 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BACTrack: Building Appearance Collection for Aerial Tracking
Dec 11, 2023
Siamese network-based trackers have shown remarkable success in aerial tracking. Most previous works, however, usually perform template matching only between the initial template and the search region and thus fail to deal with rapidly changing targets that often appear in aerial tracking. As a remedy, this work presents Building Appearance Collection Tracking (BACTrack). This simple yet effective tracking framework builds a dynamic collection of target templates online and performs efficient multi-template matching to achieve robust tracking. Specifically, BACTrack mainly comprises a Mixed-Temporal Transformer (MTT) and an appearance discriminator. The former is responsible for efficiently building relationships between the search region and multiple target templates in parallel through a mixed-temporal attention mechanism. At the same time, the appearance discriminator employs an online adaptive template-update strategy to ensure that the collected multiple templates remain reliable and diverse, allowing them to closely follow rapid changes in the target's appearance and suppress background interference during tracking. Extensive experiments show that our BACTrack achieves top performance on four challenging aerial tracking benchmarks while maintaining an impressive speed of over 87 FPS on a single GPU. Speed tests on embedded platforms also validate our potential suitability for deployment on UAV platforms.
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Dec 11, 2023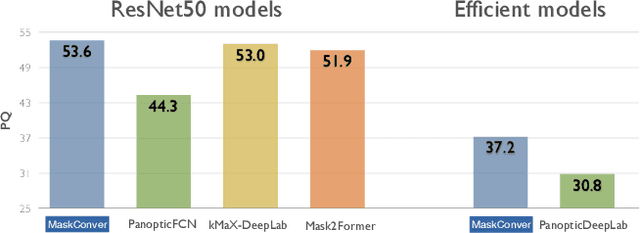
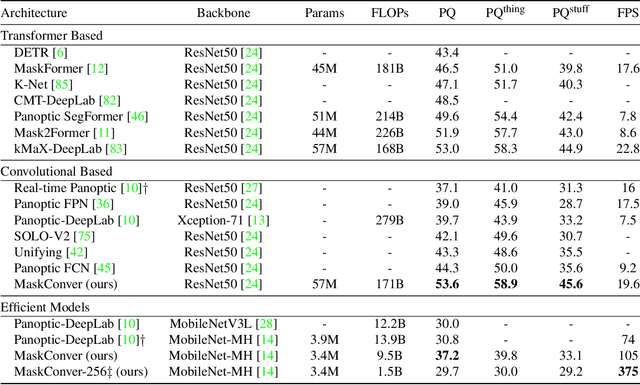
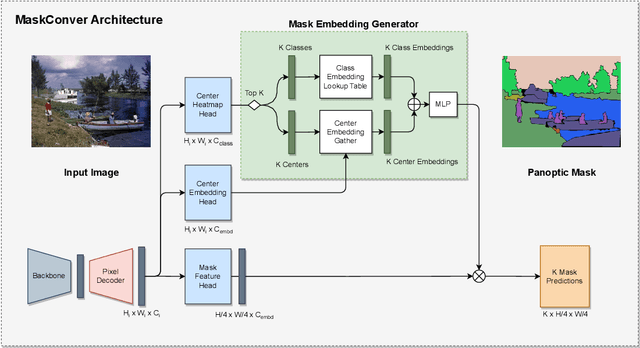

In recent years, transformer-based models have dominated panoptic segmentation, thanks to their strong modeling capabilities and their unified representation for both semantic and instance classes as global binary masks. In this paper, we revisit pure convolution model and propose a novel panoptic architecture named MaskConver. MaskConver proposes to fully unify things and stuff representation by predicting their centers. To that extent, it creates a lightweight class embedding module that can break the ties when multiple centers co-exist in the same location. Furthermore, our study shows that the decoder design is critical in ensuring that the model has sufficient context for accurate detection and segmentation. We introduce a powerful ConvNeXt-UNet decoder that closes the performance gap between convolution- and transformerbased models. With ResNet50 backbone, our MaskConver achieves 53.6% PQ on the COCO panoptic val set, outperforming the modern convolution-based model, Panoptic FCN, by 9.3% as well as transformer-based models such as Mask2Former (+1.7% PQ) and kMaX-DeepLab (+0.6% PQ). Additionally, MaskConver with a MobileNet backbone reaches 37.2% PQ, improving over Panoptic-DeepLab by +6.4% under the same FLOPs/latency constraints. A further optimized version of MaskConver achieves 29.7% PQ, while running in real-time on mobile devices. The code and model weights will be publicly available
Development of the Lifelike Head Unit for a Humanoid Cybernetic Avatar `Yui' and Its Operation Interface
Dec 11, 2023In the context of avatar-mediated communication, it is crucial for the face-to-face interlocutor to sense the operator's presence and emotions via the avatar. Although androids resembling humans have been developed to convey presence through appearance and movement, few studies have prioritized deepening the communication experience for both operator and interlocutor using android robot as an avatar. Addressing this gap, we introduce the ``Cybernetic Avatar `Yui','' featuring a human-like head unit with 28 degrees of freedom, capable of expressing gaze, facial emotions, and speech-related mouth movements. Through an eye-tracking unit in a Head-Mounted Display (HMD) and degrees of freedom on both eyes of Yui, operators can control the avatar's gaze naturally. Additionally, microphones embedded in Yui's ears allow operators to hear surrounding sounds in three dimensions, enabling them to discern the direction of calls based solely on auditory information. An HMD's face-tracking unit synchronizes the avatar's facial movements with those of the operator. This immersive interface, coupled with Yui's human-like appearance, enables real-time emotion transmission and communication, enhancing the sense of presence for both parties. Our experiments demonstrate Yui's facial expression capabilities, and validate the system's efficacy through teleoperation trials, suggesting potential advancements in avatar technology.
