 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Context-Aware Selective Label Smoothing for Calibrating Sequence Recognition Model
Mar 13, 2023

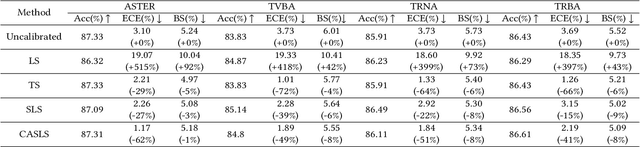
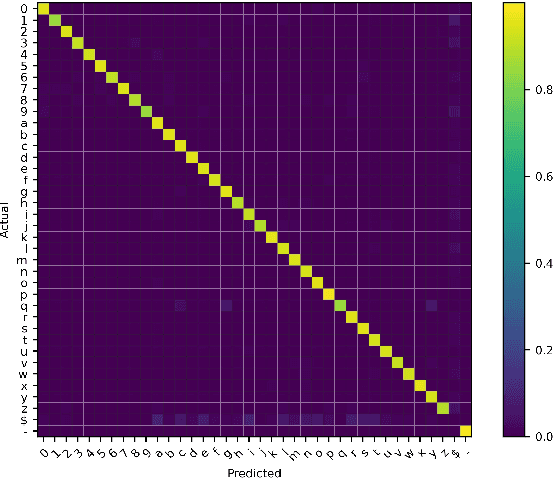
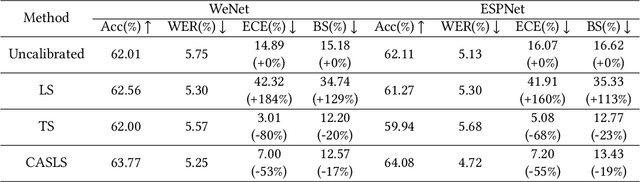
Despite the success of deep neural network (DNN) on sequential data (i.e., scene text and speech) recognition, it suffers from the over-confidence problem mainly due to overfitting in training with the cross-entropy loss, which may make the decision-making less reliable. Confidence calibration has been recently proposed as one effective solution to this problem. Nevertheless, the majority of existing confidence calibration methods aims at non-sequential data, which is limited if directly applied to sequential data since the intrinsic contextual dependency in sequences or the class-specific statistical prior is seldom exploited. To the end, we propose a Context-Aware Selective Label Smoothing (CASLS) method for calibrating sequential data. The proposed CASLS fully leverages the contextual dependency in sequences to construct confusion matrices of contextual prediction statistics over different classes. Class-specific error rates are then used to adjust the weights of smoothing strength in order to achieve adaptive calibration. Experimental results on sequence recognition tasks, including scene text recognition and speech recognition, demonstrate that our method can achieve the state-of-the-art performance.
AV-data2vec: Self-supervised Learning of Audio-Visual Speech Representations with Contextualized Target Representations
