 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
ClsGAN: Selective Attribute Editing Based On Classification Adversarial Network
Oct 25, 2019

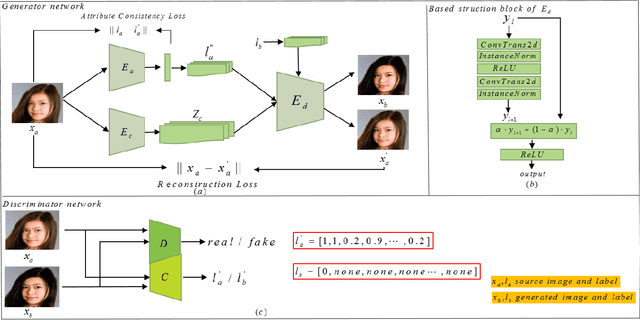

Attribution editing has shown remarking progress by the incorporating of encoder-decoder structure and generative adversarial network. However, there are still some challenges in the quality and attribute transformation of the generated images. Encoder-decoder structure leads to blurring of images and the skip-connection of encoder-decoder structure weakens the attribute transfer ability. To address these limitations, we propose a classification adversarial model(Cls-GAN) that can balance between attribute transfer and generated photo-realistic images. Considering that the transfer images are affected by the original attribute using skip-connection, we introduce upper convolution residual network(Tr-resnet) to selectively extract information from the source image and target label. Specially, we apply to the attribute classification adversarial network to learn about the defects of attribute transfer images so as to guide the generator. Finally, to meet the requirement of multimodal and improve reconstruction effect, we build two encoders including the content and style network, and select a attribute label approximation between source label and the output of style network. Experiments that operates at the dataset of CelebA show that images are superiority against the existing state-of-the-art models in image quality and transfer accuracy. Experiments on wikiart and seasonal datasets demonstrate that ClsGAN can effectively implement styel transfer.
SurReal: enhancing Surgical simulation Realism using style transfer
Nov 07, 2018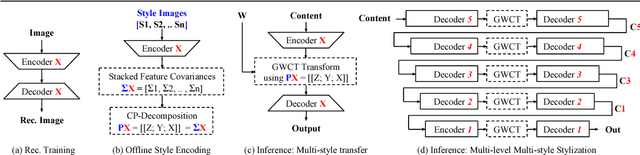

