 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Learning Oracle Attention for High-fidelity Face Completion
Mar 31, 2020

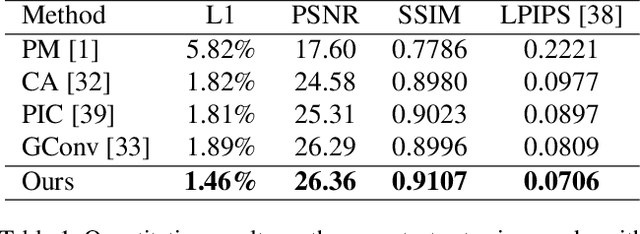
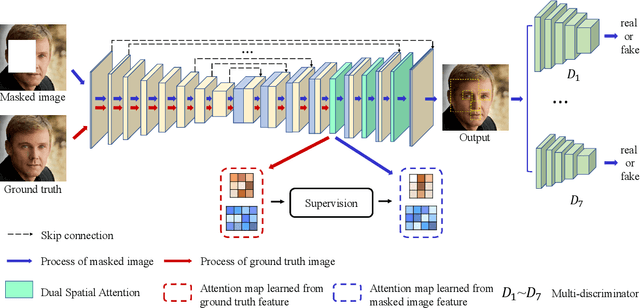

High-fidelity face completion is a challenging task due to the rich and subtle facial textures involved. What makes it more complicated is the correlations between different facial components, for example, the symmetry in texture and structure between both eyes. While recent works adopted the attention mechanism to learn the contextual relations among elements of the face, they have largely overlooked the disastrous impacts of inaccurate attention scores; in addition, they fail to pay sufficient attention to key facial components, the completion results of which largely determine the authenticity of a face image. Accordingly, in this paper, we design a comprehensive framework for face completion based on the U-Net structure. Specifically, we propose a dual spatial attention module to efficiently learn the correlations between facial textures at multiple scales; moreover, we provide an oracle supervision signal to the attention module to ensure that the obtained attention scores are reasonable. Furthermore, we take the location of the facial components as prior knowledge and impose a multi-discriminator on these regions, with which the fidelity of facial components is significantly promoted. Extensive experiments on two high-resolution face datasets including CelebA-HQ and Flickr-Faces-HQ demonstrate that the proposed approach outperforms state-of-the-art methods by large margins.
How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks)
Sep 07, 2017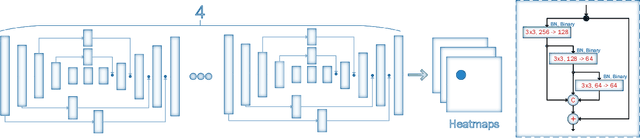
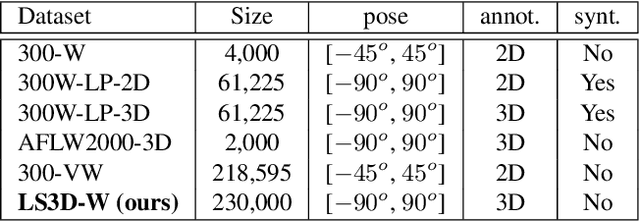
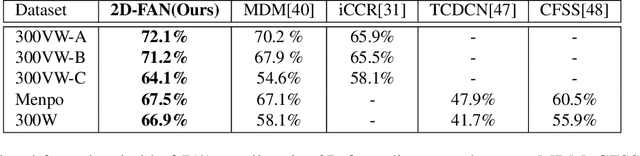
This paper investigates how far a very deep neural network is from attaining close to saturating performance on existing 2D and 3D face alignment datasets. To this end, we make the following 5 contributions: (a) we construct, for the first time, a very strong baseline by combining a state-of-the-art architecture for landmark localization with a state-of-the-art residual block, train it on a very large yet synthetically expanded 2D facial landmark