 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
HMCNAS: Neural Architecture Search using Hidden Markov Chains and Bayesian Optimization
Jul 31, 2020
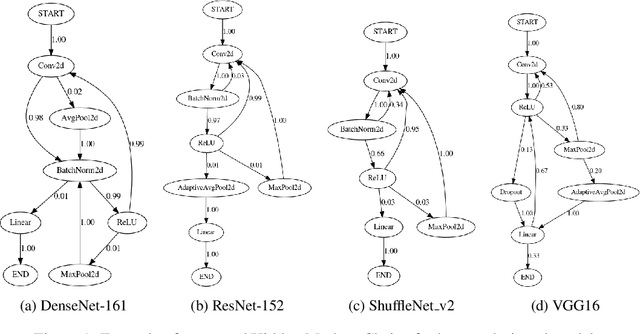
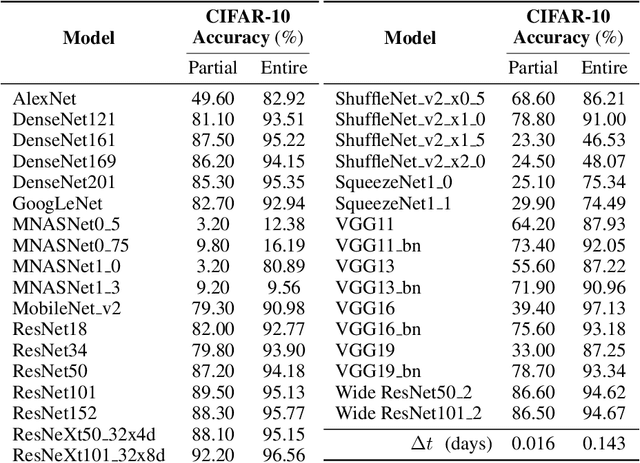
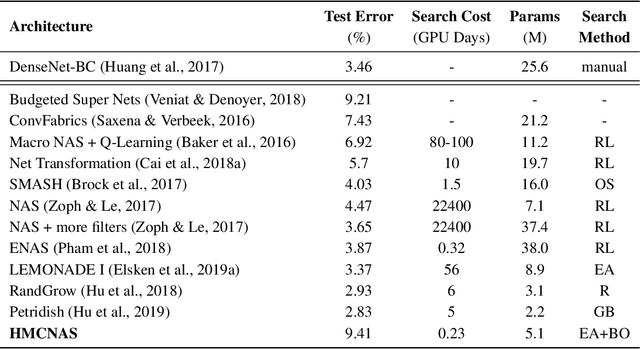
Neural Architecture Search has achieved state-of-the-art performance in a variety of tasks, out-performing human-designed networks. However, many assumptions, that require human definition, related with the problems being solved or the models generated are still needed: final model architectures, number of layers to be sampled, forced operations, small search spaces, which ultimately contributes to having models with higher performances at the cost of inducing bias into the system. In this paper, we propose HMCNAS, which is composed of two novel components: i) a method that leverages information about human-designed models to autonomously generate a complex search space, and ii) an Evolutionary Algorithm with Bayesian Optimization that is capable of generating competitive CNNs from scratch, without relying on human-defined parameters or small search spaces. The experimental results show that the proposed approach results in competitive architectures obtained in a very short time. HMCNAS provides a step towards generalizing NAS, by providing a way to create competitive models, without requiring any human knowledge about the specific task.
