 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMuSE: Lightweight Multi-modal Speaker Extraction
Paper and Code
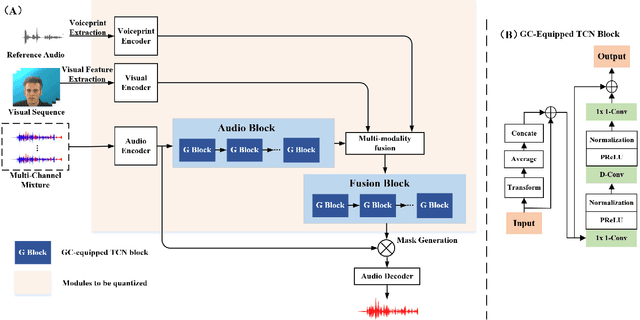

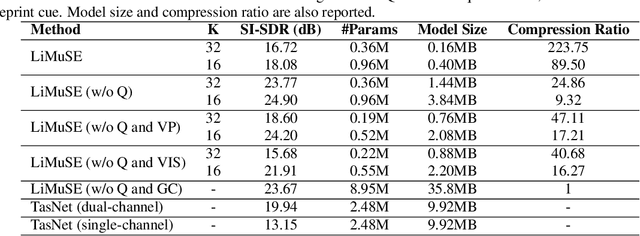
The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.