 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Foundational Models in Medical Imaging: A Comprehensive Survey and Future Vision
Oct 28, 2023
Foundation models, large-scale, pre-trained deep-learning models adapted to a wide range of downstream tasks have gained significant interest lately in various deep-learning problems undergoing a paradigm shift with the rise of these models. Trained on large-scale dataset to bridge the gap between different modalities, foundation models facilitate contextual reasoning, generalization, and prompt capabilities at test time. The predictions of these models can be adjusted for new tasks by augmenting the model input with task-specific hints called prompts without requiring extensive labeled data and retraining. Capitalizing on the advances in computer vision, medical imaging has also marked a growing interest in these models. To assist researchers in navigating this direction, this survey intends to provide a comprehensive overview of foundation models in the domain of medical imaging. Specifically, we initiate our exploration by providing an exposition of the fundamental concepts forming the basis of foundation models. Subsequently, we offer a methodical taxonomy of foundation models within the medical domain, proposing a classification system primarily structured around training strategies, while also incorporating additional facets such as application domains, imaging modalities, specific organs of interest, and the algorithms integral to these models. Furthermore, we emphasize the practical use case of some selected approaches and then discuss the opportunities, applications, and future directions of these large-scale pre-trained models, for analyzing medical images. In the same vein, we address the prevailing challenges and research pathways associated with foundational models in medical imaging. These encompass the areas of interpretability, data management, computational requirements, and the nuanced issue of contextual comprehension.
Can Word Sense Distribution Detect Semantic Changes of Words?
Oct 16, 2023Semantic Change Detection (SCD) of words is an important task for various NLP applications that must make time-sensitive predictions. Some words are used over time in novel ways to express new meanings, and these new meanings establish themselves as novel senses of existing words. On the other hand, Word Sense Disambiguation (WSD) methods associate ambiguous words with sense ids, depending on the context in which they occur. Given this relationship between WSD and SCD, we explore the possibility of predicting whether a target word has its meaning changed between two corpora collected at different time steps, by comparing the distributions of senses of that word in each corpora. For this purpose, we use pretrained static sense embeddings to automatically annotate each occurrence of the target word in a corpus with a sense id. Next, we compute the distribution of sense ids of a target word in a given corpus. Finally, we use different divergence or distance measures to quantify the semantic change of the target word across the two given corpora. Our experimental results on SemEval 2020 Task 1 dataset show that word sense distributions can be accurately used to predict semantic changes of words in English, German, Swedish and Latin.
* Accepted to Findings of EMNLP 2023
Real-time auralization for performers on virtual stages
Sep 06, 2023This article presents an interactive system for stage acoustics experimentation including considerations for hearing one's own and others' instruments. The quality of real-time auralization systems for psychophysical experiments on music performance depends on the system's calibration and latency, among other factors (e.g. visuals, simulation methods, haptics, etc). The presented system focuses on the acoustic considerations for laboratory implementations. The calibration is implemented as a set of filters accounting for the microphone-instrument distances and the directivity factors, as well as the transducers' frequency responses. Moreover, sources of errors are characterized using both state-of-the-art information and derivations from the mathematical definition of the calibration filter. In order to compensate for hardware latency without cropping parts of the simulated impulse responses, the virtual direct sound of musicians hearing themselves is skipped from the simulation and addressed by letting the actual direct sound reach the listener through open headphones. The required latency compensation of the interactive part (i.e. hearing others) meets the minimum distance requirement between musicians, which is 2 m for the implemented system. Finally, a proof of concept is provided that includes objective and subjective experiments, which give support to the feasibility of the proposed setup.
Efficient Causal Discovery for Robotics Applications
Oct 24, 2023Using robots for automating tasks in environments shared with humans, such as warehouses, shopping centres, or hospitals, requires these robots to comprehend the fundamental physical interactions among nearby agents and objects. Specifically, creating models to represent cause-and-effect relationships among these elements can aid in predicting unforeseen human behaviours and anticipate the outcome of particular robot actions. To be suitable for robots, causal analysis must be both fast and accurate, meeting real-time demands and the limited computational resources typical in most robotics applications. In this paper, we present a practical demonstration of our approach for fast and accurate causal analysis, known as Filtered PCMCI (F-PCMCI), along with a real-world robotics application. The provided application illustrates how our F-PCMCI can accurately and promptly reconstruct the causal model of a human-robot interaction scenario, which can then be leveraged to enhance the quality of the interaction.
