 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Leveraging Compressed Frame Sizes For Ultra-Fast Video Classification
Mar 13, 2024
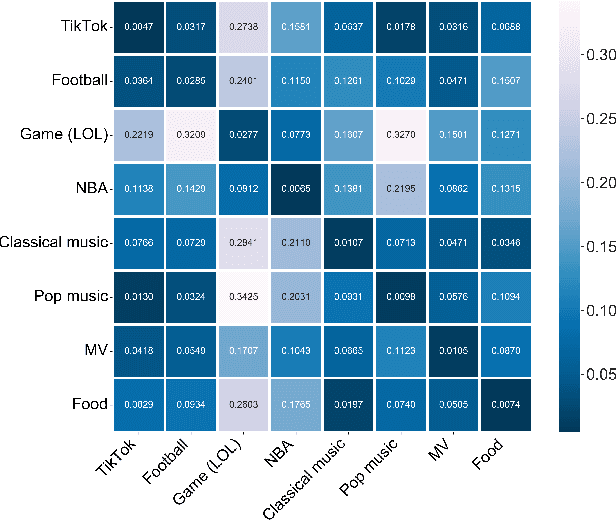
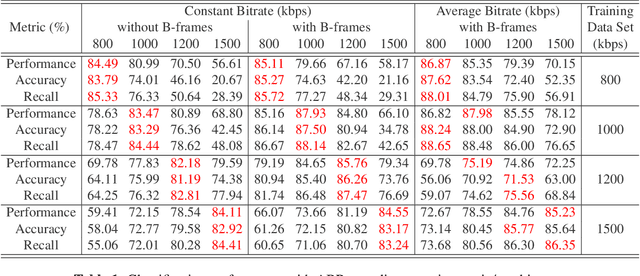
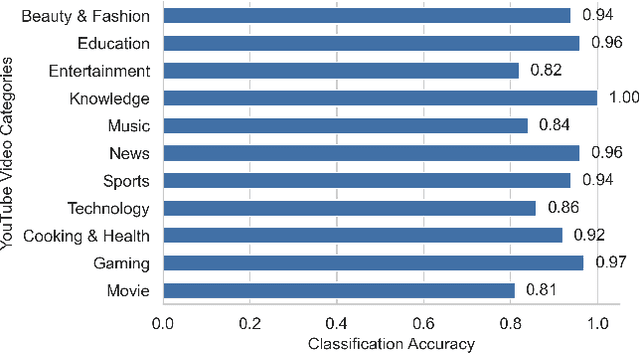
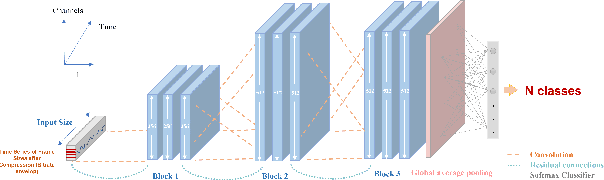
Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially when an immense volume of video content is being constantly generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream decoding. To validate our approach, we built a comprehensive data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our evaluations indicate precision, accuracy, and recall rates consistently above 80%, many exceeding 90%, and some reaching 99%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by seven orders of magnitude.
