 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
DiarizationLM: Speaker Diarization Post-Processing with Large Language Models
Jan 16, 2024
In this paper, we introduce DiarizationLM, a framework to leverage large language models (LLM) to post-process the outputs from a speaker diarization system. Various goals can be achieved with the proposed framework, such as improving the readability of the diarized transcript, or reducing the word diarization error rate (WDER). In this framework, the outputs of the automatic speech recognition (ASR) and speaker diarization systems are represented as a compact textual format, which is included in the prompt to an optionally finetuned LLM. The outputs of the LLM can be used as the refined diarization results with the desired enhancement. As a post-processing step, this framework can be easily applied to any off-the-shelf ASR and speaker diarization systems without retraining existing components. Our experiments show that a finetuned PaLM 2-S model can reduce the WDER by rel. 55.5% on the Fisher telephone conversation dataset, and rel. 44.9% on the Callhome English dataset.
Multi-Modal Emotion Recognition by Text, Speech and Video Using Pretrained Transformers
Feb 11, 2024Due to the complex nature of human emotions and the diversity of emotion representation methods in humans, emotion recognition is a challenging field. In this research, three input modalities, namely text, audio (speech), and video, are employed to generate multimodal feature vectors. For generating features for each of these modalities, pre-trained Transformer models with fine-tuning are utilized. In each modality, a Transformer model is used with transfer learning to extract feature and emotional structure. These features are then fused together, and emotion recognition is performed using a classifier. To select an appropriate fusion method and classifier, various feature-level and decision-level fusion techniques have been experimented with, and ultimately, the best model, which combines feature-level fusion by concatenating feature vectors and classification using a Support Vector Machine on the IEMOCAP multimodal dataset, achieves an accuracy of 75.42%. Keywords: Multimodal Emotion Recognition, IEMOCAP, Self-Supervised Learning, Transfer Learning, Transformer.
End to end Hindi to English speech conversion using Bark, mBART and a finetuned XLSR Wav2Vec2
Jan 11, 2024Speech has long been a barrier to effective communication and connection, persisting as a challenge in our increasingly interconnected world. This research paper introduces a transformative solution to this persistent obstacle an end-to-end speech conversion framework tailored for Hindi-to-English translation, culminating in the synthesis of English audio. By integrating cutting-edge technologies such as XLSR Wav2Vec2 for automatic speech recognition (ASR), mBART for neural machine translation (NMT), and a Text-to-Speech (TTS) synthesis component, this framework offers a unified and seamless approach to cross-lingual communication. We delve into the intricate details of each component, elucidating their individual contributions and exploring the synergies that enable a fluid transition from spoken Hindi to synthesized English audio.
Frame-level emotional state alignment method for speech emotion recognition
Dec 27, 2023Speech emotion recognition (SER) systems aim to recognize human emotional state during human-computer interaction. Most existing SER systems are trained based on utterance-level labels. However, not all frames in an audio have affective states consistent with utterance-level label, which makes it difficult for the model to distinguish the true emotion of the audio and perform poorly. To address this problem, we propose a frame-level emotional state alignment method for SER. First, we fine-tune HuBERT model to obtain a SER system with task-adaptive pretraining (TAPT) method, and extract embeddings from its transformer layers to form frame-level pseudo-emotion labels with clustering. Then, the pseudo labels are used to pretrain HuBERT. Hence, the each frame output of HuBERT has corresponding emotional information. Finally, we fine-tune the above pretrained HuBERT for SER by adding an attention layer on the top of it, which can focus only on those frames that are emotionally more consistent with utterance-level label. The experimental results performed on IEMOCAP indicate that our proposed method performs better than state-of-the-art (SOTA) methods.