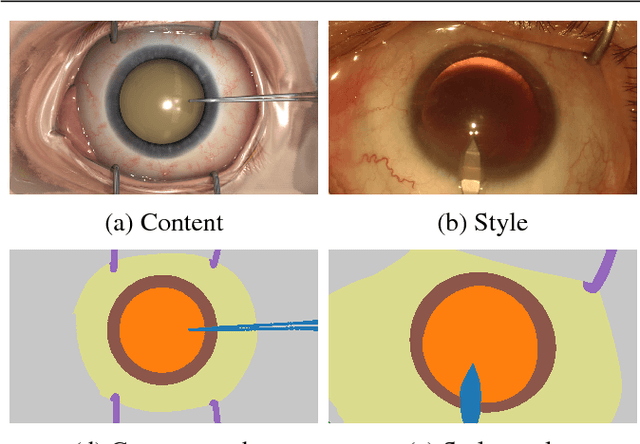

Surgical simulation is an increasingly important element of surgical education. Using simulation can be a means to address some of the significant challenges in developing surgical skills with limited time and resources. The photo-realistic fidelity of simulations is a key feature that can improve the experience and transfer ratio of trainees. In this paper, we demonstrate how we can enhance the visual fidelity of existing surgical simulation by performing style transfer of multi-class labels from real surgical video onto synthetic content. We demonstrate our approach on simulations of cataract surgery using real data labels from an existing public dataset. Our results highlight the feasibility of the approach and also the powerful possibility to extend this technique to incorporate additional temporal constraints and to different applications.
Aesthetic Features for Personalized Photo Recommendation
Aug 31, 2018
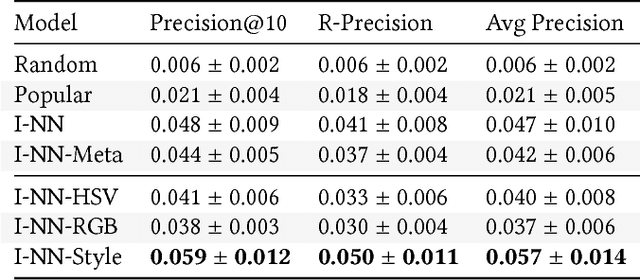
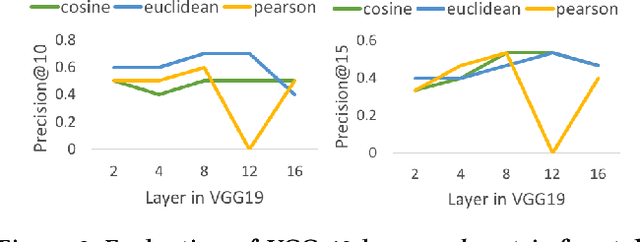
Many photography websites such as Flickr, 500px, Unsplash, and Adobe Behance are used by amateur and professional photography enthusiasts. Unlike content-based image search, such users of photography websites are not just looking for photos with certain content, but more generally for photos with a certain photographic "aesthetic". In this context, we explore personalized photo recommendation and propose two aesthetic feature extraction methods based on (i) color space and (ii) deep style transfer embeddings. Using a dataset from 500px, we evaluate how these features can be best leveraged by collaborative filtering methods and show that (ii) provides a significant boost in photo recommendation performance.
Deep Factorised Inverse-Sketching
Aug 07, 2018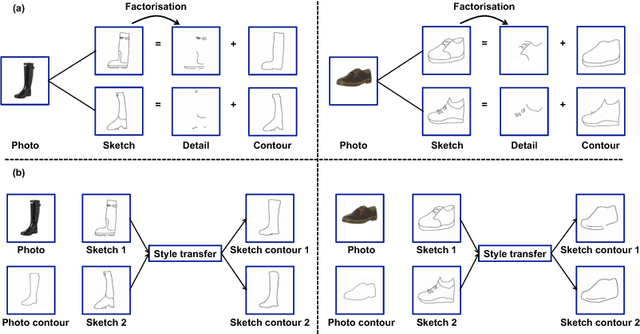
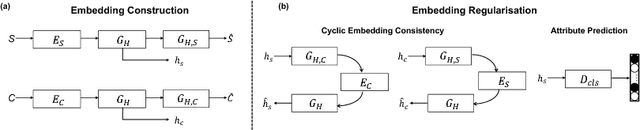
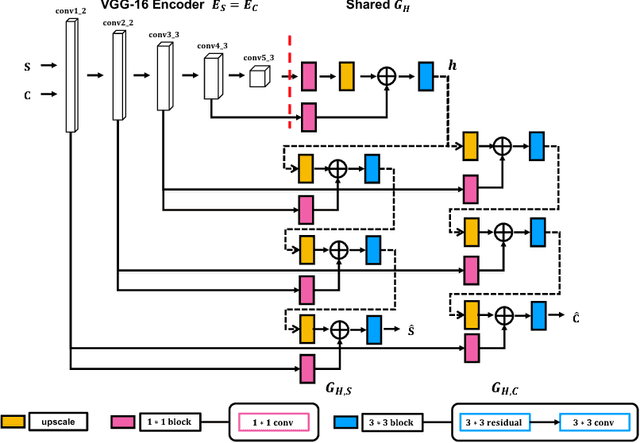
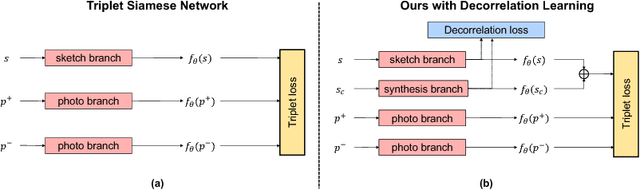
Modelling human free-hand sketches has become topical recently, driven by practical applications such as fine-grained sketch based image retrieval (FG-SBIR). Sketches are clearly related to photo edge-maps, but a human free-hand sketch of a photo is not simply a clean rendering of that photo's edge map. Instead there is a fundamental process of abstraction and iconic rendering, where overall geometry is warped and salient details are selectively included. In this paper we study this sketching process and attempt to invert it. We model this inversion by translating iconic free-hand sketches to contours that resemble more geometrically realistic projections of object boundaries, and separately factorise out the salient added details. This factorised re-representation makes it easier to match a free-hand sketch to a photo instance of an object. Specifically, we propose a novel unsupervised image style transfer model based on enforcing a cyclic embedding consistency constraint. A deep FG-SBIR model is then formulated to accommodate complementary discriminative detail from each factorised sketch for better matching with the corresponding photo. Our method is evaluated both qualitatively and quantitatively to demonstrate its superiority over a number of state-of-the-art alternatives for style transfer and FG-SBIR.
Neural Comic Style Transfer: Case Study
Sep 11, 2018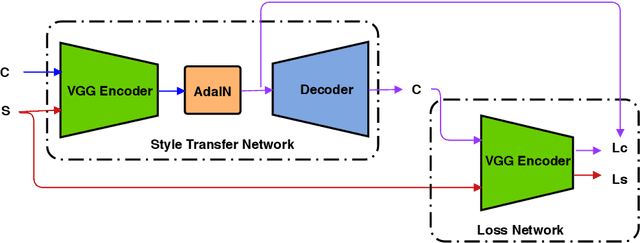
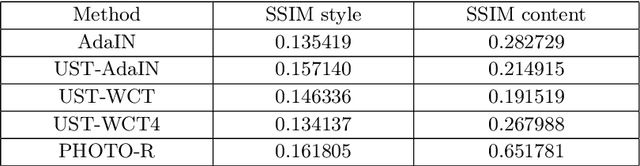