Orchestrated Robust Controller for the Precision Control of Heavy-duty Hydraulic Manipulators
Dec 11, 2023Vast industrial investment along with increased academic research on hydraulic heavy-duty manipulators has unavoidably paved the way for their automatization, necessitating the design of robust and high-precision controllers. In this study, an orchestrated robust controller is designed to address the mentioned issue. To do so, the entire robotic system is decomposed into subsystems, and a robust controller is designed at each local subsystem by considering unknown model uncertainties, unknown disturbances, and compound input constraints, thanks to virtual decomposition control (VDC). As such, radial basic function neural networks (RBFNNs) are incorporated into VDC to tackle unknown disturbances and uncertainties, resulting in novel decentralized RBFNNs. All these robust local controllers designed at each local subsystem are, then, orchestrated to accomplish high-precision control. In the end, for the first time in the context of VDC, a semi-globally uniformly ultimate boundedness is achieved under the designed controller. The validity of the theoretical results is verified by performing extensive simulations and experiments on a 6-degrees-of-freedom industrial manipulator with a nominal lifting capacity of $600\, kg$ at $5$ meters reach. Comparing the simulation result to state-of-the-art controller along with provided experimental results, demonstrates that the proposed method established all the promises and performed excellently.
PACE: A Program Analysis Framework for Continuous Performance Prediction
Dec 01, 2023Software development teams establish elaborate continuous integration pipelines containing automated test cases to accelerate the development process of software. Automated tests help to verify the correctness of code modifications decreasing the response time to changing requirements. However, when the software teams do not track the performance impact of pending modifications, they may need to spend considerable time refactoring existing code. This paper presents PACE, a program analysis framework that provides continuous feedback on the performance impact of pending code updates. We design performance microbenchmarks by mapping the execution time of functional test cases given a code update. We map microbenchmarks to code stylometry features and feed them to predictors for performance predictions. Our experiments achieved significant performance in predicting code performance, outperforming current state-of-the-art by 75% on neural-represented code stylometry features.
From Correspondences to Pose: Non-minimal Certifiably Optimal Relative Pose without Disambiguation
Dec 10, 2023Estimating the relative camera pose from $n \geq 5$ correspondences between two calibrated views is a fundamental task in computer vision. This process typically involves two stages: 1) estimating the essential matrix between the views, and 2) disambiguating among the four candidate relative poses that satisfy the epipolar geometry. In this paper, we demonstrate a novel approach that, for the first time, bypasses the second stage. Specifically, we show that it is possible to directly estimate the correct relative camera pose from correspondences without needing a post-processing step to enforce the cheirality constraint on the correspondences. Building on recent advances in certifiable non-minimal optimization, we frame the relative pose estimation as a Quadratically Constrained Quadratic Program (QCQP). By applying the appropriate constraints, we ensure the estimation of a camera pose that corresponds to a valid 3D geometry and that is globally optimal when certified. We validate our method through exhaustive synthetic and real-world experiments, confirming the efficacy, efficiency and accuracy of the proposed approach. Code is available at https://github.com/javrtg/C2P.
