 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Privacy-Preserving Remote Heart Rate Estimation from Facial Videos
Jun 01, 2023
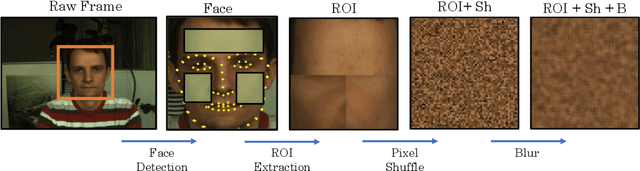
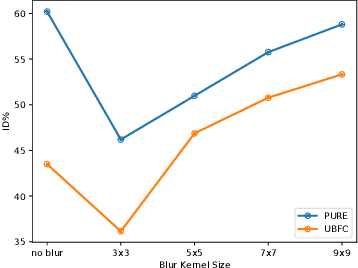
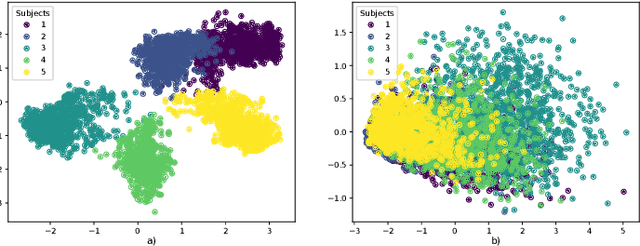

Remote Photoplethysmography (rPPG) is the process of estimating PPG from facial videos. While this approach benefits from contactless interaction, it is reliant on videos of faces, which often constitutes an important privacy concern. Recent research has revealed that deep learning techniques are vulnerable to attacks, which can result in significant data breaches making deep rPPG estimation even more sensitive. To address this issue, we propose a data perturbation method that involves extraction of certain areas of the face with less identity-related information, followed by pixel shuffling and blurring. Our experiments on two rPPG datasets (PURE and UBFC) show that our approach reduces the accuracy of facial recognition algorithms by over 60%, with minimal impact on rPPG extraction. We also test our method on three facial recognition datasets (LFW, CALFW, and AgeDB), where our approach reduced performance by nearly 50%. Our findings demonstrate the potential of our approach as an effective privacy-preserving solution for rPPG estimation.
Novel Smart N95 Filtering Facepiece Respirator with Real-time Adaptive Fit Functionality and Wireless Humidity Monitoring for Enhanced Wearable Comfort
Sep 09, 2023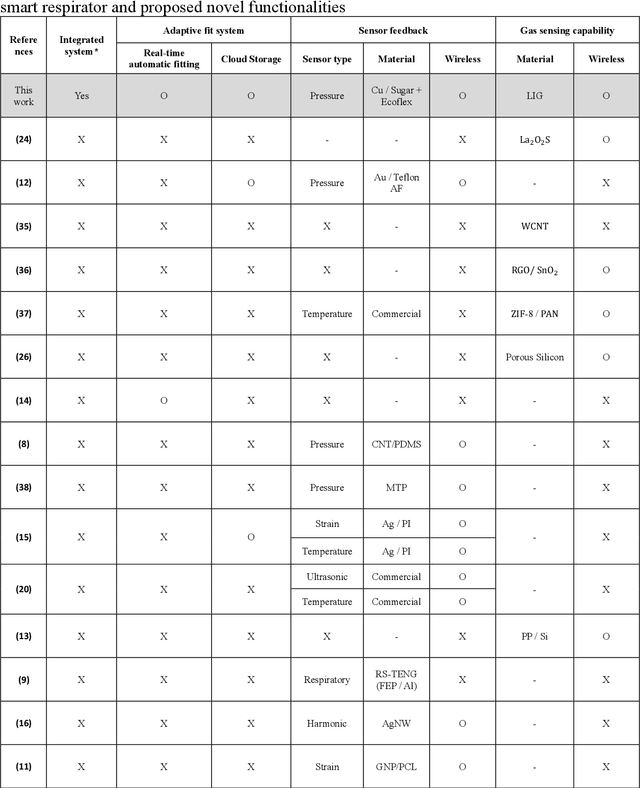
The widespread emergence of the COVID-19 pandemic has transformed our lifestyle, and facial respirators have become an essential part of daily life. Nevertheless, the current respirators possess several limitations such as poor respirator fit because they are incapable of covering diverse human facial sizes and shapes, potentially diminishing the effect of wearing respirators. In addition, the current facial respirators do not inform the user of the air quality within the smart facepiece respirator in case of continuous long-term use. Here, we demonstrate the novel smart N-95 filtering facepiece respirator that incorporates the humidity sensor and pressure sensory feedback-enabled self-fit adjusting functionality for the effective performance of the facial respirator to prevent the transmission of airborne pathogens. The laser-induced graphene (LIG) constitutes the humidity sensor, and the pressure sensor array based on the dielectric elastomeric sponge monitors the respirator contact on the face of the user, providing the sensory information for a closed-loop feedback mechanism. As a result of the self-fit adjusting mode along with elastomeric lining, the fit factor is increased by 3.20 and 5 times at average and maximum respectively. We expect that the experimental proof-of-concept of this work will offer viable solutions to the current commercial respirators to address the limitations.
