 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Gaussian Vector: An Efficient Solution for Facial Landmark Detection
Oct 03, 2020

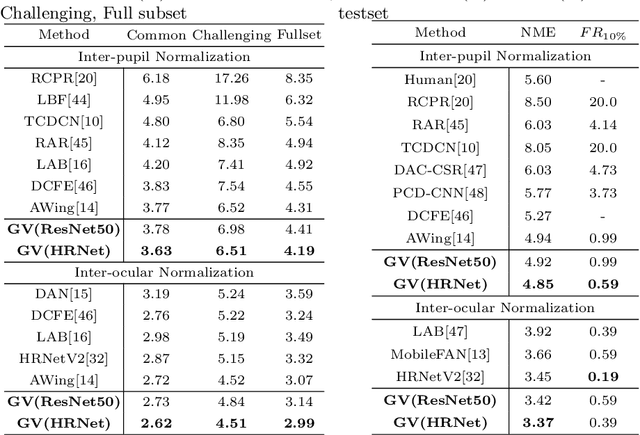
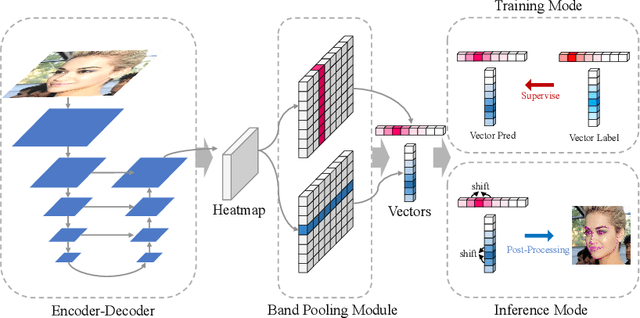
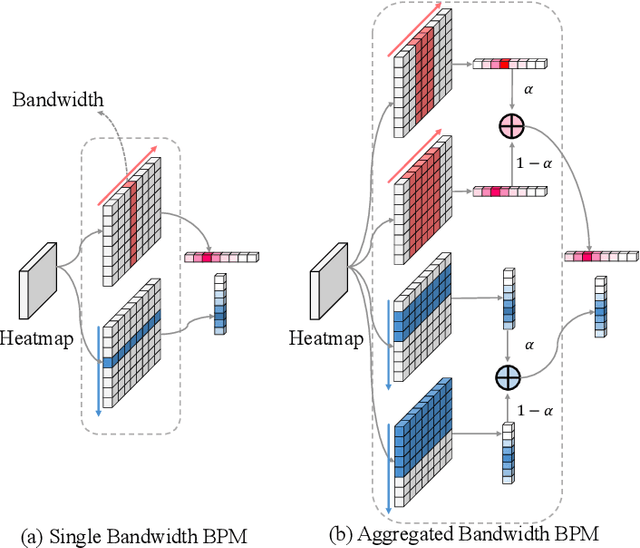
Significant progress has been made in facial landmark detection with the development of Convolutional Neural Networks. The widely-used algorithms can be classified into coordinate regression methods and heatmap based methods. However, the former loses spatial information, resulting in poor performance while the latter suffers from large output size or high post-processing complexity. This paper proposes a new solution, Gaussian Vector, to preserve the spatial information as well as reduce the output size and simplify the post-processing. Our method provides novel vector supervision and introduces Band Pooling Module to convert heatmap into a pair of vectors for each landmark. This is a plug-and-play component which is simple and effective. Moreover, Beyond Box Strategy is proposed to handle the landmarks out of the face bounding box. We evaluate our method on 300W, COFW, WFLW and JD-landmark. That the results significantly surpass previous works demonstrates the effectiveness of our approach.
