 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Video-Based Activity Classification of Human Pickers in Agriculture
Nov 17, 2023
In farming systems, harvesting operations are tedious, time- and resource-consuming tasks. Based on this, deploying a fleet of autonomous robots to work alongside farmworkers may provide vast productivity and logistics benefits. Then, an intelligent robotic system should monitor human behavior, identify the ongoing activities and anticipate the worker's needs. In this work, the main contribution consists of creating a benchmark model for video-based human pickers detection, classifying their activities to serve in harvesting operations for different agricultural scenarios. Our solution uses the combination of a Mask Region-based Convolutional Neural Network (Mask R-CNN) for object detection and optical flow for motion estimation with newly added statistical attributes of flow motion descriptors, named as Correlation Sensitivity (CS). A classification criterion is defined based on the Kernel Density Estimation (KDE) analysis and K-means clustering algorithm, which are implemented upon in-house collected dataset from different crop fields like strawberry polytunnels and apple tree orchards. The proposed framework is quantitatively analyzed using sensitivity, specificity, and accuracy measures and shows satisfactory results amidst various dataset challenges such as lighting variation, blur, and occlusions.
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Nov 16, 2023This study investigates the consequences of training large language models (LLMs) on synthetic data generated by their predecessors, an increasingly prevalent practice aimed at addressing the limited supply of human-generated training data. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we developed a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive fine-tuning experiments across various natural language generation tasks. Our findings reveal a marked decrease in the diversity of the models' outputs through successive iterations. This trend underscores the potential risks of training LLMs on predecessor-generated text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of LLMs.
Open-Vocabulary Camouflaged Object Segmentation
Nov 19, 2023
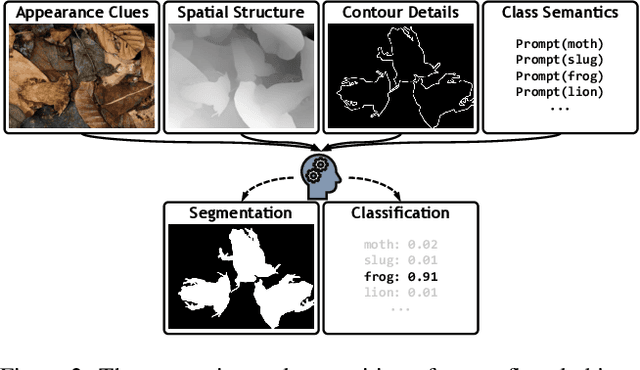
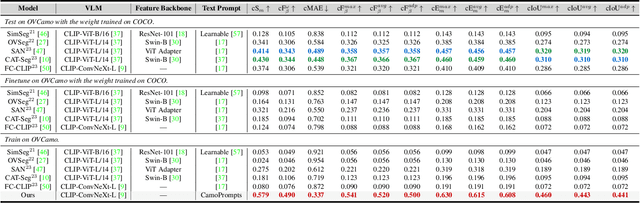

Recently, the emergence of the large-scale vision-language model (VLM), such as CLIP, has opened the way towards open-world object perception. Many works has explored the utilization of pre-trained VLM for the challenging open-vocabulary dense prediction task that requires perceive diverse objects with novel classes at inference time. Existing methods construct experiments based on the public datasets of related tasks, which are not tailored for open vocabulary and rarely involves imperceptible objects camouflaged in complex scenes due to data collection bias and annotation costs. To fill in the gaps, we introduce a new task, open-vocabulary camouflaged object segmentation (OVCOS) and construct a large-scale complex scene dataset (\textbf{OVCamo}) which containing 11,483 hand-selected images with fine annotations and corresponding object classes. Further, we build a strong single-stage open-vocabulary \underline{c}amouflaged \underline{o}bject \underline{s}egmentation transform\underline{er} baseline \textbf{OVCoser} attached to the parameter-fixed CLIP with iterative semantic guidance and structure enhancement. By integrating the guidance of class semantic knowledge and the supplement of visual structure cues from the edge and depth information, the proposed method can efficiently capture camouflaged objects. Moreover, this effective framework also surpasses previous state-of-the-arts of open-vocabulary semantic image segmentation by a large margin on our OVCamo dataset. With the proposed dataset and baseline, we hope that this new task with more practical value can further expand the research on open-vocabulary dense prediction tasks.
