 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Potential and Limitations of Few-Shot In-Context Learning to Generate Metamorphic Specifications for Tax Preparation Software
Nov 20, 2023
Due to the ever-increasing complexity of income tax laws in the United States, the number of US taxpayers filing their taxes using tax preparation software (henceforth, tax software) continues to increase. According to the U.S. Internal Revenue Service (IRS), in FY22, nearly 50% of taxpayers filed their individual income taxes using tax software. Given the legal consequences of incorrectly filing taxes for the taxpayer, ensuring the correctness of tax software is of paramount importance. Metamorphic testing has emerged as a leading solution to test and debug legal-critical tax software due to the absence of correctness requirements and trustworthy datasets. The key idea behind metamorphic testing is to express the properties of a system in terms of the relationship between one input and its slightly metamorphosed twinned input. Extracting metamorphic properties from IRS tax publications is a tedious and time-consuming process. As a response, this paper formulates the task of generating metamorphic specifications as a translation task between properties extracted from tax documents - expressed in natural language - to a contrastive first-order logic form. We perform a systematic analysis on the potential and limitations of in-context learning with Large Language Models(LLMs) for this task, and outline a research agenda towards automating the generation of metamorphic specifications for tax preparation software.
APNet2: High-quality and High-efficiency Neural Vocoder with Direct Prediction of Amplitude and Phase Spectra
Nov 20, 2023In our previous work, we proposed a neural vocoder called APNet, which directly predicts speech amplitude and phase spectra with a 5 ms frame shift in parallel from the input acoustic features, and then reconstructs the 16 kHz speech waveform using inverse short-time Fourier transform (ISTFT). APNet demonstrates the capability to generate synthesized speech of comparable quality to the HiFi-GAN vocoder but with a considerably improved inference speed. However, the performance of the APNet vocoder is constrained by the waveform sampling rate and spectral frame shift, limiting its practicality for high-quality speech synthesis. Therefore, this paper proposes an improved iteration of APNet, named APNet2. The proposed APNet2 vocoder adopts ConvNeXt v2 as the backbone network for amplitude and phase predictions, expecting to enhance the modeling capability. Additionally, we introduce a multi-resolution discriminator (MRD) into the GAN-based losses and optimize the form of certain losses. At a common configuration with a waveform sampling rate of 22.05 kHz and spectral frame shift of 256 points (i.e., approximately 11.6ms), our proposed APNet2 vocoder outperformed the original APNet and Vocos vocoders in terms of synthesized speech quality. The synthesized speech quality of APNet2 is also comparable to that of HiFi-GAN and iSTFTNet, while offering a significantly faster inference speed.
Learning quantum Hamiltonians at any temperature in polynomial time
Oct 03, 2023We study the problem of learning a local quantum Hamiltonian $H$ given copies of its Gibbs state $\rho = e^{-\beta H}/\textrm{tr}(e^{-\beta H})$ at a known inverse temperature $\beta>0$. Anshu, Arunachalam, Kuwahara, and Soleimanifar (arXiv:2004.07266) gave an algorithm to learn a Hamiltonian on $n$ qubits to precision $\epsilon$ with only polynomially many copies of the Gibbs state, but which takes exponential time. Obtaining a computationally efficient algorithm has been a major open problem [Alhambra'22 (arXiv:2204.08349)], [Anshu, Arunachalam'22 (arXiv:2204.08349)], with prior work only resolving this in the limited cases of high temperature [Haah, Kothari, Tang'21 (arXiv:2108.04842)] or commuting terms [Anshu, Arunachalam, Kuwahara, Soleimanifar'21]. We fully resolve this problem, giving a polynomial time algorithm for learning $H$ to precision $\epsilon$ from polynomially many copies of the Gibbs state at any constant $\beta > 0$. Our main technical contribution is a new flat polynomial approximation to the exponential function, and a translation between multi-variate scalar polynomials and nested commutators. This enables us to formulate Hamiltonian learning as a polynomial system. We then show that solving a low-degree sum-of-squares relaxation of this polynomial system suffices to accurately learn the Hamiltonian.