IFaceUV: Intuitive Motion Facial Image Generation by Identity Preservation via UV map
Jun 08, 2023
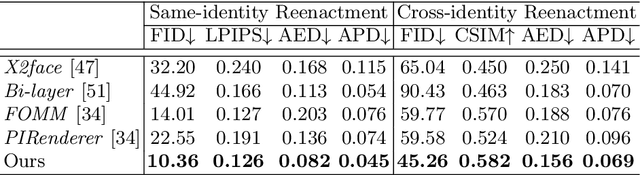
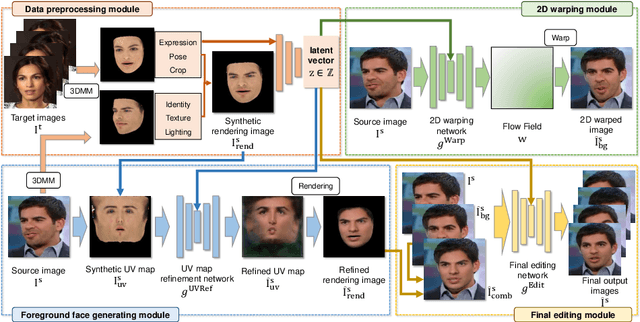
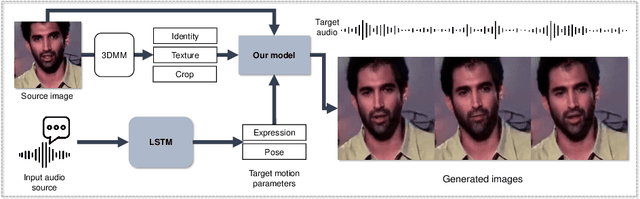
Reenacting facial images is an important task that can find numerous applications. We proposed IFaceUV, a fully differentiable pipeline that properly combines 2D and 3D information to conduct the facial reenactment task. The three-dimensional morphable face models (3DMMs) and corresponding UV maps are utilized to intuitively control facial motions and textures, respectively. Two-dimensional techniques based on 2D image warping is further required to compensate for missing components of the 3DMMs such as backgrounds, ear, hair and etc. In our pipeline, we first extract 3DMM parameters and corresponding UV maps from source and target images. Then, initial UV maps are refined by the UV map refinement network and it is rendered to the image with the motion manipulated 3DMM parameters. In parallel, we warp the source image according to the 2D flow field obtained from the 2D warping network. Rendered and warped images are combined in the final editing network to generate the final reenactment image. Additionally, we tested our model for the audio-driven facial reenactment task. Extensive qualitative and quantitative experiments illustrate the remarkable performance of our method compared to other state-of-the-art methods.
