 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robot Safety Monitoring using Programmable Light Curtains
Apr 04, 2024
As factories continue to evolve into collaborative spaces with multiple robots working together with human supervisors in the loop, ensuring safety for all actors involved becomes critical. Currently, laser-based light curtain sensors are widely used in factories for safety monitoring. While these conventional safety sensors meet high accuracy standards, they are difficult to reconfigure and can only monitor a fixed user-defined region of space. Furthermore, they are typically expensive. Instead, we leverage a controllable depth sensor, programmable light curtains (PLC), to develop an inexpensive and flexible real-time safety monitoring system for collaborative robot workspaces. Our system projects virtual dynamic safety envelopes that tightly envelop the moving robot at all times and detect any objects that intrude the envelope. Furthermore, we develop an instrumentation algorithm that optimally places (multiple) PLCs in a workspace to maximize the visibility coverage of robots. Our work enables fence-less human-robot collaboration, while scaling to monitor multiple robots with few sensors. We analyze our system in a real manufacturing testbed with four robot arms and demonstrate its capabilities as a fast, accurate, and inexpensive safety monitoring solution.
EndoGSLAM: Real-Time Dense Reconstruction and Tracking in Endoscopic Surgeries using Gaussian Splatting
Mar 22, 2024Precise camera tracking, high-fidelity 3D tissue reconstruction, and real-time online visualization are critical for intrabody medical imaging devices such as endoscopes and capsule robots. However, existing SLAM (Simultaneous Localization and Mapping) methods often struggle to achieve both complete high-quality surgical field reconstruction and efficient computation, restricting their intraoperative applications among endoscopic surgeries. In this paper, we introduce EndoGSLAM, an efficient SLAM approach for endoscopic surgeries, which integrates streamlined Gaussian representation and differentiable rasterization to facilitate over 100 fps rendering speed during online camera tracking and tissue reconstructing. Extensive experiments show that EndoGSLAM achieves a better trade-off between intraoperative availability and reconstruction quality than traditional or neural SLAM approaches, showing tremendous potential for endoscopic surgeries. The project page is at https://EndoGSLAM.loping151.com
From Pixels to Predictions: Spectrogram and Vision Transformer for Better Time Series Forecasting
Mar 17, 2024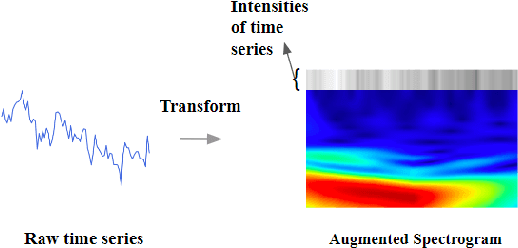
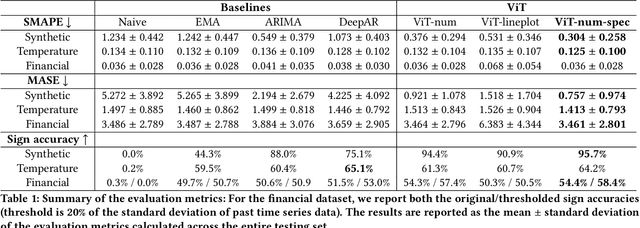
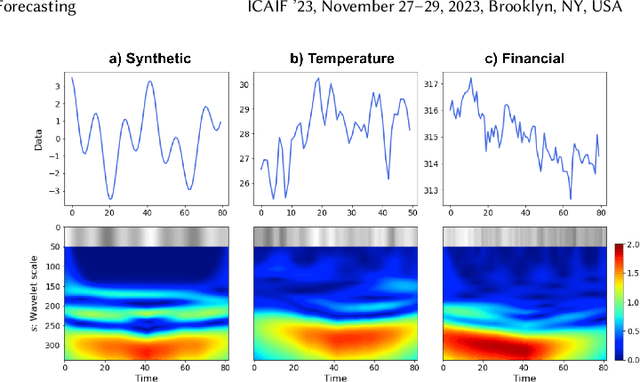
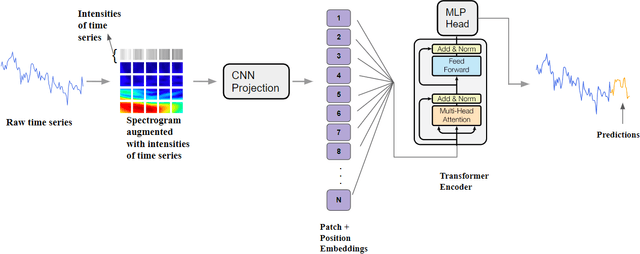
Time series forecasting plays a crucial role in decision-making across various domains, but it presents significant challenges. Recent studies have explored image-driven approaches using computer vision models to address these challenges, often employing lineplots as the visual representation of time series data. In this paper, we propose a novel approach that uses time-frequency spectrograms as the visual representation of time series data. We introduce the use of a vision transformer for multimodal learning, showcasing the advantages of our approach across diverse datasets from different domains. To evaluate its effectiveness, we compare our method against statistical baselines (EMA and ARIMA), a state-of-the-art deep learning-based approach (DeepAR), other visual representations of time series data (lineplot images), and an ablation study on using only the time series as input. Our experiments demonstrate the benefits of utilizing spectrograms as a visual representation for time series data, along with the advantages of employing a vision transformer for simultaneous learning in both the time and frequency domains.