Estimating optical vegetation indices with Sentinel-1 SAR data and AutoML
Nov 13, 2023Current optical vegetation indices (VIs) for monitoring forest ecosystems are widely used in various applications. However, continuous monitoring based on optical satellite data can be hampered by atmospheric effects such as clouds. On the contrary, synthetic aperture radar (SAR) data can offer insightful and systematic forest monitoring with complete time series due to signal penetration through clouds and day and night acquisitions. The goal of this work is to overcome the issues affecting optical data with SAR data and serve as a substitute for estimating optical VIs for forests using machine learning. Time series of four VIs (LAI, FAPAR, EVI and NDVI) were estimated using multitemporal Sentinel-1 SAR and ancillary data. This was enabled by creating a paired multi-temporal and multi-modal dataset in Google Earth Engine (GEE), including temporally and spatially aligned Sentinel-1, Sentinel-2, digital elevation model (DEM), weather and land cover datasets (MMT-GEE). The use of ancillary features generated from DEM and weather data improved the results. The open-source Automatic Machine Learning (AutoML) approach, auto-sklearn, outperformed Random Forest Regression for three out of four VIs, while a 1-hour optimization length was enough to achieve sufficient results with an R2 of 69-84% low errors (0.05-0.32 of MAE depending on VI). Great agreement was also found for selected case studies in the time series analysis and in the spatial comparison between the original and estimated SAR-based VIs. In general, compared to VIs from currently freely available optical satellite data and available global VI products, a better temporal resolution (up to 240 measurements/year) and a better spatial resolution (20 m) were achieved using estimated SAR-based VIs. A great advantage of the SAR-based VI is the ability to detect abrupt forest changes with a sub-weekly temporal accuracy.
Evolving Domain Adaptation of Pretrained Language Models for Text Classification
Nov 16, 2023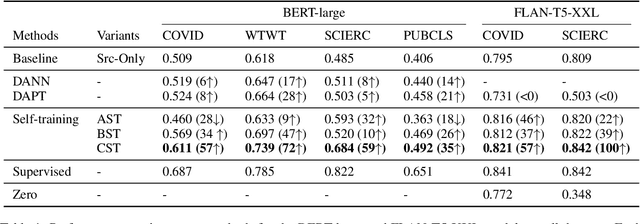

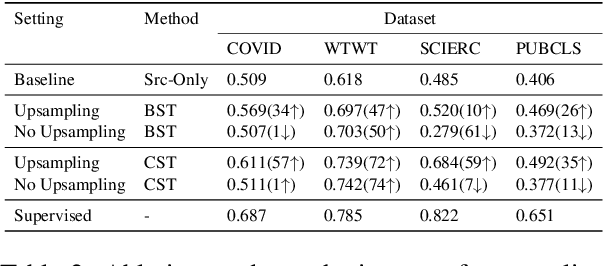
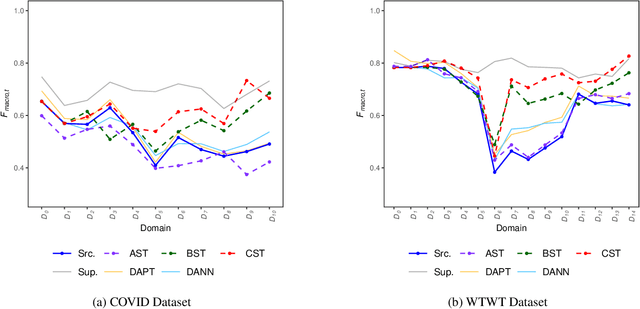
Adapting pre-trained language models (PLMs) for time-series text classification amidst evolving domain shifts (EDS) is critical for maintaining accuracy in applications like stance detection. This study benchmarks the effectiveness of evolving domain adaptation (EDA) strategies, notably self-training, domain-adversarial training, and domain-adaptive pretraining, with a focus on an incremental self-training method. Our analysis across various datasets reveals that this incremental method excels at adapting PLMs to EDS, outperforming traditional domain adaptation techniques. These findings highlight the importance of continually updating PLMs to ensure their effectiveness in real-world applications, paving the way for future research into PLM robustness against the natural temporal evolution of language.
