 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
One Shot 3D Photography
Aug 27, 2020

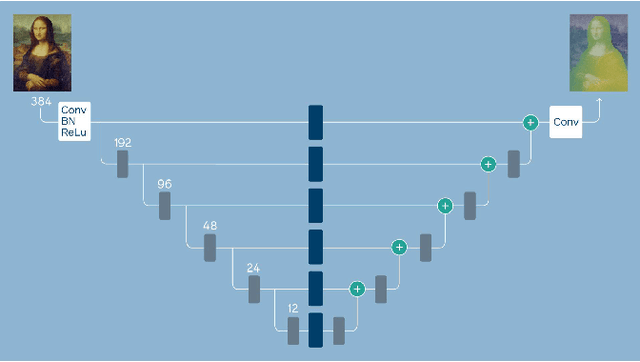

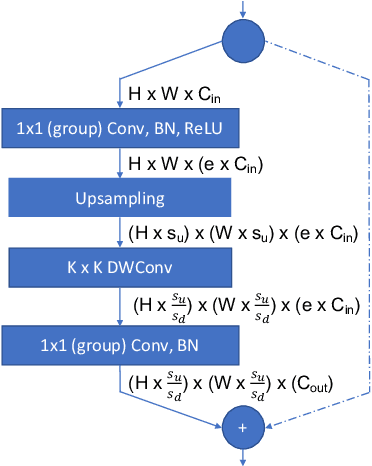
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
Pixel-wise Crowd Understanding via Synthetic Data
Jul 30, 2020
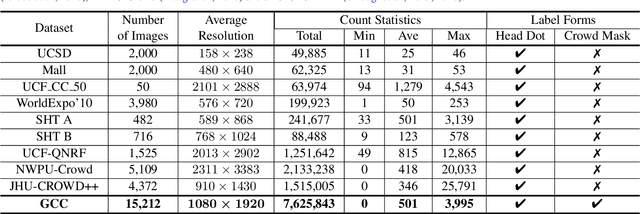
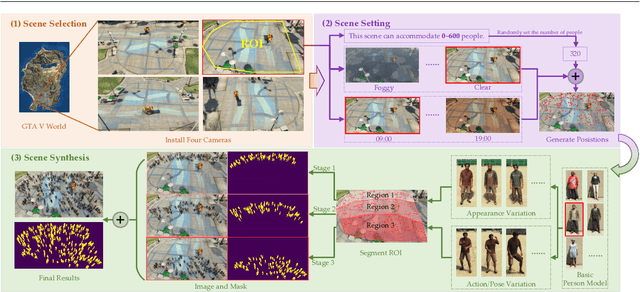

Crowd analysis via computer vision techniques is an important topic in the field of video surveillance, which has wide-spread applications including crowd monitoring, public safety, space design and so on. Pixel-wise crowd understanding is the most fundamental task in crowd analysis because of its finer results for video sequences or still images than other analysis tasks. Unfortunately, pixel-level understanding needs a large amount of labeled training data. Annotating them is an expensive work, which causes that current crowd datasets are small. As a result, most algorithms suffer from over-fitting to varying degrees. In this paper, take crowd counting and segmentation as examples from the pixel-wise crowd understanding, we attempt to remedy these problems from two aspects, namely data and methodology. Firstly, we develop a free data collector and labeler to generate synthetic and labeled crowd scenes in a computer game, Grand Theft Auto V. Then we use it to construct a large-scale, diverse synthetic crowd dataset, which is named as "GCC Dataset". Secondly, we propose two simple methods to improve the performance of crowd understanding via exploiting the synthetic data. To be specific, 1) supervised crowd understanding: pre-train a crowd analysis model on the synthetic data, then fine-tune it using the real data and labels, which makes the model perform better on the real world; 2) crowd understanding via domain adaptation: translate the synthetic data to photo-realistic images, then train the model on translated data and labels. As a result, the trained model works well in real crowd scenes.
