 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Letter-Based Speech Recognition with Gated ConvNets
Dec 22, 2017
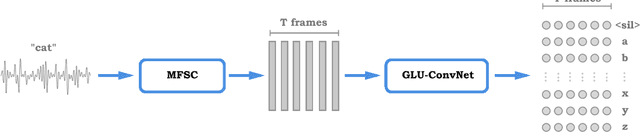

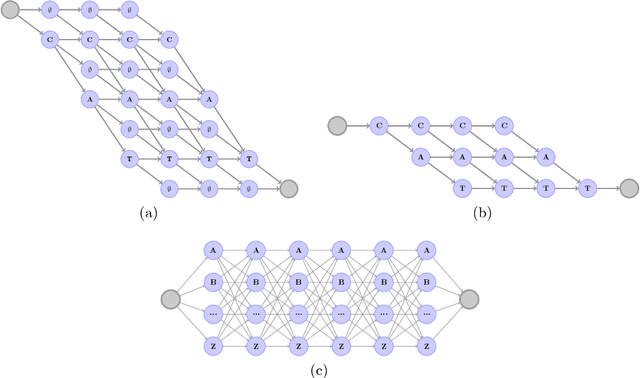

In this paper we introduce a new speech recognition system, leveraging a simple letter-based ConvNet acoustic model. The acoustic model requires -- only audio transcription for training -- no alignment annotations, nor any forced alignment step is needed. At inference, our decoder takes only a word list and a language model, and is fed with letter scores from the -- acoustic model -- no phonetic word lexicon is needed. Key ingredients for the acoustic model are Gated Linear Units and high dropout. We show near state-of-the-art results in word error rate on the LibriSpeech corpus using log-mel filterbanks, both on the "clean" and "other" configurations.
CTL-MTNet: A Novel CapsNet and Transfer Learning-Based Mixed Task Net for the Single-Corpus and Cross-Corpus Speech Emotion Recognition
Jul 18, 2022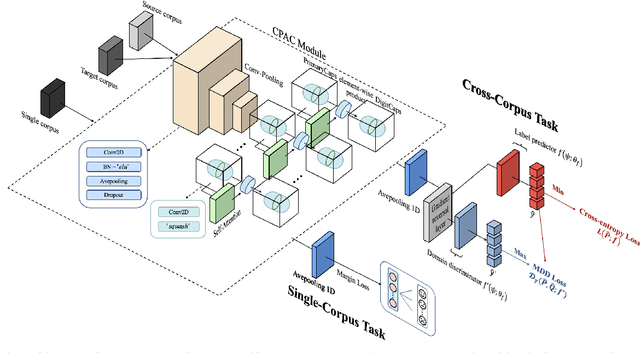
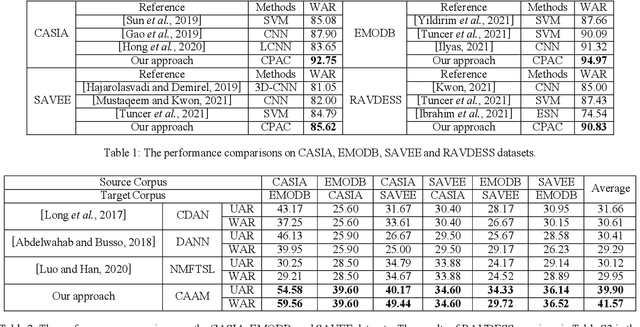
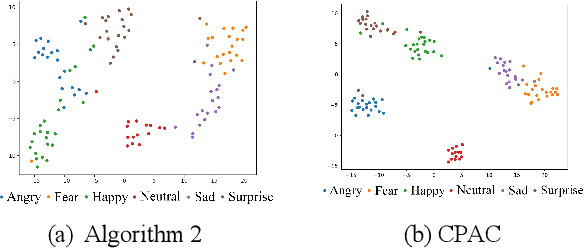

Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. An essential challenge in SER is to extract common attributes from different speakers or languages, especially when a specific source corpus has to be trained to recognize the unknown data coming from another speech corpus. To address this challenge, a Capsule Network (CapsNet) and Transfer Learning based Mixed Task Net (CTLMTNet) are proposed to deal with both the singlecorpus and cross-corpus SER tasks simultaneously in this paper. For the single-corpus task, the combination of Convolution-Pooling and Attention CapsNet module CPAC) is designed by embedding the self-attention mechanism to the CapsNet, guiding the module to focus on the important features that can be fed