 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Toolkit for Joint Speaker Diarization and Identification with Application to Speaker-Attributed ASR
Sep 09, 2024

We present a modular toolkit to perform joint speaker diarization and speaker identification. The toolkit can leverage on multiple models and algorithms which are defined in a configuration file. Such flexibility allows our system to work properly in various conditions (e.g., multiple registered speakers' sets, acoustic conditions and languages) and across application domains (e.g. media monitoring, institutional, speech analytics). In this demonstration we show a practical use-case in which speaker-related information is used jointly with automatic speech recognition engines to generate speaker-attributed transcriptions. To achieve that, we employ a user-friendly web-based interface to process audio and video inputs with the chosen configuration.
* Show and Tell paper. Presented at Interspeech 2024
Exploring Spoken Language Identification Strategies for Automatic Transcription of Multilingual Broadcast and Institutional Speech
Jun 13, 2024


This paper addresses spoken language identification (SLI) and speech recognition of multilingual broadcast and institutional speech, real application scenarios that have been rarely addressed in the SLI literature. Observing that in these domains language changes are mostly associated with speaker changes, we propose a cascaded system consisting of speaker diarization and language identification and compare it with more traditional language identification and language diarization systems. Results show that the proposed system often achieves lower language classification and language diarization error rates (up to 10% relative language diarization error reduction and 60% relative language confusion reduction) and leads to lower WERs on multilingual test sets (more than 8% relative WER reduction), while at the same time does not negatively affect speech recognition on monolingual audio (with an absolute WER increase between 0.1% and 0.7% w.r.t. monolingual ASR).
Interpretable Dysarthric Speaker Adaptation based on Optimal-Transport
Mar 14, 2022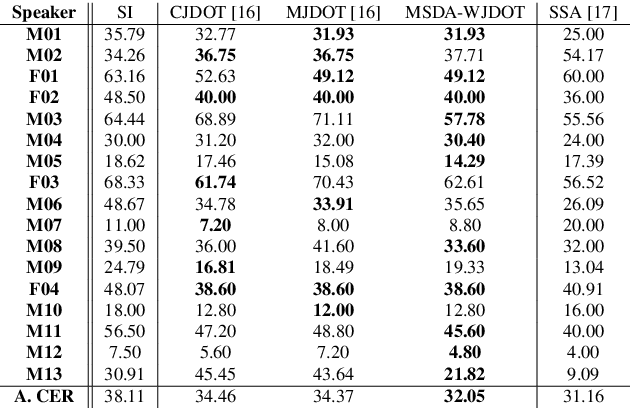
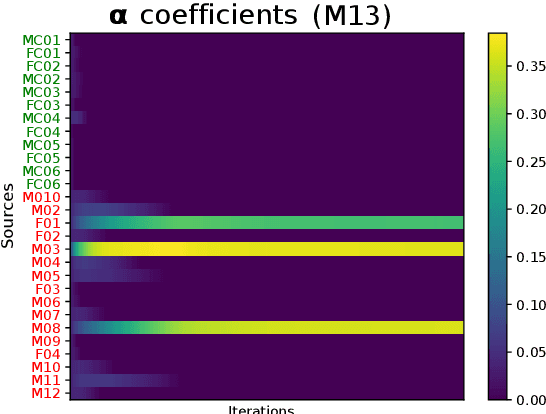
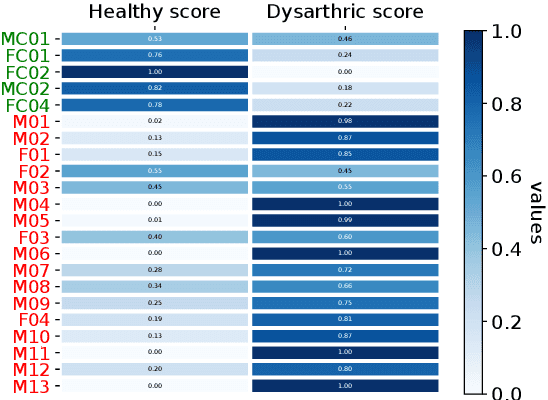