Real-time Bandwidth Estimation from Offline Expert Demonstrations
Sep 23, 2023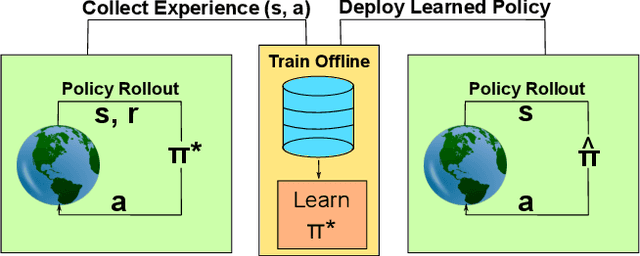



In this work, we tackle the problem of bandwidth estimation (BWE) for real-time communication systems; however, in contrast to previous works, we leverage the vast efforts of prior heuristic-based BWE methods and synergize these approaches with deep learning-based techniques. Our work addresses challenges in generalizing to unseen network dynamics and extracting rich representations from prior experience, two key challenges in integrating data-driven bandwidth estimators into real-time systems. To that end, we propose Merlin, the first purely offline, data-driven solution to BWE that harnesses prior heuristic-based methods to extract an expert BWE policy. Through a series of experiments, we demonstrate that Merlin surpasses state-of-the-art heuristic-based and deep learning-based bandwidth estimators in terms of objective quality of experience metrics while generalizing beyond the offline world to in-the-wild network deployments where Merlin achieves a 42.85% and 12.8% reduction in packet loss and delay, respectively, when compared against WebRTC in inter-continental videoconferencing calls. We hope that Merlin's offline-oriented design fosters new strategies for real-time network control.
Invariant-based Mapping of Space During General Motion of an Observer
Nov 18, 2023This paper explores visual motion-based invariants, resulting in a new instantaneous domain where: a) the stationary environment is perceived as unchanged, even as the 2D images undergo continuous changes due to camera motion, b) obstacles can be detected and potentially avoided in specific subspaces, and c) moving objects can potentially be detected. To achieve this, we make use of nonlinear functions derived from measurable optical flow, which are linked to geometric 3D invariants. We present simulations involving a camera that translates and rotates relative to a 3D object, capturing snapshots of the camera projected images. We show that the object appears unchanged in the new domain over time. We process real data from the KITTI dataset and demonstrate how to segment space to identify free navigational regions and detect obstacles within a predetermined subspace. Additionally, we present preliminary results, based on the KITTI dataset, on the identification and segmentation of moving objects, as well as the visualization of shape constancy. This representation is straightforward, relying on functions for the simple de-rotation of optical flow. This representation only requires a single camera, it is pixel-based, making it suitable for parallel processing, and it eliminates the necessity for 3D reconstruction techniques.
SBTRec- A Transformer Framework for Personalized Tour Recommendation Problem with Sentiment Analysis
Nov 18, 2023
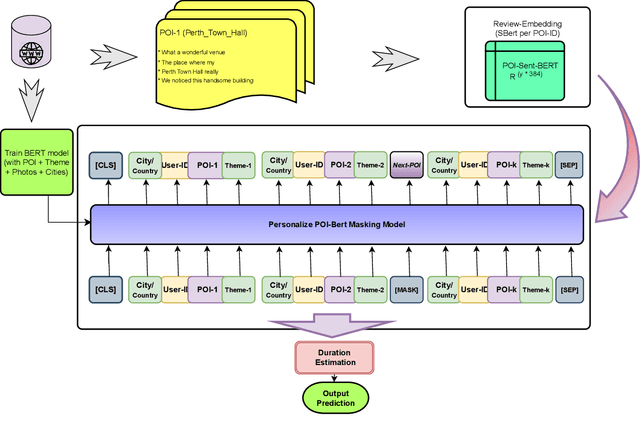
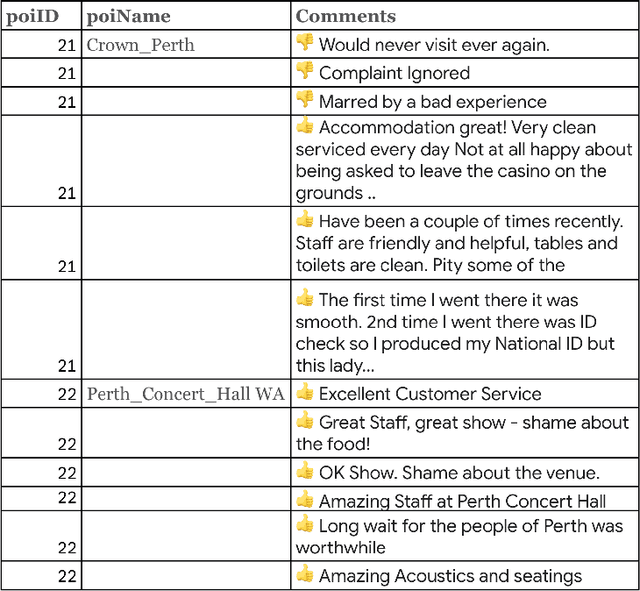
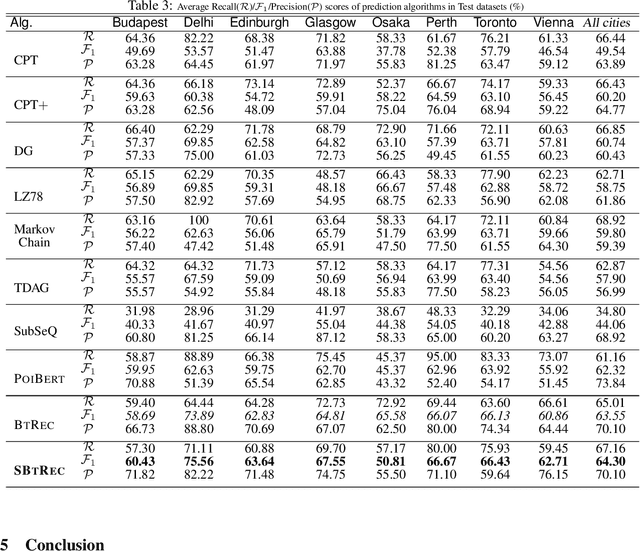