into different capsules. The extracted high-level features by CPAC provide sufficient discriminative ability. Furthermore, to handle the cross-corpus task, CTL-MTNet employs a Corpus Adaptation Adversarial Module (CAAM) by combining CPAC with Margin Disparity Discrepancy (MDD), which can learn the domain-invariant emotion representations through extracting the strong emotion commonness. Experiments including ablation studies and visualizations on both singleand cross-corpus tasks using four well-known SER datasets in different languages are conducted for performance evaluation and comparison. The results indicate that in both tasks the CTL-MTNet showed better performance in all cases compared to a number of state-of-the-art methods. The source code and the supplementary materials are available at: https://github.com/MLDMXM2017/CTLMTNet
XTREME-S: Evaluating Cross-lingual Speech Representations
Apr 13, 2022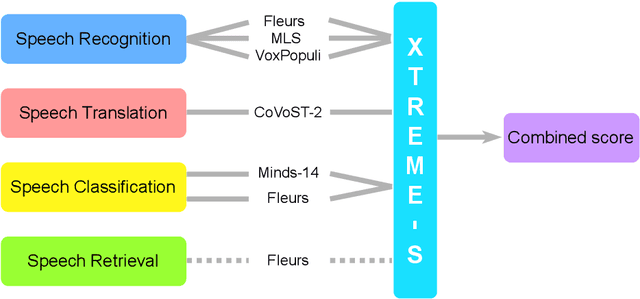
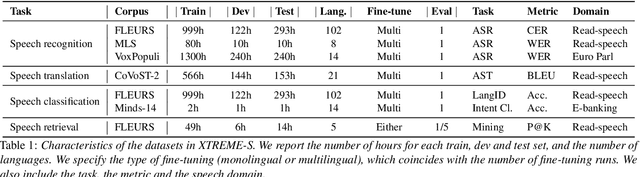
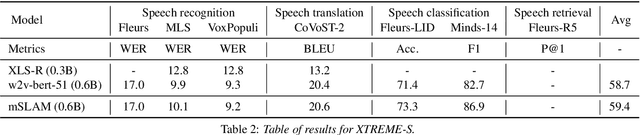
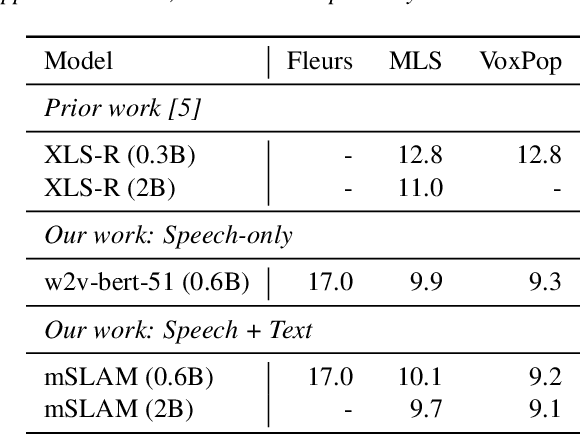
We introduce XTREME-S, a new benchmark to evaluate universal cross-lingual speech representations in many languages. XTREME-S covers four task families: speech recognition, classification, speech-to-text translation and retrieval. Covering 102 languages from 10+ language families, 3 different domains and 4 task families, XTREME-S aims to simplify multilingual speech representation evaluation, as well as catalyze research in "universal" speech representation learning. This paper describes the new benchmark and establishes the first speech-only and speech-text baselines using XLS-R and mSLAM on all downstream tasks. We motivate the design choices and detail how to use the benchmark. Datasets and fine-tuning scripts are made easily accessible at https://hf.co/datasets/google/xtreme_s.