RethNet: Object-by-Object Learning for Detecting Facial Skin Problems
Jan 11, 2021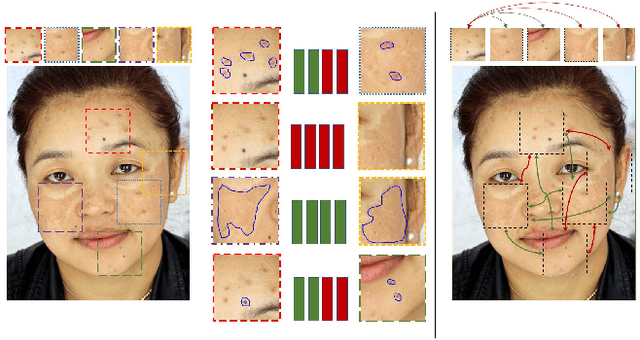

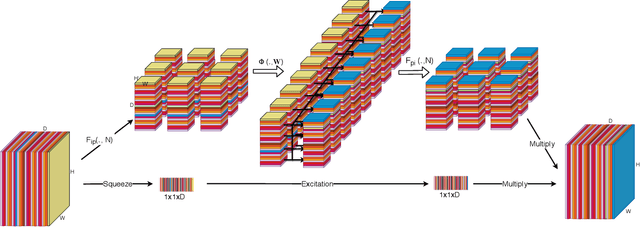
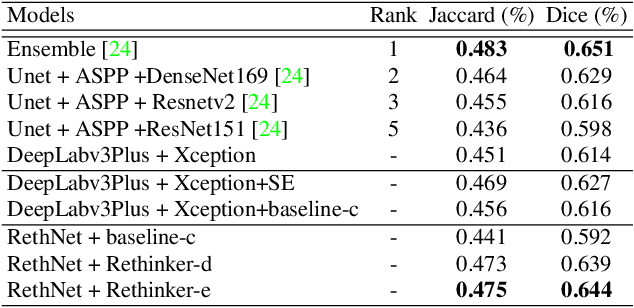
Semantic segmentation is a hot topic in computer vision where the most challenging tasks of object detection and recognition have been handling by the success of semantic segmentation approaches. We propose a concept of object-by-object learning technique to detect 11 types of facial skin lesions using semantic segmentation methods. Detecting individual skin lesion in a dense group is a challenging task, because of ambiguities in the appearance of the visual data. We observe that there exist co-occurrent visual relations between object classes (e.g., wrinkle and age spot, or papule and whitehead, etc.). In fact, rich contextual information significantly helps to handle the issue. Therefore, we propose REthinker blocks that are composed of the locally constructed convLSTM/Conv3D layers and SE module as a one-shot attention mechanism whose responsibility is to increase network's sensitivity in the local and global contextual representation that supports to capture ambiguously appeared objects and co-occurrence interactions between object classes. Experiments show that our proposed model reached MIoU of 79.46% on the test of a prepared dataset, representing a 15.34% improvement over Deeplab v3+ (MIoU of 64.12%).
Video2StyleGAN: Encoding Video in Latent Space for Manipulation
Jun 27, 2022
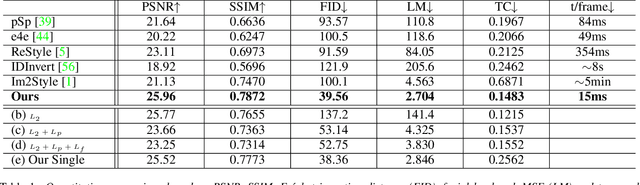
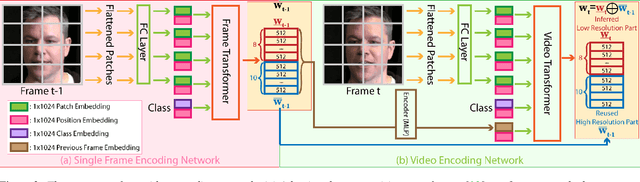
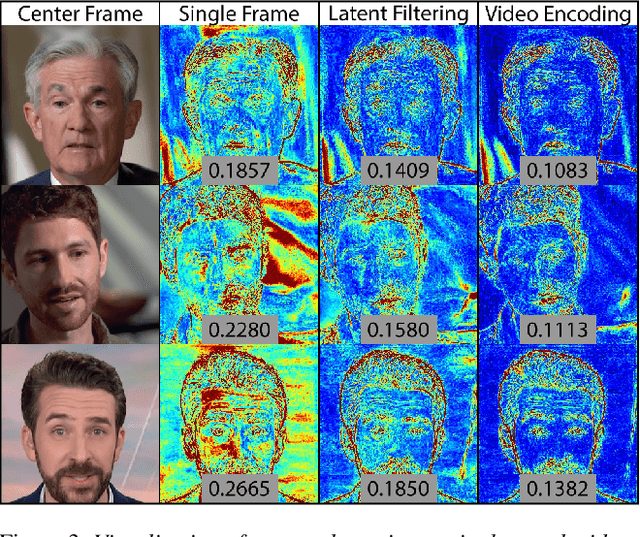
Many recent works have been proposed for face image editing by leveraging the latent space of pretrained GANs. However, few attempts have been made to directly apply them to videos, because 1) they do not guarantee temporal consistency, 2) their application is limited by their processing speed on videos, and 3) they cannot accurately encode details of face motion and expression. To this end, we propose a novel network to encode face videos into the latent space of StyleGAN for semantic face video manipulation. Based on the vision transformer, our network reuses the high-resolution portion of the latent vector to enforce temporal consistency. To capture subtle face motions and expressions, we design novel losses that involve sparse facial landmarks and dense 3D face mesh. We have thoroughly evaluated our approach and successfully demonstrated its application to various face video manipulations. Particularly, we propose a novel network for pose/expression control in a 3D coordinate system. Both qualitative and quantitative results have shown that our approach can significantly outperform existing single image methods, while achieving real-time (66 fps) speed.
