 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITC-RWKV: Interactive Tissue-Cell Modeling with Recurrent Key-Value Aggregation for Histopathological Subtyping
Oct 24, 2025Accurate interpretation of histopathological images demands integration of information across spatial and semantic scales, from nuclear morphology and cellular textures to global tissue organization and disease-specific patterns. Although recent foundation models in pathology have shown strong capabilities in capturing global tissue context, their omission of cell-level feature modeling remains a key limitation for fine-grained tasks such as cancer subtype classification. To address this, we propose a dual-stream architecture that models the interplay between macroscale tissue features and aggregated cellular representations. To efficiently aggregate information from large cell sets, we propose a receptance-weighted key-value aggregation model, a recurrent transformer that captures inter-cell dependencies with linear complexity. Furthermore, we introduce a bidirectional tissue-cell interaction module to enable mutual attention between localized cellular cues and their surrounding tissue environment. Experiments on four histopathological subtype classification benchmarks show that the proposed method outperforms existing models, demonstrating the critical role of cell-level aggregation and tissue-cell interaction in fine-grained computational pathology.
QWD-GAN: Quality-aware Wavelet-driven GAN for Unsupervised Medical Microscopy Images Denoising
Sep 19, 2025



Image denoising plays a critical role in biomedical and microscopy imaging, especially when acquiring wide-field fluorescence-stained images. This task faces challenges in multiple fronts, including limitations in image acquisition conditions, complex noise types, algorithm adaptability, and clinical application demands. Although many deep learning-based denoising techniques have demonstrated promising results, further improvements are needed in preserving image details, enhancing algorithmic efficiency, and increasing clinical interpretability. We propose an unsupervised image denoising method based on a Generative Adversarial Network (GAN) architecture. The approach introduces a multi-scale adaptive generator based on the Wavelet Transform and a dual-branch discriminator that integrates difference perception feature maps with original features. Experimental results on multiple biomedical microscopy image datasets show that the proposed model achieves state-of-the-art denoising performance, particularly excelling in the preservation of high-frequency information. Furthermore, the dual-branch discriminator is seamlessly compatible with various GAN frameworks. The proposed quality-aware, wavelet-driven GAN denoising model is termed as QWD-GAN.
PointGS: Point Attention-Aware Sparse View Synthesis with Gaussian Splatting
Jun 12, 20253D Gaussian splatting (3DGS) is an innovative rendering technique that surpasses the neural radiance field (NeRF) in both rendering speed and visual quality by leveraging an explicit 3D scene representation. Existing 3DGS approaches require a large number of calibrated views to generate a consistent and complete scene representation. When input views are limited, 3DGS tends to overfit the training views, leading to noticeable degradation in rendering quality. To address this limitation, we propose a Point-wise Feature-Aware Gaussian Splatting framework that enables real-time, high-quality rendering from sparse training views. Specifically, we first employ the latest stereo foundation model to estimate accurate camera poses and reconstruct a dense point cloud for Gaussian initialization. We then encode the colour attributes of each 3D Gaussian by sampling and aggregating multiscale 2D appearance features from sparse inputs. To enhance point-wise appearance representation, we design a point interaction network based on a self-attention mechanism, allowing each Gaussian point to interact with its nearest neighbors. These enriched features are subsequently decoded into Gaussian parameters through two lightweight multi-layer perceptrons (MLPs) for final rendering. Extensive experiments on diverse benchmarks demonstrate that our method significantly outperforms NeRF-based approaches and achieves competitive performance under few-shot settings compared to the state-of-the-art 3DGS methods.
Lattice piecewise affine approximation of explicit nonlinear model predictive control with application to trajectory tracking of mobile robot
Feb 16, 2023



To promote the widespread use of mobile robots in diverse fields, the performance of trajectory tracking must be ensured. To address the constraints and nonlinear features associated with mobile robot systems, we apply nonlinear model predictive control (MPC) to realize the trajectory tracking of mobile robots. Specifically, to alleviate the online computational complexity of nonlinear MPC, this paper devises a lattice piecewise affine (PWA) approximation method that can approximate both the nonlinear system and control law of explicit nonlinear MPC. The kinematic model of the mobile robot is successively linearized along the trajectory to obtain a linear time-varying description of the system, which is then expressed using a lattice PWA model. Subsequently, the nonlinear MPC problem can be transformed into a series of linear MPC problems. Furthermore, to reduce the complexity of online calculation of multiple linear MPC problems, we approximate the optimal solution of the linear MPC by using the lattice PWA model. That is, for different sampling states, the optimal control inputs are obtained, and lattice PWA approximations are constructed for the state control pairs. Simulations are performed to evaluate the performance of our method in comparison with the linear MPC and explicit linear MPC frameworks. The results show that compared with the explicit linear MPC, our method has a higher online computing speed and can decrease the offline computing time without significantly increasing the tracking error.
LiMuSE: Lightweight Multi-modal Speaker Extraction
Nov 07, 2021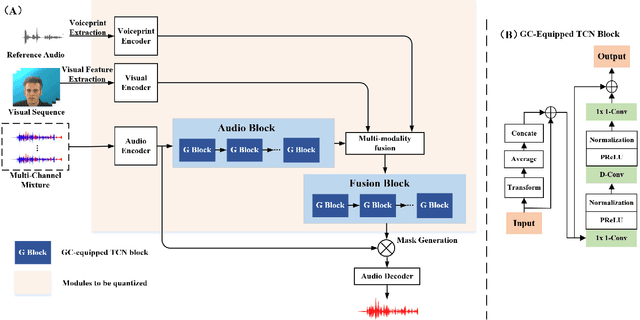

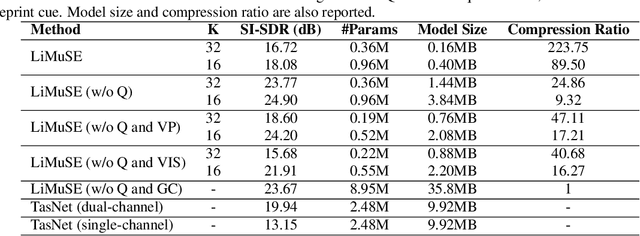
The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.