Realistic Speech-to-Face Generation with Speech-Conditioned Latent Diffusion Model with Face Prior
Oct 05, 2023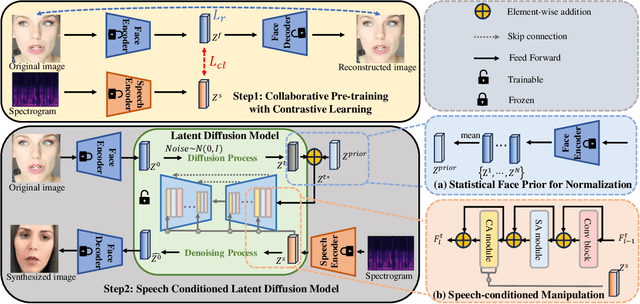
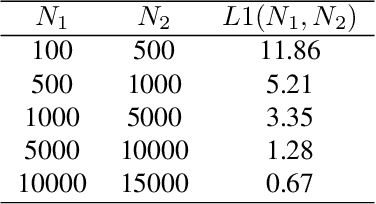

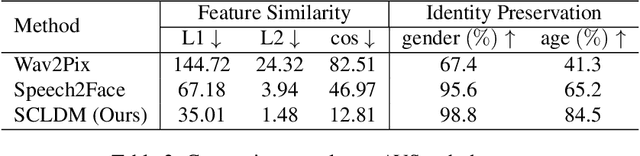
Speech-to-face generation is an intriguing area of research that focuses on generating realistic facial images based on a speaker's audio speech. However, state-of-the-art methods employing GAN-based architectures lack stability and cannot generate realistic face images. To fill this gap, we propose a novel speech-to-face generation framework, which leverages a Speech-Conditioned Latent Diffusion Model, called SCLDM. To the best of our knowledge, this is the first work to harness the exceptional modeling capabilities of diffusion models for speech-to-face generation. Preserving the shared identity information between speech and face is crucial in generating realistic results. Therefore, we employ contrastive pre-training for both the speech encoder and the face encoder. This pre-training strategy facilitates effective alignment between the attributes of speech, such as age and gender, and the corresponding facial characteristics in the face images. Furthermore, we tackle the challenge posed by excessive diversity in the synthesis process caused by the diffusion model. To overcome this challenge, we introduce the concept of residuals by integrating a statistical face prior to the diffusion process. This addition helps to eliminate the shared component across the faces and enhances the subtle variations captured by the speech condition. Extensive quantitative, qualitative, and user study experiments demonstrate that our method can produce more realistic face images while preserving the identity of the speaker better than state-of-the-art methods. Highlighting the notable enhancements, our method demonstrates significant gains in all metrics on the AVSpeech dataset and Voxceleb dataset, particularly noteworthy are the improvements of 32.17 and 32.72 on the cosine distance metric for the two datasets, respectively.
3D Structure-guided Network for Tooth Alignment in 2D Photograph
Oct 17, 2023Orthodontics focuses on rectifying misaligned teeth (i.e., malocclusions), affecting both masticatory function and aesthetics. However, orthodontic treatment often involves complex, lengthy procedures. As such, generating a 2D photograph depicting aligned teeth prior to orthodontic treatment is crucial for effective dentist-patient communication and, more importantly, for encouraging patients to accept orthodontic intervention. In this paper, we propose a 3D structure-guided tooth alignment network that takes 2D photographs as input (e.g., photos captured by smartphones) and aligns the teeth within the 2D image space to generate an orthodontic comparison photograph featuring aesthetically pleasing, aligned teeth. Notably, while the process operates within a 2D image space, our method employs 3D intra-oral scanning models collected in clinics to learn about orthodontic treatment, i.e., projecting the pre- and post-orthodontic 3D tooth structures onto 2D tooth contours, followed by a diffusion model to learn the mapping relationship. Ultimately, the aligned tooth contours are leveraged to guide the generation of a 2D photograph with aesthetically pleasing, aligned teeth and realistic textures. We evaluate our network on various facial photographs, demonstrating its exceptional performance and strong applicability within the orthodontic industry.
CLIP2Protect: Protecting Facial Privacy using Text-Guided Makeup via Adversarial Latent Search
Jun 20, 2023
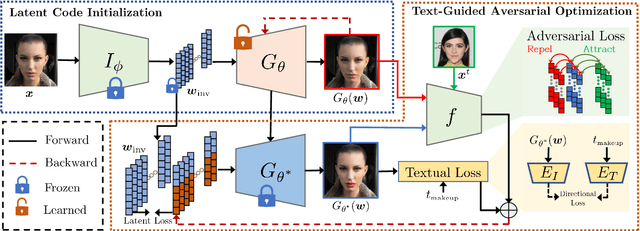

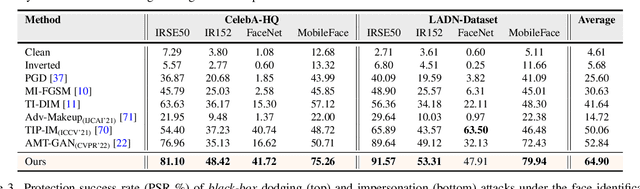
The success of deep learning based face recognition systems has given rise to serious privacy concerns due to their ability to enable unauthorized tracking of users in the digital world. Existing methods for enhancing privacy fail to generate naturalistic images that can protect facial privacy without compromising user experience. We propose a novel two-step approach for facial privacy protection that relies on finding adversarial latent codes in the low-dimensional manifold of a pretrained generative model. The first step inverts the given face image into the latent space and finetunes the generative model to achieve an accurate reconstruction of the given image from its latent code. This step produces a good initialization, aiding the generation of high-quality faces that resemble the given identity. Subsequently, user-defined makeup text prompts and identity-preserving regularization are used to guide the search for adversarial codes in the latent space. Extensive experiments demonstrate that faces generated by our approach have stronger black-box transferability with an absolute gain of 12.06% over the state-of-the-art facial privacy protection approach under the face verification task. Finally, we demonstrate the effectiveness of the proposed approach for commercial face recognition systems. Our code is available at https://github.com/fahadshamshad/Clip2Protect.