Neural Networks Hear You Loud And Clear: Hearing Loss Compensation Using Deep Neural Networks
Mar 15, 2024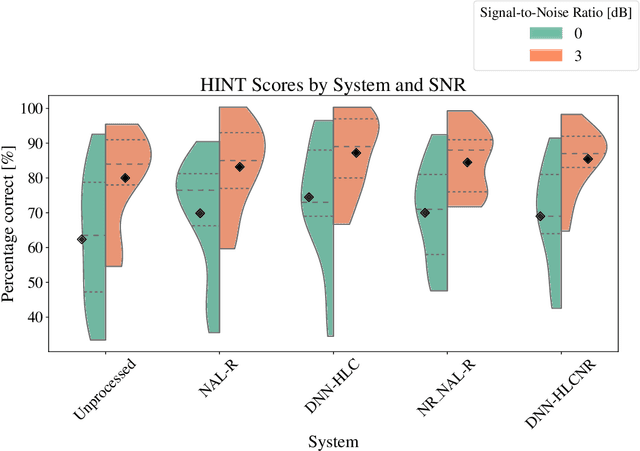
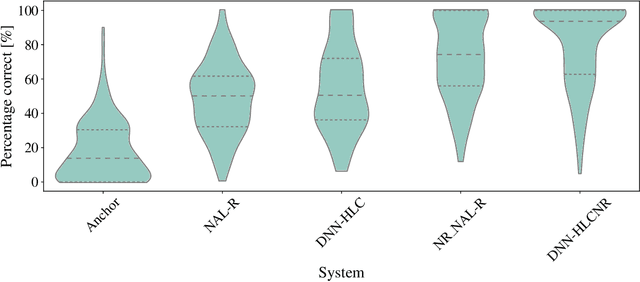
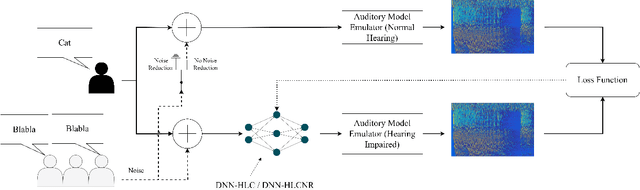
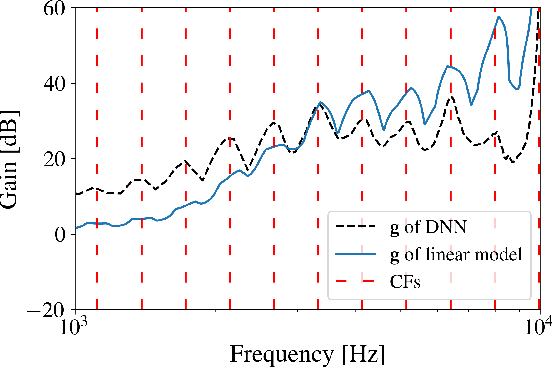
This article investigates the use of deep neural networks (DNNs) for hearing-loss compensation. Hearing loss is a prevalent issue affecting millions of people worldwide, and conventional hearing aids have limitations in providing satisfactory compensation. DNNs have shown remarkable performance in various auditory tasks, including speech recognition, speaker identification, and music classification. In this study, we propose a DNN-based approach for hearing-loss compensation, which is trained on the outputs of hearing-impaired and normal-hearing DNN-based auditory models in response to speech signals. First, we introduce a framework for emulating auditory models using DNNs, focusing on an auditory-nerve model in the auditory pathway. We propose a linearization of the DNN-based approach, which we use to analyze the DNN-based hearing-loss compensation. Additionally we develop a simple approach to choose the acoustic center frequencies of the auditory model used for the compensation strategy. Finally, we evaluate the DNN-based hearing-loss compensation strategies using listening tests with hearing impaired listeners. The results demonstrate that the proposed approach results in feasible hearing-loss compensation strategies. Our proposed approach was shown to provide an increase in speech intelligibility and was found to outperform a conventional approach in terms of perceived speech quality.
SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation
Feb 27, 2024We present SongComposer, an innovative LLM designed for song composition. It could understand and generate melodies and lyrics in symbolic song representations, by leveraging the capability of LLM. Existing music-related LLM treated the music as quantized audio signals, while such implicit encoding leads to inefficient encoding and poor flexibility. In contrast, we resort to symbolic song representation, the mature and efficient way humans designed for music, and enable LLM to explicitly compose songs like humans. In practice, we design a novel tuple design to format lyric and three note attributes (pitch, duration, and rest duration) in the melody, which guarantees the correct LLM understanding of musical symbols and realizes precise alignment between lyrics and melody. To impart basic music understanding to LLM, we carefully collected SongCompose-PT, a large-scale song pretraining dataset that includes lyrics, melodies, and paired lyrics-melodies in either Chinese or English. After adequate pre-training, 10K carefully crafted QA pairs are used to empower the LLM with the instruction-following capability and solve diverse tasks. With extensive experiments, SongComposer demonstrates superior performance in lyric-to-melody generation, melody-to-lyric generation, song continuation, and text-to-song creation, outperforming advanced LLMs like GPT-4.