This work addresses the mismatch problem between the distribution of training data (source) and testing data (target), in the challenging context of dysarthric speech recognition. We focus on Speaker Adaptation (SA) in command speech recognition, where data from multiple sources (i.e., multiple speakers) are available. Specifically, we propose an unsupervised Multi-Source Domain Adaptation (MSDA) algorithm based on optimal-transport, called MSDA via Weighted Joint Optimal Transport (MSDA-WJDOT). We achieve a Command Error Rate relative reduction of 16% and 7% over the speaker-independent model and the best competitor method, respectively. The strength of the proposed approach is that, differently from any other existing SA method, it offers an interpretable model that can also be exploited, in this context, to diagnose dysarthria without any specific training. Indeed, it provides a closeness measure between the target and the source speakers, reflecting their similarity in terms of speech characteristics. Based on the similarity between the target speaker and the healthy/dysarthric source speakers, we then define the healthy/dysarthric score of the target speaker that we leverage to perform dysarthria detection. This approach does not require any additional training and achieves a 95% accuracy in the dysarthria diagnosis.
EasyCall corpus: a dysarthric speech dataset
Apr 06, 2021
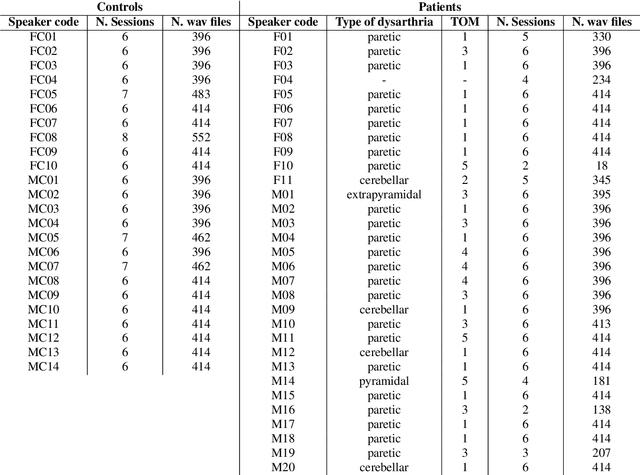
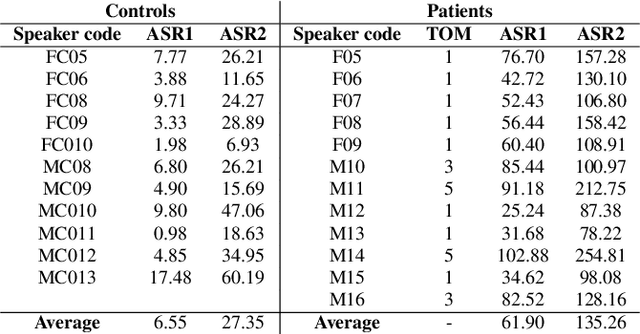
This paper introduces a new dysarthric speech command dataset in Italian, called EasyCall corpus. The dataset consists of 21386 audio recordings from 24 healthy and 31 dysarthric speakers, whose individual degree of speech impairment was assessed by neurologists through the Therapy Outcome Measure. The corpus aims at providing a resource for the development of ASR-based assistive technologies for patients with dysarthria. In particular, it may be exploited to develop a voice-controlled contact application for commercial smartphones, aiming at improving dysarthric patients' ability to communicate with their family and caregivers. Before recording the dataset, participants were administered a survey to evaluate which commands are more likely to be employed by dysarthric individuals in a voice-controlled contact application. In addition, the dataset includes a list of non-commands (i.e., words near/inside commands or phonetically close to commands) that can be leveraged to build a more robust command recognition system. At present commercial ASR systems perform poorly on the EasyCall Corpus as we report in this paper. This result corroborates the need for dysarthric speech corpora for developing effective assistive technologies. To the best of our knowledge, this database represents the richest corpus of dysarthric speech to date.
