 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Network Packet Generation through Statistical Learning and Genetic Algorithms
Jun 18, 2026Developing robust intrusion detection systems (IDS) for IoT environments requires large, labeled datasets capturing realistic traffic distributions across both benign and malicious activity. Existing public datasets suffer from fixed activity distributions and extreme class imbalance, while deep generative models (GANs, VAEs) provide no mechanism to enforce that synthetic packets remain within physically valid feature ranges. This paper proposes and compares two constraint-enforcing approaches for synthetic IoT network packet generation: (i) a statistical learning method combining PCA-based latent space sampling with dual One-Class SVM (OCSVM) and Isolation Forest (IF) boundary enforcement, and (ii) a genetic algorithm (GA) method that treats packet generation as a multi-objective optimization problem with explicit fitness criteria for anomaly model acceptance and distributional fidelity. Both methods embed hard validity constraints -- dual anomaly-detection gating, feature-range clamping, and independent validation -- directly into the synthesis pipeline. Evaluation on the complete ACI IoT 2023 dataset (1,231,411 packets, 12 attack categories, class imbalance up to 175,805:1) demonstrates that both methods achieve PASS status across all categories under independently trained validators with a 30% anomaly rate threshold: the statistical method attains 1.20% average anomaly rate with ~1,091 packets/s throughput, while the GA attains 0.62% average anomaly rate with organic per-class variance (0.00%-2.50%) at ~5.7 packets/s. Both methods successfully amplify the 5-sample ARP Spoofing category by 200x to 1,000 validated packets. The ~190:1 throughput ratio between methods, combined with their complementary quality profiles, provides evidence-based selection criteria for deployment contexts ranging from rapid dataset augmentation to adversarial robustness testing.
Categorical Robustness Assessment for Machine Learning based Network Intrusion Detection Systems
Jun 10, 2026Network Intrusion Detection Systems (NIDS) heavily utlize Machine Learning (ML) but ML models can be manipulated via adversarial attacks. These attacks add carefully crafted perturbations to network traffic data that leads to misclassifications. While prior work has demonstrated adversarial vulnerabilities in isolated settings, systematic cross-architecture as well as class and category of attack based comparisons under controlled attack conditions remain limited, leaving practitioners without clear guidance on which models to deploy in adversarial environments. This paper asks a simple question: what type of classifier architectures actually hold up when attackers try to manipulate the systems? We put three popular architectures through their paces: a 1D Convolutional Neural Network, a Long Short-Term Memory (LSTM) network, and a Random Forest (RF) ensemble. Using the ACI-IoT-2023 dataset (over 1.2 million samples spanning 12 attack types), we subject each model with FGSM and PGD adversarial attacks, which apply gradient-based perturbations in normalized feature space consistent with established adversarial ML evaluation protocols, at perturbation budgets ranging from $ε=0.01$ to $ε=0.1$. Surprisingly, Random Forest achieved near-perfect baseline accuracy (99.98\%), yet collapsed catastrophically under attack, dropping 73 percentage points at the smallest perturbation we tested. CNN, on the other hand, retained 95.5\% accuracy at $ε=0.01$ and degraded gracefully as perturbations increased. LSTM fell somewhere in between. These findings flip the conventional wisdom where high baseline accuracy means nothing if a model shatters at the first sign of adversarial pressure. For practitioners deploying intrusion detection in adversarial environments, we recommend CNN-based architectures and provide scenario-specific deployment guidance.
Adaptive Pruning of Deep Neural Networks for Resource-Aware Embedded Intrusion Detection on the Edge
May 20, 2025Artificial neural network pruning is a method in which artificial neural network sizes can be reduced while attempting to preserve the predicting capabilities of the network. This is done to make the model smaller or faster during inference time. In this work we analyze the ability of a selection of artificial neural network pruning methods to generalize to a new cybersecurity dataset utilizing a simpler network type than was designed for. We analyze each method using a variety of pruning degrees to best understand how each algorithm responds to the new environment. This has allowed us to determine the most well fit pruning method of those we searched for the task. Unexpectedly, we have found that many of them do not generalize to the problem well, leaving only a few algorithms working to an acceptable degree.