Towards Counterfactual Image Manipulation via CLIP
Jul 07, 2022
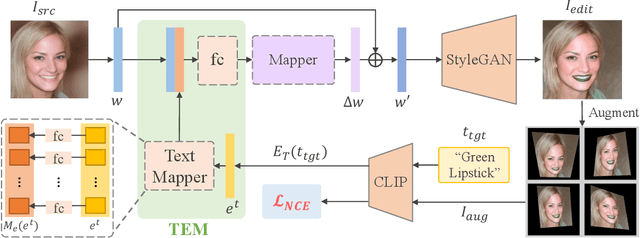
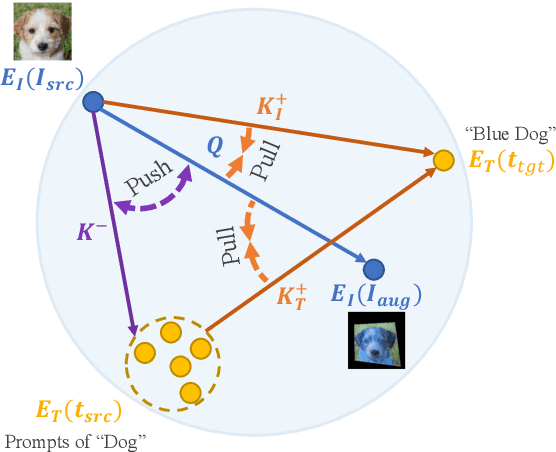

Leveraging StyleGAN's expressivity and its disentangled latent codes, existing methods can achieve realistic editing of different visual attributes such as age and gender of facial images. An intriguing yet challenging problem arises: Can generative models achieve counterfactual editing against their learnt priors? Due to the lack of counterfactual samples in natural datasets, we investigate this problem in a text-driven manner with Contrastive-Language-Image-Pretraining (CLIP), which can offer rich semantic knowledge even for various counterfactual concepts. Different from in-domain manipulation, counterfactual manipulation requires more comprehensive exploitation of semantic knowledge encapsulated in CLIP as well as more delicate handling of editing directions for avoiding being stuck in local minimum or undesired editing. To this end, we design a novel contrastive loss that exploits predefined CLIP-space directions to guide the editing toward desired directions from different perspectives. In addition, we design a simple yet effective scheme that explicitly maps CLIP embeddings (of target text) to the latent space and fuses them with latent codes for effective latent code optimization and accurate editing. Extensive experiments show that our design achieves accurate and realistic editing while driving by target texts with various counterfactual concepts.
