 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimely Parameter Updating in Over-the-Air Federated Learning
Dec 22, 2025Incorporating over-the-air computations (OAC) into the model training process of federated learning (FL) is an effective approach to alleviating the communication bottleneck in FL systems. Under OAC-FL, every client modulates its intermediate parameters, such as gradient, onto the same set of orthogonal waveforms and simultaneously transmits the radio signal to the edge server. By exploiting the superposition property of multiple-access channels, the edge server can obtain an automatically aggregated global gradient from the received signal. However, the limited number of orthogonal waveforms available in practical systems is fundamentally mismatched with the high dimensionality of modern deep learning models. To address this issue, we propose Freshness Freshness-mAgnItude awaRe top-k (FAIR-k), an algorithm that selects, in each communication round, the most impactful subset of gradients to be updated over the air. In essence, FAIR-k combines the complementary strengths of the Round-Robin and Top-k algorithms, striking a delicate balance between timeliness (freshness of parameter updates) and importance (gradient magnitude). Leveraging tools from Markov analysis, we characterize the distribution of parameter staleness under FAIR-k. Building on this, we establish the convergence rate of OAC-FL with FAIR-k, which discloses the joint effect of data heterogeneity, channel noise, and parameter staleness on the training efficiency. Notably, as opposed to conventional analyses that assume a universal Lipschitz constant across all the clients, our framework adopts a finer-grained model of the data heterogeneity. The analysis demonstrates that since FAIR-k promotes fresh (and fair) parameter updates, it not only accelerates convergence but also enhances communication efficiency by enabling an extended period of local training without significantly affecting overall training efficiency.
A Differentiable Digital Twin of Distributed Link Scheduling for Contention-Aware Networking
Dec 11, 2025



Many routing and flow optimization problems in wired networks can be solved efficiently using minimum cost flow formulations. However, this approach does not extend to wireless multi-hop networks, where the assumptions of fixed link capacity and linear cost structure collapse due to contention for shared spectrum resources. The key challenge is that the long-term capacity of a wireless link becomes a non-linear function of its network context, including network topology, link quality, and the traffic assigned to neighboring links. In this work, we pursue a new direction of modeling wireless network under randomized medium access control by developing an analytical network digital twin (NDT) that predicts link duty cycles from network context. We generalize randomized contention as finding a Maximal Independent Set (MIS) on the conflict graph using weighted Luby's algorithm, derive an analytical model of link duty cycles, and introduce an iterative procedure that resolves the circular dependency among duty cycle, link capacity, and contention probability. Our numerical experiments show that the proposed NDT accurately predicts link duty cycles and congestion patterns with up to a 5000x speedup over packet-level simulation, and enables us to optimize link scheduling using gradient descent for reduced congestion and radio footprint.
MGStream: Motion-aware 3D Gaussian for Streamable Dynamic Scene Reconstruction
May 20, 20253D Gaussian Splatting (3DGS) has gained significant attention in streamable dynamic novel view synthesis (DNVS) for its photorealistic rendering capability and computational efficiency. Despite much progress in improving rendering quality and optimization strategies, 3DGS-based streamable dynamic scene reconstruction still suffers from flickering artifacts and storage inefficiency, and struggles to model the emerging objects. To tackle this, we introduce MGStream which employs the motion-related 3D Gaussians (3DGs) to reconstruct the dynamic and the vanilla 3DGs for the static. The motion-related 3DGs are implemented according to the motion mask and the clustering-based convex hull algorithm. The rigid deformation is applied to the motion-related 3DGs for modeling the dynamic, and the attention-based optimization on the motion-related 3DGs enables the reconstruction of the emerging objects. As the deformation and optimization are only conducted on the motion-related 3DGs, MGStream avoids flickering artifacts and improves the storage efficiency. Extensive experiments on real-world datasets N3DV and MeetRoom demonstrate that MGStream surpasses existing streaming 3DGS-based approaches in terms of rendering quality, training/storage efficiency and temporal consistency. Our code is available at: https://github.com/pcl3dv/MGStream.
SeLR: Sparsity-enhanced Lagrangian Relaxation for Computation Offloading at the Edge
May 01, 2025