$k$-$t$ CLAIR: Self-Consistency Guided Multi-Prior Learning for Dynamic Parallel MR Image Reconstruction
Oct 17, 2023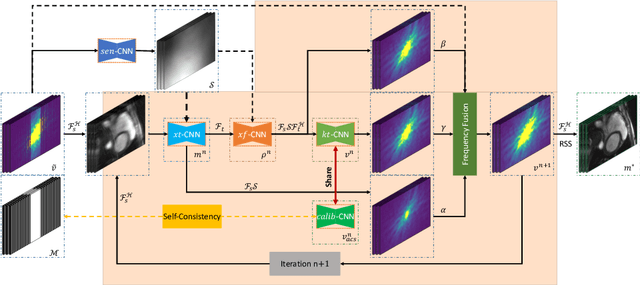
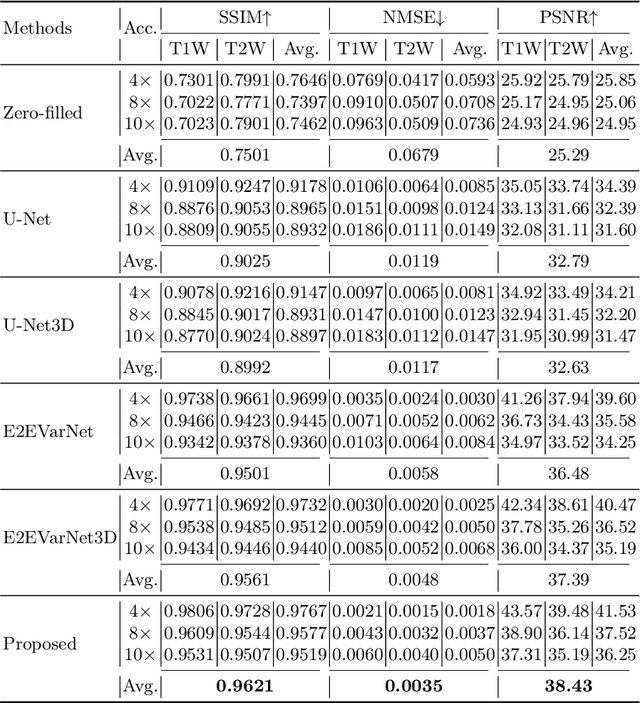
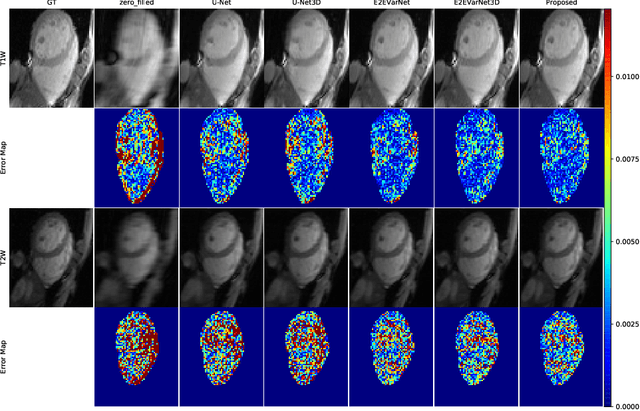
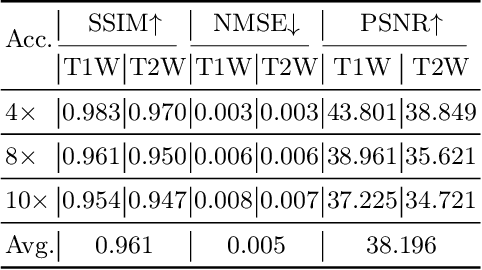
Cardiac magnetic resonance imaging (CMR) has been widely used in clinical practice for the medical diagnosis of cardiac diseases. However, the long acquisition time hinders its development in real-time applications. Here, we propose a novel self-consistency guided multi-prior learning framework named $k$-$t$ CLAIR to exploit spatiotemporal correlations from highly undersampled data for accelerated dynamic parallel MRI reconstruction. The $k$-$t$ CLAIR progressively reconstructs faithful images by leveraging multiple complementary priors learned in the $x$-$t$, $x$-$f$, and $k$-$t$ domains in an iterative fashion, as dynamic MRI exhibits high spatiotemporal redundancy. Additionally, $k$-$t$ CLAIR incorporates calibration information for prior learning, resulting in a more consistent reconstruction. Experimental results on cardiac cine and T1W/T2W images demonstrate that $k$-$t$ CLAIR achieves high-quality dynamic MR reconstruction in terms of both quantitative and qualitative performance.