Exploring the pattern of Emotion in children with ASD as an early biomarker through Recurring-Convolution Neural Network (R-CNN)
Dec 30, 2021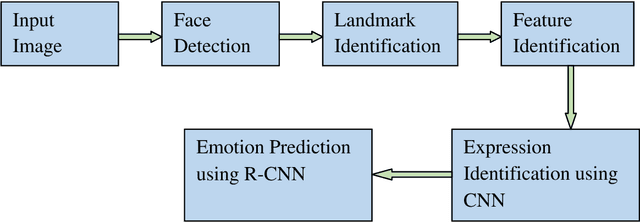
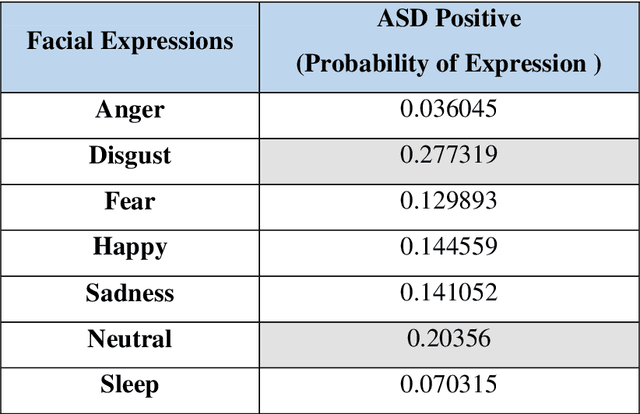
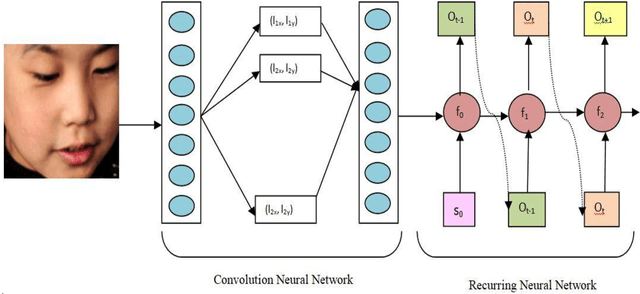
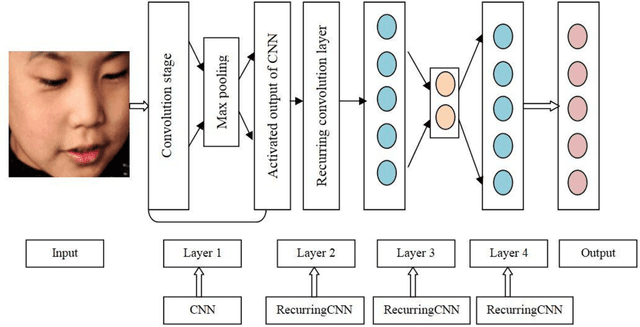
Autism Spectrum Disorder (ASD) is found to be a major concern among various occupational therapists. The foremost challenge of this neurodevelopmental disorder lies in the fact of analyzing and exploring various symptoms of the children at their early stage of development. Such early identification could prop up the therapists and clinicians to provide proper assistive support to make the children lead an independent life. Facial expressions and emotions perceived by the children could contribute to such early intervention of autism. In this regard, the paper implements in identifying basic facial expression and exploring their emotions upon a time variant factor. The emotions are analyzed by incorporating the facial expression identified through CNN using 68 landmark points plotted on the frontal face with a prediction network formed by RNN known as RCNN-FER system. The paper adopts R-CNN to take the advantage of increased accuracy and performance with decreased time complexity in predicting emotion as a textual network analysis. The papers proves better accuracy in identifying the emotion in autistic children when compared over simple machine learning models built for such identifications contributing to autistic society.
Styleverse: Towards Identity Stylization across Heterogeneous Domains
Mar 02, 2022

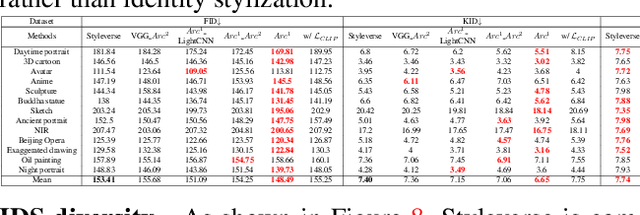

We propose a new challenging task namely IDentity Stylization (IDS) across heterogeneous domains. IDS focuses on stylizing the content identity, rather than completely swapping it using the reference identity. We use an effective heterogeneous-network-based framework $Styleverse$ that uses a single domain-aware generator to exploit the Metaverse of diverse heterogeneous faces, based on the proposed dataset FS13 with limited data. FS13 means 13 kinds of Face Styles considering diverse lighting conditions, art representations and life dimensions. Previous similar tasks, \eg, image style transfer can handle textural style transfer based on a reference image. This task usually ignores the high structure-aware facial area and high-fidelity preservation of the content. However, Styleverse intends to controllably create topology-aware faces in the Parallel Style Universe, where the source facial identity is adaptively styled via AdaIN guided by the domain-aware and reference-aware style embeddings from heterogeneous pretrained models. We first establish the IDS quantitative benchmark as well as the qualitative Styleverse matrix. Extensive experiments demonstrate that Styleverse achieves higher-fidelity identity stylization compared with other state-of-the-art methods.