dataset and finally evaluate it on all other 2D facial landmark datasets. (b) We create a guided by 2D landmarks network which converts 2D landmark annotations to 3D and unifies all existing datasets, leading to the creation of LS3D-W, the largest and most challenging 3D facial landmark dataset to date ~230,000 images. (c) Following that, we train a neural network for 3D face alignment and evaluate it on the newly introduced LS3D-W. (d) We further look into the effect of all "traditional" factors affecting face alignment performance like large pose, initialization and resolution, and introduce a "new" one, namely the size of the network. (e) We show that both 2D and 3D face alignment networks achieve performance of remarkable accuracy which is probably close to saturating the datasets used. Training and testing code as well as the dataset can be downloaded from https://www.adrianbulat.com/face-alignment/
LiMuSE: Lightweight Multi-modal Speaker Extraction
Nov 07, 2021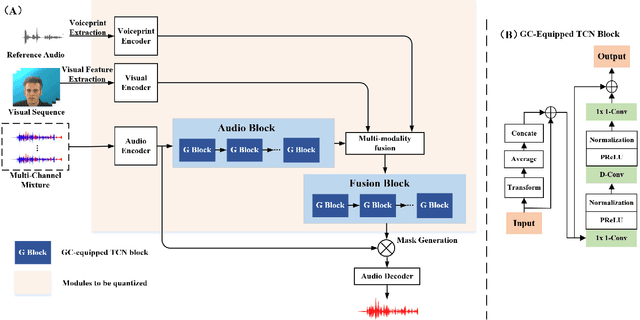

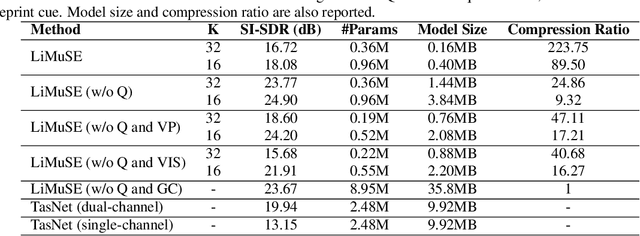
The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
Jul 29, 2020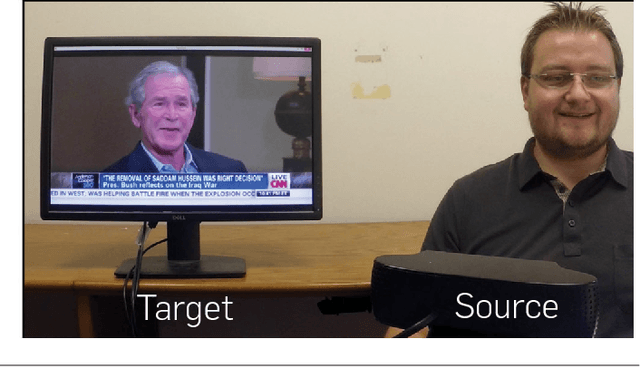
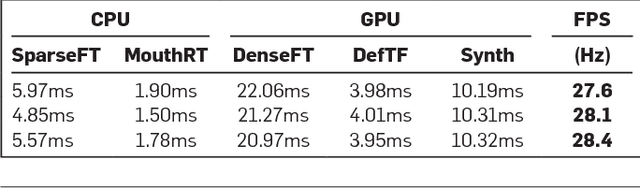
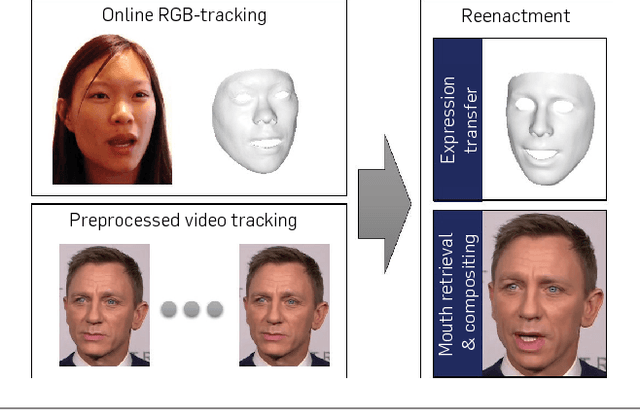

We present Face2Face, a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. Our goal is to animate the facial expressions of the target video by a source actor and re-render the manipulated output video in a photo-realistic fashion. To this end, we first address the under-constrained problem of facial identity recovery from monocular video by non-rigid model-based bundling. At run time, we track facial expressions of both source and target video using a dense photometric consistency measure. Reenactment is then achieved by fast and efficient deformation transfer between source and target. The mouth interior that best matches the re-targeted expression is retrieved from the target sequence and warped to produce an accurate fit. Finally, we convincingly re-render the synthesized target face on top of the corresponding video stream such that it seamlessly blends with the real-world illumination. We demonstrate our method in a live setup, where Youtube videos are reenacted in real time.