M2E-Try On Net: Fashion from Model to Everyone
Nov 21, 2018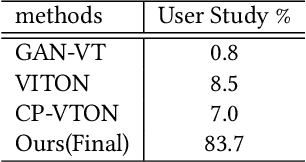
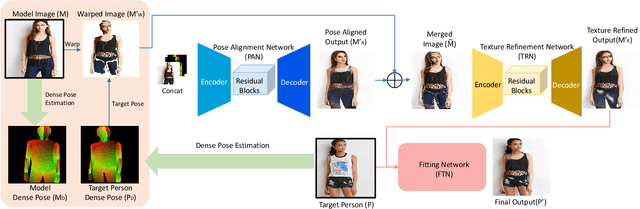
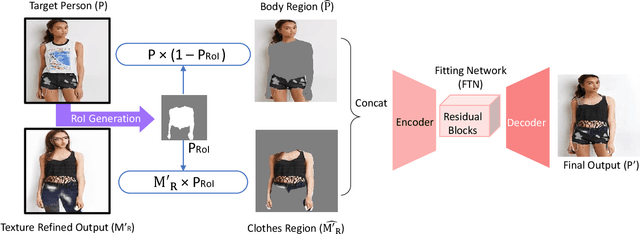

Most existing virtual try-on applications require clean clothes images. Instead, we present a novel virtual Try-On network, M2E-Try On Net, which transfers the clothes from a model image to a person image without the need of any clean product images. To obtain a realistic image of person wearing the desired model clothes, we aim to solve the following challenges: 1) non-rigid nature of clothes - we need to align poses between the model and the user; 2) richness in textures of fashion items - preserving the fine details and characteristics of the clothes is critical for photo-realistic transfer; 3) variation of identity appearances - it is required to fit the desired model clothes to the person identity seamlessly. To tackle these challenges, we introduce three key components, including the pose alignment network (PAN), the texture refinement network (TRN) and the fitting network (FTN). Since it is unlikely to gather image pairs of input person image and desired output image (i.e. person wearing the desired clothes), our framework is trained in a self-supervised manner to gradually transfer the poses and textures of the model's clothes to the desired appearance. In the experiments, we verify on the Deep Fashion dataset and MVC dataset that our method can generate photo-realistic images for the person to try-on the model clothes. Furthermore, we explore the model capability for different fashion items, including both upper and lower garments.
Deep Learning for Free-Hand Sketch: A Survey
Jan 08, 2020


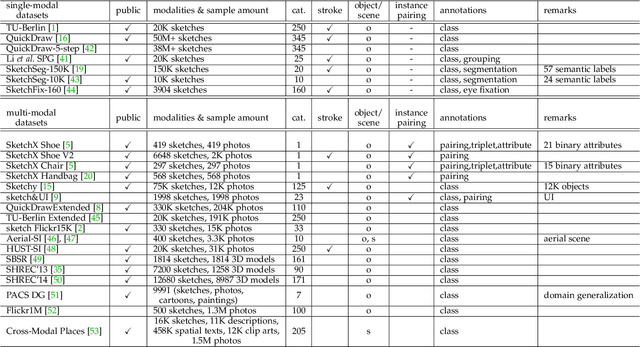
Free-hand sketches are highly hieroglyphic and illustrative, which have been widely used by humans to depict objects or stories from ancient times to the present. The recent prevalence of touchscreen devices has made sketch creation a much easier task than ever and consequently made sketch-oriented applications increasingly more popular. The prosperity of deep learning has also immensely promoted the research for the free-hand sketch. This paper presents a comprehensive survey of the free-hand sketch oriented deep learning techniques. The main contents of this survey include: (i) The intrinsic traits and domain-unique challenges of the free-hand sketch are discussed, to clarify the essential differences between free-hand sketch and other data modalities, e.g., natural photo. (ii) The development of the free-hand sketch community in the deep learning era is reviewed, by surveying the existing datasets, research topics, and the state-of-the-art methods via a detailed taxonomy. (iii) Moreover, the bottlenecks, open problems, and potential research directions of this community have also been discussed to promote the future works.