Spectrum and Prosody Conversion for Cross-lingual Voice Conversion with CycleGAN
Aug 12, 2020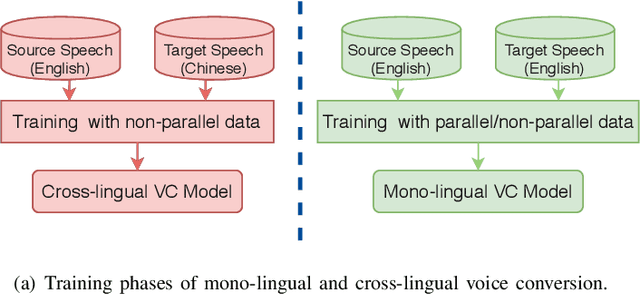
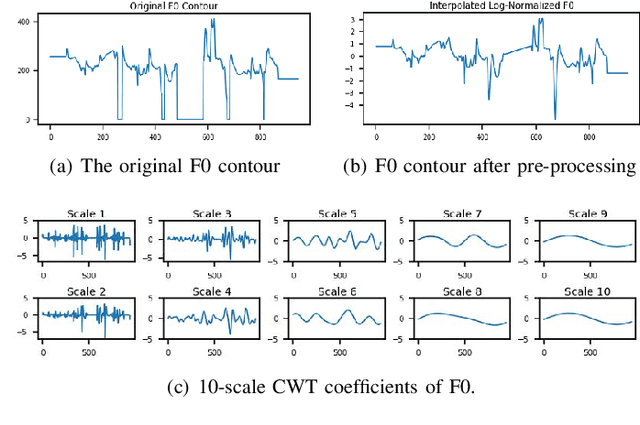
Cross-lingual voice conversion aims to change source speaker's voice to sound like that of target speaker, when source and target speakers speak different languages. It relies on non-parallel training data from two different languages, hence, is more challenging than mono-lingual voice conversion. Previous studies on cross-lingual voice conversion mainly focus on spectral conversion with a linear transformation for F0 transfer. However, as an important prosodic factor, F0 is inherently hierarchical, thus it is insufficient to just use a linear method for conversion. We propose the use of continuous wavelet transform (CWT) decomposition for F0 modeling. CWT provides a way to decompose a signal into different temporal scales that explain prosody in different time resolutions. We also propose to train two CycleGAN pipelines for spectrum and prosody mapping respectively. In this way, we eliminate the need for parallel data of any two languages and any alignment techniques. Experimental results show that our proposed Spectrum-Prosody-CycleGAN framework outperforms the Spectrum-CycleGAN baseline in subjective evaluation. To our best knowledge, this is the first study of prosody in cross-lingual voice conversion.
$α$ Belief Propagation for Approximate Inference
Jun 27, 2020



Belief propagation (BP) algorithm is a widely used message-passing method for inference in graphical models. BP on loop-free graphs converges in linear time. But for graphs with loops, BP's performance is uncertain, and the understanding of its solution is limited. To gain a better understanding of BP in general graphs, we derive an interpretable belief propagation algorithm that is motivated by minimization of a localized $\alpha$-divergence. We term this algorithm as $\alpha$ belief propagation ($\alpha$-BP). It turns out that $\alpha$-BP generalizes standard BP. In addition, this work studies the convergence properties of $\alpha$-BP. We prove and offer the convergence conditions for $\alpha$-BP. Experimental simulations on random graphs validate our theoretical results. The application of $\alpha$-BP to practical problems is also demonstrated.