NN-grams: Unifying neural network and n-gram language models for Speech Recognition
Jun 23, 2016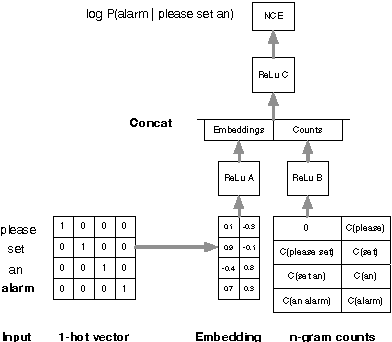


We present NN-grams, a novel, hybrid language model integrating n-grams and neural networks (NN) for speech recognition. The model takes as input both word histories as well as n-gram counts. Thus, it combines the memorization capacity and scalability of an n-gram model with the generalization ability of neural networks. We report experiments where the model is trained on 26B words. NN-grams are efficient at run-time since they do not include an output soft-max layer. The model is trained using noise contrastive estimation (NCE), an approach that transforms the estimation problem of neural networks into one of binary classification between data samples and noise samples. We present results with noise samples derived from either an n-gram distribution or from speech recognition lattices. NN-grams outperforms an n-gram model on an Italian speech recognition dictation task.
Attentive Fusion Enhanced Audio-Visual Encoding for Transformer Based Robust Speech Recognition
Aug 06, 2020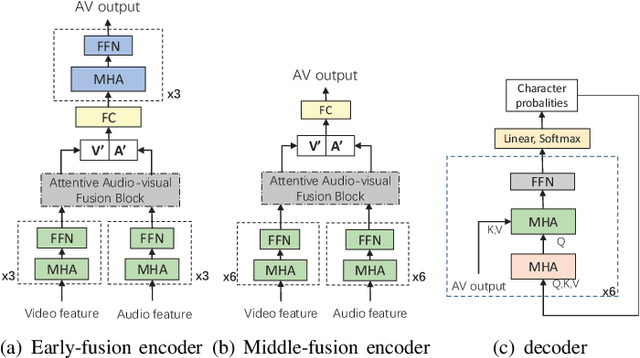
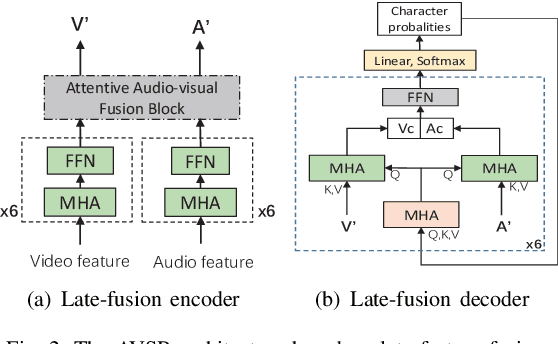
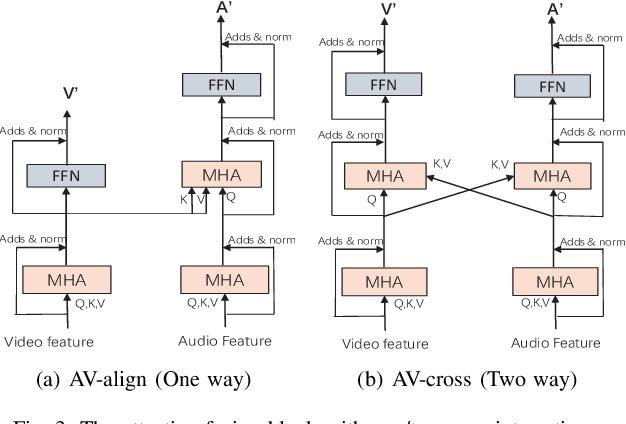
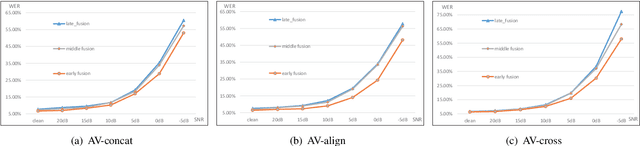
Audio-visual information fusion enables a performance improvement in speech recognition performed in complex acoustic scenarios, e.g., noisy environments. It is required to explore an effective audio-visual fusion strategy for audiovisual alignment and modality reliability. Different from the previous end-to-end approaches where the audio-visual fusion is performed after encoding each modality, in this paper we propose to integrate an attentive fusion block into the encoding process. It is shown that the proposed audio-visual fusion method in the encoder module can enrich audio-visual representations, as the relevance between the two modalities is leveraged. In line with the transformer-based architecture, we implement the embedded fusion block using a multi-head attention based audiovisual fusion with one-way or two-way interactions. The proposed method can sufficiently combine the two streams and weaken the over-reliance on the audio modality. Experiments on the LRS3-TED dataset demonstrate that the proposed method can increase the recognition rate by 0.55%, 4.51% and 4.61% on average under the clean, seen and unseen noise conditions, respectively, compared to the state-of-the-art approach.