Feb 10, 2023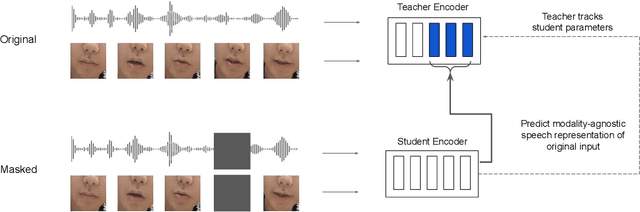
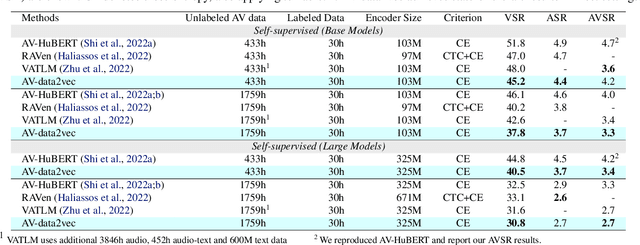
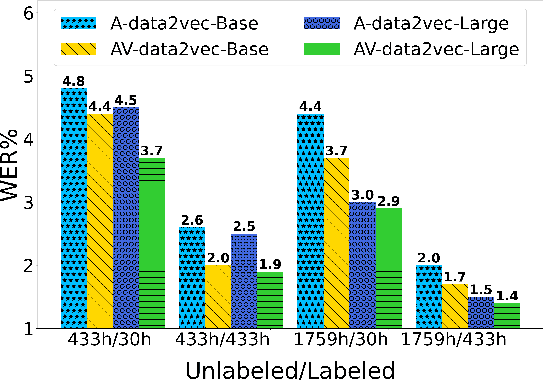
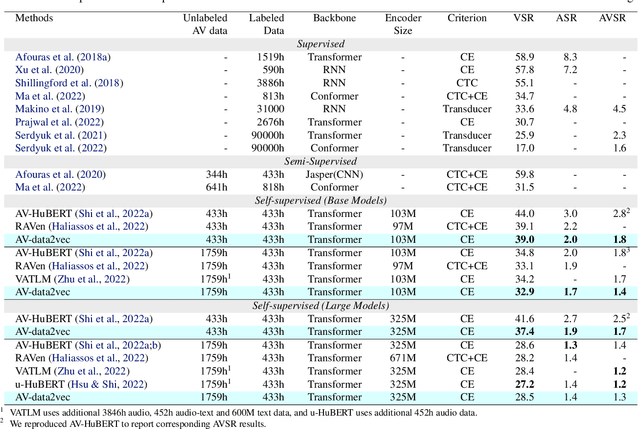
Self-supervision has shown great potential for audio-visual speech recognition by vastly reducing the amount of labeled data required to build good systems. However, existing methods are either not entirely end-to-end or do not train joint representations of both modalities. In this paper, we introduce AV-data2vec which addresses these challenges and builds audio-visual representations based on predicting contextualized representations which has been successful in the uni-modal case. The model uses a shared transformer encoder for both audio and video and can combine both modalities to improve speech recognition. Results on LRS3 show that AV-data2vec consistently outperforms existing methods under most settings.
Content-Context Factorized Representations for Automated Speech Recognition
May 19, 2022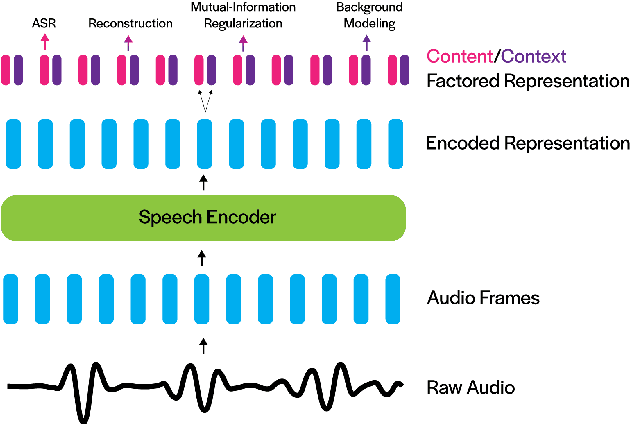
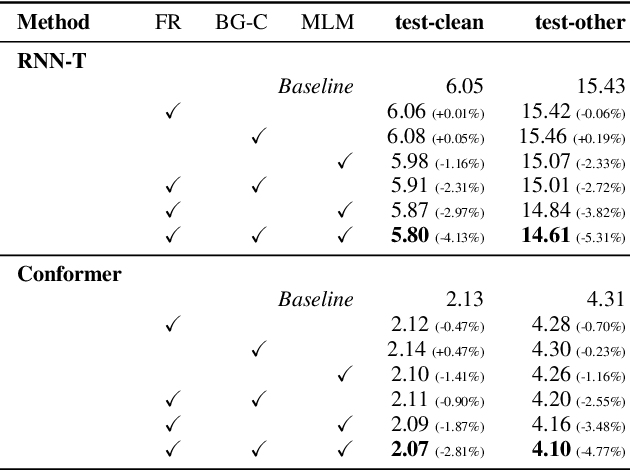
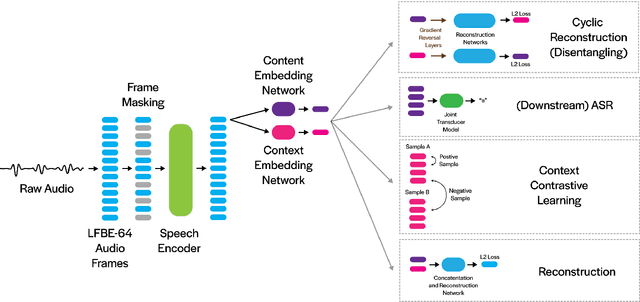
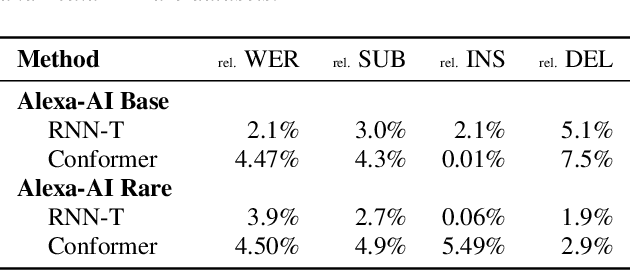
Deep neural networks have largely demonstrated their ability to perform automated speech recognition (ASR) by extracting meaningful features from input audio frames. Such features, however, may consist not only of information about the spoken language content, but also may contain information about unnecessary contexts such as background noise and sounds or speaker identity, accent, or protected attributes. Such information can directly harm generalization performance, by