 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Debiasing Classifiers by Amplifying Bias with Latent Diffusion and Large Language Models
Nov 25, 2024



Neural networks struggle with image classification when biases are learned and misleads correlations, affecting their generalization and performance. Previous methods require attribute labels (e.g. background, color) or utilizes Generative Adversarial Networks (GANs) to mitigate biases. We introduce DiffuBias, a novel pipeline for text-to-image generation that enhances classifier robustness by generating bias-conflict samples, without requiring training during the generation phase. Utilizing pretrained diffusion and image captioning models, DiffuBias generates images that challenge the biases of classifiers, using the top-$K$ losses from a biased classifier ($f_B$) to create more representative data samples. This method not only debiases effectively but also boosts classifier generalization capabilities. To the best of our knowledge, DiffuBias is the first approach leveraging a stable diffusion model to generate bias-conflict samples in debiasing tasks. Our comprehensive experimental evaluations demonstrate that DiffuBias achieves state-of-the-art performance on benchmark datasets. We also conduct a comparative analysis of various generative models in terms of carbon emissions and energy consumption to highlight the significance of computational efficiency.
DiffInject: Revisiting Debias via Synthetic Data Generation using Diffusion-based Style Injection
Jun 10, 2024Dataset bias is a significant challenge in machine learning, where specific attributes, such as texture or color of the images are unintentionally learned resulting in detrimental performance. To address this, previous efforts have focused on debiasing models either by developing novel debiasing algorithms or by generating synthetic data to mitigate the prevalent dataset biases. However, generative approaches to date have largely relied on using bias-specific samples from the dataset, which are typically too scarce. In this work, we propose, DiffInject, a straightforward yet powerful method to augment synthetic bias-conflict samples using a pretrained diffusion model. This approach significantly advances the use of diffusion models for debiasing purposes by manipulating the latent space. Our framework does not require any explicit knowledge of the bias types or labelling, making it a fully unsupervised setting for debiasing. Our methodology demonstrates substantial result in effectively reducing dataset bias.
Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation
Aug 07, 2023



Sequential recommendation addresses the issue of preference drift by predicting the next item based on the user's previous behaviors. Recently, a promising approach using contrastive learning has emerged, demonstrating its effectiveness in recommending items under sparse user-item interactions. Significantly, the effectiveness of combinations of various augmentation methods has been demonstrated in different domains, particularly in computer vision. However, when it comes to augmentation within a contrastive learning framework in sequential recommendation, previous research has only focused on limited conditions and simple structures. Thus, it is still possible to extend existing approaches to boost the effects of augmentation methods by using progressed structures with the combinations of multiple augmentation methods. In this work, we propose a novel framework called Hierarchical Contrastive Learning with Multiple Augmentation for Sequential Recommendation(HCLRec) to overcome the aforementioned limitation. Our framework leverages existing augmentation methods hierarchically to improve performance. By combining augmentation methods continuously, we generate low-level and high-level view pairs. We employ a Transformers-based model to encode the input sequence effectively. Furthermore, we introduce additional blocks consisting of Transformers and position-wise feed-forward network(PFFN) layers to learn the invariance of the original sequences from hierarchically augmented views. We pass the input sequence to subsequent layers based on the number of increment levels applied to the views to handle various augmentation levels. Within each layer, we compute contrastive loss between pairs of views at the same level. Extensive experiments demonstrate that our proposed method outperforms state-of-the-art approaches and that HCLRec is robust even when faced with the problem of sparse interaction.
Deepfake Detection for Facial Images with Facemasks
Feb 23, 2022
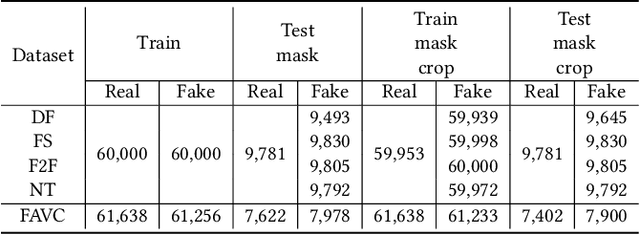
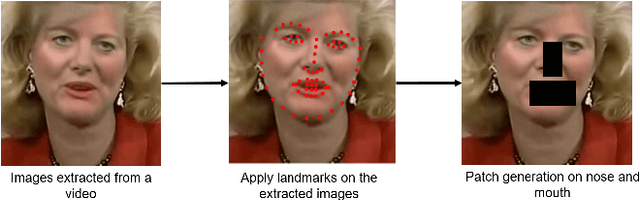
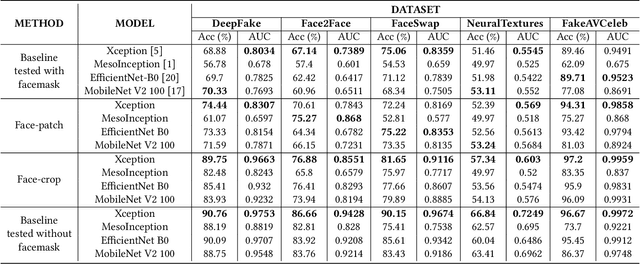
Hyper-realistic face image generation and manipulation have givenrise to numerous unethical social issues, e.g., invasion of privacy,threat of security, and malicious political maneuvering, which re-sulted in the development of recent deepfake detection methodswith the rising demands of deepfake forensics. Proposed deepfakedetection methods to date have shown remarkable detection perfor-mance and robustness. However, none of the suggested deepfakedetection methods assessed the performance of deepfakes withthe facemask during the pandemic crisis after the outbreak of theCovid-19. In this paper, we thoroughly evaluate the performance ofstate-of-the-art deepfake detection models on the deepfakes withthe facemask. Also, we propose two approaches to enhance themasked deepfakes detection:face-patchandface-crop. The experi-mental evaluations on both methods are assessed through the base-line deepfake detection models on the various deepfake datasets.Our extensive experiments show that, among the two methods,face-cropperforms better than theface-patch, and could be a trainmethod for deepfake detection models to detect fake faces withfacemask in real world.