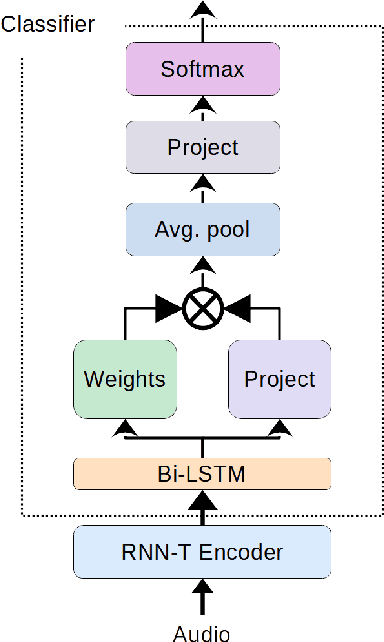
Speech transcription, emotion recognition, and language identification are usually considered to be three different tasks. Each one requires a different model with a different architecture and training process. We propose using a recurrent neural network transducer (RNN-T)-based speech-to-text (STT) system as a common component that can be used for emotion recognition and language identification as well as for speech recognition. Our work extends the STT system for emotion classification through minimal changes, and shows successful results on the IEMOCAP and MELD datasets. In addition, we demonstrate that by adding a lightweight component to the RNN-T module, it can also be used for language identification. In our evaluations, this new classifier demonstrates state-of-the-art accuracy for the NIST-LRE-07 dataset.
A new data augmentation method for intent classification enhancement and its application on spoken conversation datasets
Feb 21, 2022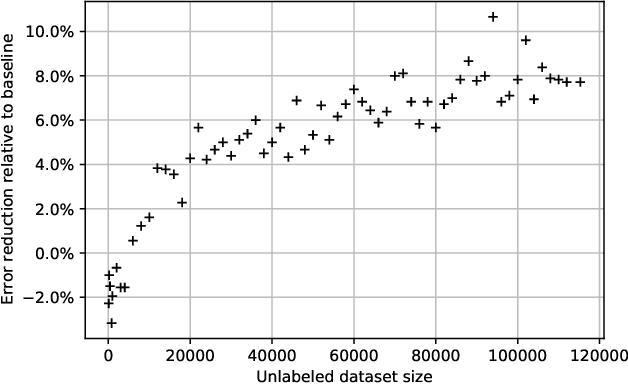
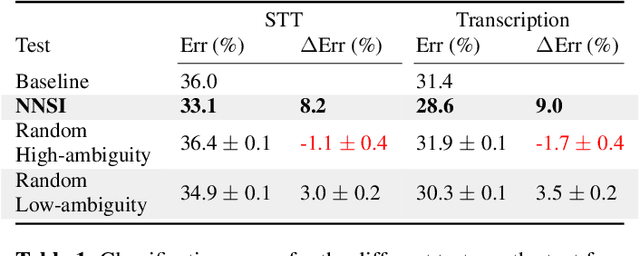
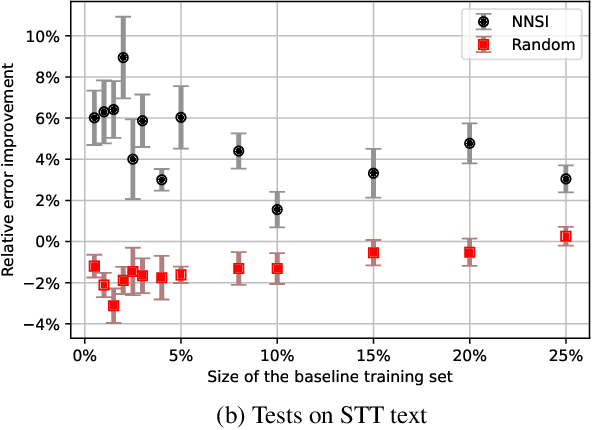
Intent classifiers are vital to the successful operation of virtual agent systems. This is especially so in voice activated systems where the data can be noisy with many ambiguous directions for user intents. Before operation begins, these classifiers are generally lacking in real-world training data. Active learning is a common approach used to help label large amounts of collected user input. However, this approach requires many hours of manual labeling work. We present the Nearest Neighbors Scores Improvement (NNSI) algorithm for automatic data selection and labeling. The NNSI reduces the need for manual labeling by automatically selecting highly-ambiguous samples and labeling them with high accuracy. This is done by integrating the classifier's output from a semantically similar group of text samples. The labeled samples can then be added to the training set to improve the accuracy of the classifier. We demonstrated the use of NNSI on two large-scale, real-life voice conversation systems. Evaluation of our results showed that our method was able to select and label useful samples with high accuracy. Adding these new samples to the training data significantly improved the classifiers and reduced error rates by up to 10%.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
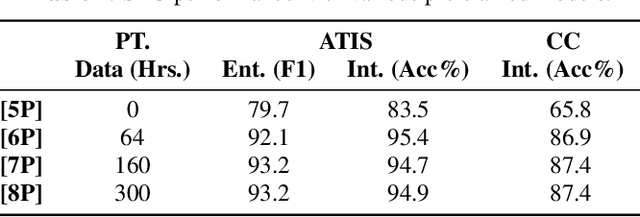