TaBIIC: Taxonomy Building through Iterative and Interactive Clustering
Dec 10, 2023Building taxonomies is often a significant part of building an ontology, and many attempts have been made to automate the creation of such taxonomies from relevant data. The idea in such approaches is either that relevant definitions of the intension of concepts can be extracted as patterns in the data (e.g. in formal concept analysis) or that their extension can be built from grouping data objects based on similarity (clustering). In both cases, the process leads to an automatically constructed structure, which can either be too coarse and lacking in definition, or too fined-grained and detailed, therefore requiring to be refined into the desired taxonomy. In this paper, we explore a method that takes inspiration from both approaches in an iterative and interactive process, so that refinement and definition of the concepts in the taxonomy occur at the time of identifying those concepts in the data. We show that this method is applicable on a variety of data sources and leads to taxonomies that can be more directly integrated into ontologies.
DCIR: Dynamic Consistency Intrinsic Reward for Multi-Agent Reinforcement Learning
Dec 10, 2023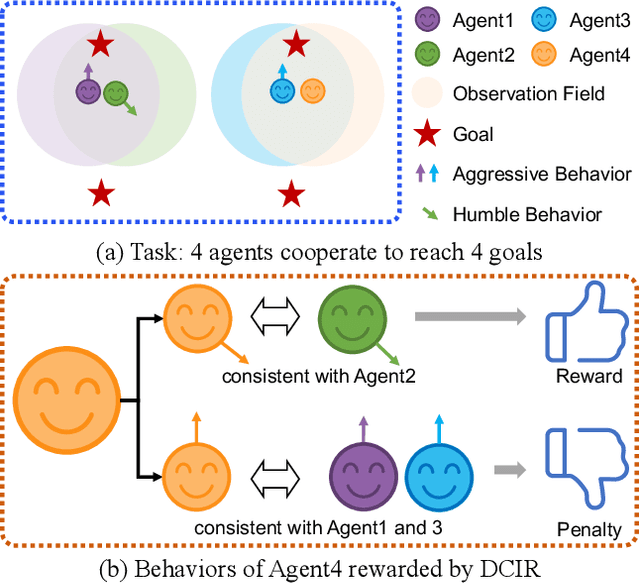
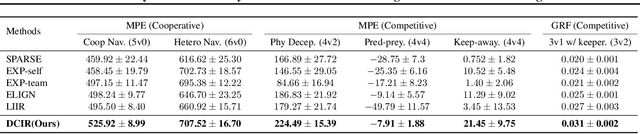
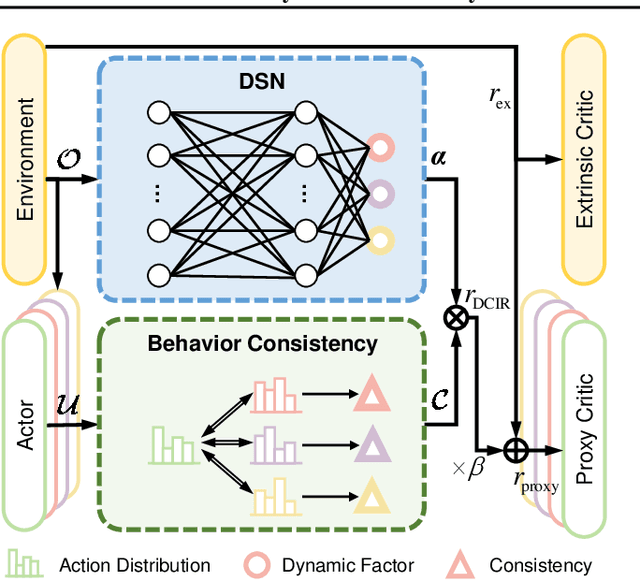
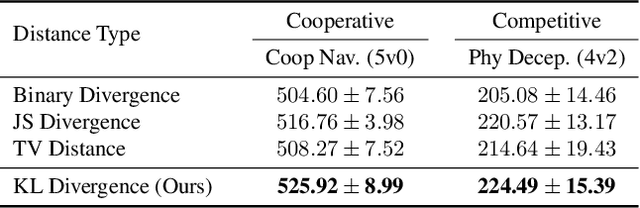
Learning optimal behavior policy for each agent in multi-agent systems is an essential yet difficult problem. Despite fruitful progress in multi-agent reinforcement learning, the challenge of addressing the dynamics of whether two agents should exhibit consistent behaviors is still under-explored. In this paper, we propose a new approach that enables agents to learn whether their behaviors should be consistent with that of other agents by utilizing intrinsic rewards to learn the optimal policy for each agent. We begin by defining behavior consistency as the divergence in output actions between two agents when provided with the same observation. Subsequently, we introduce dynamic consistency intrinsic reward (DCIR) to stimulate agents to be aware of others' behaviors and determine whether to be consistent with them. Lastly, we devise a dynamic scale network (DSN) that provides learnable scale factors for the agent at every time step to dynamically ascertain whether to award consistent behavior and the magnitude of rewards. We evaluate DCIR in multiple environments including Multi-agent Particle, Google Research Football and StarCraft II Micromanagement, demonstrating its efficacy.