GLStyleNet: Higher Quality Style Transfer Combining Global and Local Pyramid Features
Nov 18, 2018

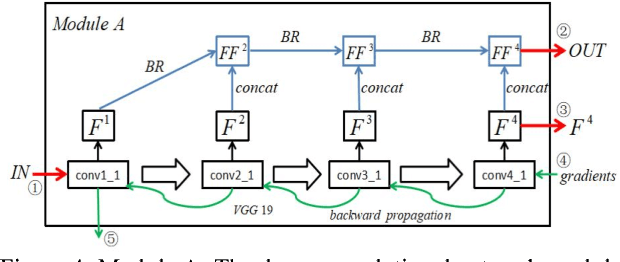
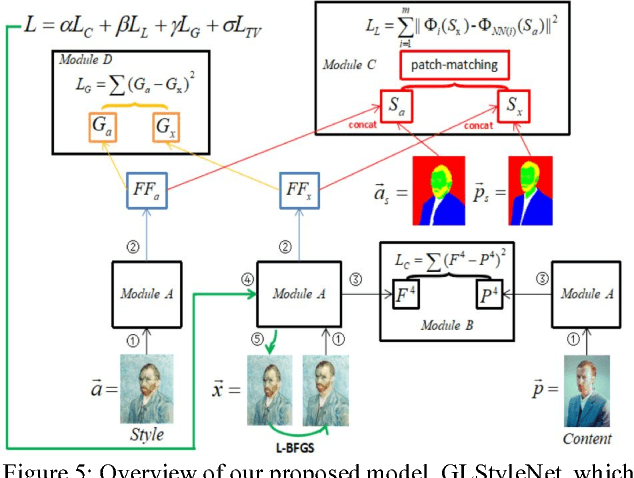
Recent studies using deep neural networks have shown remarkable success in style transfer especially for artistic and photo-realistic images. However, the approaches using global feature correlations fail to capture small, intricate textures and maintain correct texture scales of the artworks, and the approaches based on local patches are defective on global effect. In this paper, we present a novel feature pyramid fusion neural network, dubbed GLStyleNet, which sufficiently takes into consideration multi-scale and multi-level pyramid features by best aggregating layers across a VGG network, and performs style transfer hierarchically with multiple losses of different scales. Our proposed method retains high-frequency pixel information and low frequency construct information of images from two aspects: loss function constraint and feature fusion. Our approach is not only flexible to adjust the trade-off between content and style, but also controllable between global and local. Compared to state-of-the-art methods, our method can transfer not just large-scale, obvious style cues but also subtle, exquisite ones, and dramatically improves the quality of style transfer. We demonstrate the effectiveness of our approach on portrait style transfer, artistic style transfer, photo-realistic style transfer and Chinese ancient painting style transfer tasks. Experimental results indicate that our unified approach improves image style transfer quality over previous state-of-the-art methods, while also accelerating the whole process in a certain extent. Our code is available at https://github.com/EndyWon/GLStyleNet.
On Addressing the Impact of ISO Speed upon PRNU and Forgery Detection
Jun 20, 2020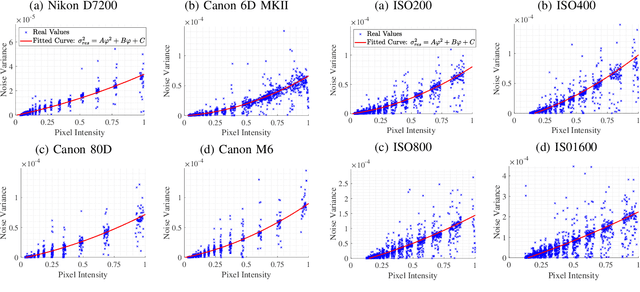
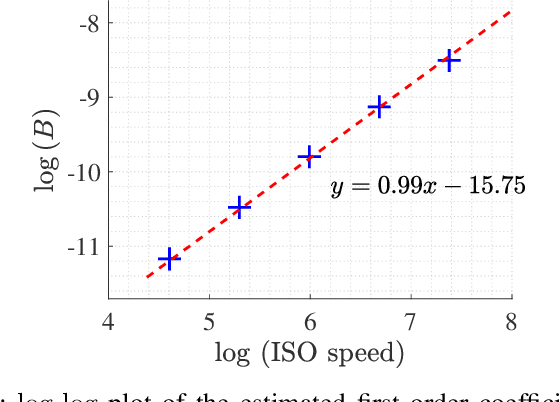
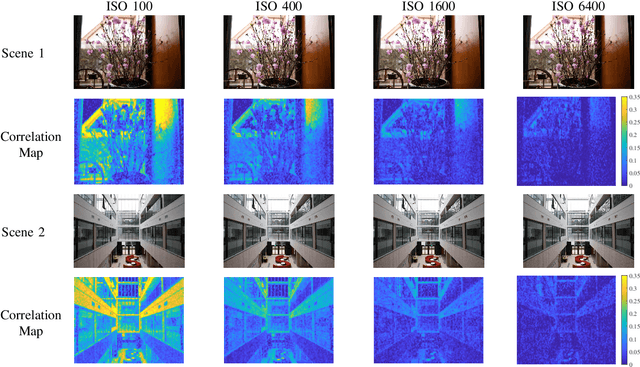