Gaussian Kernelized Self-Attention for Long Sequence Data and Its Application to CTC-based Speech Recognition
Feb 18, 2021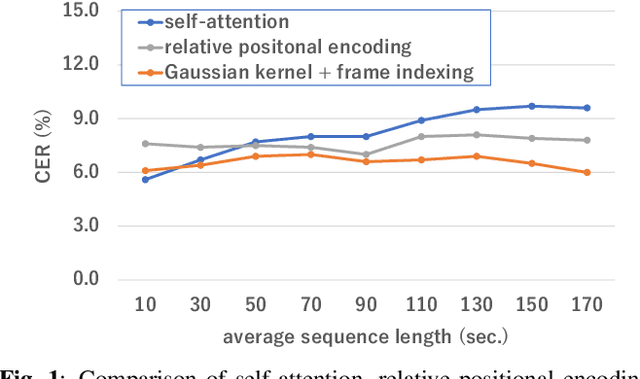
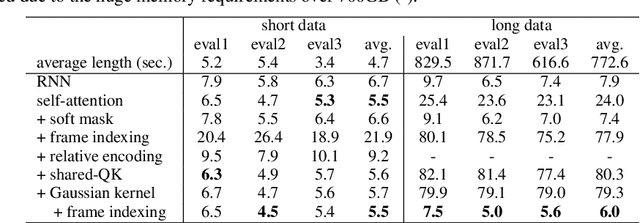
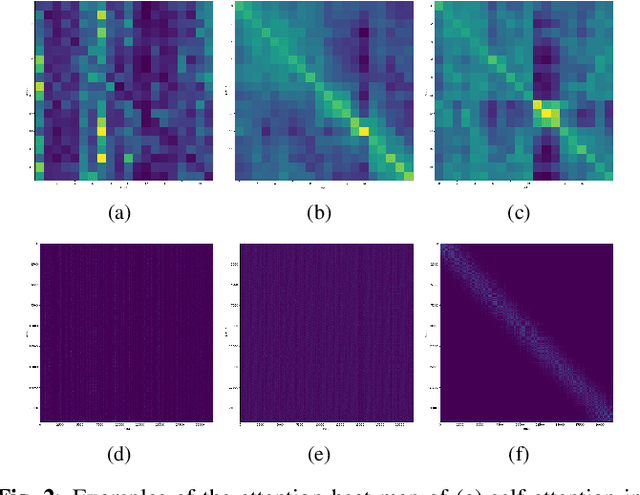
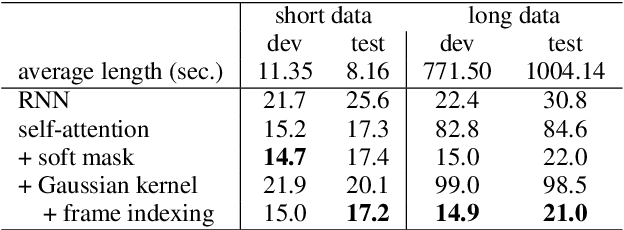
Self-attention (SA) based models have recently achieved significant performance improvements in hybrid and end-to-end automatic speech recognition (ASR) systems owing to their flexible context modeling capability. However, it is also known that the accuracy degrades when applying SA to long sequence data. This is mainly due to the length mismatch between the inference and training data because the training data are usually divided into short segments for efficient training. To mitigate this mismatch, we propose a new architecture, which is a variant of the Gaussian kernel, which itself is a shift-invariant kernel. First, we mathematically demonstrate that self-attention with shared weight parameters for queries and keys is equivalent to a normalized kernel function. By replacing this kernel function with the proposed Gaussian kernel, the architecture becomes completely shift-invariant with the relative position information embedded using a frame indexing technique. The proposed Gaussian kernelized SA was applied to connectionist temporal classification (CTC) based ASR. An experimental evaluation with the Corpus of Spontaneous Japanese (CSJ) and TEDLIUM 3 benchmarks shows that the proposed SA achieves a significant improvement in accuracy (e.g., from 24.0% WER to 6.0% in CSJ) in long sequence data without any windowing techniques.
