 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Sonus Texere! Automated Dense Soundtrack Construction for Books using Movie Adaptations
Dec 02, 2022

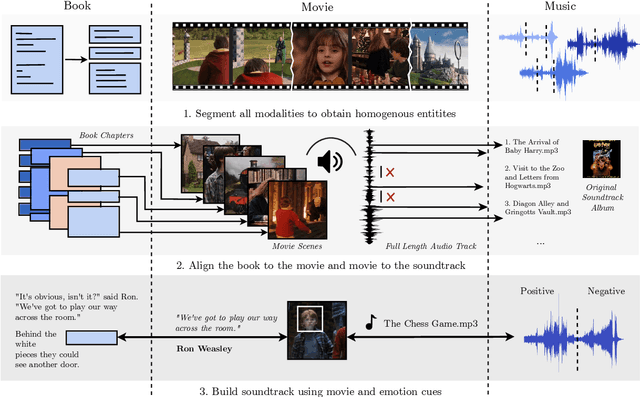
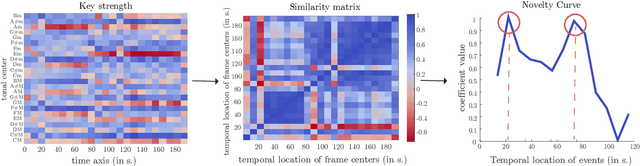

Reading, much like music listening, is an immersive experience that transports readers while taking them on an emotional journey. Listening to complementary music has the potential to amplify the reading experience, especially when the music is stylistically cohesive and emotionally relevant. In this paper, we propose the first fully automatic method to build a dense soundtrack for books, which can play high-quality instrumental music for the entirety of the reading duration. Our work employs a unique text processing and music weaving pipeline that determines the context and emotional composition of scenes in a chapter. This allows our method to identify and play relevant excerpts from the soundtrack of the book's movie adaptation. By relying on the movie composer's craftsmanship, our book soundtracks include expert-made motifs and other scene-specific musical characteristics. We validate the design decisions of our approach through a perceptual study. Our readers note that the book soundtrack greatly enhanced their reading experience, due to high immersiveness granted via uninterrupted and style-consistent music, and a heightened emotional state attained via high precision emotion and scene context recognition.
Dance2Music: Automatic Dance-driven Music Generation
Jul 13, 2021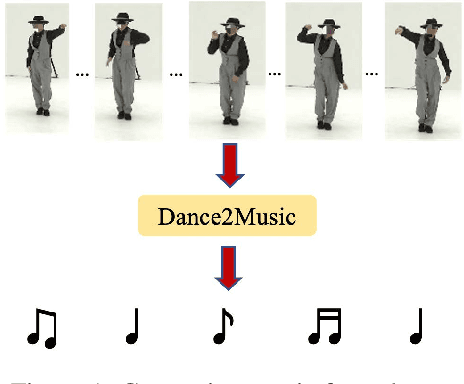
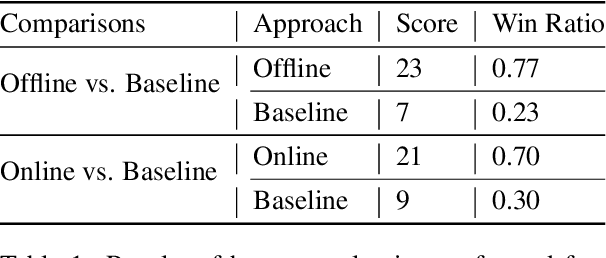

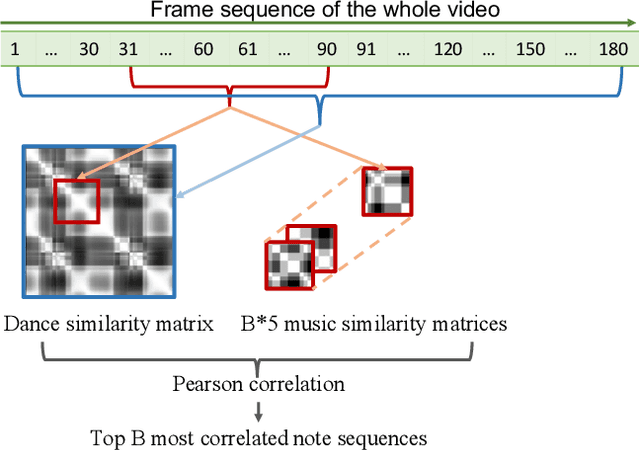
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.