introducing spurious correlations between the spoken words and the context in which such words were spoken. In this work, we introduce an unsupervised, encoder-agnostic method for factoring speech-encoder representations into explicit content-encoding representations and spurious context-encoding representations. By doing so, we demonstrate improved performance on standard ASR benchmarks, as well as improved performance in both real-world and artificially noisy ASR scenarios.
Learning a Dual-Mode Speech Recognition Model via Self-Pruning
Jul 25, 2022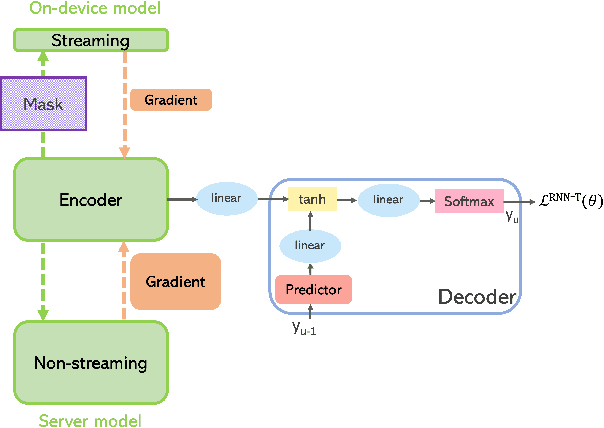

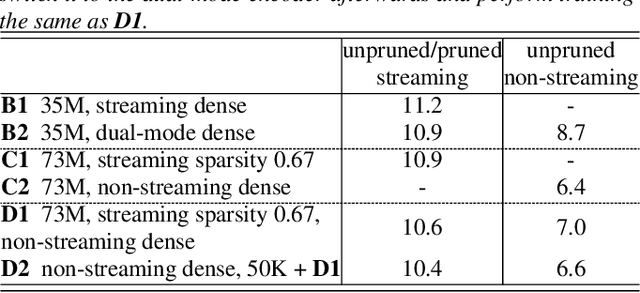

There is growing interest in unifying the streaming and full-context automatic speech recognition (ASR) networks into a single end-to-end ASR model to simplify the model training and deployment for both use cases. While in real-world ASR applications, the streaming ASR models typically operate under more storage and computational constraints - e.g., on embedded devices - than any server-side full-context models. Motivated by the recent progress in Omni-sparsity supernet training, where multiple subnetworks are jointly optimized in one single model, this work aims to jointly learn a compact sparse on-device streaming ASR model, and a large dense server non-streaming model, in a single supernet. Next, we present that, performing supernet training on both wav2vec 2.0 self-supervised learning and supervised ASR fine-tuning can not only substantially improve the large non-streaming model as shown in prior works, and also be able to improve the compact sparse streaming model.