Contextual Speech Recognition with Difficult Negative Training Examples
Oct 29, 2018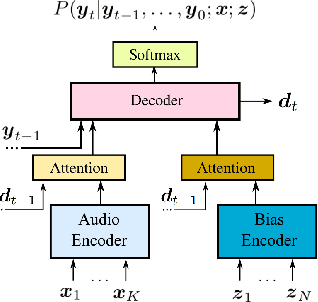
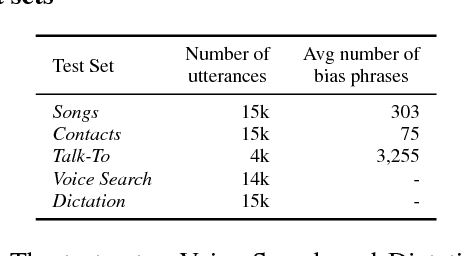
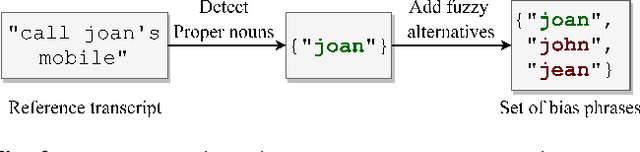
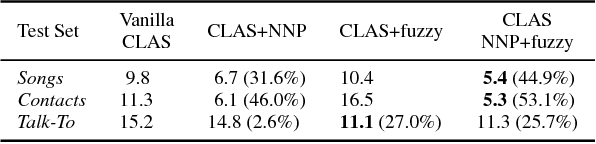
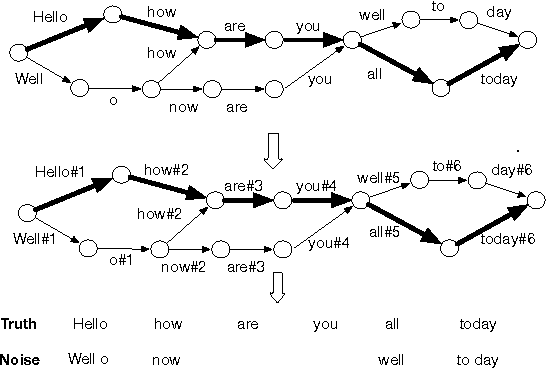
Improving the representation of contextual information is key to unlocking the potential of end-to-end (E2E) automatic speech recognition (ASR). In this work, we present a novel and simple approach for training an ASR context mechanism with difficult negative examples. The main idea is to focus on proper nouns (e.g., unique entities such as names of people and places) in the reference transcript, and use phonetically similar phrases as negative examples, encouraging the neural model to learn more discriminative representations. We apply our approach to an end-to-end contextual ASR model that jointly learns to transcribe and select the correct context items, and show that our proposed method gives up to $53.1\%$ relative improvement in word error rate (WER) across several benchmarks.