Structure-Enhanced Pop Music Generation via Harmony-Aware Learning
Sep 14, 2021
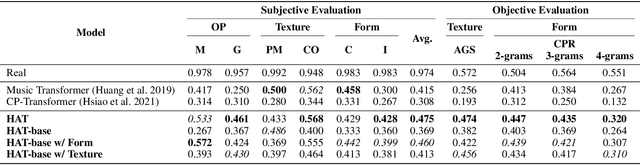
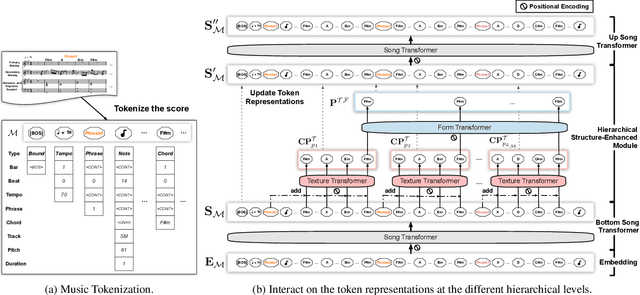
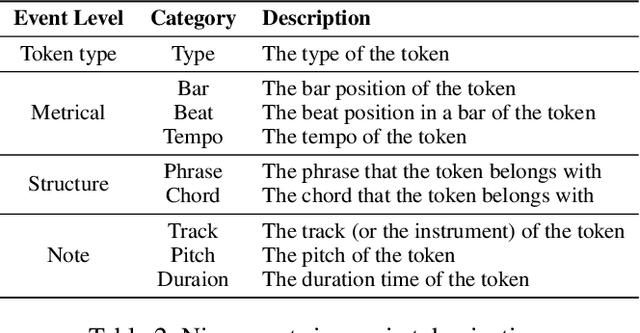
Automatically composing pop music with a satisfactory structure is an attractive but challenging topic. Although the musical structure is easy to be perceived by human, it is difficult to be described clearly and defined accurately. And it is still far from being solved that how we should model the structure in pop music generation. In this paper, we propose to leverage harmony-aware learning for structure-enhanced pop music generation. On the one hand, one of the participants of harmony, chord, represents the harmonic set of multiple notes, which is integrated closely with the spatial structure of music, texture. On the other hand, the other participant of harmony, chord progression, usually accompanies with the development of the music, which promotes the temporal structure of music, form. Besides, when chords evolve into chord progression, the texture and the form can be bridged by the harmony naturally, which contributes to the joint learning of the two structures. Furthermore, we propose the Harmony-Aware Hierarchical Music Transformer (HAT), which can exploit the structure adaptively from the music, and interact on the music tokens at multiple levels to enhance the signals of the structure in various musical elements. Results of subjective and objective evaluations demonstrate that HAT significantly improves the quality of generated music, especially in the structureness.