FastORB-SLAM: a Fast ORB-SLAM Method with Coarse-to-Fine Descriptor Independent Keypoint Matching
Aug 22, 2020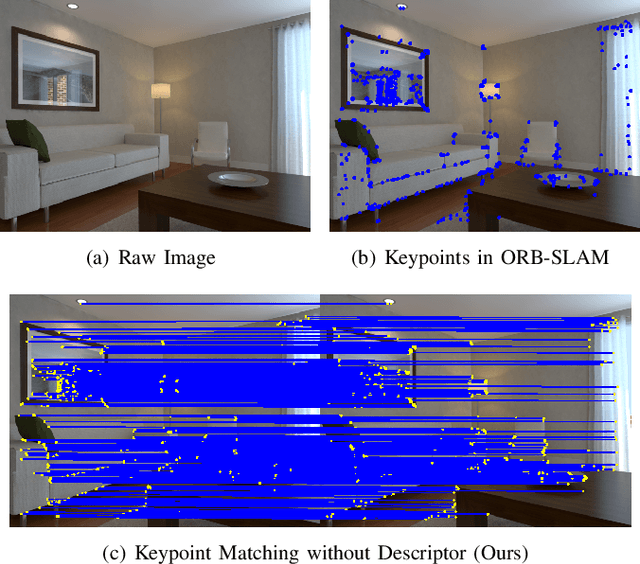
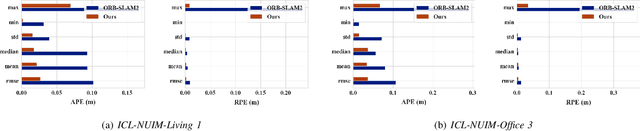
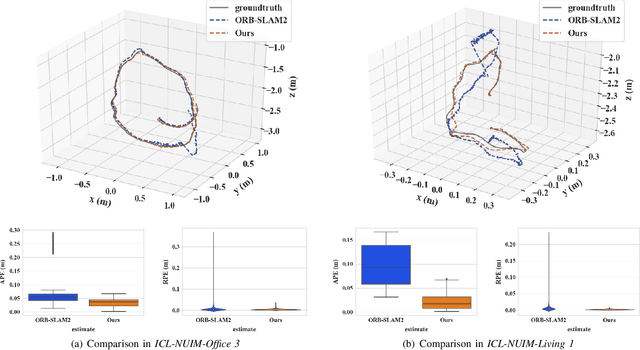
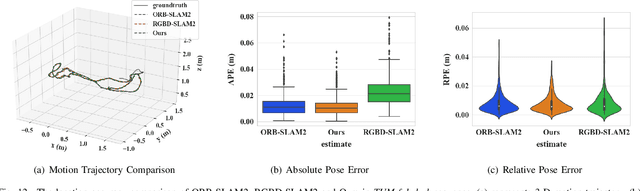
Indirect methods for visual SLAM are gaining popularity due to their robustness to varying environments. ORB-SLAM2 is a benchmark method in this domain, however, the computation of descriptors in ORB-SLAM2 is time-consuming and the descriptors cannot be reused unless a frame is selected as a keyframe. To overcome these problems, we present FastORB-SLAM which is light-weight and efficient as it tracks keypoints between adjacent frames without computing descriptors. To achieve this, a two-stage coarse-to-fine descriptor independent keypoint matching method is proposed based on sparse optical flow. In the first stage, we first predict initial keypoint correspondences via a uniform acceleration motion model and then robustly establish the correspondences via a pyramid-based sparse optical flow tracking method. In the second stage, we leverage motion smoothness and the epipolar constraint to refine the correspondences. In particular, our method computes descriptors only for keyframes. We test FastORB-SLAM with an RGBD camera on \textit{TUM} and \textit{ICL-NUIM} datasets and compare its accuracy and efficiency to nine existing RGBD SLAM methods. Qualitative and quantitative results show that our method achieves state-of-the-art performance in accuracy and is about twice as fast as the ORB-SLAM2
PIDNet: An Efficient Network for Dynamic Pedestrian Intrusion Detection
Sep 01, 2020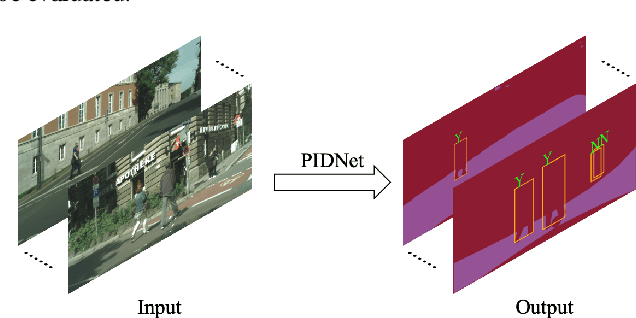
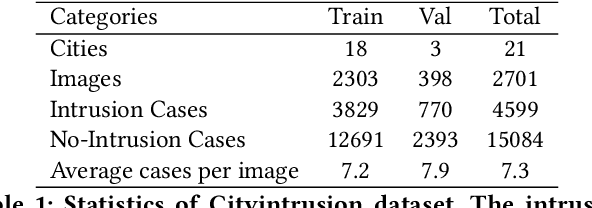
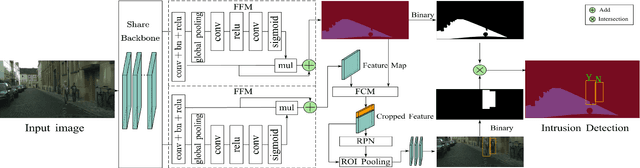
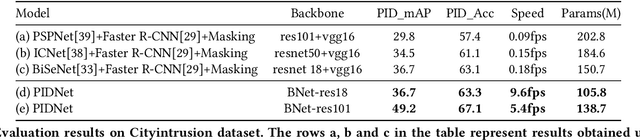
