 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Continuous Locomotion Modes via Multidimensional Feature Learning from sEMG
Nov 13, 2023
Walking-assistive devices require adaptive control methods to ensure smooth transitions between various modes of locomotion. For this purpose, detecting human locomotion modes (e.g., level walking or stair ascent) in advance is crucial for improving the intelligence and transparency of such robotic systems. This study proposes Deep-STF, a unified end-to-end deep learning model designed for integrated feature extraction in spatial, temporal, and frequency dimensions from surface electromyography (sEMG) signals. Our model enables accurate and robust continuous prediction of nine locomotion modes and 15 transitions at varying prediction time intervals, ranging from 100 to 500 ms. In addition, we introduced the concept of 'stable prediction time' as a distinct metric to quantify prediction efficiency. This term refers to the duration during which consistent and accurate predictions of mode transitions are made, measured from the time of the fifth correct prediction to the occurrence of the critical event leading to the task transition. This distinction between stable prediction time and prediction time is vital as it underscores our focus on the precision and reliability of mode transition predictions. Experimental results showcased Deep-STP's cutting-edge prediction performance across diverse locomotion modes and transitions, relying solely on sEMG data. When forecasting 100 ms ahead, Deep-STF surpassed CNN and other machine learning techniques, achieving an outstanding average prediction accuracy of 96.48%. Even with an extended 500 ms prediction horizon, accuracy only marginally decreased to 93.00%. The averaged stable prediction times for detecting next upcoming transitions spanned from 28.15 to 372.21 ms across the 100-500 ms time advances.
Test-Time Training for Speech
Sep 28, 2023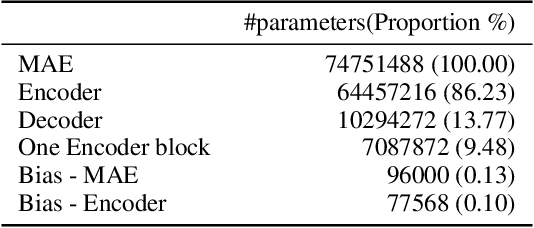

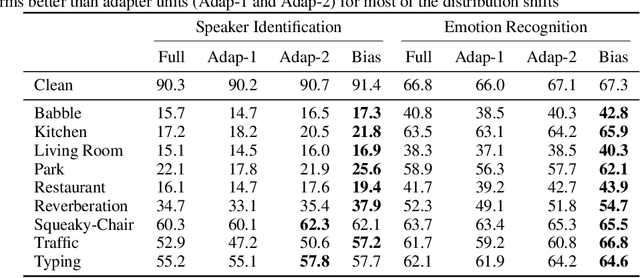
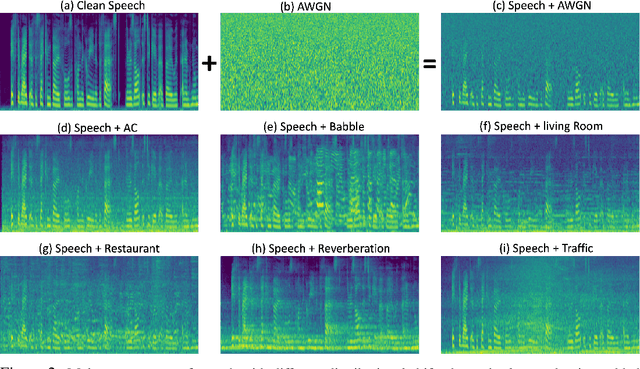
In this paper, we study the application of Test-Time Training (TTT) as a solution to handling distribution shifts in speech applications. In particular, we introduce distribution-shifts to the test datasets of standard speech-classification tasks -- for example, speaker-identification and emotion-detection -- and explore how Test-Time Training (TTT) can help adjust to the distribution-shift. In our experiments that include distribution shifts due to background noise and natural variations in speech such as gender and age, we identify some key-challenges with TTT including sensitivity to optimization hyperparameters (e.g., number of optimization steps and subset of parameters chosen for TTT) and scalability (e.g., as each example gets its own set of parameters, TTT is not scalable). Finally, we propose using BitFit -- a parameter-efficient fine-tuning algorithm proposed for text applications that only considers the bias parameters for fine-tuning -- as a solution to the aforementioned challenges and demonstrate that it is consistently more stable than fine-tuning all the parameters of the model.
Take One Step at a Time to Know Incremental Utility of Demonstration: An Analysis on Reranking for Few-Shot In-Context Learning
Nov 16, 2023In-Context Learning (ICL) is an emergent capability of Large Language Models (LLMs). Only a few demonstrations enable LLMs to be used as blackbox for new tasks. Previous studies have shown that using LLMs' outputs as labels is effective in training models to select demonstrations. Such a label is expected to estimate utility of a demonstration in ICL; however, it has not been well understood how different labeling strategies affect results on target tasks. This paper presents an analysis on different utility functions by focusing on LLMs' output probability given ground-truth output, and task-specific reward given LLMs' prediction. Unlike the previous work, we introduce a novel labeling method, incremental utility, which estimates how much incremental knowledge is brought into the LLMs by a demonstration. We conduct experiments with instruction-tuned LLMs on binary/multi-class classification, segmentation, and translation across Arabic, English, Finnish, Japanese, and Spanish. Our results show that (1) the probability is effective when the probability values are distributed across the whole value range (on the classification tasks), and (2) the downstream metric is more robust when nuanced reward values are provided with long outputs (on the segmentation and translation tasks). We then show that the proposed incremental utility further helps ICL by contrasting how the LLMs perform with and without the demonstrations.