Group Movie Selection using Multi-channel Emotion Recognition
Mar 11, 2024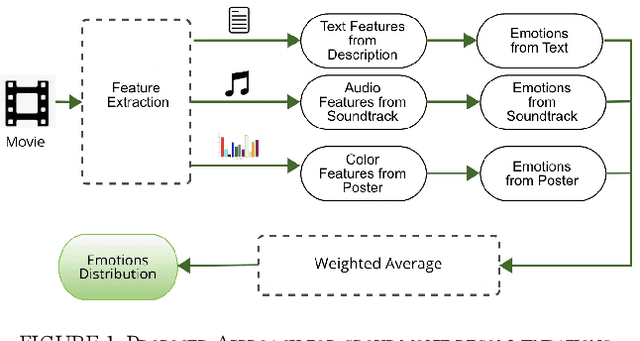

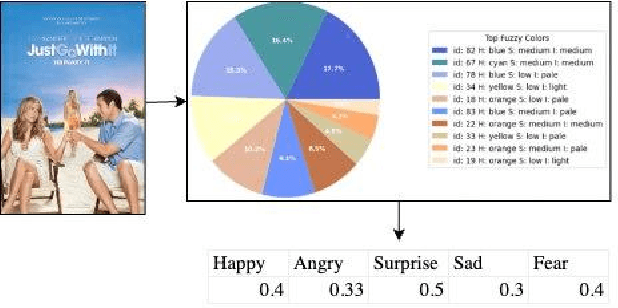

Social activities often done in groups include watching television or movies. Choosing a film that appeals to the emotional inclinations of a varied group can be tricky. One of the most difficult aspects of making group movie suggestions is achieving agreement among members. At the same time, emotion is the most important component that connects the film and the viewer. Current research proposes a methodology for group movie selection that employs emotional analysis from numerous sources, such as film posters, soundtracks, and text. Our research stands at the intersection of emotion recognition technology in music, text, color images, and group decision-making, providing a practical tool for navigating the complex dynamics of film selection in a group setting. The survey participants were given emotion categories and asked to select the emotions that best suited a particular movie. Preliminary comparison results between real and predicted scores show the effectiveness of using emotion detection for group movie recommendation. Such systems have the potential to enhance movie recommendation systems.
Intelligent Director: An Automatic Framework for Dynamic Visual Composition using ChatGPT
Feb 24, 2024With the rise of short video platforms represented by TikTok, the trend of users expressing their creativity through photos and videos has increased dramatically. However, ordinary users lack the professional skills to produce high-quality videos using professional creation software. To meet the demand for intelligent and user-friendly video creation tools, we propose the Dynamic Visual Composition (DVC) task, an interesting and challenging task that aims to automatically integrate various media elements based on user requirements and create storytelling videos. We propose an Intelligent Director framework, utilizing LENS to generate descriptions for images and video frames and combining ChatGPT to generate coherent captions while recommending appropriate music names. Then, the best-matched music is obtained through music retrieval. Then, materials such as captions, images, videos, and music are integrated to seamlessly synthesize the video. Finally, we apply AnimeGANv2 for style transfer. We construct UCF101-DVC and Personal Album datasets and verified the effectiveness of our framework in solving DVC through qualitative and quantitative comparisons, along with user studies, demonstrating its substantial potential.
ScripTONES: Sentiment-Conditioned Music Generation for Movie Scripts
Jan 13, 2024Film scores are considered an essential part of the film cinematic experience, but the process of film score generation is often expensive and infeasible for small-scale creators. Automating the process of film score composition would provide useful starting points for music in small projects. In this paper, we propose a two-stage pipeline for generating music from a movie script. The first phase is the Sentiment Analysis phase where the sentiment of a scene from the film script is encoded into the valence-arousal continuous space. The second phase is the Conditional Music Generation phase which takes as input the valence-arousal vector and conditionally generates piano MIDI music to match the sentiment. We study the efficacy of various music generation architectures by performing a qualitative user survey and propose methods to improve sentiment-conditioning in VAE architectures.
ByteComposer: a Human-like Melody Composition Method based on Language Model Agent
Feb 24, 2024Large Language Models (LLM) have shown encouraging progress in multimodal understanding and generation tasks. However, how to design a human-aligned and interpretable melody composition system is still under-explored. To solve this problem, we propose ByteComposer, an agent framework emulating a human's creative pipeline in four separate steps : "Conception Analysis - Draft Composition - Self-Evaluation and Modification - Aesthetic Selection". This framework seamlessly blends the interactive and knowledge-understanding features of LLMs with existing symbolic music generation models, thereby achieving a melody composition agent comparable to human creators. We conduct extensive experiments on GPT4 and several open-source large language models, which substantiate our framework's effectiveness. Furthermore, professional music composers were engaged in multi-dimensional evaluations, the final results demonstrated that across various facets of music composition, ByteComposer agent attains the level of a novice melody composer.