Will You Ever Become Popular? Learning to Predict Virality of Dance Clips
Nov 06, 2021
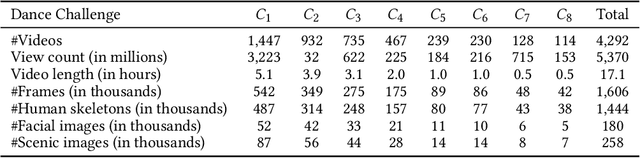
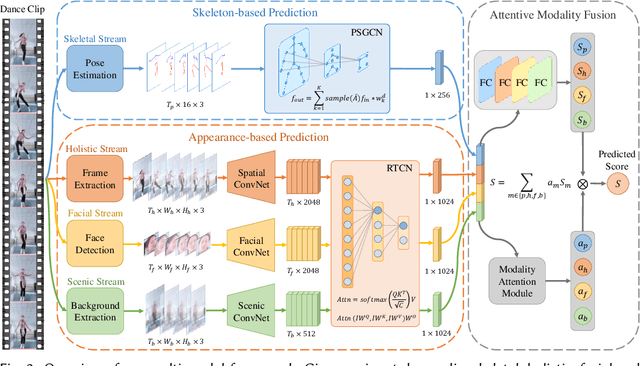
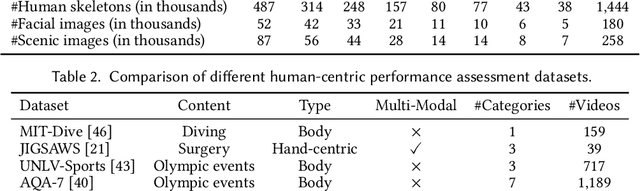
Dance challenges are going viral in video communities like TikTok nowadays. Once a challenge becomes popular, thousands of short-form videos will be uploaded in merely a couple of days. Therefore, virality prediction from dance challenges is of great commercial value and has a wide range of applications, such as smart recommendation and popularity promotion. In this paper, a novel multi-modal framework which integrates skeletal, holistic appearance, facial and scenic cues is proposed for comprehensive dance virality prediction. To model body movements, we propose a pyramidal skeleton graph convolutional network (PSGCN) which hierarchically refines spatio-temporal skeleton graphs. Meanwhile, we introduce a relational temporal convolutional network (RTCN) to exploit appearance dynamics with non-local temporal relations. An attentive fusion approach is finally proposed to adaptively aggregate predictions from different modalities. To validate our method, we introduce a large-scale viral dance video (VDV) dataset, which contains over 4,000 dance clips of eight viral dance challenges. Extensive experiments on the VDV dataset demonstrate the efficacy of our model. Extensive experiments on the VDV dataset well demonstrate the effectiveness of our approach. Furthermore, we show that short video applications like multi-dimensional recommendation and action feedback can be derived from our model.
Sequential Clustering based Facial Feature Extraction Method for Automatic Creation of Facial Models from Orthogonal Views
Dec 03, 2009
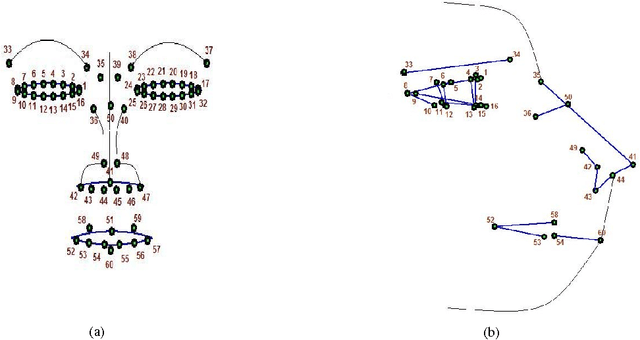

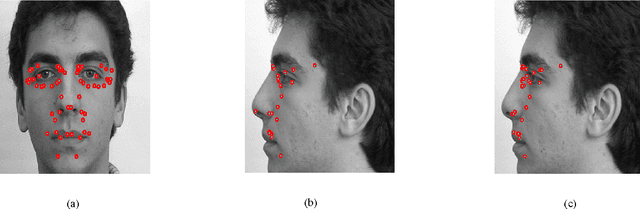
Multiview 3D face modeling has attracted increasing attention recently and has become one of the potential avenues in future video systems. We aim to make more reliable and robust automatic feature extraction and natural 3D feature construction from 2D features detected on a pair of frontal and profile view face images. We propose several heuristic algorithms to minimize possible errors introduced by prevalent nonperfect orthogonal condition and noncoherent luminance. In our approach, we first extract the 2D features that are visible to both cameras in both views. Then, we estimate the coordinates of the features in the hidden profile view based on the visible features extracted in the two orthogonal views. Finally, based on the coordinates of the extracted features, we deform a 3D generic model to perform the desired 3D clone modeling. Present study proves the scope of resulted facial models for practical applications like face recognition and facial animation.