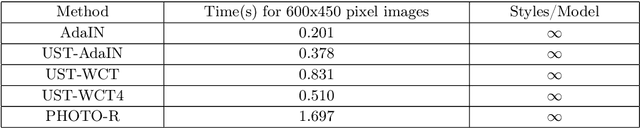
The work by Gatys et al. [1] recently showed a neural style algorithm that can produce an image in the style of another image. Some further works introduced various improvements regarding generalization, quality and efficiency, but each of them was mostly focused on styles such as paintings, abstract images or photo-realistic style. In this paper, we present a comparison of how state-of-the-art style transfer methods cope with transferring various comic styles on different images. We select different combinations of Adaptive Instance Normalization [11] and Universal Style Transfer [16] models and confront them to find their advantages and disadvantages in terms of qualitative and quantitative analysis. Finally, we present the results of a survey conducted on over 100 people that aims at validating the evaluation results in a real-life application of comic style transfer.
Ancient Painting to Natural Image: A New Solution for Painting Processing
Jan 02, 2019
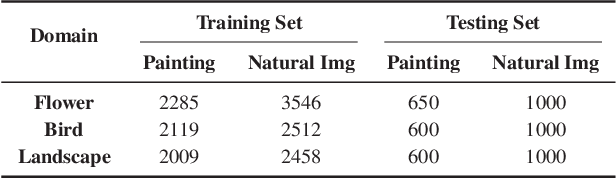