Photo Response Non-Uniformity (PRNU) has been used as a powerful device fingerprint for image forgery detection because image forgeries can be revealed by finding the absence of the PRNU in the manipulated areas. The correlation between an image's noise residual with the device's reference PRNU is often compared with a decision threshold to check the existence of the PRNU. A PRNU correlation predictor is usually used to determine this decision threshold assuming the correlation is content-dependent. However, we found that not only the correlation is content-dependent, but it also depends on the camera sensitivity setting. \textit{Camera sensitivity}, commonly known by the name of \textit{ISO speed}, is an important attribute in digital photography. In this work, we will show the PRNU correlation's dependency on ISO speed. Due to such dependency, we postulate that a correlation predictor is ISO speed-specific, i.e. \textit{reliable correlation predictions can only be made when a correlation predictor is trained with images of similar ISO speeds to the image in question}. We report the experiments we conducted to validate the postulate. It is realized that in the real-world, information about the ISO speed may not be available in the metadata to facilitate the implementation of our postulate in the correlation prediction process. We hence propose a method called Content-based Inference of ISO Speeds (CINFISOS) to infer the ISO speed from the image content.
U4D: Unsupervised 4D Dynamic Scene Understanding
Jul 23, 2019
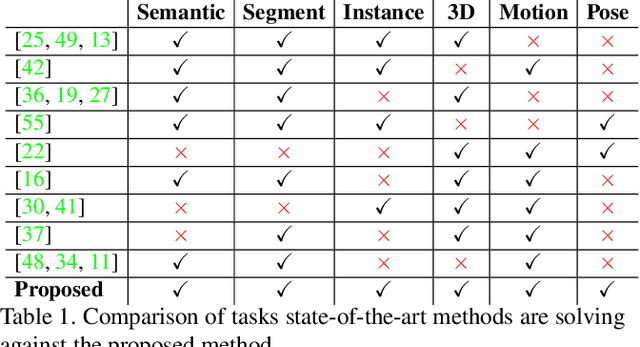

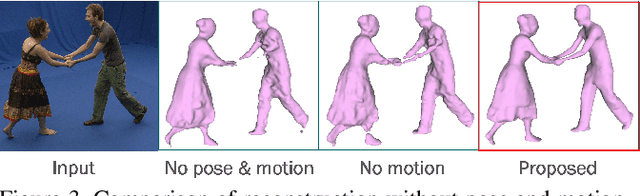
We introduce the first approach to solve the challenging problem of unsupervised 4D visual scene understanding for complex dynamic scenes with multiple interacting people from multi-view video. Our approach simultaneously estimates a detailed model that includes a per-pixel semantically and temporally coherent reconstruction, together with instance-level segmentation exploiting photo-consistency, semantic and motion information. We further leverage recent advances in 3D pose estimation to constrain the joint semantic instance segmentation and 4D temporally coherent reconstruction. This enables per person semantic instance segmentation of multiple interacting people in complex dynamic scenes. Extensive evaluation of the joint visual scene understanding framework against state-of-the-art methods on challenging indoor and outdoor sequences demonstrates a significant (approx 40%) improvement in semantic segmentation, reconstruction and scene flow accuracy.