Vision-based dynamic pedestrian intrusion detection (PID), judging whether pedestrians intrude an area-of-interest (AoI) by a moving camera, is an important task in mobile surveillance. The dynamically changing AoIs and a number of pedestrians in video frames increase the difficulty and computational complexity of determining whether pedestrians intrude the AoI, which makes previous algorithms incapable of this task. In this paper, we propose a novel and efficient multi-task deep neural network, PIDNet, to solve this problem. PIDNet is mainly designed by considering two factors: accurately segmenting the dynamically changing AoIs from a video frame captured by the moving camera and quickly detecting pedestrians from the generated AoI-contained areas. Three efficient network designs are proposed and incorporated into PIDNet to reduce the computational complexity: 1) a special PID task backbone for feature sharing, 2) a feature cropping module for feature cropping, and 3) a lighter detection branch network for feature compression. In addition, considering there are no public datasets and benchmarks in this field, we establish a benchmark dataset to evaluate the proposed network and give the corresponding evaluation metrics for the first time. Experimental results show that PIDNet can achieve 67.1% PID accuracy and 9.6 fps inference speed on the proposed dataset, which serves as a good baseline for the future vision-based dynamic PID study.
On the Evolution of Programming Languages
Jun 27, 2020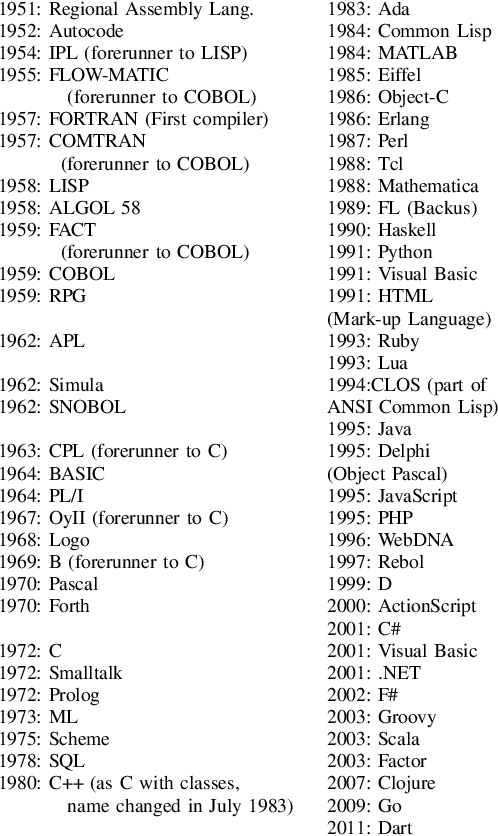

This paper attempts to connects the evolution of computer languages with the evolution of life, where the later has been dictated by \emph{theory of evolution of species}, and tries to give supportive evidence that the new languages are more robust than the previous, carry-over the mixed features of older languages, such that strong features gets added into them and weak features of older languages gets removed. In addition, an analysis of most prominent programming languages is presented, emphasizing on how the features of existing languages have influenced the development of new programming languages. At the end, it suggests a set of experimental languages, which may rule the world of programming languages in the time of new multi-core architectures. Index terms- Programming languages' evolution, classifications of languages, future languages, scripting-languages.