* Accepted in CVPR 2023. Project page: https://fahadshamshad.github.io/Clip2Protect/
Fine-Grained Annotation for Face Anti-Spoofing
Oct 12, 2023
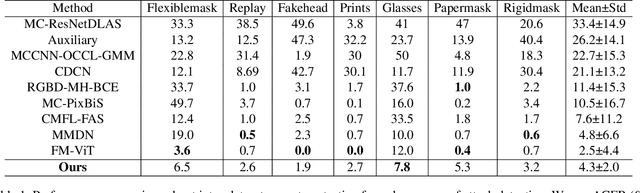
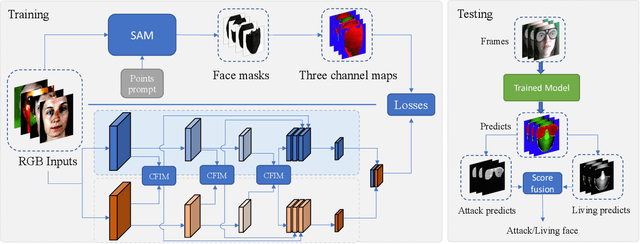
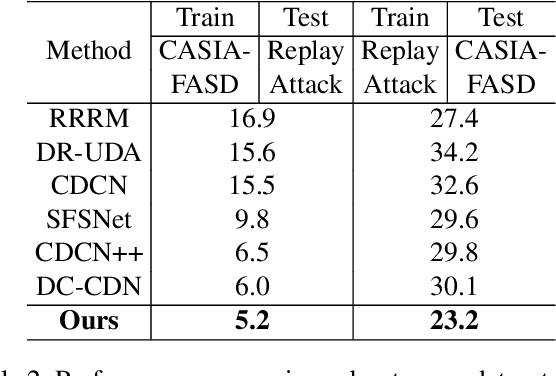
Face anti-spoofing plays a critical role in safeguarding facial recognition systems against presentation attacks. While existing deep learning methods show promising results, they still suffer from the lack of fine-grained annotations, which lead models to learn task-irrelevant or unfaithful features. In this paper, we propose a fine-grained annotation method for face anti-spoofing. Specifically, we first leverage the Segment Anything Model (SAM) to obtain pixel-wise segmentation masks by utilizing face landmarks as point prompts. The face landmarks provide segmentation semantics, which segments the face into regions. We then adopt these regions as masks and assemble them into three separate annotation maps: spoof, living, and background maps. Finally, we combine three separate maps into a three-channel map as annotations for model training. Furthermore, we introduce the Multi-Channel Region Exchange Augmentation (MCREA) to diversify training data and reduce overfitting. Experimental results demonstrate that our method outperforms existing state-of-the-art approaches in both intra-dataset and cross-dataset evaluations.
DT-NeRF: Decomposed Triplane-Hash Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
Sep 14, 2023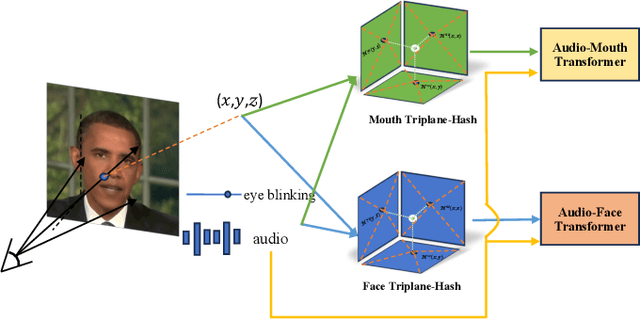
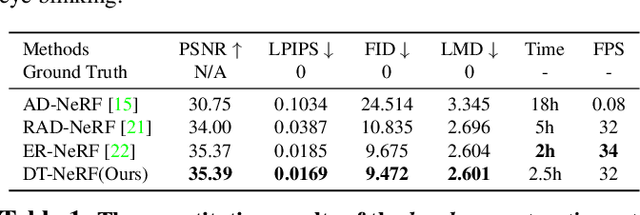
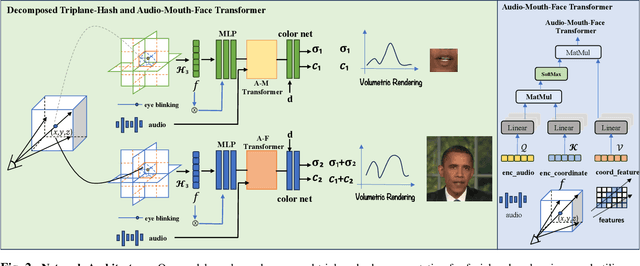
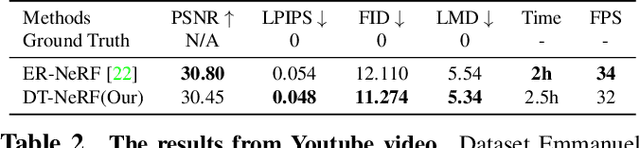
In this paper, we present the decomposed triplane-hash neural radiance fields (DT-NeRF), a framework that significantly improves the photorealistic rendering of talking faces and achieves state-of-the-art results on key evaluation datasets. Our architecture decomposes the facial region into two specialized triplanes: one specialized for representing the mouth, and the other for the broader facial features. We introduce audio features as residual terms and integrate them as query vectors into our model through an audio-mouth-face transformer. Additionally, our method leverages the capabilities of Neural Radiance Fields (NeRF) to enrich the volumetric representation of the entire face through additive volumetric rendering techniques. Comprehensive experimental evaluations corroborate the effectiveness and superiority of our proposed approach.