Efficient Encoding of Graphics Primitives with Simplex-based Structures
Nov 26, 2023Grid-based structures are commonly used to encode explicit features for graphics primitives such as images, signed distance functions (SDF), and neural radiance fields (NeRF) due to their simple implementation. However, in $n$-dimensional space, calculating the value of a sampled point requires interpolating the values of its $2^n$ neighboring vertices. The exponential scaling with dimension leads to significant computational overheads. To address this issue, we propose a simplex-based approach for encoding graphics primitives. The number of vertices in a simplex-based structure increases linearly with dimension, making it a more efficient and generalizable alternative to grid-based representations. Using the non-axis-aligned simplicial structure property, we derive and prove a coordinate transformation, simplicial subdivision, and barycentric interpolation scheme for efficient sampling, which resembles transformation procedures in the simplex noise algorithm. Finally, we use hash tables to store multiresolution features of all interest points in the simplicial grid, which are passed into a tiny fully connected neural network to parameterize graphics primitives. We implemented a detailed simplex-based structure encoding algorithm in C++ and CUDA using the methods outlined in our approach. In the 2D image fitting task, the proposed method is capable of fitting a giga-pixel image with 9.4% less time compared to the baseline method proposed by instant-ngp, while maintaining the same quality and compression rate. In the volumetric rendering setup, we observe a maximum 41.2% speedup when the samples are dense enough.
Animate124: Animating One Image to 4D Dynamic Scene
Nov 24, 2023We introduce Animate124 (Animate-one-image-to-4D), the first work to animate a single in-the-wild image into 3D video through textual motion descriptions, an underexplored problem with significant applications. Our 4D generation leverages an advanced 4D grid dynamic Neural Radiance Field (NeRF) model, optimized in three distinct stages using multiple diffusion priors. Initially, a static model is optimized using the reference image, guided by 2D and 3D diffusion priors, which serves as the initialization for the dynamic NeRF. Subsequently, a video diffusion model is employed to learn the motion specific to the subject. However, the object in the 3D videos tends to drift away from the reference image over time. This drift is mainly due to the misalignment between the text prompt and the reference image in the video diffusion model. In the final stage, a personalized diffusion prior is therefore utilized to address the semantic drift. As the pioneering image-text-to-4D generation framework, our method demonstrates significant advancements over existing baselines, evidenced by comprehensive quantitative and qualitative assessments.
Federated Transformed Learning for a Circular, Secure, and Tiny AI
Nov 24, 2023Deep Learning (DL) is penetrating into a diverse range of mass mobility, smart living, and industrial applications, rapidly transforming the way we live and work. DL is at the heart of many AI implementations. A key set of challenges is to produce AI modules that are: (1) "circular" - can solve new tasks without forgetting how to solve previous ones, (2) "secure" - have immunity to adversarial data attacks, and (3) "tiny" - implementable in low power low cost embedded hardware. Clearly it is difficult to achieve all three aspects on a single horizontal layer of platforms, as the techniques require transformed deep representations that incur different computation and communication requirements. Here we set out the vision to achieve transformed DL representations across a 5G and Beyond networked architecture. We first detail the cross-sectoral motivations for each challenge area, before demonstrating recent advances in DL research that can achieve circular, secure, and tiny AI (CST-AI). Recognising the conflicting demand of each transformed deep representation, we federate their deep learning transformations and functionalities across the network to achieve connected run-time capabilities.