* 6 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
CapsField: Light Field-based Face and Expression Recognition in the Wild using Capsule Routing
Jan 10, 2021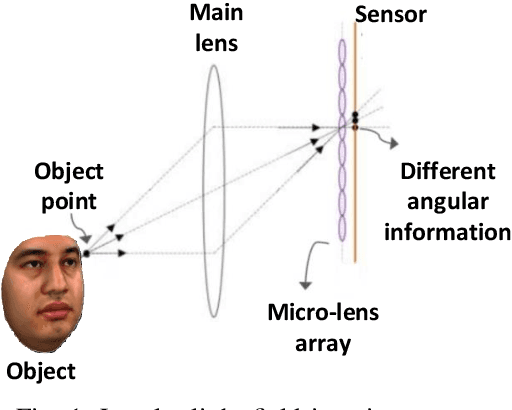
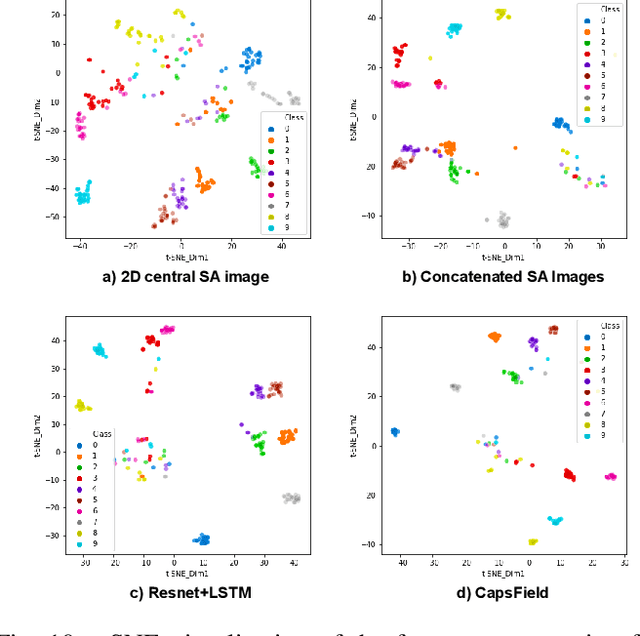
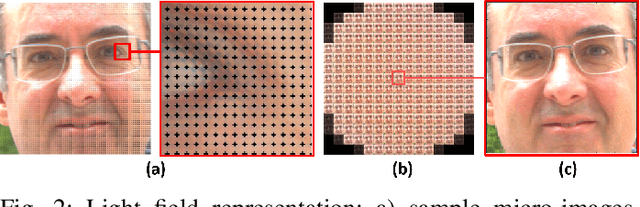
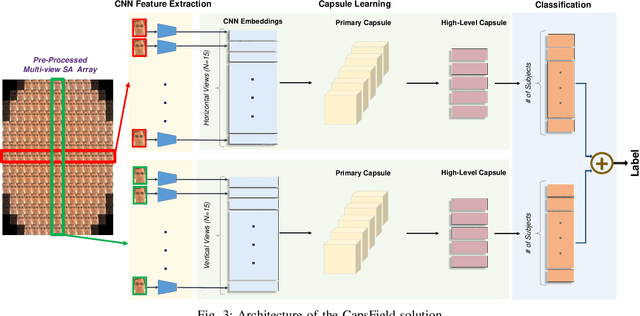
Light field (LF) cameras provide rich spatio-angular visual representations by sensing the visual scene from multiple perspectives and have recently emerged as a promising technology to boost the performance of human-machine systems such as biometrics and affective computing. Despite the significant success of LF representation for constrained facial image analysis, this technology has never been used for face and expression recognition in the wild. In this context, this paper proposes a new deep face and expression recognition solution, called CapsField, based on a convolutional neural network and an additional capsule network that utilizes dynamic routing to learn hierarchical relations between capsules. CapsField extracts the spatial features from facial images and learns the angular part-whole relations for a selected set of 2D sub-aperture images rendered from each LF image. To analyze the performance of the proposed solution in the wild, the first in the wild LF face dataset, along with a new complementary constrained face dataset captured from the same subjects recorded earlier have been captured and are made available. A subset of the in the wild dataset contains facial images with different expressions, annotated for usage in the context of face expression recognition tests. An extensive performance assessment study using the new datasets has been conducted for the proposed and relevant prior solutions, showing that the CapsField proposed solution achieves superior performance for both face and expression recognition tasks when compared to the state-of-the-art.