This paper introduces a novel computational approach for offloading sensor data processing tasks to servers in edge networks for better accuracy and makespan. A task is assigned with one of several offloading options, each comprises a server, a route for uploading data to the server, and a service profile that specifies the performance and resource consumption at the server and in the network. This offline offloading and routing problem is formulated as mixed integer programming (MIP), which is non-convex and HP-hard due to the discrete decision variables associated to the offloading options. The novelty of our approach is to transform this non-convex problem into iterative convex optimization by relaxing integer decision variables into continuous space, combining primal-dual optimization for penalizing constraint violations and reweighted $L_1$-minimization for promoting solution sparsity, which achieves better convergence through a smoother path in a continuous search space. Compared to existing greedy heuristics, our approach can achieve a better Pareto frontier in accuracy and latency, scales better to larger problem instances, and can achieve a 7.72--9.17$\times$ reduction in computational overhead of scheduling compared to the optimal solver in hierarchically organized edge networks with 300 nodes and 50--100 tasks.
Generalizing Biased Backpressure Routing and Scheduling to Wireless Multi-hop Networks with Advanced Air-interfaces
Apr 30, 2025



Backpressure (BP) routing and scheduling is a well-established resource allocation method for wireless multi-hop networks, known for its fully distributed operations and proven maximum queue stability. Recent advances in shortest path-biased BP routing (SP-BP) mitigate shortcomings such as slow startup and random walk, but exclusive link-level commodity selection still suffers from the last-packet problem and bandwidth underutilization. Moreover, classic BP routing implicitly assumes single-input-single-output (SISO) transceivers, which can lead to the same packets being scheduled on multiple outgoing links for multiple-input-multiple-output (MIMO) transceivers, causing detouring and looping in MIMO networks. In this paper, we revisit the foundational Lyapunov drift theory underlying BP routing and demonstrate that exclusive commodity selection is unnecessary, and instead propose a Max-Utility link-sharing method. Additionally, we generalize MaxWeight scheduling to MIMO networks by introducing attributed capacity hypergraphs (ACH), an extension of traditional conflict graphs for SISO networks, and by incorporating backlog reassignment into scheduling iterations to prevent redundant packet routing. Numerical evaluations show that our approach substantially mitigates the last-packet problem in state-of-the-art (SOTA) SP-BP under lightweight traffic, and slightly expands the network capacity region for heavier traffic.
Joint Task Offloading and Routing in Wireless Multi-hop Networks Using Biased Backpressure Algorithm
Dec 19, 2024


A significant challenge for computation offloading in wireless multi-hop networks is the complex interaction among traffic flows in the presence of interference. Existing approaches often ignore these key effects and/or rely on outdated queueing and channel state information. To fill these gaps, we reformulate joint offloading and routing as a routing problem on an extended graph with physical and virtual links. We adopt the state-of-the-art shortest path-biased Backpressure routing algorithm, which allows the destination and the route of a job to be dynamically adjusted at every time step based on network-wide long-term information and real-time states of local neighborhoods. In large networks, our approach achieves smaller makespan than existing approaches, such as separated Backpressure offloading and joint offloading and routing based on linear programming.
Fully Distributed Online Training of Graph Neural Networks in Networked Systems
Dec 08, 2024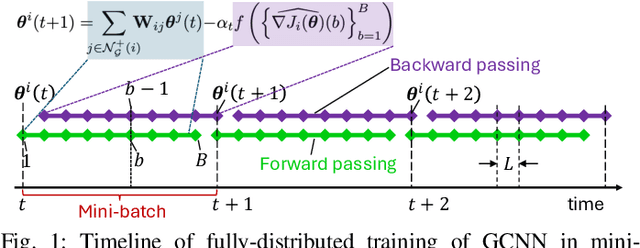
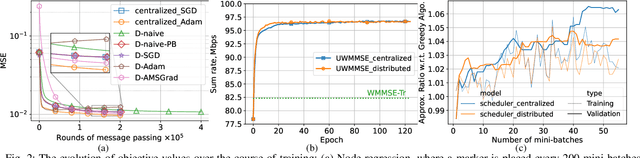
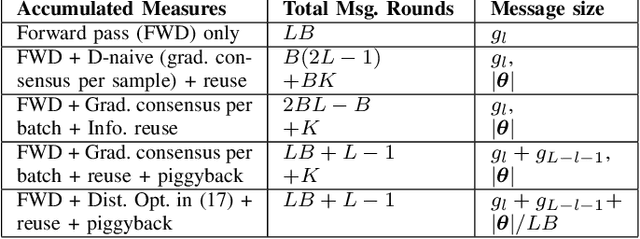
Graph neural networks (GNNs) are powerful tools for developing scalable, decentralized artificial intelligence in large-scale networked systems, such as wireless networks, power grids, and transportation networks. Currently, GNNs in networked systems mostly follow a paradigm of `centralized training, distributed execution', which limits their adaptability and slows down their development cycles. In this work, we fill this gap for the first time by developing a communication-efficient, fully distributed online training approach for GNNs applied to large networked systems. For a mini-batch with $B$ samples, our approach of training an $L$-layer GNN only adds $L$ rounds of message passing to the $LB$ rounds required by GNN inference, with doubled message sizes. Through numerical experiments in graph-based node regression, power allocation, and link scheduling in wireless networks, we demonstrate the effectiveness of our approach in training GNNs under supervised, unsupervised, and reinforcement learning paradigms.
Biased Backpressure Routing Using Link Features and Graph Neural Networks
Jul 13, 2024