GATGPT: A Pre-trained Large Language Model with Graph Attention Network for Spatiotemporal Imputation
Nov 24, 2023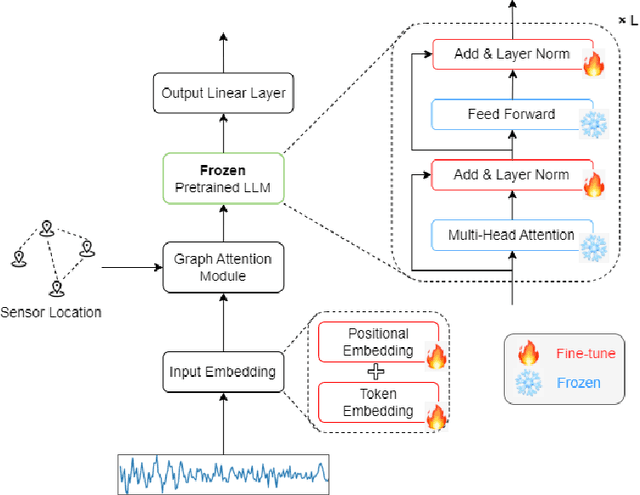
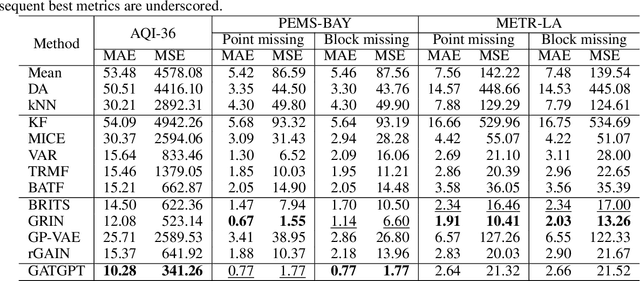
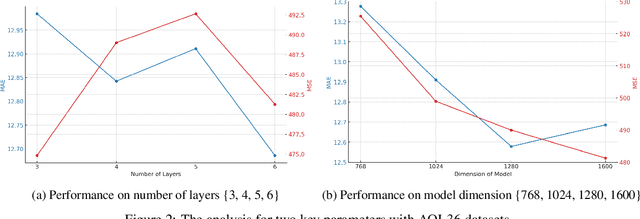
The analysis of spatiotemporal data is increasingly utilized across diverse domains, including transportation, healthcare, and meteorology. In real-world settings, such data often contain missing elements due to issues like sensor malfunctions and data transmission errors. The objective of spatiotemporal imputation is to estimate these missing values by understanding the inherent spatial and temporal relationships in the observed multivariate time series. Traditionally, spatiotemporal imputation has relied on specific, intricate architectures designed for this purpose, which suffer from limited applicability and high computational complexity. In contrast, our approach integrates pre-trained large language models (LLMs) into spatiotemporal imputation, introducing a groundbreaking framework, GATGPT. This framework merges a graph attention mechanism with LLMs. We maintain most of the LLM parameters unchanged to leverage existing knowledge for learning temporal patterns, while fine-tuning the upper layers tailored to various applications. The graph attention component enhances the LLM's ability to understand spatial relationships. Through tests on three distinct real-world datasets, our innovative approach demonstrates comparable results to established deep learning benchmarks.
Towards a more inductive world for drug repurposing approaches
Nov 24, 2023Drug-target interaction (DTI) prediction is a challenging, albeit essential task in drug repurposing. Learning on graph models have drawn special attention as they can significantly reduce drug repurposing costs and time commitment. However, many current approaches require high-demanding additional information besides DTIs that complicates their evaluation process and usability. Additionally, structural differences in the learning architecture of current models hinder their fair benchmarking. In this work, we first perform an in-depth evaluation of current DTI datasets and prediction models through a robust benchmarking process, and show that DTI prediction methods based on transductive models lack generalization and lead to inflated performance when evaluated as previously done in the literature, hence not being suited for drug repurposing approaches. We then propose a novel biologically-driven strategy for negative edge subsampling and show through in vitro validation that newly discovered interactions are indeed true. We envision this work as the underpinning for future fair benchmarking and robust model design. All generated resources and tools are publicly available as a python package.
Infinite forecast combinations based on Dirichlet process
Nov 24, 2023Forecast combination integrates information from various sources by consolidating multiple forecast results from the target time series. Instead of the need to select a single optimal forecasting model, this paper introduces a deep learning ensemble forecasting model based on the Dirichlet process. Initially, the learning rate is sampled with three basis distributions as hyperparameters to convert the infinite mixture into a finite one. All checkpoints are collected to establish a deep learning sub-model pool, and weight adjustment and diversity strategies are developed during the combination process. The main advantage of this method is its ability to generate the required base learners through a single training process, utilizing the decaying strategy to tackle the challenge posed by the stochastic nature of gradient descent in determining the optimal learning rate. To ensure the method's generalizability and competitiveness, this paper conducts an empirical analysis using the weekly dataset from the M4 competition and explores sensitivity to the number of models to be combined. The results demonstrate that the ensemble model proposed offers substantial improvements in prediction accuracy and stability compared to a single benchmark model.
Creating Temporally Correlated High-Resolution Power Injection Profiles Using Physics-Aware GAN
Nov 22, 2023Traditional smart meter measurements lack the granularity needed for real-time decision-making. To address this practical problem, we create a generative adversarial networks (GAN) model that enforces temporal consistency on its high-resolution outputs via hard inequality constraints using a convex optimization layer. A unique feature of our GAN model is that it is trained solely on slow timescale aggregated power information obtained from historical smart meter data. The results demonstrate that the model can successfully create minutely interval temporally-correlated instantaneous power injection profiles from 15-minute average power consumption information. This innovative approach, emphasizing inter-neuron constraints, offers a promising avenue for improved high-speed state estimation in distribution systems and enhances the applicability of data-driven solutions for monitoring such systems.