Pipeline Generative Adversarial Networks for Facial Images Generation with Multiple Attributes
Nov 29, 2017
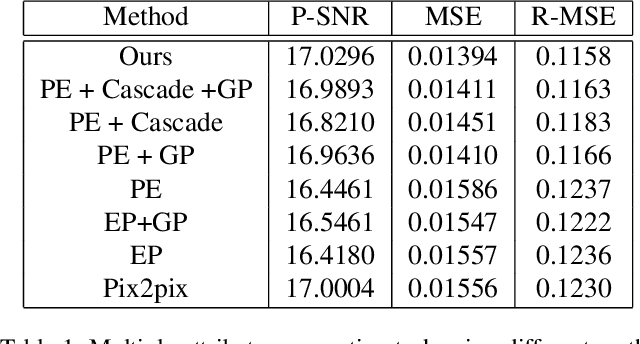
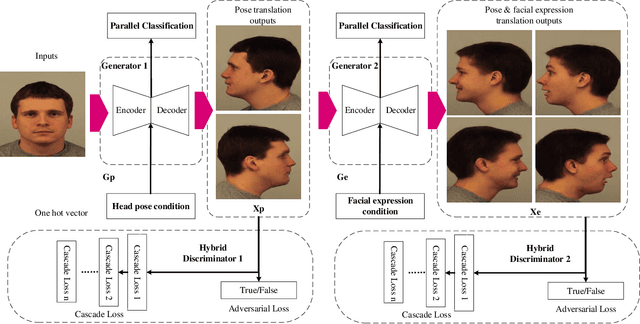
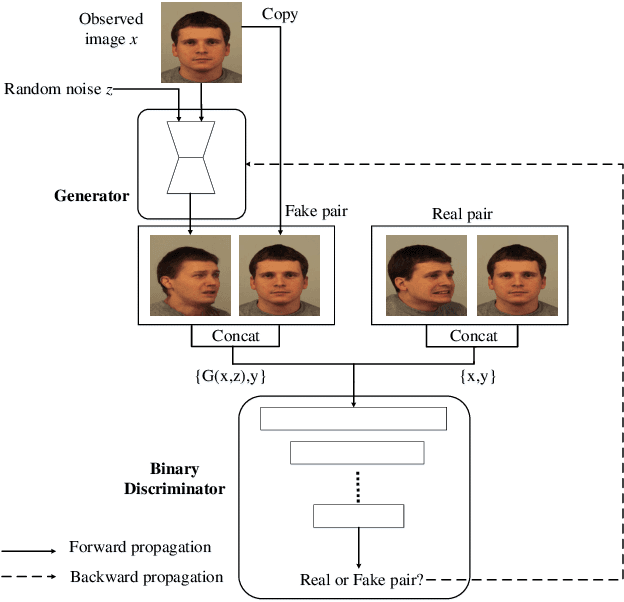
Generative Adversarial Networks are proved to be efficient on various kinds of image generation tasks. However, it is still a challenge if we want to generate images precisely. Many researchers focus on how to generate images with one attribute. But image generation under multiple attributes is still a tough work. In this paper, we try to generate a variety of face images under multiple constraints using a pipeline process. The Pip-GAN (Pipeline Generative Adversarial Network) we present employs a pipeline network structure which can generate a complex facial image step by step using a neutral face image. We applied our method on two face image databases and demonstrate its ability to generate convincing novel images of unseen identities under multiple conditions previously.