Imaging and Classification Techniques for Seagrass Mapping and Monitoring: A Comprehensive Survey
Mar 01, 2019
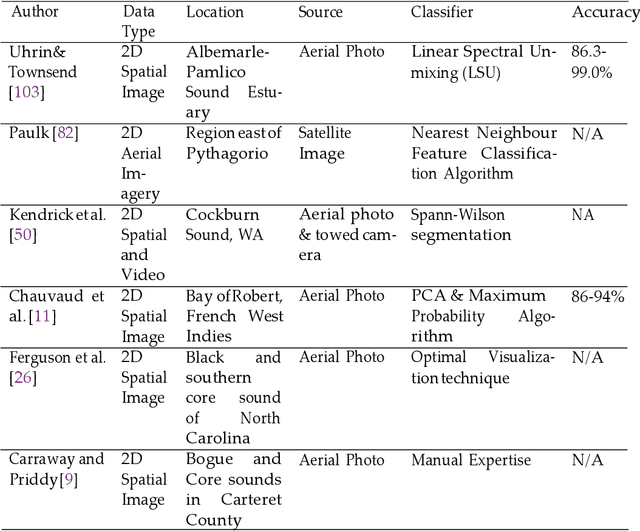
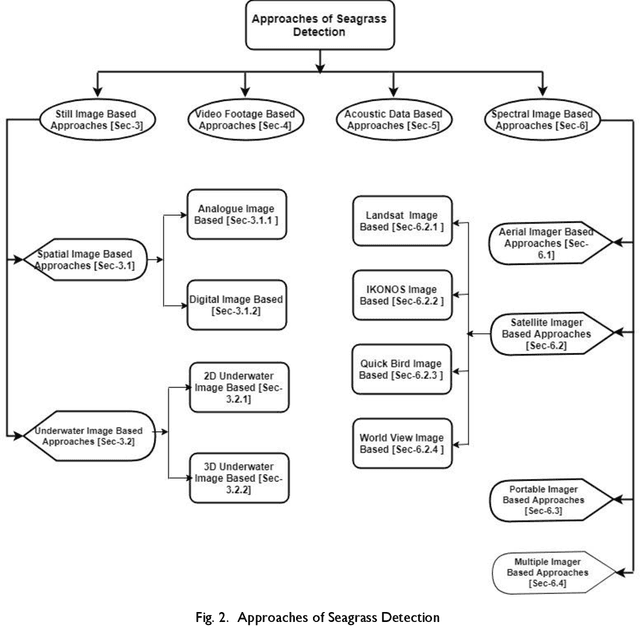
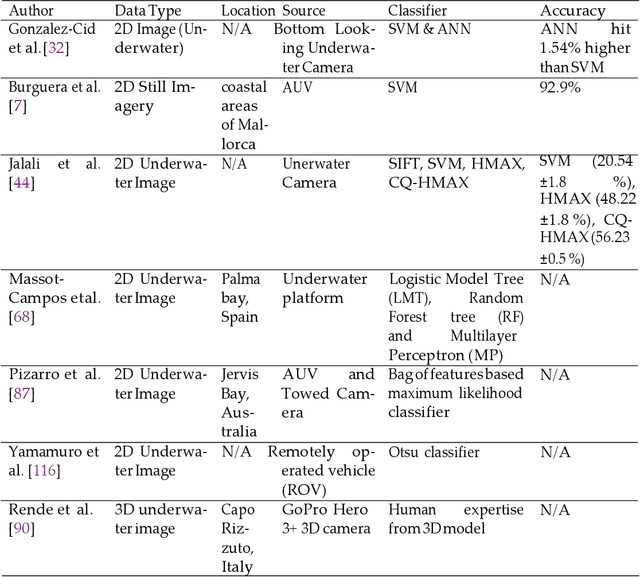
Monitoring underwater habitats is a vital part of observing the condition of the environment. The detection and mapping of underwater vegetation, especially seagrass has drawn the attention of the research community as early as the nineteen eighties. Initially, this monitoring relied on in situ observation by experts. Later, advances in remote-sensing technology, satellite-monitoring techniques and, digital photo- and video-based techniques opened a window to quicker, cheaper, and, potentially, more accurate seagrass-monitoring methods. So far, for seagrass detection and mapping, digital images from airborne cameras, spectral images from satellites, acoustic image data using underwater sonar technology, and digital underwater photo and video images have been used to map the seagrass meadows or monitor their condition. In this article, we have reviewed the recent approaches to seagrass detection and mapping to understand the gaps of the present approaches and determine further research scope to monitor the ocean health more easily. We have identified four classes of approach to seagrass mapping and assessment: still image-, video data-, acoustic image-, and spectral image data-based techniques. We have critically analysed the surveyed approaches and found the research gaps including the need for quick, cheap and effective imaging techniques robust to depth, turbidity, location and weather conditions, fully automated seagrass detectors that can work in real-time, accurate techniques for estimating the seagrass density, and the availability of high computation facilities for processing large scale data. For addressing these gaps, future research should focus on developing cheaper image and video data collection techniques, deep learning based automatic annotation and classification, and real-time percentage-cover calculation.