Optimal Transport-based Adaptation in Dysarthric Speech Tasks
Apr 06, 2021
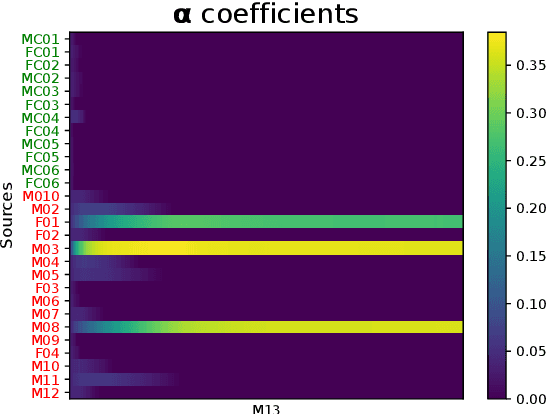
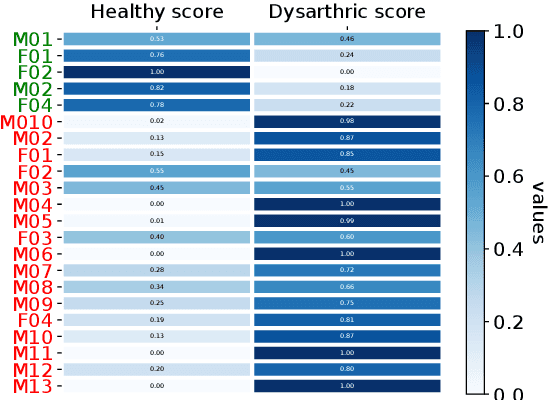
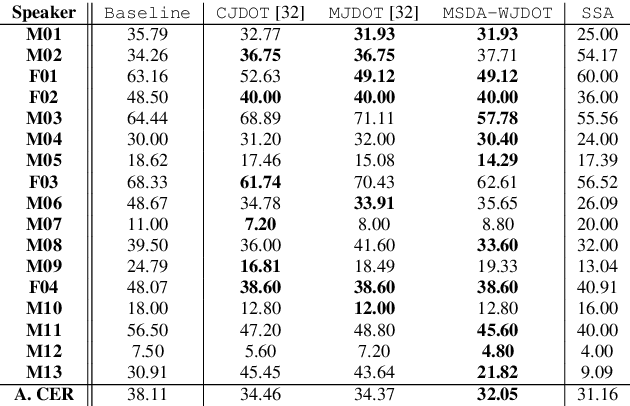
In many real-world applications, the mismatch between distributions of training data (source) and test data (target) significantly degrades the performance of machine learning algorithms. In speech data, causes of this mismatch include different acoustic environments or speaker characteristics. In this paper, we address this issue in the challenging context of dysarthric speech, by multi-source domain/speaker adaptation (MSDA/MSSA). Specifically, we propose the use of an optimal-transport based approach, called MSDA via Weighted Joint Optimal Transport (MSDA-WDJOT). We confront the mismatch problem in dysarthria detection for which the proposed approach outperforms both the Baseline and the state-of-the-art MSDA models, improving the detection accuracy of 0.9% over the best competitor method. We then employ MSDA-WJDOT for dysarthric speaker adaptation in command speech recognition. This provides a Command Error Rate relative reduction of 16% and 7% over the baseline and the best competitor model, respectively. Interestingly, MSDA-WJDOT provides a similarity score between the source and the target, i.e. between speakers in this case. We leverage this similarity measure to define a Dysarthric and Healthy score of the target speaker and diagnose the dysarthria with an accuracy of 95%.