Apoptosis classification using attention based spatio temporal graph convolution neural network
Nov 16, 2023Accurate classification of apoptosis plays an important role in cell biology research. There are many state-of-the-art approaches which use deep CNNs to perform the apoptosis classification but these approaches do not account for the cell interaction. Our paper proposes the Attention Graph spatio-temporal graph convolutional network to classify the cell death based on the target cells in the video. This method considers the interaction of multiple target cells at each time stamp. We model the whole video sequence as a set of graphs and classify the target cell in the video as dead or alive. Our method encounters both spatial and temporal relationships.
Context Consistency between Training and Testing in Simultaneous Machine Translation
Nov 13, 2023Simultaneous Machine Translation (SiMT) aims to yield a real-time partial translation with a monotonically growing the source-side context. However, there is a counterintuitive phenomenon about the context usage between training and testing: e.g., the wait-k testing model consistently trained with wait-k is much worse than that model inconsistently trained with wait-k' (k' is not equal to k) in terms of translation quality. To this end, we first investigate the underlying reasons behind this phenomenon and uncover the following two factors: 1) the limited correlation between translation quality and training (cross-entropy) loss; 2) exposure bias between training and testing. Based on both reasons, we then propose an effective training approach called context consistency training accordingly, which makes consistent the context usage between training and testing by optimizing translation quality and latency as bi-objectives and exposing the predictions to the model during the training. The experiments on three language pairs demonstrate our intuition: our system encouraging context consistency outperforms that existing systems with context inconsistency for the first time, with the help of our context consistency training approach.
Embarassingly Simple Dataset Distillation
Nov 13, 2023Dataset distillation extracts a small set of synthetic training samples from a large dataset with the goal of achieving competitive performance on test data when trained on this sample. In this work, we tackle dataset distillation at its core by treating it directly as a bilevel optimization problem. Re-examining the foundational back-propagation through time method, we study the pronounced variance in the gradients, computational burden, and long-term dependencies. We introduce an improved method: Random Truncated Backpropagation Through Time (RaT-BPTT) to address them. RaT-BPTT incorporates a truncation coupled with a random window, effectively stabilizing the gradients and speeding up the optimization while covering long dependencies. This allows us to establish new state-of-the-art for a variety of standard dataset benchmarks. A deeper dive into the nature of distilled data unveils pronounced intercorrelation. In particular, subsets of distilled datasets tend to exhibit much worse performance than directly distilled smaller datasets of the same size. Leveraging RaT-BPTT, we devise a boosting mechanism that generates distilled datasets that contain subsets with near optimal performance across different data budgets.
Fast Normalized Cross-Correlation for Template Matching with Rotations
Nov 13, 2023Normalized cross-correlation is the reference approach to carry out template matching on images. When it is computed in Fourier space, it can handle efficiently template translations but it cannot do so with template rotations. Including rotations requires sampling the whole space of rotations, repeating the computation of the correlation each time. This article develops an alternative mathematical theory to handle efficiently, at the same time, rotations and translations. Our proposal has a reduced computational complexity because it does not require to repeatedly sample the space of rotations. To do so, we integrate the information relative to all rotated versions of the template into a unique symmetric tensor template -which is computed only once per template-. Afterward, we demonstrate that the correlation between the image to be processed with the independent tensor components of the tensorial template contains enough information to recover template instance positions and rotations. Our proposed method has the potential to speed up conventional template matching computations by a factor of several magnitude orders for the case of 3D images.
Supersampling of Data from Structured-light Scanner with Deep Learning
Nov 13, 2023This paper focuses on increasing the resolution of depth maps obtained from 3D cameras using structured light technology. Two deep learning models FDSR and DKN are modified to work with high-resolution data, and data pre-processing techniques are implemented for stable training. The models are trained on our custom dataset of 1200 3D scans. The resulting high-resolution depth maps are evaluated using qualitative and quantitative metrics. The approach for depth map upsampling offers benefits such as reducing the processing time of a pipeline by first downsampling a high-resolution depth map, performing various processing steps at the lower resolution and upsampling the resulting depth map or increasing the resolution of a point cloud captured in lower resolution by a cheaper device. The experiments demonstrate that the FDSR model excels in terms of faster processing time, making it a suitable choice for applications where speed is crucial. On the other hand, the DKN model provides results with higher precision, making it more suitable for applications that prioritize accuracy.