QUEST: Quadriletral Senary bit Pattern for Facial Expression Recognition
Jul 24, 2018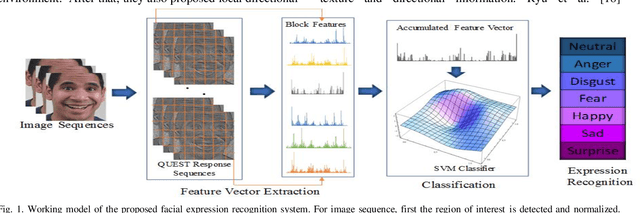
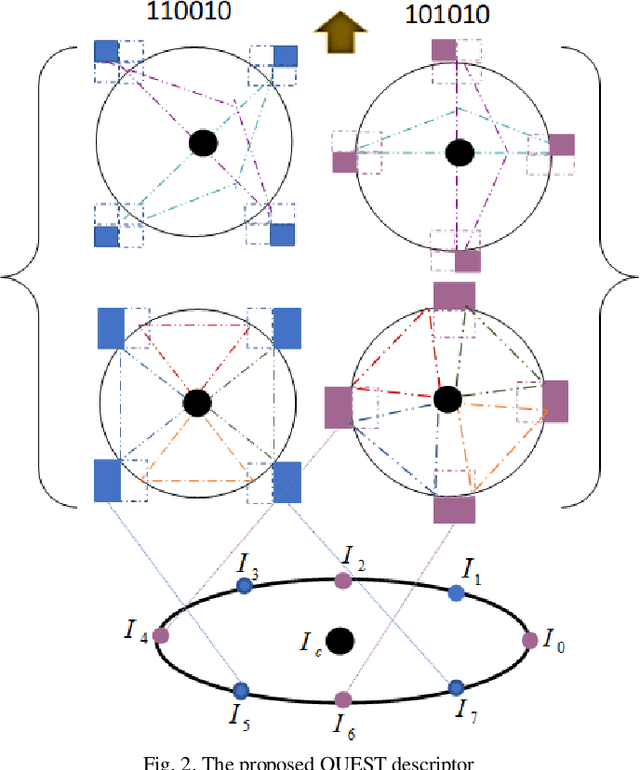
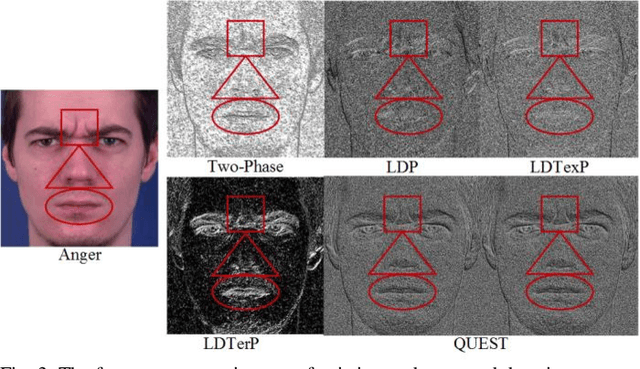
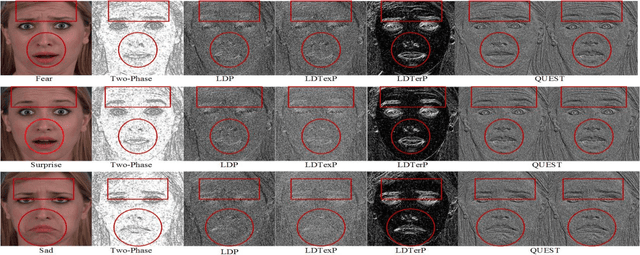
Facial expression has a significant role in analyzing human cognitive state. Deriving an accurate facial appearance representation is a critical task for an automatic facial expression recognition application. This paper provides a new feature descriptor named as Quadrilateral Senary bit Pattern for facial expression recognition. The QUEST pattern encoded the intensity changes by emphasizing the relationship between neighboring and reference pixels by dividing them into two quadrilaterals in a local neighborhood. Thus, the resultant gradient edges reveal the transitional variation information, that improves the classification rate by discriminating expression classes. Moreover, it also enhances the capability of the descriptor to deal with viewpoint variations and illumination changes. The trine relationship in a quadrilateral structure helps to extract the expressive edges and suppressing noise elements to enhance the robustness to noisy conditions. The QUEST pattern generates a six-bit compact code, which improves the efficiency of the FER system with more discriminability. The effectiveness of the proposed method is evaluated by conducting several experiments on four benchmark datasets: MMI, GEMEP-FERA, OULU-CASIA, and ISED. The experimental results show better performance of the proposed method as compared to existing state-art-the approaches.