Adversarial Speaker Disentanglement Using Unannotated External Data for Self-supervised Representation Based Voice Conversion
May 16, 2023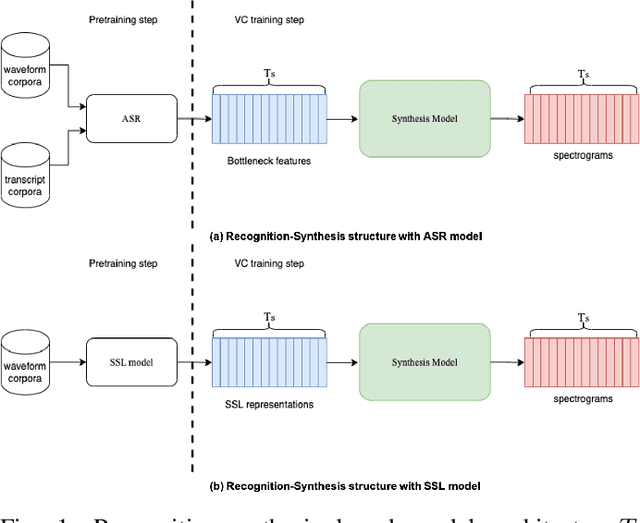
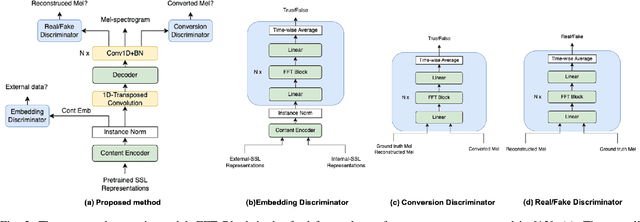
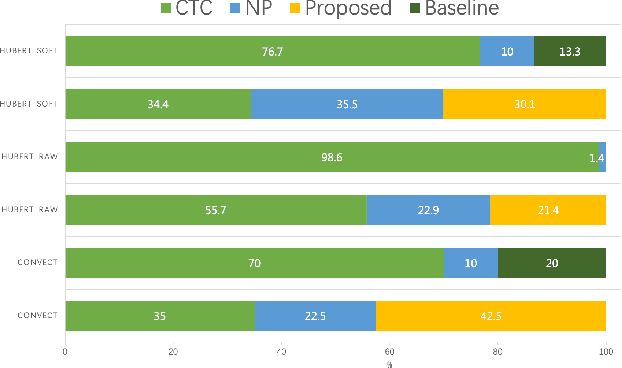
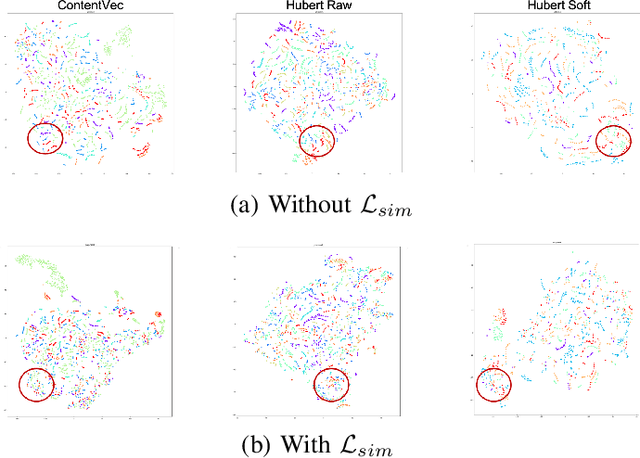
Nowadays, recognition-synthesis-based methods have been quite popular with voice conversion (VC). By introducing linguistics features with good disentangling characters extracted from an automatic speech recognition (ASR) model, the VC performance achieved considerable breakthroughs. Recently, self-supervised learning (SSL) methods trained with a large-scale unannotated speech corpus have been applied to downstream tasks focusing on the content information, which is suitable for VC tasks. However, a huge amount of speaker information in SSL representations degrades timbre similarity and the quality of converted speech significantly. To address this problem, we proposed a high-similarity any-to-one voice conversion method with the input of SSL representations. We incorporated adversarial training mechanisms in the synthesis module using external unannotated corpora. Two auxiliary discriminators were trained to distinguish whether a sequence of mel-spectrograms has been converted by the acoustic model and whether a sequence of content embeddings contains speaker information from external corpora. Experimental results show that our proposed method achieves comparable similarity and higher naturalness than the supervised method, which needs a huge amount of annotated corpora for training and is applicable to improve similarity for VC methods with other SSL representations as input.