PAtt-Lite: Lightweight Patch and Attention MobileNet for Challenging Facial Expression Recognition
Jun 16, 2023


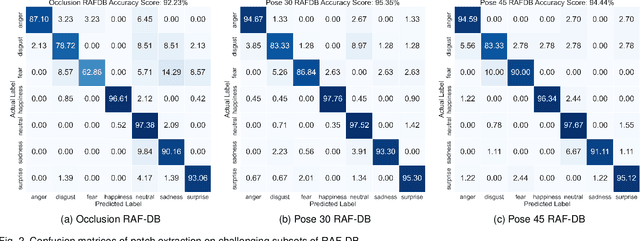
Facial Expression Recognition (FER) is a machine learning problem that deals with recognizing human facial expressions. While existing work has achieved performance improvements in recent years, FER in the wild and under challenging conditions remains a challenge. In this paper, a lightweight patch and attention network based on MobileNetV1, referred to as PAtt-Lite, is proposed to improve FER performance under challenging conditions. A truncated ImageNet-pre-trained MobileNetV1 is utilized as the backbone feature extractor of the proposed method. In place of the truncated layers is a patch extraction block that is proposed for extracting significant local facial features to enhance the representation from MobileNetV1, especially under challenging conditions. An attention classifier is also proposed to improve the learning of these patched feature maps from the extremely lightweight feature extractor. The experimental results on public benchmark databases proved the effectiveness of the proposed method. PAtt-Lite achieved state-of-the-art results on CK+, RAF-DB, FER2013, FERPlus, and the challenging conditions subsets for RAF-DB and FERPlus. The source code for the proposed method will be available at https://github.com/JLREx/PAtt-Lite.
Face Aging via Diffusion-based Editing
Sep 20, 2023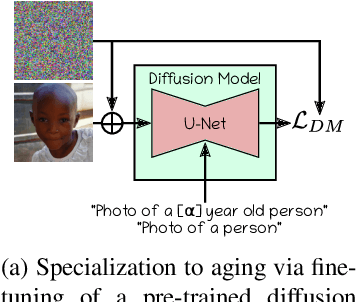
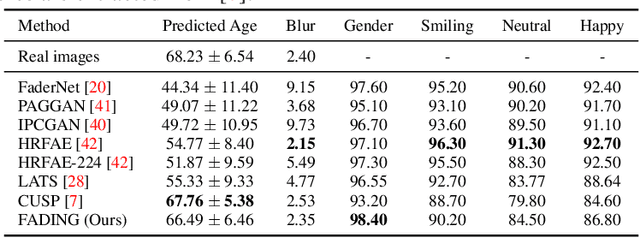


In this paper, we address the problem of face aging: generating past or future facial images by incorporating age-related changes to the given face. Previous aging methods rely solely on human facial image datasets and are thus constrained by their inherent scale and bias. This restricts their application to a limited generatable age range and the inability to handle large age gaps. We propose FADING, a novel approach to address Face Aging via DIffusion-based editiNG. We go beyond existing methods by leveraging the rich prior of large-scale language-image diffusion models. First, we specialize a pre-trained diffusion model for the task of face age editing by using an age-aware fine-tuning scheme. Next, we invert the input image to latent noise and obtain optimized null text embeddings. Finally, we perform text-guided local age editing via attention control. The quantitative and qualitative analyses demonstrate that our method outperforms existing approaches with respect to aging accuracy, attribute preservation, and aging quality.