Exploring Musical Roots: Applying Audio Embeddings to Empower Influence Attribution for a Generative Music Model
Jan 25, 2024Every artist has a creative process that draws inspiration from previous artists and their works. Today, "inspiration" has been automated by generative music models. The black box nature of these models obscures the identity of the works that influence their creative output. As a result, users may inadvertently appropriate, misuse, or copy existing artists' works. We establish a replicable methodology to systematically identify similar pieces of music audio in a manner that is useful for understanding training data attribution. A key aspect of our approach is to harness an effective music audio similarity measure. We compare the effect of applying CLMR and CLAP embeddings to similarity measurement in a set of 5 million audio clips used to train VampNet, a recent open source generative music model. We validate this approach with a human listening study. We also explore the effect that modifications of an audio example (e.g., pitch shifting, time stretching, background noise) have on similarity measurements. This work is foundational to incorporating automated influence attribution into generative modeling, which promises to let model creators and users move from ignorant appropriation to informed creation. Audio samples that accompany this paper are available at https://tinyurl.com/exploring-musical-roots.
OntoChat: a Framework for Conversational Ontology Engineering using Language Models
Mar 09, 2024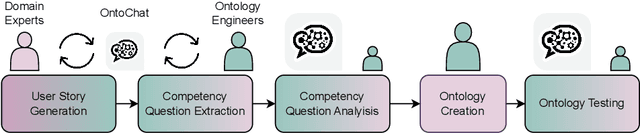
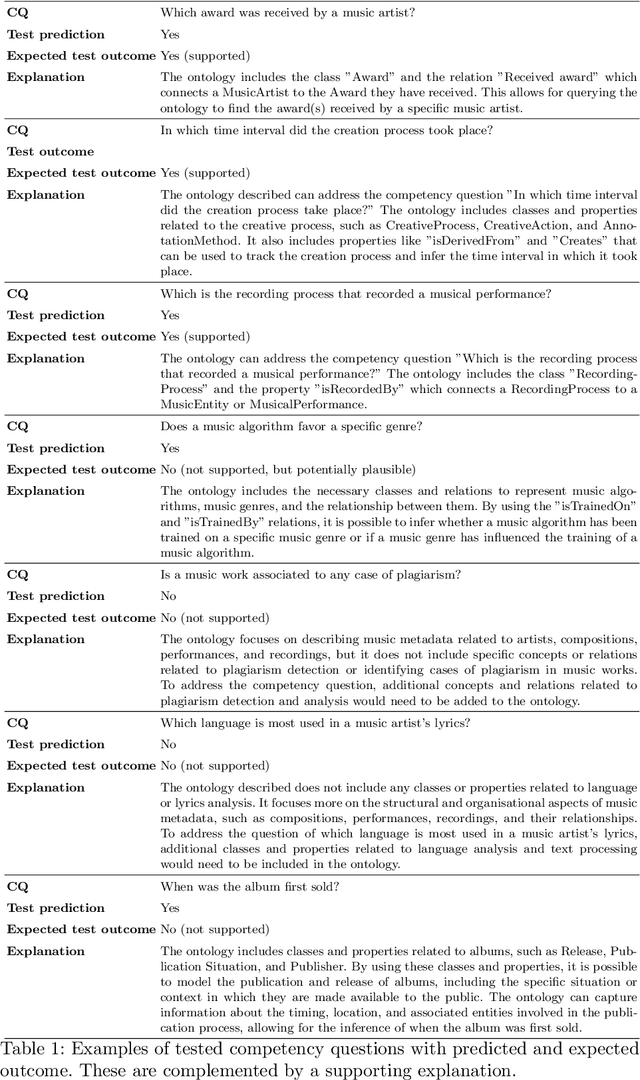
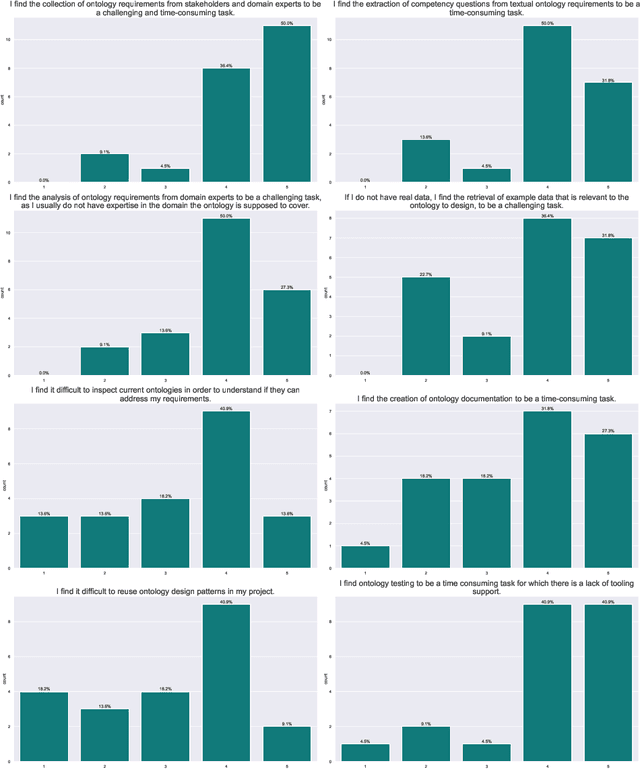
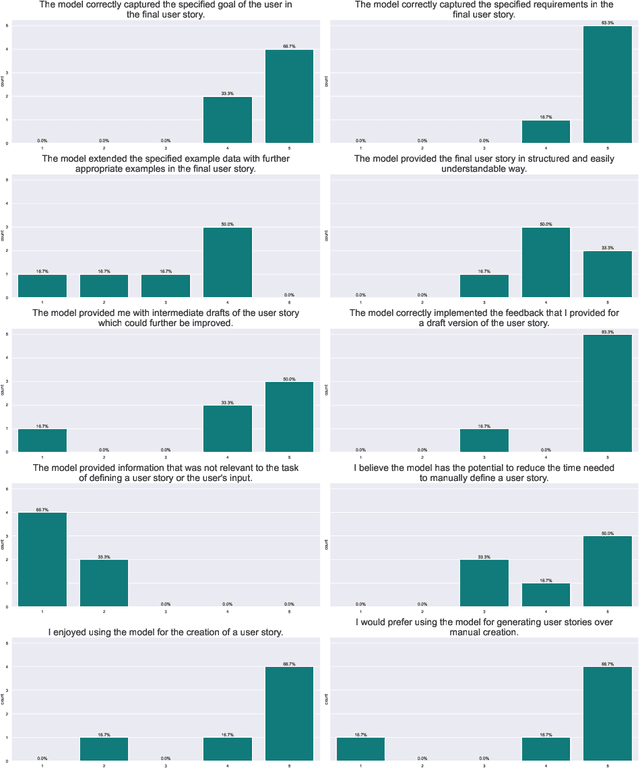
Ontology engineering (OE) in large projects poses a number of challenges arising from the heterogeneous backgrounds of the various stakeholders, domain experts, and their complex interactions with ontology designers. This multi-party interaction often creates systematic ambiguities and biases from the elicitation of ontology requirements, which directly affect the design, evaluation and may jeopardise the target reuse. Meanwhile, current OE methodologies strongly rely