Efficient Machine Learning Approach for Optimizing the Timing Resolution of a High Purity Germanium Detector
Mar 31, 2020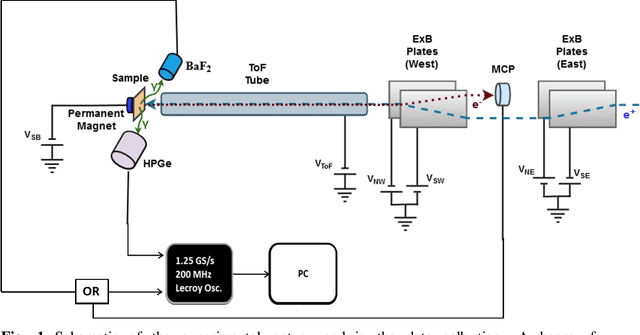
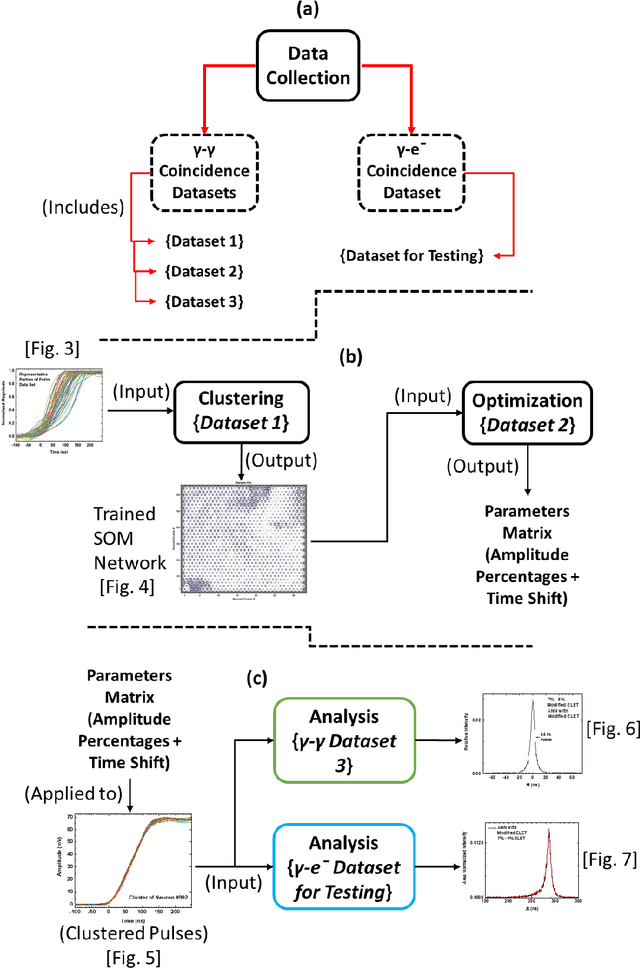
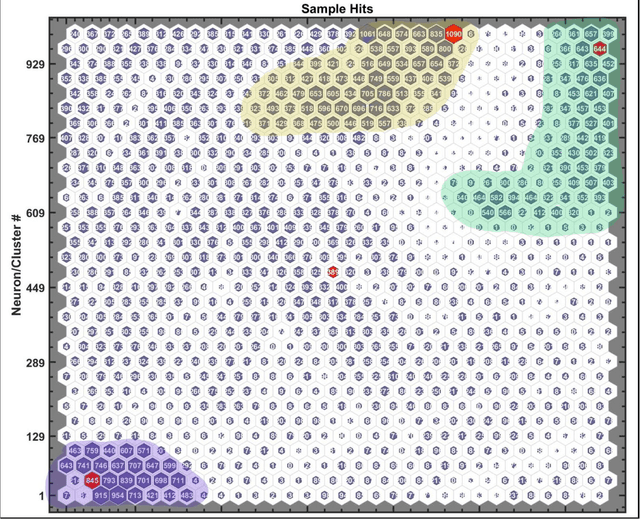
We describe here an efficient machine-learning based approach for the optimization of parameters used for extracting the arrival time of waveforms, in particular those generated by the detection of 511 keV annihilation gamma-rays by a 60 cm3 coaxial high purity germanium detector (HPGe). The method utilizes a type of artificial neural network (ANN) called a self-organizing map (SOM) to cluster the HPGe waveforms based on the shape of their rising edges. The optimal timing parameters for HPGe waveforms belonging to a particular cluster are found by minimizing the time difference between the HPGe signal and a signal produced by a BaF2 scintillation detector. Applying these variable timing parameters to the HPGe signals achieved a gamma-coincidence timing resolution of ~ 4.3 ns at the 511 keV photo peak (defined as 511 +- 50 keV) and a timing resolution of ~ 6.5 ns for the entire gamma spectrum--without rejecting any valid pulses. This timing resolution approaches the best obtained by analog nuclear electronics, without the corresponding complexities of analog optimization procedures. We further demonstrate the universality and efficacy of the machine learning approach by applying the method to the generation of secondary electron time-of-flight spectra following the implantation of energetic positrons on a sample.