Continuous Spiking Graph Neural Networks
Apr 02, 2024Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.
GENEVIC: GENetic data Exploration and Visualization via Intelligent interactive Console
Apr 04, 2024Summary: The vast generation of genetic data poses a significant challenge in efficiently uncovering valuable knowledge. Introducing GENEVIC, an AI-driven chat framework that tackles this challenge by bridging the gap between genetic data generation and biomedical knowledge discovery. Leveraging generative AI, notably ChatGPT, it serves as a biologist's 'copilot'. It automates the analysis, retrieval, and visualization of customized domain-specific genetic information, and integrates functionalities to generate protein interaction networks, enrich gene sets, and search scientific literature from PubMed, Google Scholar, and arXiv, making it a comprehensive tool for biomedical research. In its pilot phase, GENEVIC is assessed using a curated database that ranks genetic variants associated with Alzheimer's disease, schizophrenia, and cognition, based on their effect weights from the Polygenic Score Catalog, thus enabling researchers to prioritize genetic variants in complex diseases. GENEVIC's operation is user-friendly, accessible without any specialized training, secured by Azure OpenAI's HIPAA-compliant infrastructure, and evaluated for its efficacy through real-time query testing. As a prototype, GENEVIC is set to advance genetic research, enabling informed biomedical decisions. Availability and implementation: GENEVIC is publicly accessible at https://genevic-anath2024.streamlit.app. The underlying code is open-source and available via GitHub at https://github.com/anath2110/GENEVIC.git.
RAnGE: Reachability Analysis for Guaranteed Ergodicity
Apr 04, 2024This paper investigates performance guarantees on coverage-based ergodic exploration methods in environments containing disturbances. Ergodic exploration methods generate trajectories for autonomous robots such that time spent in an area is proportional to the utility of exploring in the area. However, providing formal performance guarantees for ergodic exploration methods is still an open challenge due to the complexities in the problem formulation. In this work, we propose to formulate ergodic search as a differential game, in which a controller and external disturbance force seek to minimize and maximize the ergodic metric, respectively. Through an extended-state Bolza-form transform of the ergodic problem, we demonstrate it is possible to use techniques from reachability analysis to solve for optimal controllers that guarantee coverage and are robust against disturbances. Our approach leverages neural-network based methods to obtain approximate value function solutions for reachability problems that mitigate the increased computational scaling due to the extended state. As a result, we are able to compute continuous value functions for the ergodic exploration problem and provide performance guarantees for coverage under disturbances. Simulated and experimental results demonstrate the efficacy of our approach to generate robust ergodic trajectories for search and exploration with external disturbance force.
Performance of computer vision algorithms for fine-grained classification using crowdsourced insect images
Apr 04, 2024With fine-grained classification, we identify unique characteristics to distinguish among classes of the same super-class. We are focusing on species recognition in Insecta, as they are critical for biodiversity monitoring and at the base of many ecosystems. With citizen science campaigns, billions of images are collected in the wild. Once these are labelled, experts can use them to create distribution maps. However, the labelling process is time-consuming, which is where computer vision comes in. The field of computer vision offers a wide range of algorithms, each with its strengths and weaknesses; how do we identify the algorithm that is in line with our application? To answer this question, we provide a full and detailed evaluation of nine algorithms among deep convolutional networks (CNN), vision transformers (ViT), and locality-based vision transformers (LBVT) on 4 different aspects: classification performance, embedding quality, computational cost, and gradient activity. We offer insights that we haven't yet had in this domain proving to which extent these algorithms solve the fine-grained tasks in Insecta. We found that the ViT performs the best on inference speed and computational cost while the LBVT outperforms the others on performance and embedding quality; the CNN provide a trade-off among the metrics.