A Novel Multi-Task Learning Method for Symbolic Music Emotion Recognition
Jan 15, 2022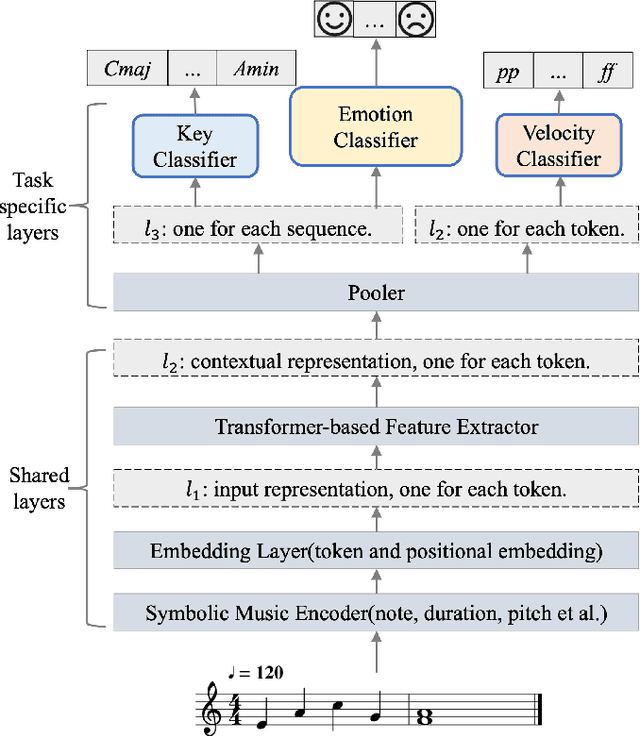


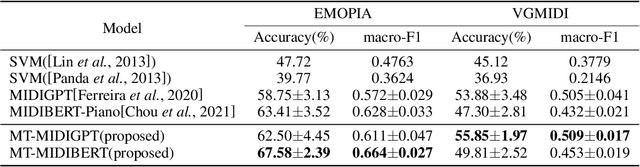
Symbolic Music Emotion Recognition(SMER) is to predict music emotion from symbolic data, such as MIDI and MusicXML. Previous work mainly focused on learning better representation via (mask) language model pre-training but ignored the intrinsic structure of the music, which is extremely important to the emotional expression of music. In this paper, we present a simple multi-task framework for SMER, which incorporates the emotion recognition task with other emotion-related auxiliary tasks derived from the intrinsic structure of the music. The results show that our multi-task framework can be adapted to different models. Moreover, the labels of auxiliary tasks are easy to be obtained, which means our multi-task methods do not require manually annotated labels other than emotion. Conducting on two publicly available datasets (EMOPIA and VGMIDI), the experiments show that our methods perform better in SMER task. Specifically, accuracy has been increased by 4.17 absolute point to 67.58 in EMOPIA dataset, and 1.97 absolute point to 55.85 in VGMIDI dataset. Ablation studies also show the effectiveness of multi-task methods designed in this paper.
Semi-Supervised Convolutive NMF for Automatic Music Transcription
Feb 10, 2022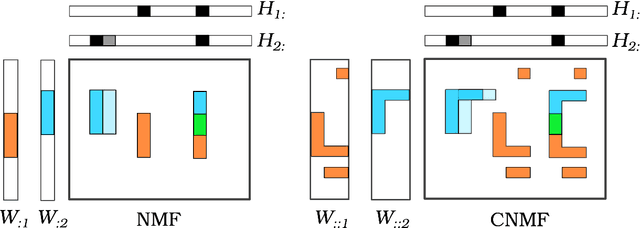
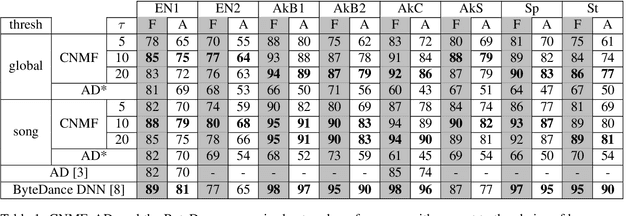
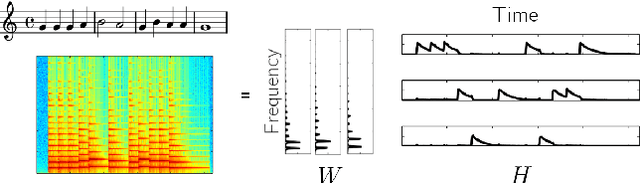
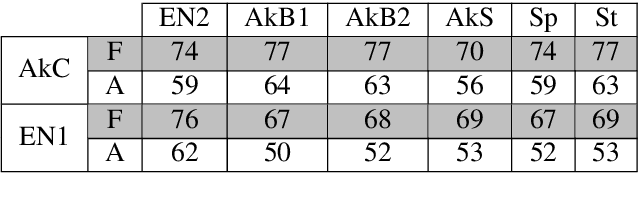
Automatic Music Transcription, which consists in transforming an audio recording of a musical performance into symbolic format, remains a difficult Music Information Retrieval task. In this work, we propose a semi-supervised approach using low-rank matrix factorization techniques, in particular Convolutive Nonnegative Matrix Factorization. In the semi-supervised setting, only a single recording of each individual notes is required. We show on the MAPS dataset that the proposed semi-supervised CNMF method performs better than state-of-the-art low-rank factorization techniques and a little worse than supervised deep learning state-of-the-art methods, while however suffering from generalization issues.