Structure-Preserving Super Resolution with Gradient Guidance
Mar 29, 2020
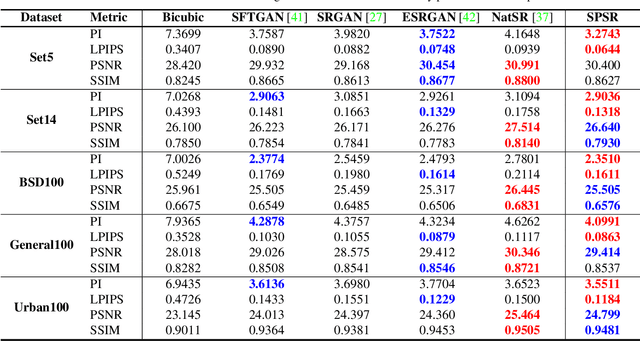
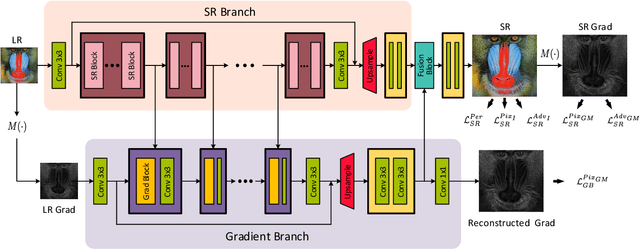

Structures matter in single image super resolution (SISR). Recent studies benefiting from generative adversarial network (GAN) have promoted the development of SISR by recovering photo-realistic images. However, there are always undesired structural distortions in the recovered images. In this paper, we propose a structure-preserving super resolution method to alleviate the above issue while maintaining the merits of GAN-based methods to generate perceptual-pleasant details. Specifically, we exploit gradient maps of images to guide the recovery in two aspects. On the one hand, we restore high-resolution gradient maps by a gradient branch to provide additional structure priors for the SR process. On the other hand, we propose a gradient loss which imposes a second-order restriction on the super-resolved images. Along with the previous image-space loss functions, the gradient-space objectives help generative networks concentrate more on geometric structures. Moreover, our method is model-agnostic, which can be potentially used for off-the-shelf SR networks. Experimental results show that we achieve the best PI and LPIPS performance and meanwhile comparable PSNR and SSIM compared with state-of-the-art perceptual-driven SR methods. Visual results demonstrate our superiority in restoring structures while generating natural SR images.