Nominality Score Conditioned Time Series Anomaly Detection by Point/Sequential Reconstruction
Oct 24, 2023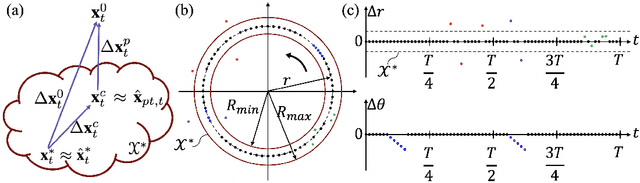
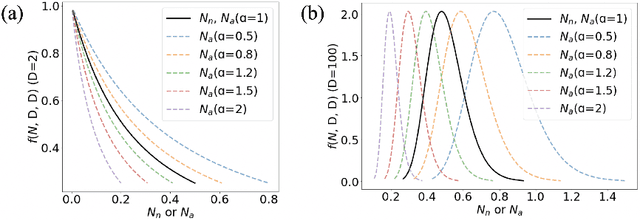
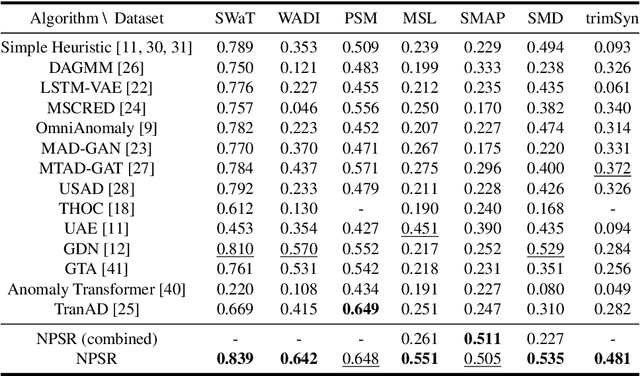
Time series anomaly detection is challenging due to the complexity and variety of patterns that can occur. One major difficulty arises from modeling time-dependent relationships to find contextual anomalies while maintaining detection accuracy for point anomalies. In this paper, we propose a framework for unsupervised time series anomaly detection that utilizes point-based and sequence-based reconstruction models. The point-based model attempts to quantify point anomalies, and the sequence-based model attempts to quantify both point and contextual anomalies. Under the formulation that the observed time point is a two-stage deviated value from a nominal time point, we introduce a nominality score calculated from the ratio of a combined value of the reconstruction errors. We derive an induced anomaly score by further integrating the nominality score and anomaly score, then theoretically prove the superiority of the induced anomaly score over the original anomaly score under certain conditions. Extensive studies conducted on several public datasets show that the proposed framework outperforms most state-of-the-art baselines for time series anomaly detection.
From Big to Small Without Losing It All: Text Augmentation with ChatGPT for Efficient Sentiment Analysis
Dec 07, 2023In the era of artificial intelligence, data is gold but costly to annotate. The paper demonstrates a groundbreaking solution to this dilemma using ChatGPT for text augmentation in sentiment analysis. We leverage ChatGPT's generative capabilities to create synthetic training data that significantly improves the performance of smaller models, making them competitive with, or even outperforming, their larger counterparts. This innovation enables models to be both efficient and effective, thereby reducing computational cost, inference time, and memory usage without compromising on quality. Our work marks a key advancement in the cost-effective development and deployment of robust sentiment analysis models.