Future Predictive Success-or-Failure Classification for Long-Horizon Robotic Tasks
Apr 04, 2024Automating long-horizon tasks with a robotic arm has been a central research topic in robotics. Optimization-based action planning is an efficient approach for creating an action plan to complete a given task. Construction of a reliable planning method requires a design process of conditions, e.g., to avoid collision between objects. The design process, however, has two critical issues: 1) iterative trials--the design process is time-consuming due to the trial-and-error process of modifying conditions, and 2) manual redesign--it is difficult to cover all the necessary conditions manually. To tackle these issues, this paper proposes a future-predictive success-or-failure-classification method to obtain conditions automatically. The key idea behind the proposed method is an end-to-end approach for determining whether the action plan can complete a given task instead of manually redesigning the conditions. The proposed method uses a long-horizon future-prediction method to enable success-or-failure classification without the execution of an action plan. This paper also proposes a regularization term called transition consistency regularization to provide easy-to-predict feature distribution. The regularization term improves future prediction and classification performance. The effectiveness of our method is demonstrated through classification and robotic-manipulation experiments.
Advancing multivariate time series similarity assessment: an integrated computational approach
Mar 16, 2024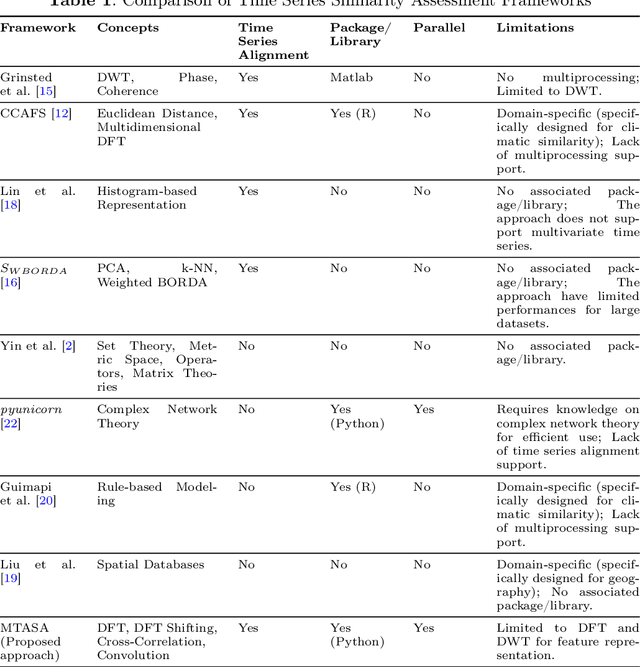
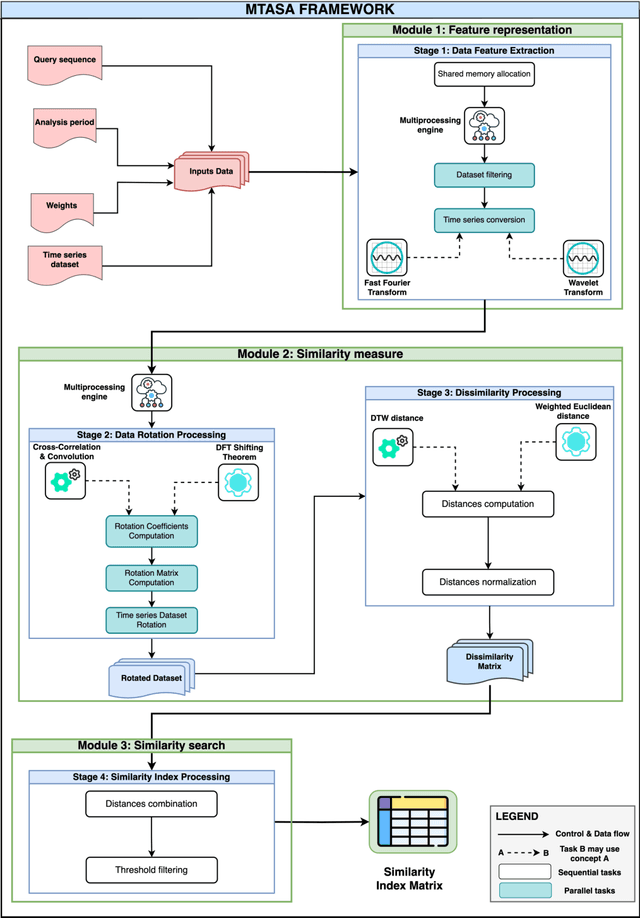
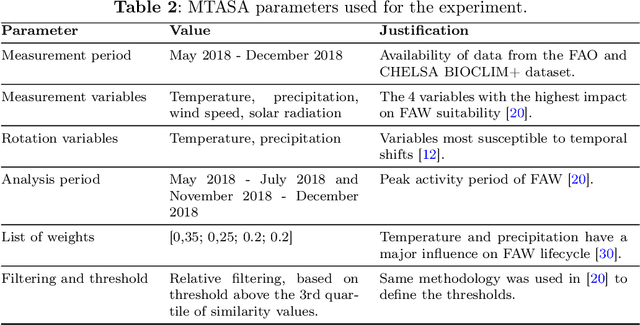
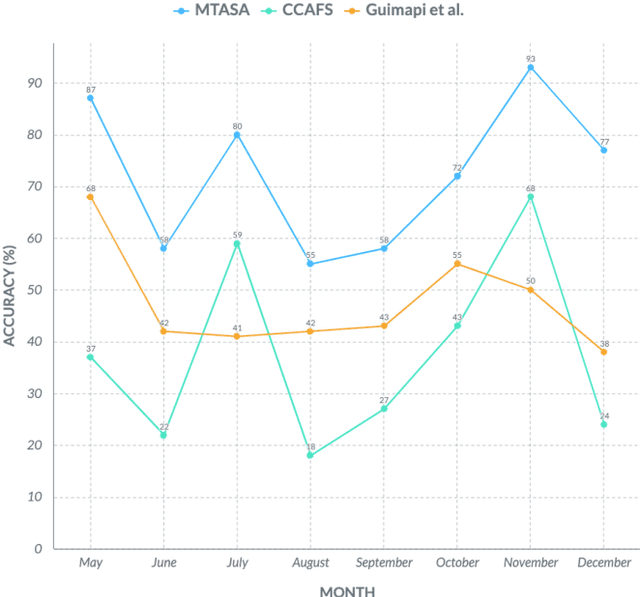
Data mining, particularly the analysis of multivariate time series data, plays a crucial role in extracting insights from complex systems and supporting informed decision-making across diverse domains. However, assessing the similarity of multivariate time series data presents several challenges, including dealing with large datasets, addressing temporal misalignments, and the need for efficient and comprehensive analytical frameworks. To address all these challenges, we propose a novel integrated computational approach known as Multivariate Time series Alignment and Similarity Assessment (MTASA). MTASA is built upon a hybrid methodology designed to optimize time series alignment, complemented by a multiprocessing engine that enhances the utilization of computational resources. This integrated approach comprises four key components, each addressing