A2D: Anywhere Anytime Drumming
Apr 04, 2023
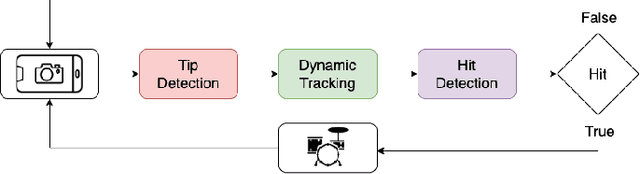
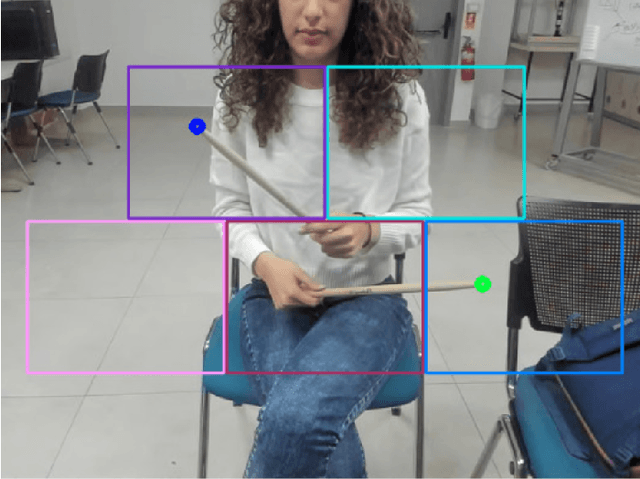

The drum kit, which has only been around for around 100 years, is a popular instrument in many music genres such as pop, rock, and jazz. However, the road to owning a kit is expensive, both financially and space-wise. Also, drums are more difficult to move around compared to other instruments, as they do not fit into a single bag. We propose a no-drums approach that uses only two sticks and a smartphone or a webcam to provide an air-drumming experience. The detection algorithm combines deep learning tools with tracking methods for an enhanced user experience. Based on both quantitative and qualitative testing with humans-in-the-loop, we show that our system has zero misses for beginner level play and negligible misses for advanced level play. Additionally, our limited human trials suggest potential directions for future research.
WuYun: Exploring hierarchical skeleton-guided melody generation using knowledge-enhanced deep learning
Jan 11, 2023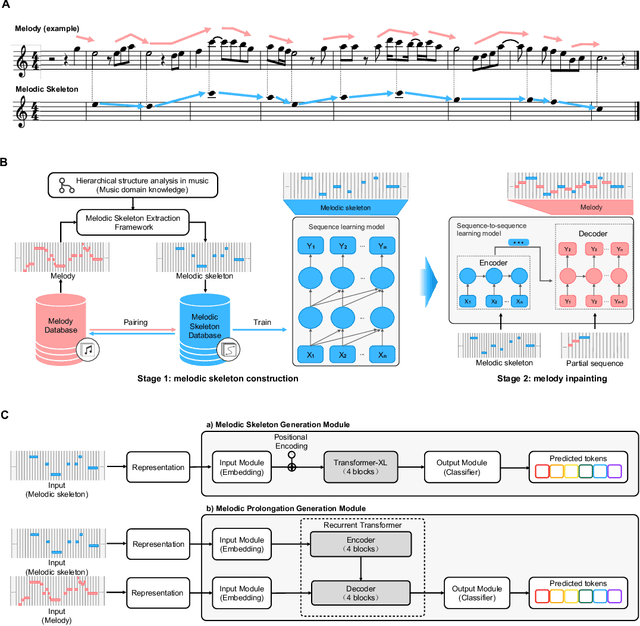
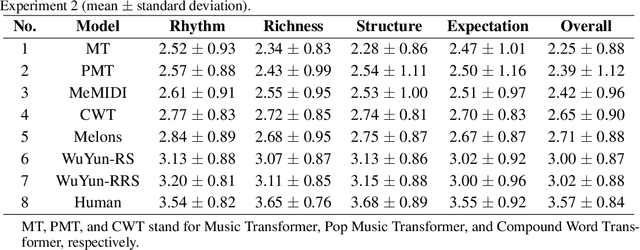
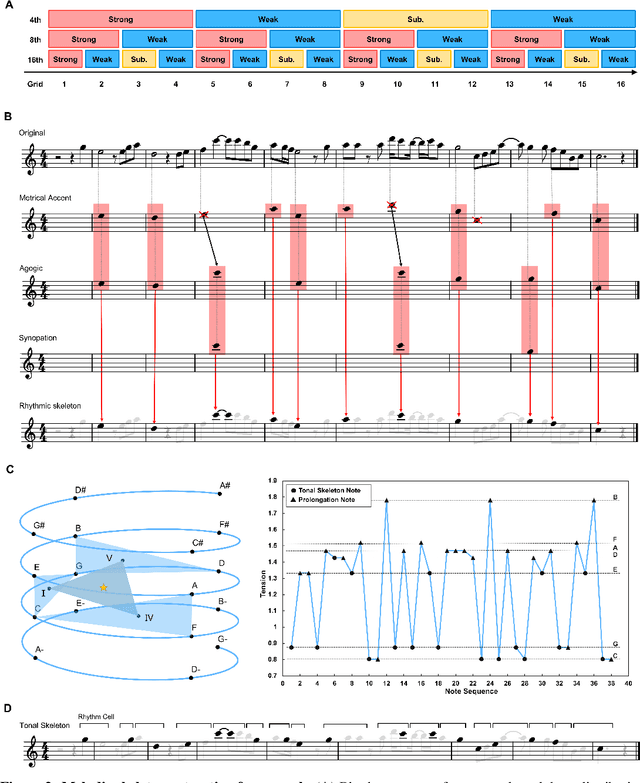
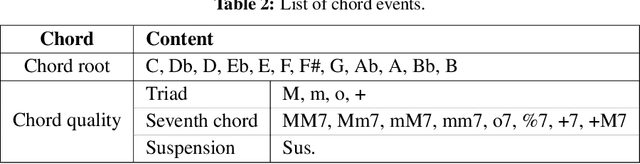
Although deep learning has revolutionized music generation, existing methods for structured melody generation follow an end-to-end left-to-right note-by-note generative paradigm and treat each note equally. Here, we present WuYun, a knowledge-enhanced deep learning architecture for improving the structure of generated melodies, which first generates the most structurally important notes to construct a melodic skeleton and subsequently infills it with dynamically decorative notes into a full-fledged melody. Specifically, we use music domain knowledge to extract melodic