Audio-Visual Target Speaker Extraction on Multi-Talker Environment using Event-Driven Cameras
Dec 05, 2019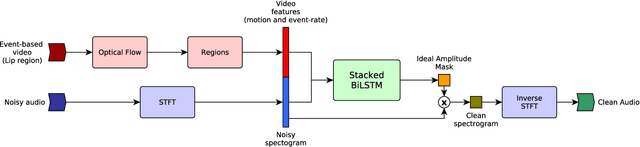

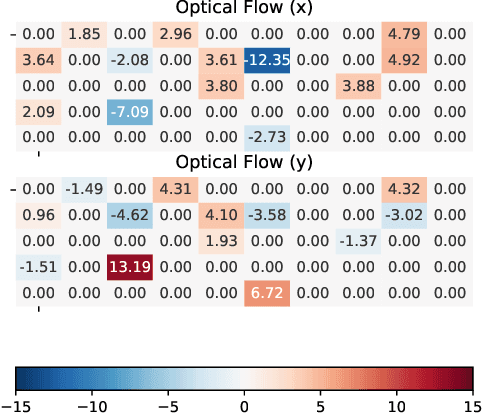
In this work, we propose a new method to address audio-visual target speaker extraction in multi-talker environments using event-driven cameras. All audio-visual speech separation approaches use a frame-based video to extract visual features. However, these frame-based cameras usually work at 30 frames per second. This limitation makes it difficult to process an audio-visual signal with low latency. In order to overcome this limitation, we propose using event-driven cameras due to their high temporal resolution and low latency. Recent work showed that the use of landmark motion features is very important in order to get good results on audio-visual speech separation. Thus, we use event-driven vision sensors from which the extraction of motion is available at lower latency computational cost. A stacked Bidirectional LSTM is trained to predict an Ideal Amplitude Mask before post-processing to get a clean audio signal. The performance of our model is close to those yielded in frame-based fashion.
Joined Audio-Visual Speech Enhancement and Recognition in the Cocktail Party: The Tug Of War Between Enhancement and Recognition Losses
Apr 16, 2019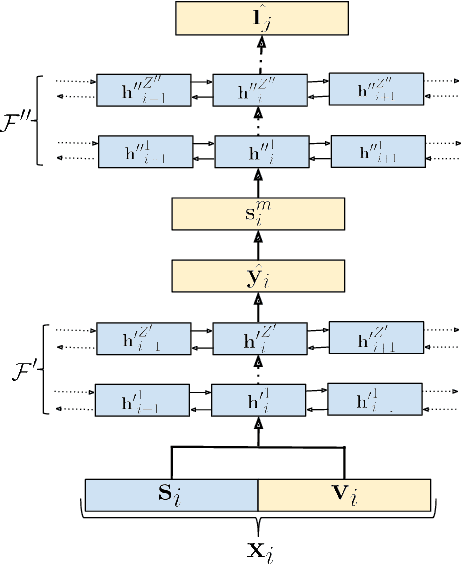
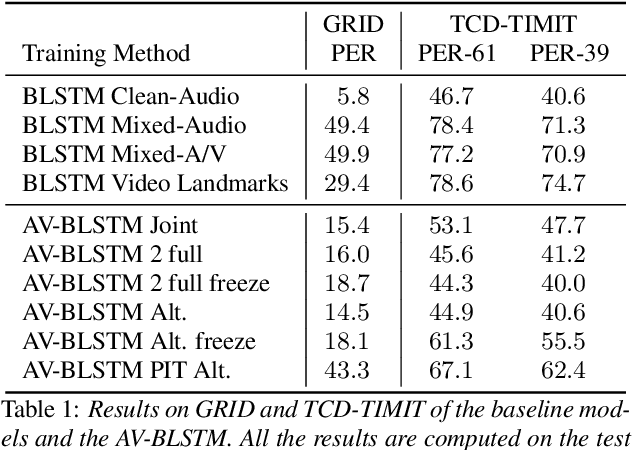