Unsupervised Model-based speaker adaptation of end-to-end lattice-free MMI model for speech recognition
Nov 17, 2022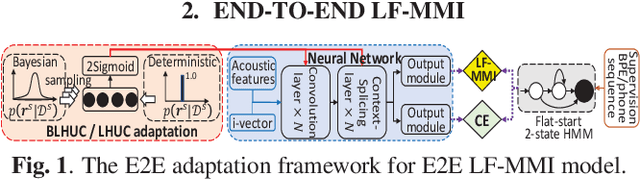
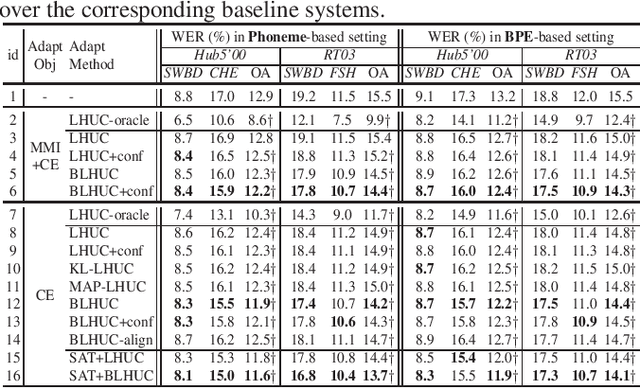
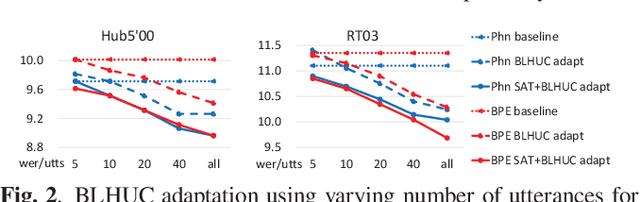
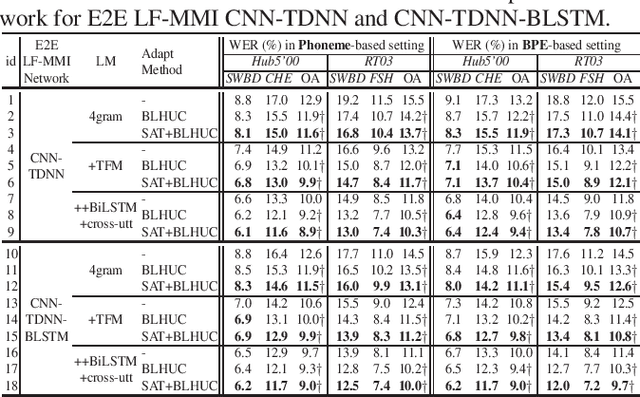
Modeling the speaker variability is a key challenge for automatic speech recognition (ASR) systems. In this paper, the learning hidden unit contributions (LHUC) based adaptation techniques with compact speaker dependent (SD) parameters are used to facilitate both speaker adaptive training (SAT) and unsupervised test-time speaker adaptation for end-to-end (E2E) lattice-free MMI (LF-MMI) models. An unsupervised model-based adaptation framework is proposed to estimate the SD parameters in E2E paradigm using LF-MMI and cross entropy (CE) criterions. Various regularization methods of the standard LHUC adaptation, e.g., the Bayesian LHUC (BLHUC) adaptation, are systematically investigated to mitigate the risk of overfitting, on E2E LF-MMI CNN-TDNN and CNN-TDNN-BLSTM models. Lattice-based confidence score estimation is used for adaptation data selection to reduce the supervision label uncertainty. Experiments on the 300-hour Switchboard task suggest that applying BLHUC in the proposed unsupervised E2E adaptation framework to byte pair encoding (BPE) based E2E LF-MMI systems consistently outperformed the baseline systems by relative word error rate (WER) reductions up to 10.5% and 14.7% on the NIST Hub5'00 and RT03 evaluation sets, and achieved the best performance in WERs of 9.0% and 9.7%, respectively. These results are comparable to the results of state-of-the-art adapted LF-MMI hybrid systems and adapted Conformer-based E2E systems.