When traveling to an unfamiliar city for holidays, tourists often rely on guidebooks, travel websites, or recommendation systems to plan their daily itineraries and explore popular points of interest (POIs). However, these approaches may lack optimization in terms of time feasibility, localities, and user preferences. In this paper, we propose the SBTRec algorithm: a BERT-based Trajectory Recommendation with sentiment analysis, for recommending personalized sequences of POIs as itineraries. The key contributions of this work include analyzing users' check-ins and uploaded photos to understand the relationship between POI visits and distance. We introduce SBTRec, which encompasses sentiment analysis to improve recommendation accuracy by understanding users' preferences and satisfaction levels from reviews and comments about different POIs. Our proposed algorithms are evaluated against other sequence prediction methods using datasets from 8 cities. The results demonstrate that SBTRec achieves an average F1 score of 61.45%, outperforming baseline algorithms. The paper further discusses the flexibility of the SBTRec algorithm, its ability to adapt to different scenarios and cities without modification, and its potential for extension by incorporating additional information for more reliable predictions. Overall, SBTRec provides personalized and relevant POI recommendations, enhancing tourists' overall trip experiences. Future work includes fine-tuning personalized embeddings for users, with evaluation of users' comments on POIs,~to further enhance prediction accuracy.
BeamSync: Over-The-Air Synchronization for Distributed Massive MIMO Systems
Nov 18, 2023In distributed massive multiple-input multiple-output (MIMO) systems, multiple geographically separated access points (APs) communicate simultaneously with a user, leveraging the benefits of multi-antenna coherent MIMO processing and macro-diversity gains from the distributed setups. However, time and frequency synchronization of the multiple APs is crucial to achieve good performance and enable joint precoding. In this paper, we analyze the synchronization requirement among multiple APs from a reciprocity perspective, taking into account the multiplicative impairments caused by mismatches in radio frequency (RF) hardware. We demonstrate that a phase calibration of reciprocity-calibrated APs is sufficient for the joint coherent transmission of data to the user. To achieve synchronization, we propose a novel over-the-air synchronization protocol, named BeamSync, to calibrate the geographically separated APs without sending any measurements to the central processing unit (CPU) through fronthaul. We show that sending the synchronization signal in the dominant direction of the channel between APs is optimal. Additionally, we derive the optimal phase and frequency offset estimators. Simulation results indicate that the proposed BeamSync method enhances performance by 3 dB when the number of antennas at the APs is doubled. Moreover, the method performs well compared to traditional beamforming techniques.