Towards a Deep Learning-based Online Quality Prediction System for Welding Processes
Oct 19, 2023The digitization of manufacturing processes enables promising applications for machine learning-assisted quality assurance. A widely used manufacturing process that can strongly benefit from data-driven solutions is \ac{GMAW}. The welding process is characterized by complex cause-effect relationships between material properties, process conditions and weld quality. In non-laboratory environments with frequently changing process parameters, accurate determination of weld quality by destructive testing is economically unfeasible. Deep learning offers the potential to identify the relationships in available process data and predict the weld quality from process observations. In this paper, we present a concept for a deep learning based predictive quality system in \ac{GMAW}. At its core, the concept involves a pipeline consisting of four major phases: collection and management of multi-sensor data (e.g. current and voltage), real-time processing and feature engineering of the time series data by means of autoencoders, training and deployment of suitable recurrent deep learning models for quality predictions, and model evolutions under changing process conditions using continual learning. The concept provides the foundation for future research activities in which we will realize an online predictive quality system for running production.
Enhanced Backpressure Routing Using Wireless Link Features
Oct 14, 2023Backpressure (BP) routing is a well-established framework for distributed routing and scheduling in wireless multi-hop networks. However, the basic BP scheme suffers from poor end-to-end delay due to the drawbacks of slow startup, random walk, and the last packet problem. Biased BP with shortest path awareness can address the first two drawbacks, and sojourn time-based backlog metrics were proposed for the last packet problem. Furthermore, these BP variations require no additional signaling overhead in each time step compared to the basic BP. In this work, we further address three long-standing challenges associated with the aforementioned low-cost BP variations, including optimal scaling of the biases, bias maintenance under mobility, and incorporating sojourn time awareness into biased BP. Our analysis and experimental results show that proper scaling of biases can be achieved with the help of common link features, which can effectively reduce end-to-end delay of BP by mitigating the random walk of packets under low-to-medium traffic, including the last packet scenario. In addition, our low-overhead bias maintenance scheme is shown to be effective under mobility, and our bio-inspired sojourn time-aware backlog metric is demonstrated to be more efficient and effective for the last packet problem than existing approaches when incorporated into biased BP.
Neural Distributed Compressor Discovers Binning
Oct 25, 2023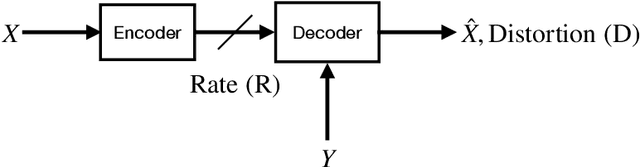
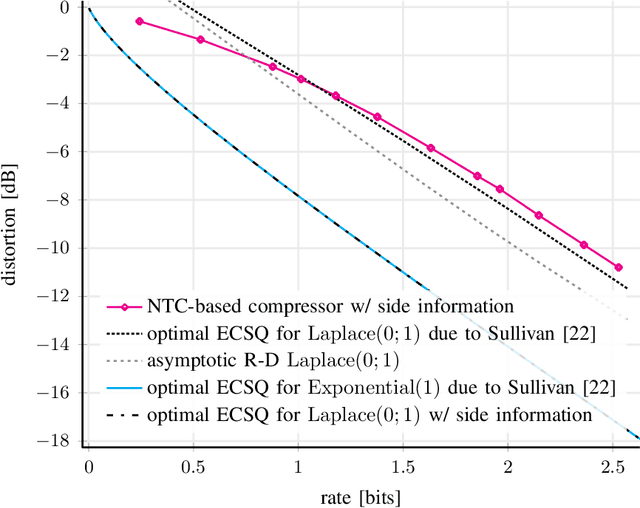
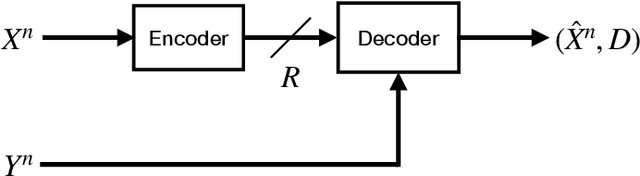
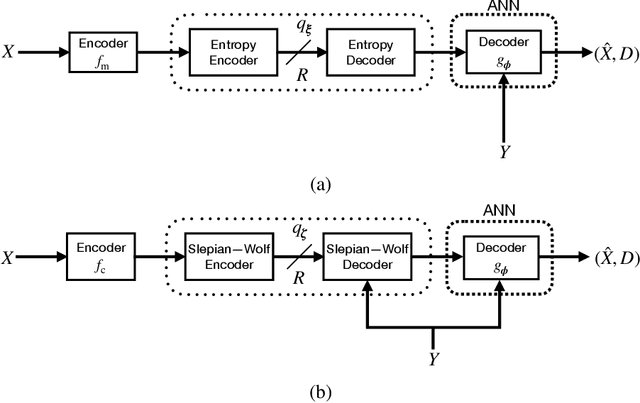
We consider lossy compression of an information source when the decoder has lossless access to a correlated one. This setup, also known as the Wyner-Ziv problem, is a special case of distributed source coding. To this day, practical approaches for the Wyner-Ziv problem have neither been fully developed nor heavily investigated. We propose a data-driven method based on machine learning that leverages the universal function approximation capability of artificial neural networks. We find that our neural network-based compression scheme, based on variational vector quantization, recovers some principles of the optimum theoretical solution of the Wyner-Ziv setup, such as binning in the source space as well as optimal combination of the quantization index and side information, for exemplary sources. These behaviors emerge although no structure exploiting knowledge of the source distributions was imposed. Binning is a widely used tool in information theoretic proofs and methods, and to our knowledge, this is the first time it has been explicitly observed to emerge from data-driven learning.