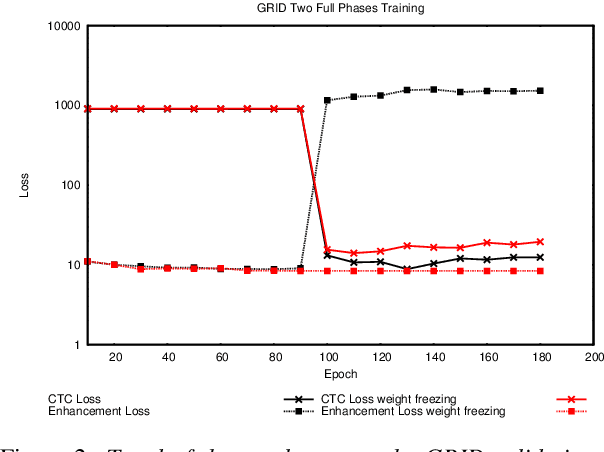
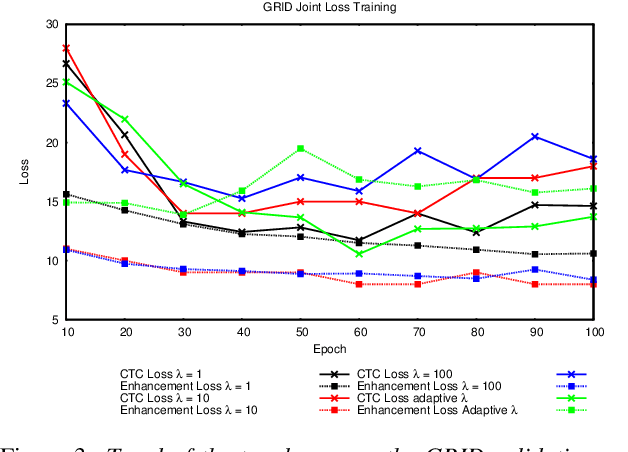
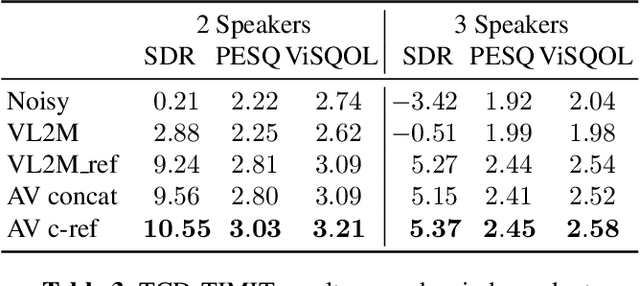
In this paper we propose an end-to-end LSTM-based model that performs single-channel speech enhancement and phone recognition in a cocktail party scenario where visual information of the target speaker is available. In the speech enhancement phase the proposed system uses a "visual attention" signal of the speaker of interest to extract her speech from the input mixed-speech signal, while in the ASR phase it recognizes her phone sequence through a phone recognizer trained with a CTC loss. It is well known that learning multiple related tasks from data simultaneously can improve performance than learning these tasks independently, therefore we decided to train the model by optimizing both tasks at the same time. This allowed us also to explore whether (and how) this joint optimization leads to better results. We analyzed different training strategies that reveal some interesting and unexpected behaviors. In particular, the experiments demonstrated that during optimization of the ASR phase the speech enhancement capability of the model significantly decreases and vice-versa. We evaluated our approach on mixed-speech versions of GRID and TCD-TIMIT. The obtained results show a remarkable drop of the Phone Error Rate (PER) compared to the audio-visual baseline models trained only to perform phone recognition phase.
Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
Nov 06, 2018
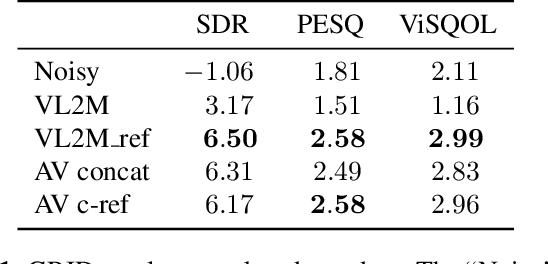
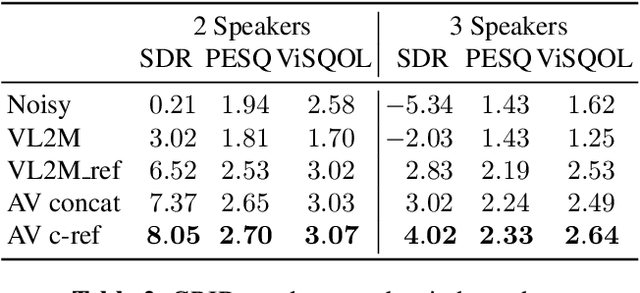
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset). The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) landmark motion features are very effective features for this task, (ii) similarly to previous work, reconstruction of the target speaker's spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. To the best of our knowledge, our proposed models are the first models trained and evaluated on the limited size GRID and TCD-TIMIT datasets, that achieve speaker-independent speech enhancement in a multi-talker setting.
Improving generalization of vocal tract feature reconstruction: from augmented acoustic inversion to articulatory feature reconstruction without articulatory data
Sep 04, 2018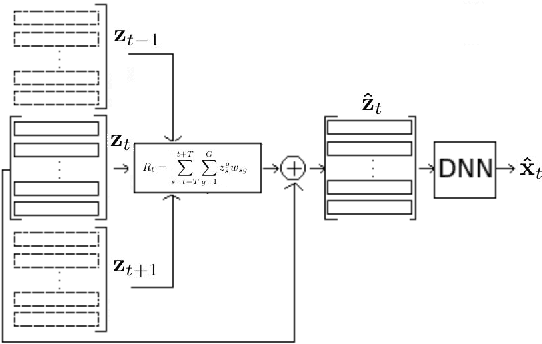
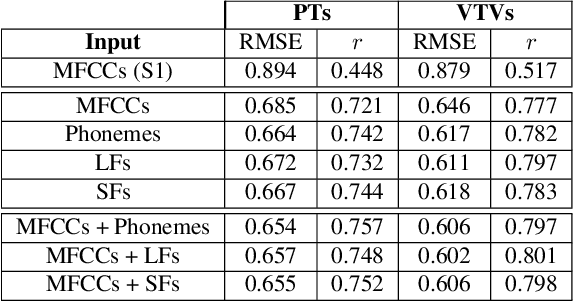
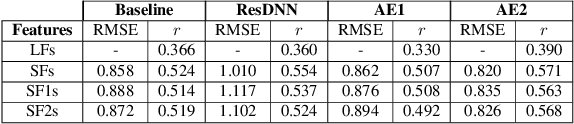
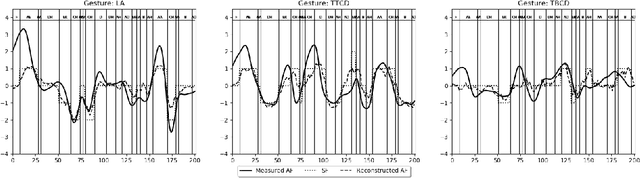
We address the problem of reconstructing articulatory movements, given audio and/or phonetic labels. The scarce availability of multi-speaker articulatory data makes it difficult to learn a reconstruction that generalizes to new speakers and across datasets. We first consider the XRMB dataset where audio, articulatory measurements and phonetic transcriptions are available. We show that phonetic labels, used as input to deep recurrent neural networks that reconstruct articulatory features, are in general more helpful than acoustic features in both matched and mismatched training-testing conditions. In a second experiment, we test a novel approach that attempts to build articulatory features from prior articulatory information extracted from phonetic labels. Such approach recovers vocal tract movements directly from an acoustic-only dataset without using any articulatory measurement. Results show that articulatory features generated by this approach can correlate up to 0.59 Pearson product-moment correlation with measured articulatory features.