 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Identity-Obscured Neural Radiance Fields: Privacy-Preserving 3D Facial Reconstruction
Dec 07, 2023
Neural radiance fields (NeRF) typically require a complete set of images taken from multiple camera perspectives to accurately reconstruct geometric details. However, this approach raise significant privacy concerns in the context of facial reconstruction. The critical need for privacy protection often leads invidividuals to be reluctant in sharing their facial images, due to fears of potential misuse or security risks. Addressing these concerns, we propose a method that leverages privacy-preserving images for reconstructing 3D head geometry within the NeRF framework. Our method stands apart from traditional facial reconstruction techniques as it does not depend on RGB information from images containing sensitive facial data. Instead, it effectively generates plausible facial geometry using a series of identity-obscured inputs, thereby protecting facial privacy.
Facial Emotion Recognition using CNN in PyTorch
Dec 17, 2023In this project, we have implemented a model to recognize real-time facial emotions given the camera images. Current approaches would read all data and input it into their model, which has high space complexity. Our model is based on the Convolutional Neural Network utilizing the PyTorch library. We believe our implementation will significantly improve the space complexity and provide a useful contribution to facial emotion recognition. Our motivation is to understanding clearly about deep learning, particularly in CNNs, and analysis real-life scenarios. Therefore, we tunned the hyper parameter of model such as learning rate, batch size, and number of epochs to meet our needs. In addition, we also used techniques to optimize the networks, such as activation function, dropout and max pooling. Finally, we analyzed the result from two optimizer to observe the relationship between number of epochs and accuracy.
Multimodal Machine Learning Combining Facial Images and Clinical Texts Improves Diagnosis of Rare Genetic Diseases
Dec 23, 2023Individuals with suspected rare genetic disorders often undergo multiple clinical evaluations, imaging studies, laboratory tests and genetic tests, to find a possible answer over a prolonged period of multiple years. Addressing this diagnostic odyssey thus have substantial clinical, psychosocial, and economic benefits. Many rare genetic diseases have distinctive facial features, which can be used by artificial intelligence algorithms to facilitate clinical diagnosis, in prioritizing candidate diseases to be further examined by lab tests or genetic assays, or in helping the phenotype-driven reinterpretation of genome/exome sequencing data. However, existing methods using frontal facial photo were built on conventional Convolutional Neural Networks (CNNs), rely exclusively on facial images, and cannot capture non-facial phenotypic traits and demographic information essential for guiding accurate diagnoses. Here we introduce GestaltMML, a multimodal machine learning (MML) approach solely based on the Transformer architecture. It integrates the facial images, demographic information (age, sex, ethnicity), and clinical notes of patients to improve prediction accuracy. Furthermore, we also introduce GestaltGPT, a GPT-based methodology with few-short learning capacities that exclusively harnesses textual inputs using a range of large language models (LLMs) including Llama 2, GPT-J and Falcon. We evaluated these methods on a diverse range of datasets, including 449 diseases from the GestaltMatcher Database, several in-house datasets on Beckwith-Wiedemann syndrome, Sotos syndrome, NAA10-related syndrome (neurodevelopmental syndrome) and others. Our results suggest that GestaltMML/GestaltGPT effectively incorporate multiple modalities of data, greatly narrow down candidate genetic diagnosis of rare diseases, and may facilitate the reinterpretation of genome/exome sequencing data.
Implicit Neural Representation for Physics-driven Actuated Soft Bodies
Jan 26, 2024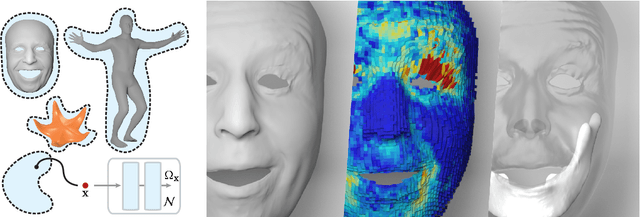

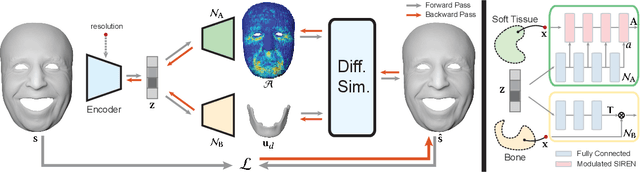
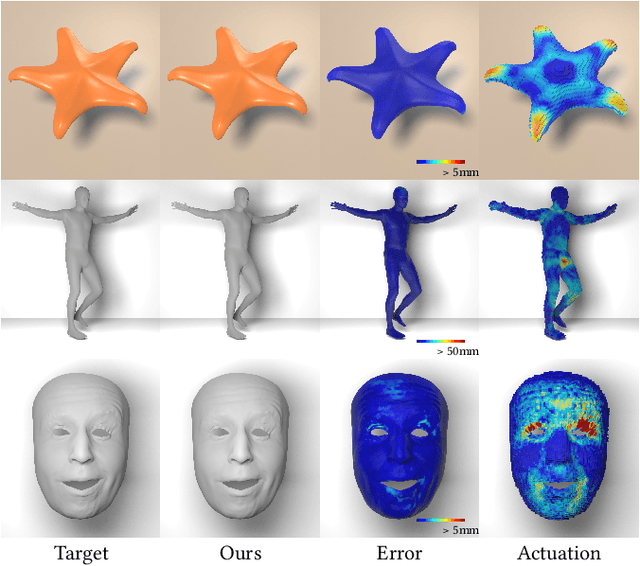
Active soft bodies can affect their shape through an internal actuation mechanism that induces a deformation. Similar to recent work, this paper utilizes a differentiable, quasi-static, and physics-based simulation layer to optimize for actuation signals parameterized by neural networks. Our key contribution is a general and implicit formulation to control active soft bodies by defining a function that enables a continuous mapping from a spatial point in the material space to the actuation value. This property allows us to capture the signal's dominant frequencies, making the method discretization agnostic and widely applicable. We extend our implicit model to mandible kinematics for the particular case of facial animation and show that we can reliably reproduce facial expressions captured with high-quality capture systems. We apply the method to volumetric soft bodies, human poses, and facial expressions, demonstrating artist-friendly properties, such as simple control over the latent space and resolution invariance at test time.