skeletons and employ sequence learning to reconstruct them, which serve as additional knowledge to provide auxiliary guidance for the melody generation process. We demonstrate that WuYun can generate melodies with better long-term structure and musicality and outperforms other state-of-the-art methods by 0.51 on average on all subjective evaluation metrics. Our study provides a multidisciplinary lens to design melodic hierarchical structures and bridge the gap between data-driven and knowledge-based approaches for numerous music generation tasks.
Emotion Embedding Spaces for Matching Music to Stories
Nov 26, 2021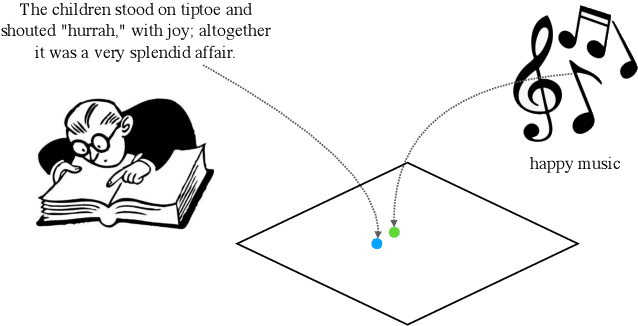
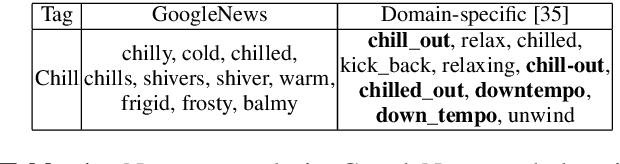

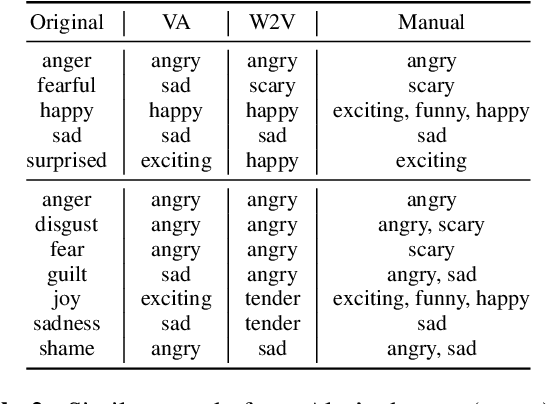
Content creators often use music to enhance their stories, as it can be a powerful tool to convey emotion. In this paper, our goal is to help creators find music to match the emotion of their story. We focus on text-based stories that can be auralized (e.g., books), use multiple sentences as input queries, and automatically retrieve matching music. We formalize this task as a cross-modal text-to-music retrieval problem. Both the music and text domains have existing datasets with emotion labels, but mismatched emotion vocabularies prevent us from using mood or emotion annotations directly for matching. To address this challenge, we propose and investigate several emotion embedding spaces, both manually defined (e.g., valence/arousal) and data-driven (e.g., Word2Vec and metric learning) to bridge this gap. Our experiments show that by leveraging these embedding spaces, we are able to successfully bridge the gap between modalities to facilitate cross modal retrieval. We show that our method can leverage the well established valence-arousal space, but that it can also achieve our goal via data-driven embedding spaces. By leveraging data-driven embeddings, our approach has the potential of being generalized to other retrieval tasks that require broader or completely different vocabularies.