PACE: A Program Analysis Framework for Continuous Performance Prediction
Dec 01, 2023Software development teams establish elaborate continuous integration pipelines containing automated test cases to accelerate the development process of software. Automated tests help to verify the correctness of code modifications decreasing the response time to changing requirements. However, when the software teams do not track the performance impact of pending modifications, they may need to spend considerable time refactoring existing code. This paper presents PACE, a program analysis framework that provides continuous feedback on the performance impact of pending code updates. We design performance microbenchmarks by mapping the execution time of functional test cases given a code update. We map microbenchmarks to code stylometry features and feed them to predictors for performance predictions. Our experiments achieved significant performance in predicting code performance, outperforming current state-of-the-art by 75% on neural-represented code stylometry features.
Automated User Experience Testing through Multi-Dimensional Performance Impact Analysis
Apr 08, 2021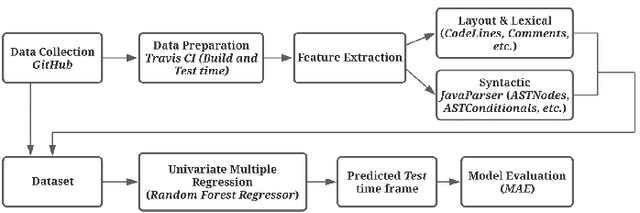
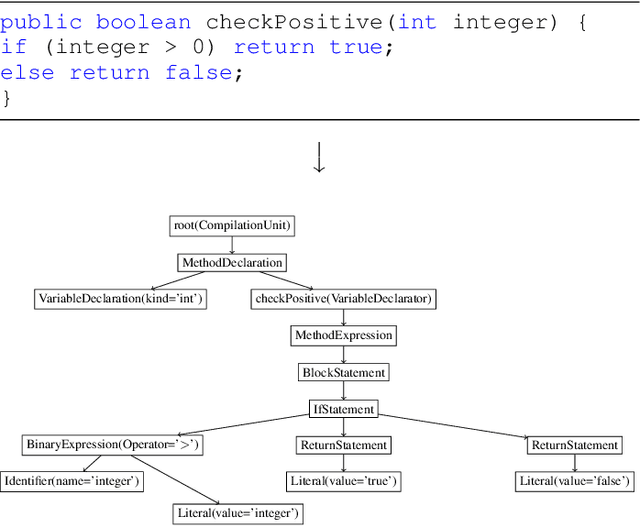
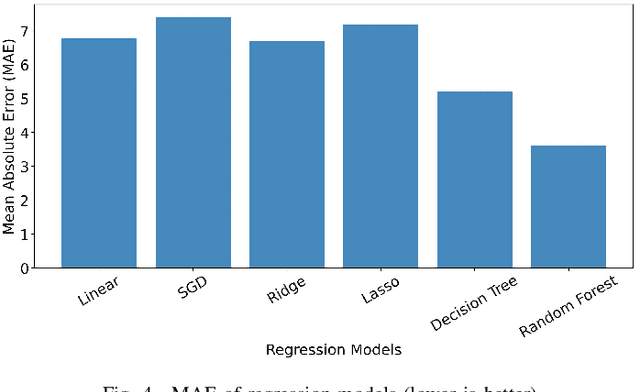
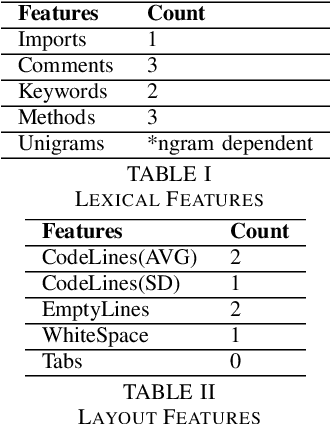
Although there are many automated software testing suites, they usually focus on unit, system, and interface testing. However, especially software updates such as new security features have the potential to diminish user experience. In this paper, we propose a novel automated user experience testing methodology that learns how code changes impact the time unit and system tests take, and extrapolate user experience changes based on this information. Such a tool can be integrated into existing continuous integration pipelines, and it provides software teams immediate user experience feedback. We construct a feature set from lexical, layout, and syntactic characteristics of the code, and using Abstract Syntax Tree-Based Embeddings, we can calculate the approximate semantic distance to feed into a machine learning algorithm. In our experiments, we use several regression methods to estimate the time impact of software updates. Our open-source tool achieved 3.7% mean absolute error rate with a random forest regressor.