Investigation of Data Augmentation Techniques for Disordered Speech Recognition
Jan 14, 2022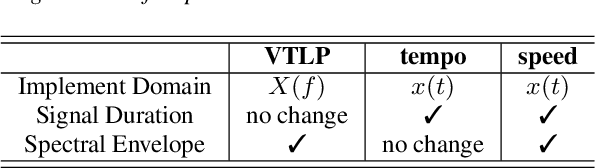
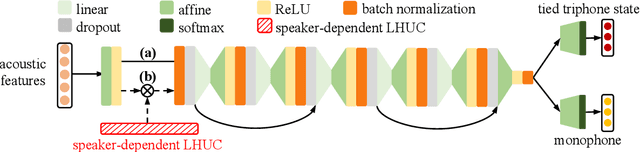
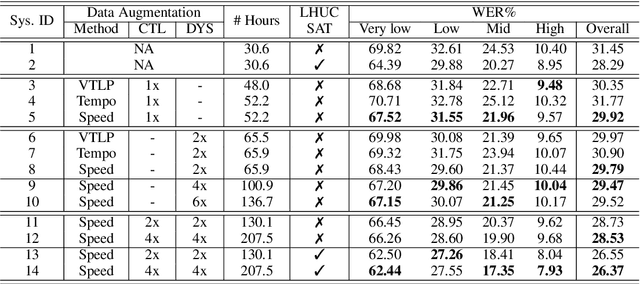
Disordered speech recognition is a highly challenging task. The underlying neuro-motor conditions of people with speech disorders, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of speech required for system development. This paper investigates a set of data augmentation techniques for disordered speech recognition, including vocal tract length perturbation (VTLP), tempo perturbation and speed perturbation. Both normal and disordered speech were exploited in the augmentation process. Variability among impaired speakers in both the original and augmented data was modeled using learning hidden unit contributions (LHUC) based speaker adaptive training. The final speaker adapted system constructed using the UASpeech corpus and the best augmentation approach based on speed perturbation produced up to 2.92% absolute (9.3% relative) word error rate (WER) reduction over the baseline system without data augmentation, and gave an overall WER of 26.37% on the test set containing 16 dysarthric speakers.
Unsupervised Domain Adaptation in Speech Recognition using Phonetic Features
Aug 04, 2021
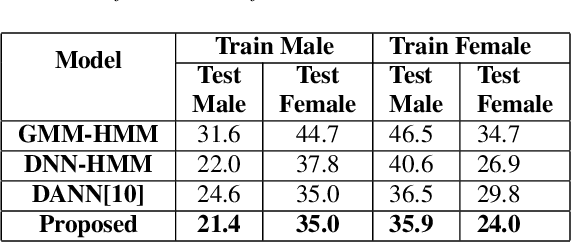
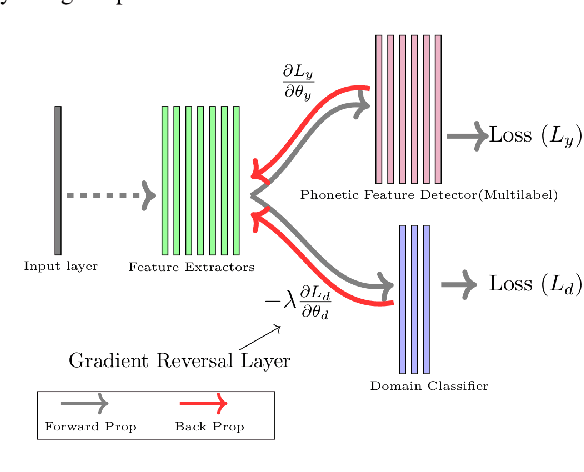
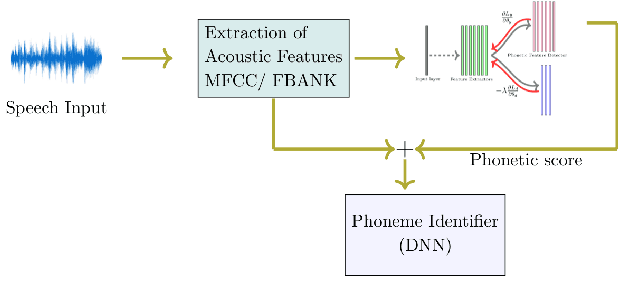
Automatic speech recognition is a difficult problem in pattern recognition because several sources of variability exist in the speech input like the channel variations, the input might be clean or noisy, the speakers may have different accent and variations in the gender, etc. As a result, domain adaptation is important in speech recognition where we train the model for a particular source domain and test it on a different target domain. In this paper, we propose a technique to perform unsupervised gender-based domain adaptation in speech recognition using phonetic features. The experiments are performed on the TIMIT dataset and there is a considerable decrease in the phoneme error rate using the proposed approach.
Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022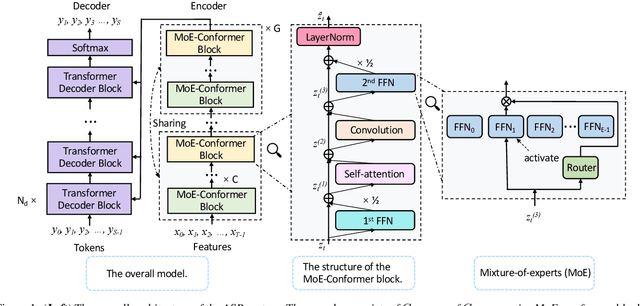
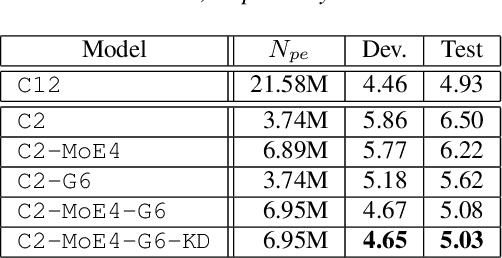
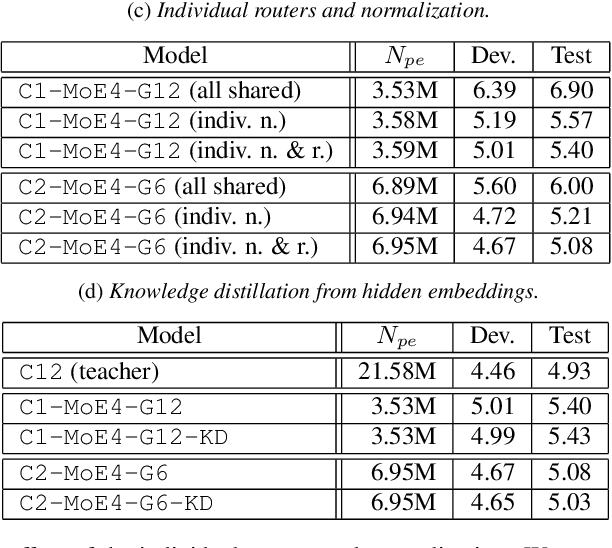
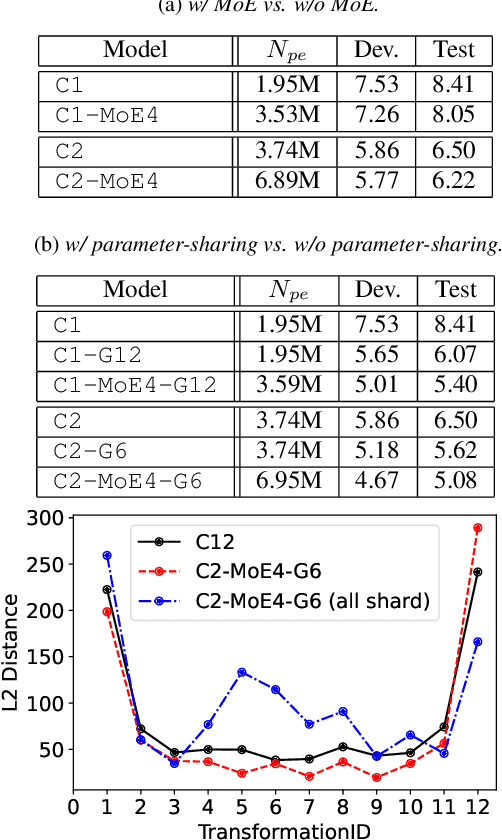
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.