Subspace Chronicles: How Linguistic Information Emerges, Shifts and Interacts during Language Model Training
Oct 25, 2023Representational spaces learned via language modeling are fundamental to Natural Language Processing (NLP), however there has been limited understanding regarding how and when during training various types of linguistic information emerge and interact. Leveraging a novel information theoretic probing suite, which enables direct comparisons of not just task performance, but their representational subspaces, we analyze nine tasks covering syntax, semantics and reasoning, across 2M pre-training steps and five seeds. We identify critical learning phases across tasks and time, during which subspaces emerge, share information, and later disentangle to specialize. Across these phases, syntactic knowledge is acquired rapidly after 0.5% of full training. Continued performance improvements primarily stem from the acquisition of open-domain knowledge, while semantics and reasoning tasks benefit from later boosts to long-range contextualization and higher specialization. Measuring cross-task similarity further reveals that linguistically related tasks share information throughout training, and do so more during the critical phase of learning than before or after. Our findings have implications for model interpretability, multi-task learning, and learning from limited data.
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023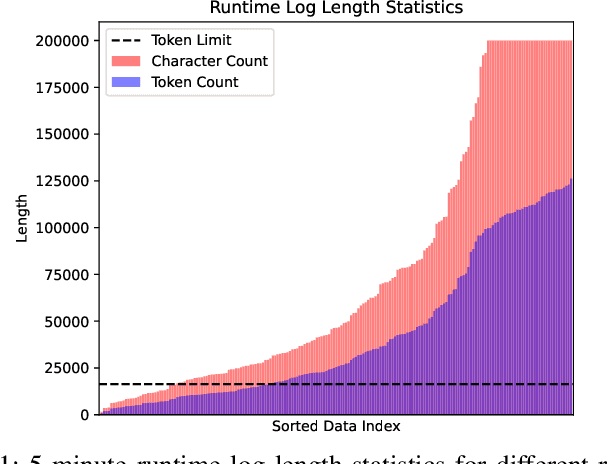
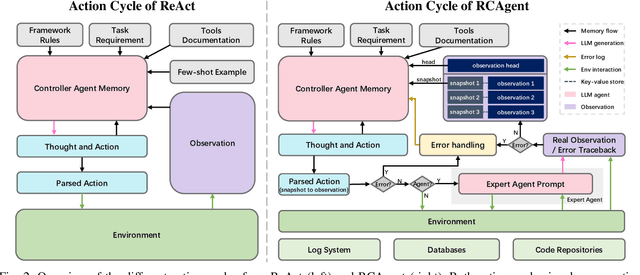

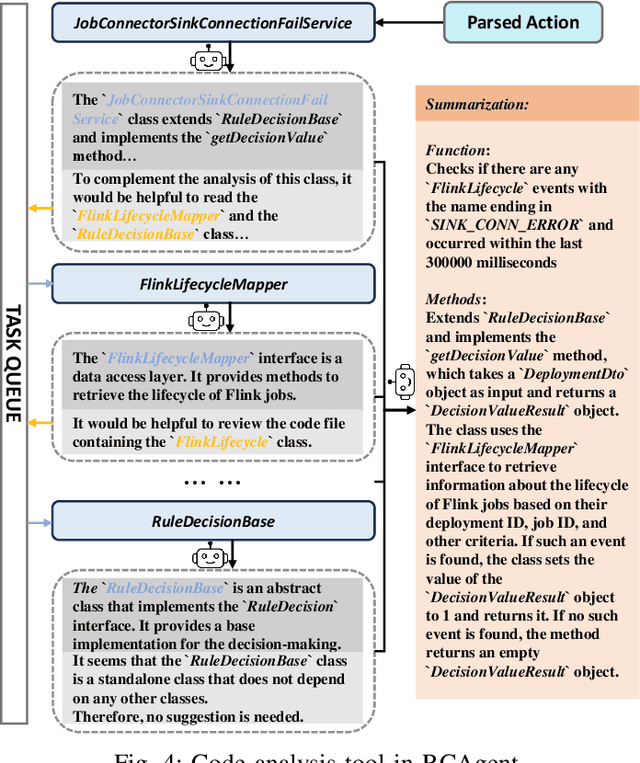
Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.