Improving ASR Contextual Biasing with Guided Attention
Jan 16, 2024In this paper, we propose a Guided Attention (GA) auxiliary training loss, which improves the effectiveness and robustness of automatic speech recognition (ASR) contextual biasing without introducing additional parameters. A common challenge in previous literature is that the word error rate (WER) reduction brought by contextual biasing diminishes as the number of bias phrases increases. To address this challenge, we employ a GA loss as an additional training objective besides the Transducer loss. The proposed GA loss aims to teach the cross attention how to align bias phrases with text tokens or audio frames. Compared to studies with similar motivations, the proposed loss operates directly on the cross attention weights and is easier to implement. Through extensive experiments based on Conformer Transducer with Contextual Adapter, we demonstrate that the proposed method not only leads to a lower WER but also retains its effectiveness as the number of bias phrases increases. Specifically, the GA loss decreases the WER of rare vocabularies by up to 19.2% on LibriSpeech compared to the contextual biasing baseline, and up to 49.3% compared to a vanilla Transducer.
Revisiting Self-supervised Learning of Speech Representation from a Mutual Information Perspective
Jan 16, 2024Existing studies on self-supervised speech representation learning have focused on developing new training methods and applying pre-trained models for different applications. However, the quality of these models is often measured by the performance of different downstream tasks. How well the representations access the information of interest is less studied. In this work, we take a closer look into existing self-supervised methods of speech from an information-theoretic perspective. We aim to develop metrics using mutual information to help practical problems such as model design and selection. We use linear probes to estimate the mutual information between the target information and learned representations, showing another insight into the accessibility to the target information from speech representations. Further, we explore the potential of evaluating representations in a self-supervised fashion, where we estimate the mutual information between different parts of the data without using any labels. Finally, we show that both supervised and unsupervised measures echo the performance of the models on layer-wise linear probing and speech recognition.
DSNet: Disentangled Siamese Network with Neutral Calibration for Speech Emotion Recognition
Dec 25, 2023One persistent challenge in deep learning based speech emotion recognition (SER) is the unconscious encoding of emotion-irrelevant factors (e.g., speaker or phonetic variability), which limits the generalization of SER in practical use. In this paper, we propose DSNet, a Disentangled Siamese Network with neutral calibration, to meet the demand for a more robust and explainable SER model. Specifically, we introduce an orthogonal feature disentanglement module to explicitly project the high-level representation into two distinct subspaces. Later, we propose a novel neutral calibration mechanism to encourage one subspace to capture sufficient emotion-irrelevant information. In this way, the other one can better isolate and emphasize the emotion-relevant information within speech signals. Experimental results on two popular benchmark datasets demonstrate the superiority of DSNet over various state-of-the-art methods for speaker-independent SER.