Challenges and Opportunities of Speech Recognition for Bengali Language
Sep 27, 2021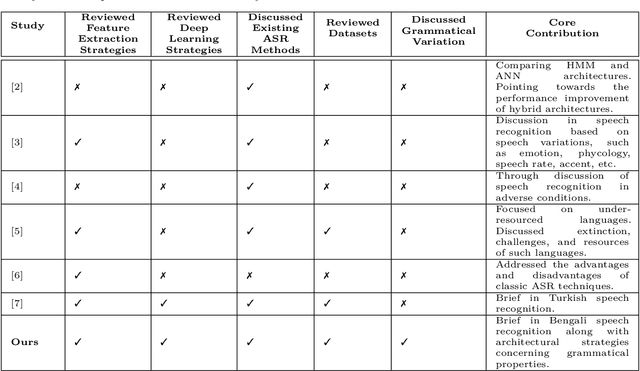
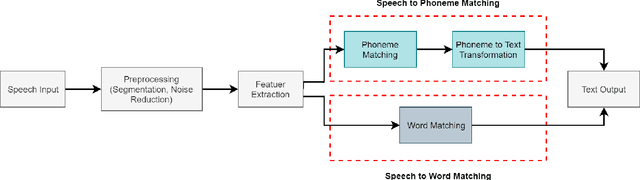
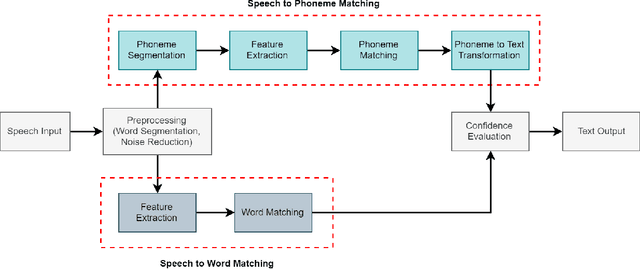
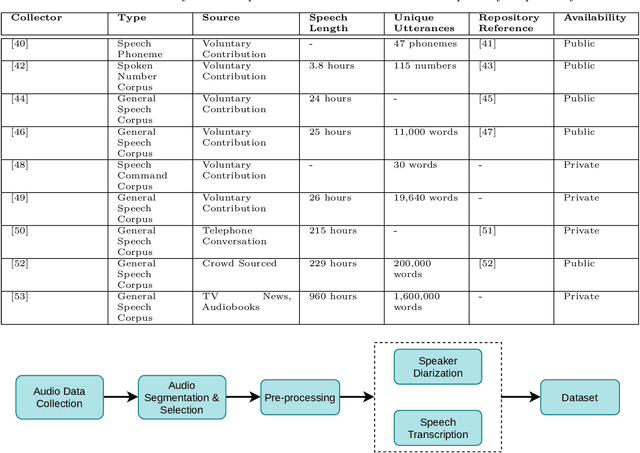
Speech recognition is a fascinating process that offers the opportunity to interact and command the machine in the field of human-computer interactions. Speech recognition is a language-dependent system constructed directly based on the linguistic and textual properties of any language. Automatic Speech Recognition (ASR) systems are currently being used to translate speech to text flawlessly. Although ASR systems are being strongly executed in international languages, ASR systems' implementation in the Bengali language has not reached an acceptable state. In this research work, we sedulously disclose the current status of the Bengali ASR system's research endeavors. In what follows, we acquaint the challenges that are mostly encountered while constructing a Bengali ASR system. We split the challenges into language-dependent and language-independent challenges and guide how the particular complications may be overhauled. Following a rigorous investigation and highlighting the challenges, we conclude that Bengali ASR systems require specific construction of ASR architectures based on the Bengali language's grammatical and phonetic structure.