on manual activities (e.g., interviews, discussion pages). After collecting evidence on the most crucial OE activities, we introduce OntoChat, a framework for conversational ontology engineering that supports requirement elicitation, analysis, and testing. By interacting with a conversational agent, users can steer the creation of user stories and the extraction of competency questions, while receiving computational support to analyse the overall requirements and test early versions of the resulting ontologies. We evaluate OntoChat by replicating the engineering of the Music Meta Ontology, and collecting preliminary metrics on the effectiveness of each component from users. We release all code at https://github.com/King-s-Knowledge-Graph-Lab/OntoChat.
Link Me Baby One More Time: Social Music Discovery on Spotify
Jan 16, 2024We explore the social and contextual factors that influence the outcome of person-to-person music recommendations and discovery. Specifically, we use data from Spotify to investigate how a link sent from one user to another results in the receiver engaging with the music of the shared artist. We consider several factors that may influence this process, such as the strength of the sender-receiver relationship, the user's role in the Spotify social network, their music social cohesion, and how similar the new artist is to the receiver's taste. We find that the receiver of a link is more likely to engage with a new artist when (1) they have similar music taste to the sender and the shared track is a good fit for their taste, (2) they have a stronger and more intimate tie with the sender, and (3) the shared artist is popular with the receiver's connections. Finally, we use these findings to build a Random Forest classifier to predict whether a shared music track will result in the receiver's engagement with the shared artist. This model elucidates which type of social and contextual features are most predictive, although peak performance is achieved when a diverse set of features are included. These findings provide new insights into the multifaceted mechanisms underpinning the interplay between music discovery and social processes.