Building BROOK: A Multi-modal and Facial Video Database for Human-Vehicle Interaction Research
May 19, 2020

With the growing popularity of Autonomous Vehicles, more opportunities have bloomed in the context of Human-Vehicle Interactions. However, the lack of comprehensive and concrete database support for such specific use case limits relevant studies in the whole design spaces. In this paper, we present our work-in-progress BROOK, a public multi-modal database with facial video records, which could be used to characterize drivers' affective states and driving styles. We first explain how we over-engineer such database in details, and what we have gained through a ten-month study. Then we showcase a Neural Network-based predictor, leveraging BROOK, which supports multi-modal prediction (including physiological data of heart rate and skin conductance and driving status data of speed)through facial videos. Finally, we discuss related issues when building such a database and our future directions in the context of BROOK. We believe BROOK is an essential building block for future Human-Vehicle Interaction Research.
Failure Detection for Facial Landmark Detectors
Aug 23, 2016

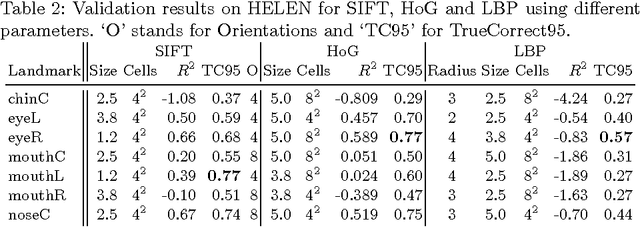
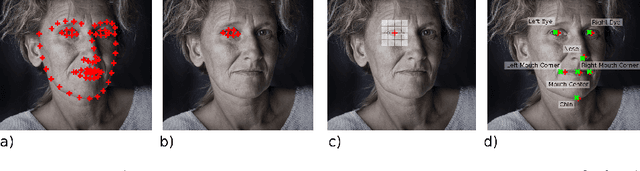
Most face applications depend heavily on the accuracy of the face and facial landmarks detectors employed. Prediction of attributes such as gender, age, and identity usually completely fail when the faces are badly aligned due to inaccurate facial landmark detection. Despite the impressive recent advances in face and facial landmark detection, little study is on the recovery from and detection of failures or inaccurate predictions. In this work we study two top recent facial landmark detectors and devise confidence models for their outputs. We validate our failure detection approaches on standard benchmarks (AFLW, HELEN) and correctly identify more than 40% of the failures in the outputs of the landmark detectors. Moreover, with our failure detection we can achieve a 12% error reduction on a gender estimation application at the cost of a small increase in computation.
Deepfake Detection for Facial Images with Facemasks
Feb 23, 2022
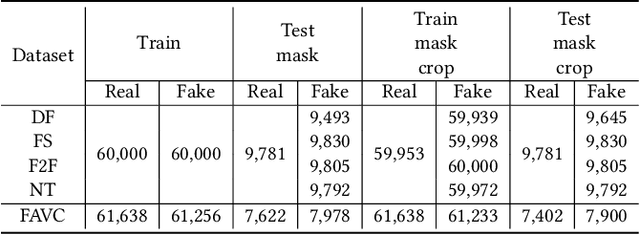
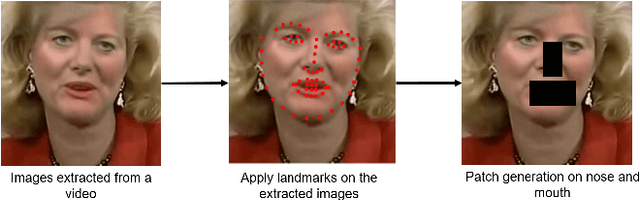
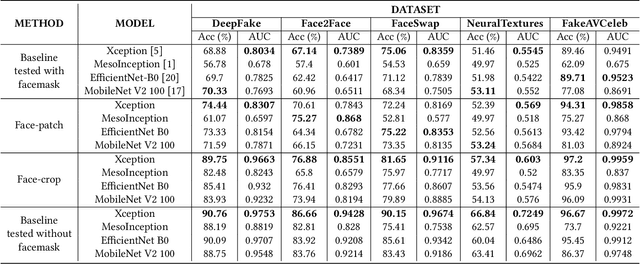
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.