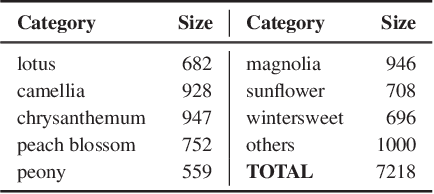
Collecting a large-scale and well-annotated dataset for image processing has become a common practice in computer vision. However, in the ancient painting area, this task is not practical as the number of paintings is limited and their style is greatly diverse. We, therefore, propose a novel solution for the problems that come with ancient painting processing. This is to use domain transfer to convert ancient paintings to photo-realistic natural images. By doing so, the ancient painting processing problems become natural image processing problems and models trained on natural images can be directly applied to the transferred paintings. Specifically, we focus on Chinese ancient flower, bird and landscape paintings in this work. A novel Domain Style Transfer Network (DSTN) is proposed to transfer ancient paintings to natural images which employ a compound loss to ensure that the transferred paintings still maintain the color composition and content of the input paintings. The experiment results show that the transferred paintings generated by the DSTN have a better performance in both the human perceptual test and other image processing tasks than other state-of-art methods, indicating the authenticity of the transferred paintings and the superiority of the proposed method.
Manipulating Attributes of Natural Scenes via Hallucination
Aug 22, 2018
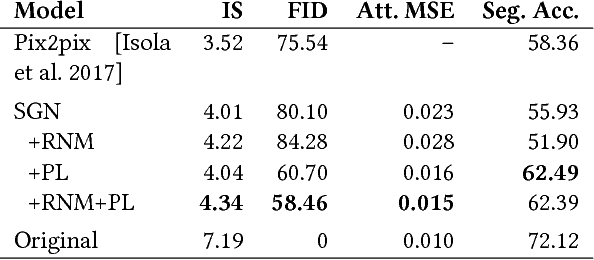
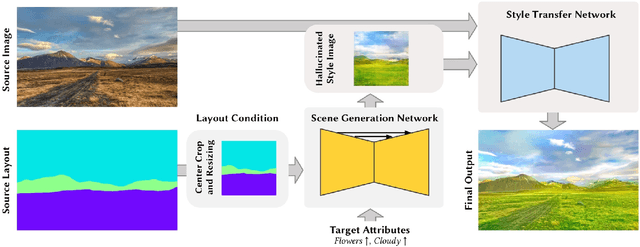
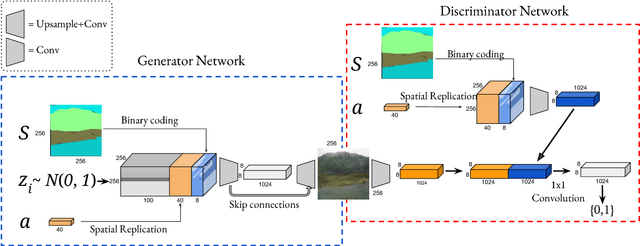
In this study, we explore building a two-stage framework for enabling users to directly manipulate high-level attributes of a natural scene. The key to our approach is a deep generative network which can hallucinate images of a scene as if they were taken at a different season (e.g. during winter), weather condition (e.g. in a cloudy day) or time of the day (e.g. at sunset). Once the scene is hallucinated with the given attributes, the corresponding look is then transferred to the input image while preserving the semantic details intact, giving a photo-realistic manipulation result. As the proposed framework hallucinates what the scene will look like, it does not require any reference style image as commonly utilized in most of the appearance or style transfer approaches. Moreover, it allows to simultaneously manipulate a given scene according to a diverse set of transient attributes within a single model, eliminating the need of training multiple networks per each translation task. Our comprehensive set of qualitative and quantitative results demonstrate the effectiveness of our approach against the competing methods.
Stylizing Face Images via Multiple Exemplars
Aug 28, 2017
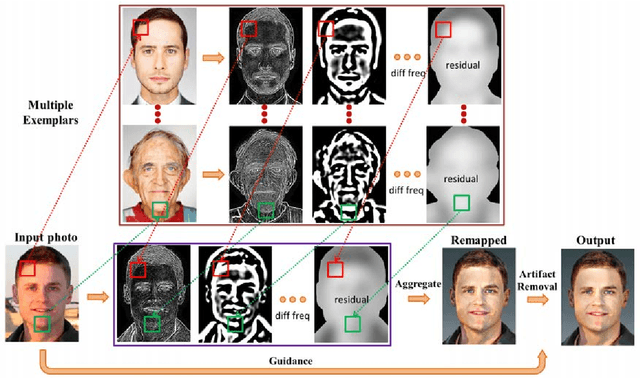


We address the problem of transferring the style of a headshot photo to face images. Existing methods using a single exemplar lead to inaccurate results when the exemplar does not contain sufficient stylized facial components for a given photo. In this work, we propose an algorithm to stylize face images using multiple exemplars containing different subjects in the same style. Patch correspondences between an input photo and multiple exemplars are established using a Markov Random Field (MRF), which enables accurate local energy transfer via Laplacian stacks. As image patches from multiple exemplars are used, the boundaries of facial components on the target image are inevitably inconsistent. The artifacts are removed by a post-processing step using an edge-preserving filter. Experimental results show that the proposed algorithm consistently produces visually pleasing results.
Photo-realistic Facial Texture Transfer
Jun 14, 2017
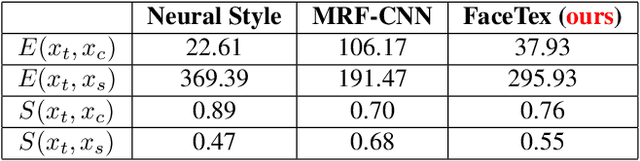