Interpretable Dysarthric Speaker Adaptation based on Optimal-Transport
Mar 14, 2022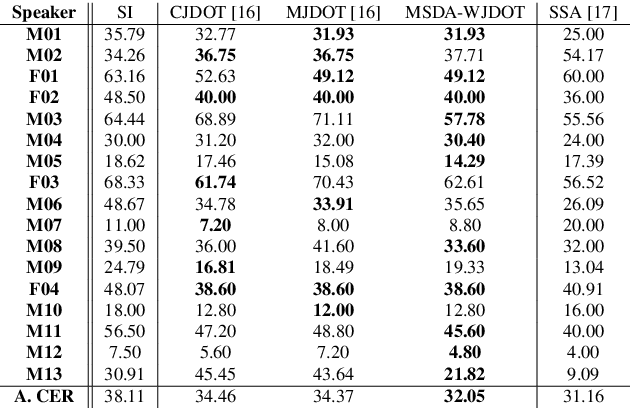
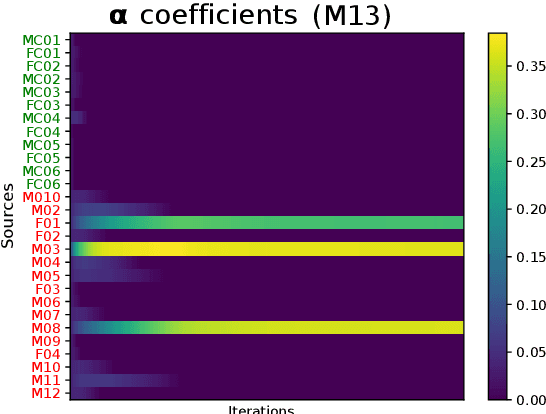
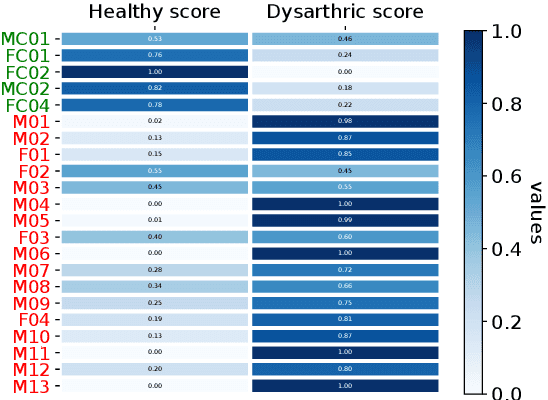
This work addresses the mismatch problem between the distribution of training data (source) and testing data (target), in the challenging context of dysarthric speech recognition. We focus on Speaker Adaptation (SA) in command speech recognition, where data from multiple sources (i.e., multiple speakers) are available. Specifically, we propose an unsupervised Multi-Source Domain Adaptation (MSDA) algorithm based on optimal-transport, called MSDA via Weighted Joint Optimal Transport (MSDA-WJDOT). We achieve a Command Error Rate relative reduction of 16% and 7% over the speaker-independent model and the best competitor method, respectively. The strength of the proposed approach is that, differently from any other existing SA method, it offers an interpretable model that can also be exploited, in this context, to diagnose dysarthria without any specific training. Indeed, it provides a closeness measure between the target and the source speakers, reflecting their similarity in terms of speech characteristics. Based on the similarity between the target speaker and the healthy/dysarthric source speakers, we then define the healthy/dysarthric score of the target speaker that we leverage to perform dysarthria detection. This approach does not require any additional training and achieves a 95% accuracy in the dysarthria diagnosis.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Feb 20, 2023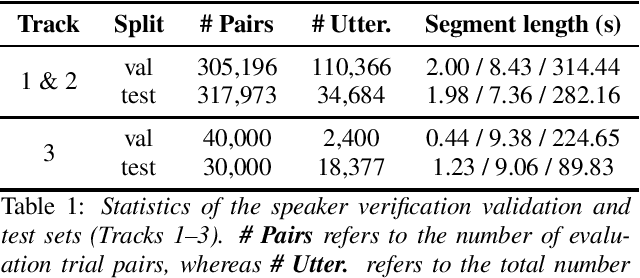
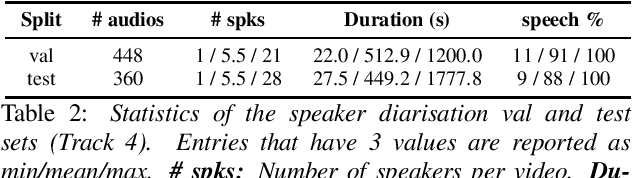
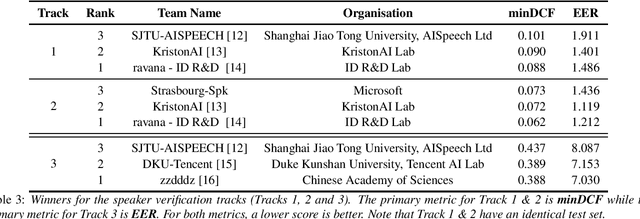

This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.