essential aspects of time series similarity assessment, thereby offering a comprehensive framework for analysis. MTASA is implemented as an open-source Python library with a user-friendly interface, making it accessible to researchers and practitioners. To evaluate the effectiveness of MTASA, we conducted an empirical study focused on assessing agroecosystem similarity using real-world environmental data. The results from this study highlight MTASA's superiority, achieving approximately 1.5 times greater accuracy and twice the speed compared to existing state-of-the-art integrated frameworks for multivariate time series similarity assessment. It is hoped that MTASA will significantly enhance the efficiency and accessibility of multivariate time series analysis, benefitting researchers and practitioners across various domains. Its capabilities in handling large datasets, addressing temporal misalignments, and delivering accurate results make MTASA a valuable tool for deriving insights and aiding decision-making processes in complex systems.
CODA: A COst-efficient Test-time Domain Adaptation Mechanism for HAR
Mar 22, 2024In recent years, emerging research on mobile sensing has led to novel scenarios that enhance daily life for humans, but dynamic usage conditions often result in performance degradation when systems are deployed in real-world settings. Existing solutions typically employ one-off adaptation schemes based on neural networks, which struggle to ensure robustness against uncertain drifting conditions in human-centric sensing scenarios. In this paper, we propose CODA, a COst-efficient Domain Adaptation mechanism for mobile sensing that addresses real-time drifts from the data distribution perspective with active learning theory, ensuring cost-efficient adaptation directly on the device. By incorporating a clustering loss and importance-weighted active learning algorithm, CODA retains the relationship between different clusters during cost-effective instance-level updates, preserving meaningful structure within the data distribution. We also showcase its generalization by seamlessly integrating it with Neural Network-based solutions for Human Activity Recognition tasks. Through meticulous evaluations across diverse datasets, including phone-based, watch-based, and integrated sensor-based sensing tasks, we demonstrate the feasibility and potential of online adaptation with CODA. The promising results achieved by CODA, even without learnable parameters, also suggest the possibility of realizing unobtrusive adaptation through specific application designs with sufficient feedback.