SNI-SLAM: Semantic Neural Implicit SLAM
Nov 18, 2023We propose SNI-SLAM, a semantic SLAM system utilizing neural implicit representation, that simultaneously performs accurate semantic mapping, high-quality surface reconstruction, and robust camera tracking. In this system, we introduce hierarchical semantic representation to allow multi-level semantic comprehension for top-down structured semantic mapping of the scene. In addition, to fully utilize the correlation between multiple attributes of the environment, we integrate appearance, geometry and semantic features through cross-attention for feature collaboration. This strategy enables a more multifaceted understanding of the environment, thereby allowing SNI-SLAM to remain robust even when single attribute is defective. Then, we design an internal fusion-based decoder to obtain semantic, RGB, Truncated Signed Distance Field (TSDF) values from multi-level features for accurate decoding. Furthermore, we propose a feature loss to update the scene representation at the feature level. Compared with low-level losses such as RGB loss and depth loss, our feature loss is capable of guiding the network optimization on a higher-level. Our SNI-SLAM method demonstrates superior performance over all recent NeRF-based SLAM methods in terms of mapping and tracking accuracy on Replica and ScanNet datasets, while also showing excellent capabilities in accurate semantic segmentation and real-time semantic mapping.
Semantic Communication for Cooperative Perception based on Importance Map
Nov 11, 2023Cooperative perception, which has a broader perception field than single-vehicle perception, has played an increasingly important role in autonomous driving to conduct 3D object detection. Through vehicle-to-vehicle (V2V) communication technology, various connected automated vehicles (CAVs) can share their sensory information (LiDAR point clouds) for cooperative perception. We employ an importance map to extract significant semantic information and propose a novel cooperative perception semantic communication scheme with intermediate fusion. Meanwhile, our proposed architecture can be extended to the challenging time-varying multipath fading channel. To alleviate the distortion caused by the time-varying multipath fading, we adopt explicit orthogonal frequency-division multiplexing (OFDM) blocks combined with channel estimation and channel equalization. Simulation results demonstrate that our proposed model outperforms the traditional separate source-channel coding over various channel models. Moreover, a robustness study indicates that only part of semantic information is key to cooperative perception. Although our proposed model has only been trained over one specific channel, it has the ability to learn robust coded representations of semantic information that remain resilient to various channel models, demonstrating its generality and robustness.
Diffeomorphic Transformations for Time Series Analysis: An Efficient Approach to Nonlinear Warping
Sep 25, 2023The proliferation and ubiquity of temporal data across many disciplines has sparked interest for similarity, classification and clustering methods specifically designed to handle time series data. A core issue when dealing with time series is determining their pairwise similarity, i.e., the degree to which a given time series resembles another. Traditional distance measures such as the Euclidean are not well-suited due to the time-dependent nature of the data. Elastic metrics such as dynamic time warping (DTW) offer a promising approach, but are limited by their computational complexity, non-differentiability and sensitivity to noise and outliers. This thesis proposes novel elastic alignment methods that use parametric \& diffeomorphic warping transformations as a means of overcoming the shortcomings of DTW-based metrics. The proposed method is differentiable \& invertible, well-suited for deep learning architectures, robust to noise and outliers, computationally efficient, and is expressive and flexible enough to capture complex patterns. Furthermore, a closed-form solution was developed for the gradient of these diffeomorphic transformations, which allows an efficient search in the parameter space, leading to better solutions at convergence. Leveraging the benefits of these closed-form diffeomorphic transformations, this thesis proposes a suite of advancements that include: (a) an enhanced temporal transformer network for time series alignment and averaging, (b) a deep-learning based time series classification model to simultaneously align and classify signals with high accuracy, (c) an incremental time series clustering algorithm that is warping-invariant, scalable and can operate under limited computational and time resources, and finally, (d) a normalizing flow model that enhances the flexibility of affine transformations in coupling and autoregressive layers.