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems
Oct 08, 2020

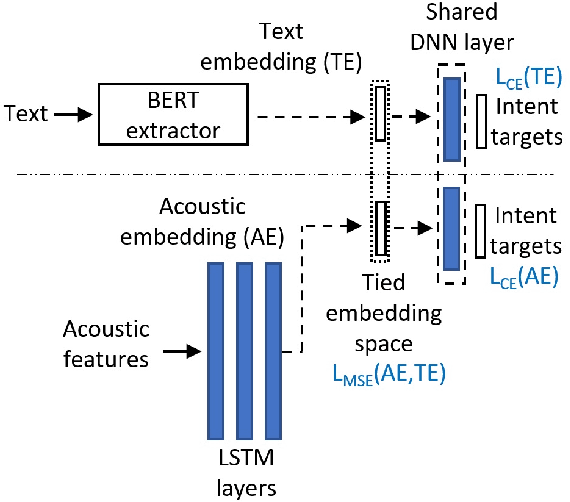
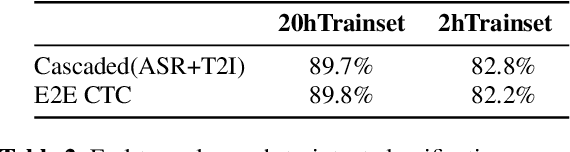
Training an end-to-end (E2E) neural network speech-to-intent (S2I) system that directly extracts intents from speech requires large amounts of intent-labeled speech data, which is time consuming and expensive to collect. Initializing the S2I model with an ASR model trained on copious speech data can alleviate data sparsity. In this paper, we attempt to leverage NLU text resources. We implemented a CTC-based S2I system that matches the performance of a state-of-the-art, traditional cascaded SLU system. We performed controlled experiments with varying amounts of speech and text training data. When only a tenth of the original data is available, intent classification accuracy degrades by 7.6% absolute. Assuming we have additional text-to-intent data (without speech) available, we investigated two techniques to improve the S2I system: (1) transfer learning, in which acoustic embeddings for intent classification are tied to fine-tuned BERT text embeddings; and (2) data augmentation, in which the text-to-intent data is converted into speech-to-intent data using a multi-speaker text-to-speech system. The proposed approaches recover 80% of performance lost due to using limited intent-labeled speech.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020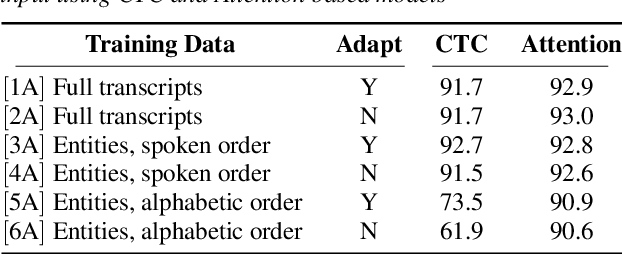
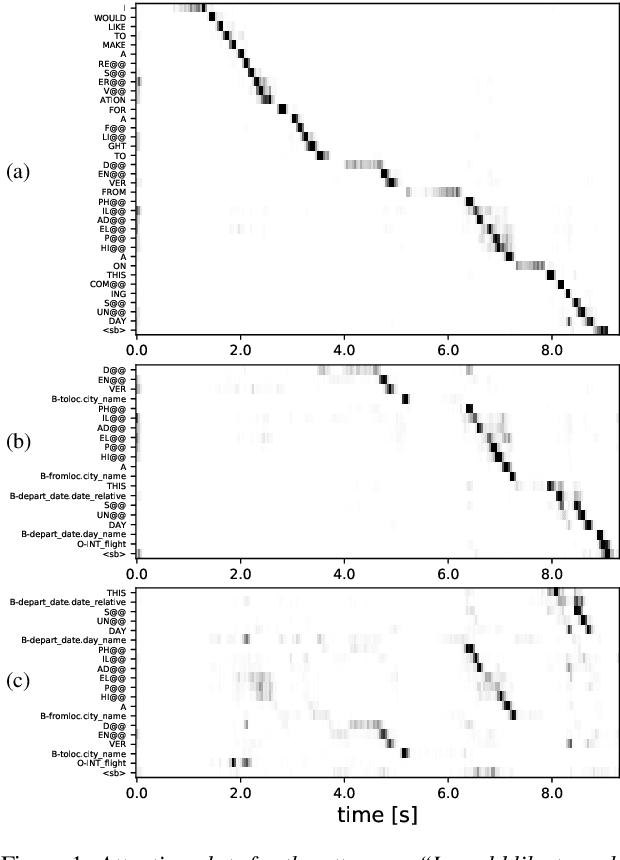

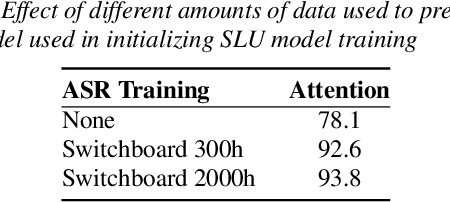
An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.