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Feb 02, 2024There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images. Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models, or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution. Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation. InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin. Our codes and pre-trained checkpoints will be available at https://github.com/InstantID/InstantID.
Mitigating Algorithmic Bias on Facial Expression Recognition
Dec 23, 2023Biased datasets are ubiquitous and present a challenge for machine learning. For a number of categories on a dataset that are equally important but some are sparse and others are common, the learning algorithms will favor the ones with more presence. The problem of biased datasets is especially sensitive when dealing with minority people groups. How can we, from biased data, generate algorithms that treat every person equally? This work explores one way to mitigate bias using a debiasing variational autoencoder with experiments on facial expression recognition.
BdSLW60: A Word-Level Bangla Sign Language Dataset
Feb 13, 2024Sign language discourse is an essential mode of daily communication for the deaf and hard-of-hearing people. However, research on Bangla Sign Language (BdSL) faces notable limitations, primarily due to the lack of datasets. Recognizing wordlevel signs in BdSL (WL-BdSL) presents a multitude of challenges, including the need for well-annotated datasets, capturing the dynamic nature of sign gestures from facial or hand landmarks, developing suitable machine learning or deep learning-based models with substantial video samples, and so on. In this paper, we address these challenges by creating a comprehensive BdSL word-level dataset named BdSLW60 in an unconstrained and natural setting, allowing positional and temporal variations and allowing sign users to change hand dominance freely. The dataset encompasses 60 Bangla sign words, with a significant scale of 9307 video trials provided by 18 signers under the supervision of a sign language professional. The dataset was rigorously annotated and cross-checked by 60 annotators. We also introduced a unique approach of a relative quantization-based key frame encoding technique for landmark based sign gesture recognition. We report the benchmarking of our BdSLW60 dataset using the Support Vector Machine (SVM) with testing accuracy up to 67.6% and an attention-based bi-LSTM with testing accuracy up to 75.1%. The dataset is available at https://www.kaggle.com/datasets/hasaniut/bdslw60 and the code base is accessible from https://github.com/hasanssl/BdSLW60_Code.
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Dec 07, 2023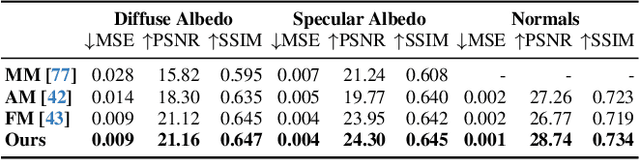
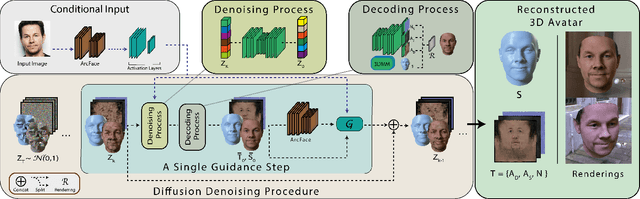

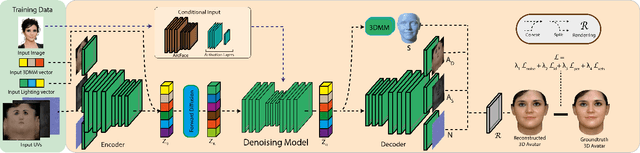
The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by achieving far better performance than GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. This model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an "in-the-wild" 2D facial image. Our multi-modal diffusion model concurrently outputs facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
FER-C: Benchmarking Out-of-Distribution Soft Calibration for Facial Expression Recognition
Dec 16, 2023We present a soft benchmark for calibrating facial expression recognition (FER). While prior works have focused on identifying affective states, we find that FER models are uncalibrated. This is particularly true when out-of-distribution (OOD) shifts further exacerbate the ambiguity of facial expressions. While most OOD benchmarks provide hard labels, we argue that the ground-truth labels for evaluating FER models should be soft in order to better reflect the ambiguity behind facial behaviours. Our framework proposes soft labels that closely approximates the average information loss based on different types of OOD shifts. Finally, we show the benefits of calibration on five state-of-the-art FER algorithms tested on our benchmark.
Does ChatGPT and Whisper Make Humanoid Robots More Relatable?
Feb 11, 2024Humanoid robots are designed to be relatable to humans for applications such as customer support and helpdesk services. However, many such systems, including Softbank's Pepper, fall short because they fail to communicate effectively with humans. The advent of Large Language Models (LLMs) shows the potential to solve the communication barrier for humanoid robotics. This paper outlines the comparison of different Automatic Speech Recognition (ASR) APIs, the integration of Whisper ASR and ChatGPT with the Pepper robot and the evaluation of the system (Pepper-GPT) tested by 15 human users. The comparison result shows that, compared to the Google ASR and Google Cloud ASR, the Whisper ASR performed best as its average Word Error Rate (1.716%) and processing time (2.639 s) are both the lowest. The participants' usability investigations show that 60% of the participants thought the performance of the Pepper-GPT was "excellent", while the rest rated this system as "good" in the subsequent experiments. It is proved that while some problems still need to be overcome, such as the robot's multilingual ability and facial tracking capacity, users generally responded positively to the system, feeling like talking to an actual human.