Disentangling Latent Space for Unsupervised Semantic Face Editing
Nov 05, 2020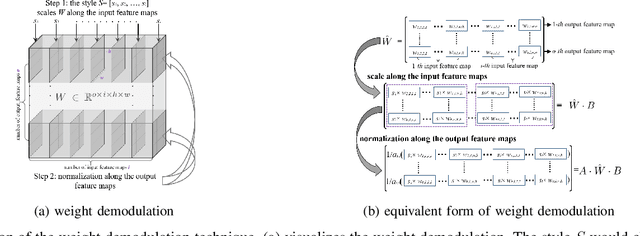
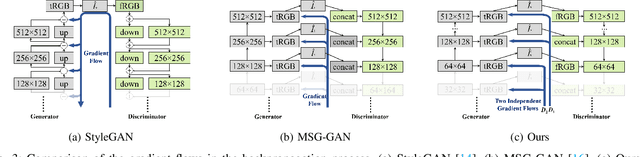

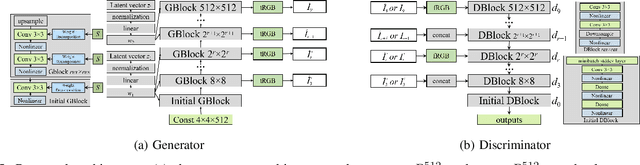
Editing facial images created by StyleGAN is a popular research topic with important applications. Through editing the latent vectors, it is possible to control the facial attributes such as smile, age, \textit{etc}. However, facial attributes are entangled in the latent space and this makes it very difficult to independently control a specific attribute without affecting the others. The key to developing neat semantic control is to completely disentangle the latent space and perform image editing in an unsupervised manner. In this paper, we present a new technique termed Structure-Texture Independent Architecture with Weight Decomposition and Orthogonal Regularization (STIA-WO) to disentangle the latent space. The GAN model, applying STIA-WO, is referred to as STGAN-WO. STGAN-WO performs weight decomposition by utilizing the style vector to construct a fully controllable weight matrix for controlling the image synthesis, and utilizes orthogonal regularization to ensure each entry of the style vector only controls one factor of variation. To further disentangle the facial attributes, STGAN-WO introduces a structure-texture independent architecture which utilizes two independently and identically distributed (i.i.d.) latent vectors to control the synthesis of the texture and structure components in a disentangled way.Unsupervised semantic editing is achieved by moving the latent code in the coarse layers along its orthogonal directions to change texture related attributes or changing the latent code in the fine layers to manipulate structure related ones. We present experimental results which show that our new STGAN-WO can achieve better attribute editing than state of the art methods (The code is available at https://github.com/max-liu-112/STGAN-WO)
On Recognizing Occluded Faces in the Wild
Sep 11, 2021

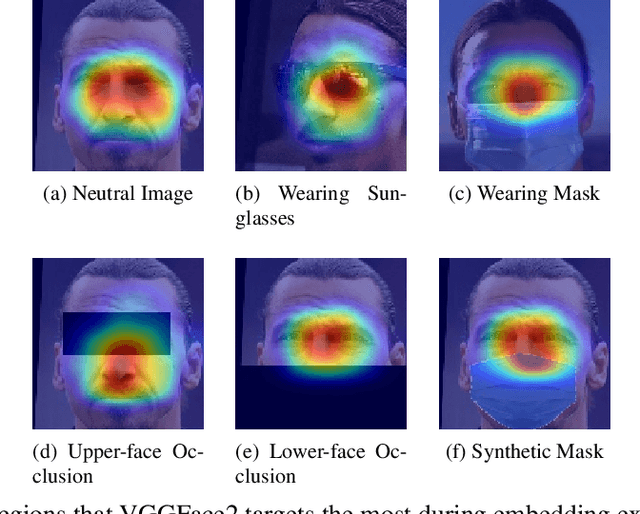
Facial appearance variations due to occlusion has been one of the main challenges for face recognition systems. To facilitate further research in this area, it is necessary and important to have occluded face datasets collected from real-world, as synthetically generated occluded faces cannot represent the nature of the problem. In this paper, we present the Real World Occluded Faces (ROF) dataset, that contains faces with both upper face occlusion, due to sunglasses, and lower face occlusion, due to masks. We propose two evaluation protocols for this dataset. Benchmark experiments on the dataset have shown that no matter how powerful the deep face representation models are, their performance degrades significantly when they are tested on real-world occluded faces. It is observed that the performance drop is far less when the models are tested on synthetically generated occluded faces. The ROF dataset and the associated evaluation protocols are publicly available at the following link https://github.com/ekremerakin/RealWorldOccludedFaces.