To reduce the latency of Backpressure (BP) routing in wireless multi-hop networks, we propose to enhance the existing shortest path-biased BP (SP-BP) and sojourn time-based backlog metrics, since they introduce no additional time step-wise signaling overhead to the basic BP. Rather than relying on hop-distance, we introduce a new edge-weighted shortest path bias built on the scheduling duty cycle of wireless links, which can be predicted by a graph convolutional neural network based on the topology and traffic of wireless networks. Additionally, we tackle three long-standing challenges associated with SP-BP: optimal bias scaling, efficient bias maintenance, and integration of delay awareness. Our proposed solutions inherit the throughput optimality of the basic BP, as well as its practical advantages of low complexity and fully distributed implementation. Our approaches rely on common link features and introduces only a one-time constant overhead to previous SP-BP schemes, or a one-time overhead linear in the network size to the basic BP. Numerical experiments show that our solutions can effectively address the major drawbacks of slow startup, random walk, and the last packet problem in basic BP, improving the end-to-end delay of existing low-overhead BP algorithms under various settings of network traffic, interference, and mobility.
UniSparse: An Intermediate Language for General Sparse Format Customization
Mar 09, 2024



The ongoing trend of hardware specialization has led to a growing use of custom data formats when processing sparse workloads, which are typically memory-bound. These formats facilitate optimized software/hardware implementations by utilizing sparsity pattern- or target-aware data structures and layouts to enhance memory access latency and bandwidth utilization. However, existing sparse tensor programming models and compilers offer little or no support for productively customizing the sparse formats. Additionally, because these frameworks represent formats using a limited set of per-dimension attributes, they lack the flexibility to accommodate numerous new variations of custom sparse data structures and layouts. To overcome this deficiency, we propose UniSparse, an intermediate language that provides a unified abstraction for representing and customizing sparse formats. Unlike the existing attribute-based frameworks, UniSparse decouples the logical representation of the sparse tensor (i.e., the data structure) from its low-level memory layout, enabling the customization of both. As a result, a rich set of format customizations can be succinctly expressed in a small set of well-defined query, mutation, and layout primitives. We also develop a compiler leveraging the MLIR infrastructure, which supports adaptive customization of formats, and automatic code generation of format conversion and compute operations for heterogeneous architectures. We demonstrate the efficacy of our approach through experiments running commonly-used sparse linear algebra operations with specialized formats on multiple different hardware targets, including an Intel CPU, an NVIDIA GPU, an AMD Xilinx FPGA, and a simulated processing-in-memory (PIM) device.
* to be published in OOPSLA'24
PSAvatar: A Point-based Morphable Shape Model for Real-Time Head Avatar Animation with 3D Gaussian Splatting
Jan 30, 2024



Despite much progress, achieving real-time high-fidelity head avatar animation is still difficult and existing methods have to trade-off between speed and quality. 3DMM based methods often fail to model non-facial structures such as eyeglasses and hairstyles, while neural implicit models suffer from deformation inflexibility and rendering inefficiency. Although 3D Gaussian has been demonstrated to possess promising capability for geometry representation and radiance field reconstruction, applying 3D Gaussian in head avatar creation remains a major challenge since it is difficult for 3D Gaussian to model the head shape variations caused by changing poses and expressions. In this paper, we introduce PSAvatar, a novel framework for animatable head avatar creation that utilizes discrete geometric primitive to create a parametric morphable shape model and employs 3D Gaussian for fine detail representation and high fidelity rendering. The parametric morphable shape model is a Point-based Morphable Shape Model (PMSM) which uses points instead of meshes for 3D representation to achieve enhanced representation flexibility. The PMSM first converts the FLAME mesh to points by sampling on the surfaces as well as off the meshes to enable the reconstruction of not only surface-like structures but also complex geometries such as eyeglasses and hairstyles. By aligning these points with the head shape in an analysis-by-synthesis manner, the PMSM makes it possible to utilize 3D Gaussian for fine detail representation and appearance modeling, thus enabling the creation of high-fidelity avatars. We show that PSAvatar can reconstruct high-fidelity head avatars of a variety of subjects and the avatars can be animated in real-time ($\ge$ 25 fps at a resolution of 512 $\times$ 512 ).