Melody transcription via generative pre-training
Dec 04, 2022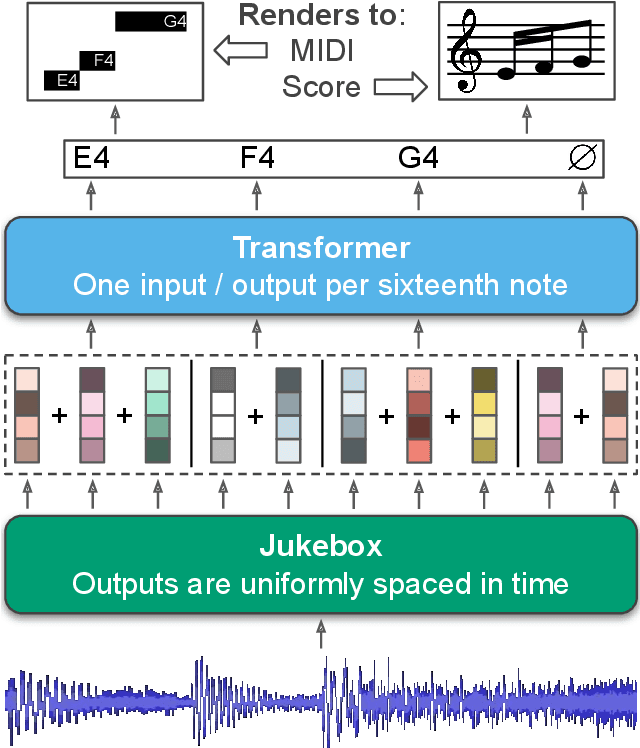
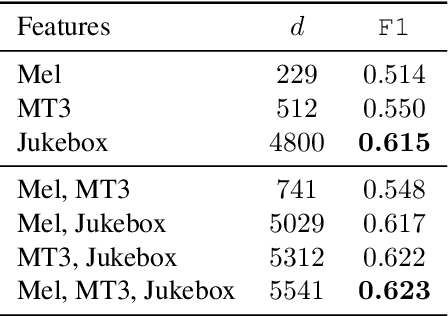

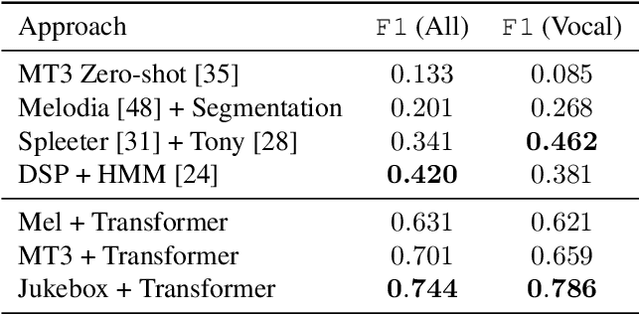
Despite the central role that melody plays in music perception, it remains an open challenge in music information retrieval to reliably detect the notes of the melody present in an arbitrary music recording. A key challenge in melody transcription is building methods which can handle broad audio containing any number of instrument ensembles and musical styles - existing strategies work well for some melody instruments or styles but not all. To confront this challenge, we leverage representations from Jukebox (Dhariwal et al. 2020), a generative model of broad music audio, thereby improving performance on melody transcription by $20$% relative to conventional spectrogram features. Another obstacle in melody transcription is a lack of training data - we derive a new dataset containing $50$ hours of melody transcriptions from crowdsourced annotations of broad music. The combination of generative pre-training and a new dataset for this task results in $77$% stronger performance on melody transcription relative to the strongest available baseline. By pairing our new melody transcription approach with solutions for beat detection, key estimation, and chord recognition, we build Sheet Sage, a system capable of transcribing human-readable lead sheets directly from music audio. Audio examples can be found at https://chrisdonahue.com/sheetsage and code at https://github.com/chrisdonahue/sheetsage .