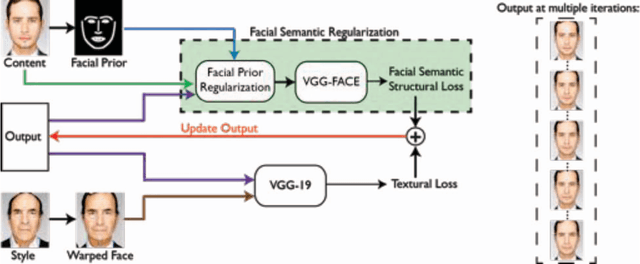
Style transfer methods have achieved significant success in recent years with the use of convolutional neural networks. However, many of these methods concentrate on artistic style transfer with few constraints on the output image appearance. We address the challenging problem of transferring face texture from a style face image to a content face image in a photorealistic manner without changing the identity of the original content image. Our framework for face texture transfer (FaceTex) augments the prior work of MRF-CNN with a novel facial semantic regularization that incorporates a face prior regularization smoothly suppressing the changes around facial meso-structures (e.g eyes, nose and mouth) and a facial structure loss function which implicitly preserves the facial structure so that face texture can be transferred without changing the original identity. We demonstrate results on face images and compare our approach with recent state-of-the-art methods. Our results demonstrate superior texture transfer because of the ability to maintain the identity of the original face image.
Photo Stylistic Brush: Robust Style Transfer via Superpixel-Based Bipartite Graph
Jul 15, 2016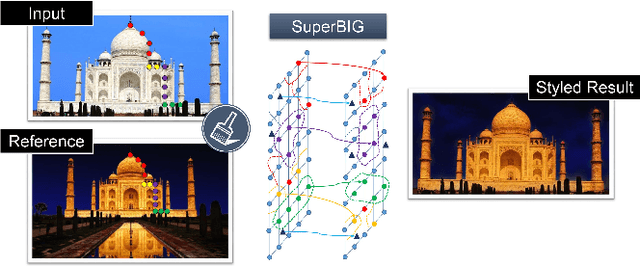
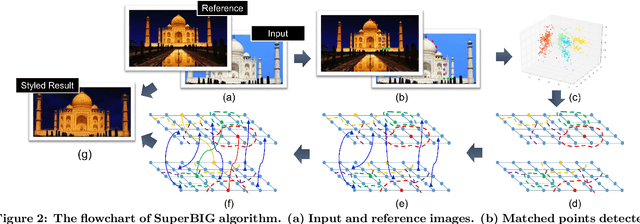


With the rapid development of social network and multimedia technology, customized image and video stylization has been widely used for various social-media applications. In this paper, we explore the problem of exemplar-based photo style transfer, which provides a flexible and convenient way to invoke fantastic visual impression. Rather than investigating some fixed artistic patterns to represent certain styles as was done in some previous works, our work emphasizes styles related to a series of visual effects in the photograph, e.g. color, tone, and contrast. We propose a photo stylistic brush, an automatic robust style transfer approach based on Superpixel-based BIpartite Graph (SuperBIG). A two-step bipartite graph algorithm with different granularity levels is employed to aggregate pixels into superpixels and find their correspondences. In the first step, with the extracted hierarchical features, a bipartite graph is constructed to describe the content similarity for pixel partition to produce superpixels. In the second step, superpixels in the input/reference image are rematched to form a new superpixel-based bipartite graph, and superpixel-level correspondences are generated by a bipartite matching. Finally, the refined correspondence guides SuperBIG to perform the transformation in a decorrelated color space. Extensive experimental results demonstrate the effectiveness and robustness of the proposed method for transferring various styles of exemplar images, even for some challenging cases, such as night images.