Dementia Assessment Using Mandarin Speech with an Attention-based Speech Recognition Encoder
Oct 06, 2023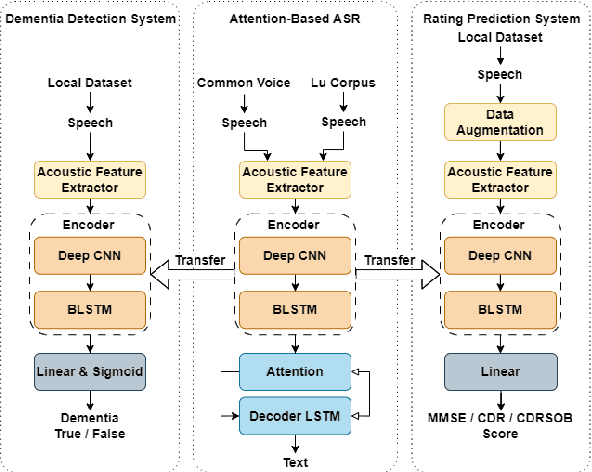
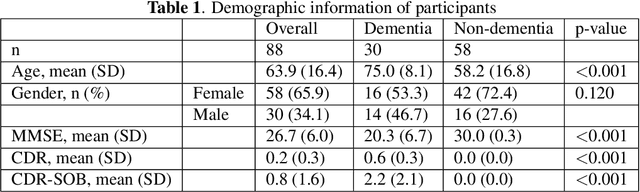
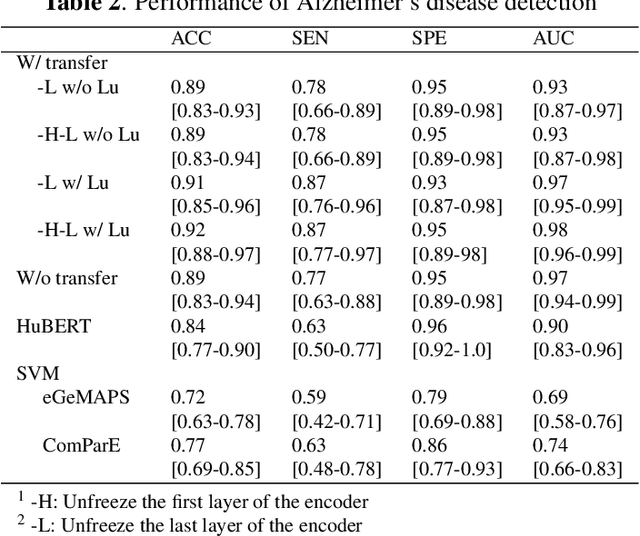
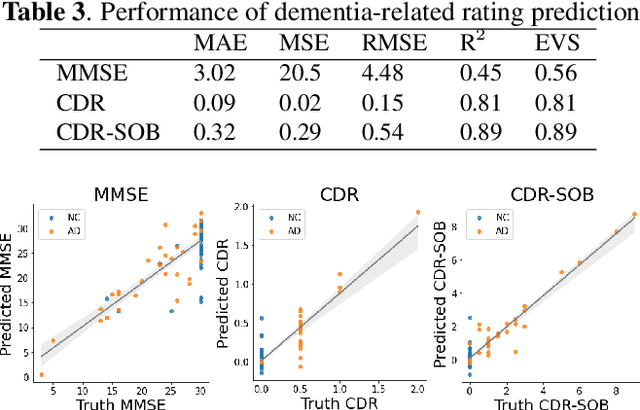
Dementia diagnosis requires a series of different testing methods, which is complex and time-consuming. Early detection of dementia is crucial as it can prevent further deterioration of the condition. This paper utilizes a speech recognition model to construct a dementia assessment system tailored for Mandarin speakers during the picture description task. By training an attention-based speech recognition model on voice data closely resembling real-world scenarios, we have significantly enhanced the model's recognition capabilities. Subsequently, we extracted the encoder from the speech recognition model and added a linear layer for dementia assessment. We collected Mandarin speech data from 99 subjects and acquired their clinical assessments from a local hospital. We achieved an accuracy of 92.04% in Alzheimer's disease detection and a mean absolute error of 9% in clinical dementia rating score prediction.
XLS-R Deep Learning Model for Multilingual ASR on Low- Resource Languages: Indonesian, Javanese, and Sundanese
Jan 12, 2024This research paper focuses on the development and evaluation of Automatic Speech Recognition (ASR) technology using the XLS-R 300m model. The study aims to improve ASR performance in converting spoken language into written text, specifically for Indonesian, Javanese, and Sundanese languages. The paper discusses the testing procedures, datasets used, and methodology employed in training and evaluating the ASR systems. The results show that the XLS-R 300m model achieves competitive Word Error Rate (WER) measurements, with a slight compromise in performance for Javanese and Sundanese languages. The integration of a 5-gram KenLM language model significantly reduces WER and enhances ASR accuracy. The research contributes to the advancement of ASR technology by addressing linguistic diversity and improving performance across various languages. The findings provide insights into optimizing ASR accuracy and applicability for diverse linguistic contexts.
Towards Automatic Data Augmentation for Disordered Speech Recognition
Dec 14, 2023Automatic recognition of disordered speech remains a highly challenging task to date due to data scarcity. This paper presents a reinforcement learning (RL) based on-the-fly data augmentation approach for training state-of-the-art PyChain TDNN and end-to-end Conformer ASR systems on such data. The handcrafted temporal and spectral mask operations in the standard SpecAugment method that are task and system dependent, together with additionally introduced minimum and maximum cut-offs of these time-frequency masks, are now automatically learned using an RNN-based policy controller and tightly integrated with ASR system training. Experiments on the UASpeech corpus suggest the proposed RL-based data augmentation approach consistently produced performance superior or comparable that obtained using expert or handcrafted SpecAugment policies. Our RL auto-augmented PyChain TDNN system produced an overall WER of 28.79% on the UASpeech test set of 16 dysarthric speakers.