Universal Source Separation with Weakly Labelled Data
May 11, 2023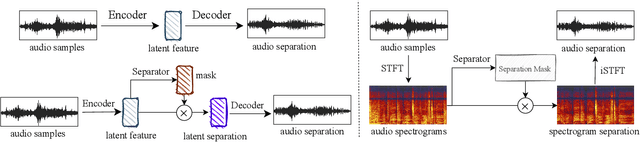
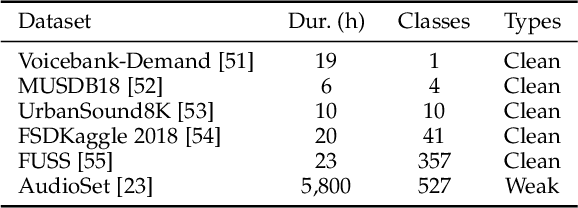
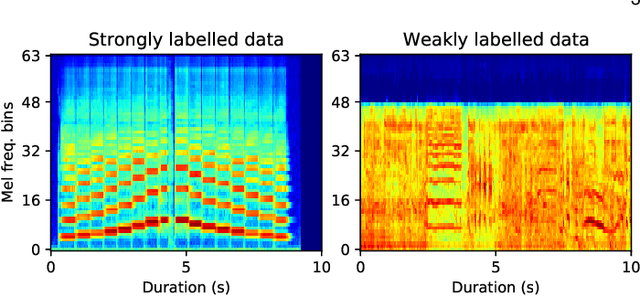

Universal source separation (USS) is a fundamental research task for computational auditory scene analysis, which aims to separate mono recordings into individual source tracks. There are three potential challenges awaiting the solution to the audio source separation task. First, previous audio source separation systems mainly focus on separating one or a limited number of specific sources. There is a lack of research on building a unified system that can separate arbitrary sources via a single model. Second, most previous systems require clean source data to train a separator, while clean source data are scarce. Third, there is a lack of USS system that can automatically detect and separate active sound classes in a hierarchical level. To use large-scale weakly labeled/unlabeled audio data for audio source separation, we propose a universal audio source separation framework containing: 1) an audio tagging model trained on weakly labeled data as a query net; and 2) a conditional source separation model that takes query net outputs as conditions to separate arbitrary sound sources. We investigate various query nets, source separation models, and training strategies and propose a hierarchical USS strategy to automatically detect and separate sound classes from the AudioSet ontology. By solely leveraging the weakly labelled AudioSet, our USS system is successful in separating a wide variety of sound classes, including sound event separation, music source separation, and speech enhancement. The USS system achieves an average signal-to-distortion ratio improvement (SDRi) of 5.57 dB over 527 sound classes of AudioSet; 10.57 dB on the DCASE 2018 Task 2 dataset; 8.12 dB on the MUSDB18 dataset; an SDRi of 7.28 dB on the Slakh2100 dataset; and an SSNR of 9.00 dB on the voicebank-demand dataset. We release the source code at https://github.com/bytedance/uss