Serialized Output Training for End-to-End Overlapped Speech Recognition
Mar 28, 2020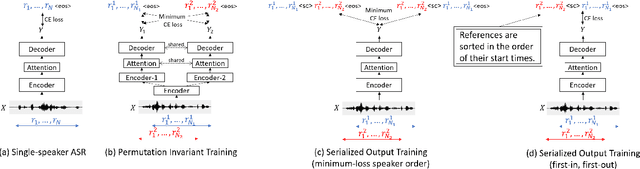
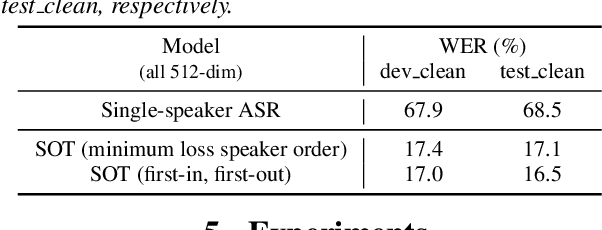
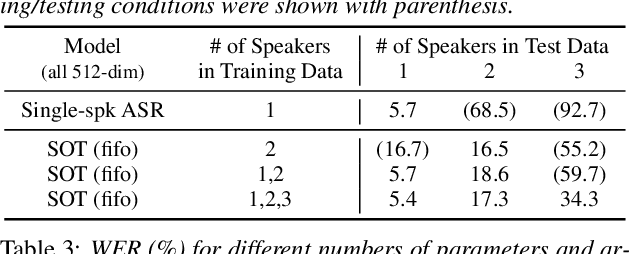
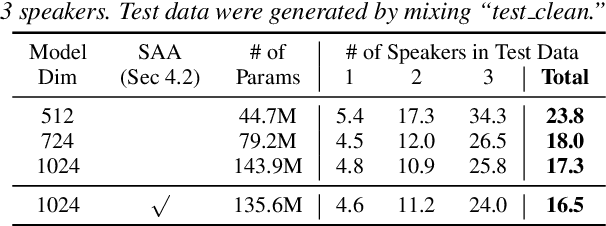
This paper proposes serialized output training (SOT), a novel framework for multi-speaker overlapped speech recognition based on an attention-based encoder-decoder approach. Instead of having multiple output layers as with the permutation invariant training (PIT), SOT uses a model with only one output layer that generates the transcriptions of multiple speakers one after another. The attention and decoder modules take care of producing multiple transcriptions from overlapped speech. SOT has two advantages over PIT: (1) no limitation in the maximum number of speakers, and (2) an ability to model the dependencies among outputs for different speakers. We also propose a simple trick to reduce the complexity of processing each training sample from $O(S!)$ to $O(1)$, where $S$ is the number of the speakers in the training sample, by using the start times of the constituent source utterances. Experimental results on LibriSpeech corpus show that the SOT models can transcribe overlapped speech with variable numbers of speakers significantly better than PIT-based models. We also show that the SOT models can accurately count the number of speakers in the input audio.