Solving Online Threat Screening Games using Constrained Action Space Reinforcement Learning
Nov 20, 2019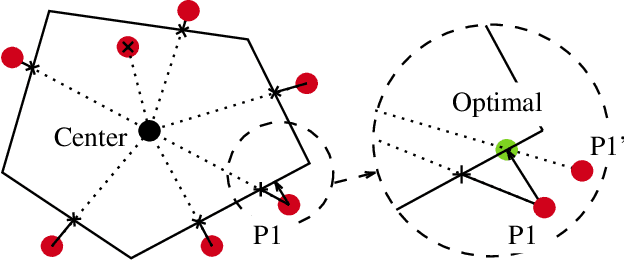
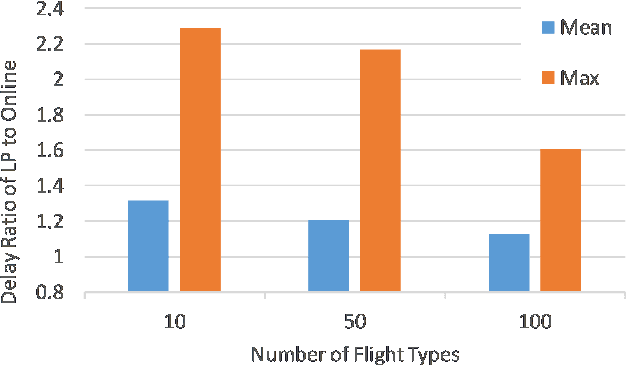
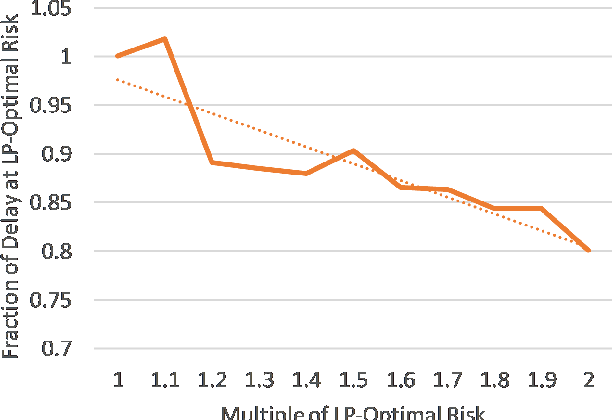
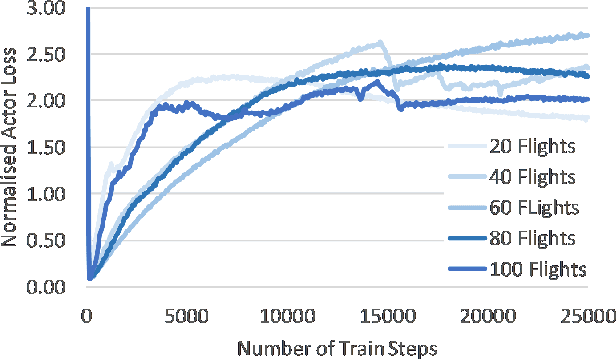
Large-scale screening for potential threats with limited resources and capacity for screening is a problem of interest at airports, seaports, and other ports of entry. Adversaries can observe screening procedures and arrive at a time when there will be gaps in screening due to limited resource capacities. To capture this game between ports and adversaries, this problem has been previously represented as a Stackelberg game, referred to as a Threat Screening Game (TSG). Given the significant complexity associated with solving TSGs and uncertainty in arrivals of customers, existing work has assumed that screenees arrive and are allocated security resources at the beginning of the time window. In practice, screenees such as airport passengers arrive in bursts correlated with flight time and are not bound by fixed time windows. To address this, we propose an online threat screening model in which screening strategy is determined adaptively as a passenger arrives while satisfying a hard bound on acceptable risk of not screening a threat. To solve the online problem with a hard bound on risk, we formulate it as a Reinforcement Learning (RL) problem with constraints on the action space (hard bound on risk). We provide a novel way to efficiently enforce linear inequality constraints on the action output in Deep Reinforcement Learning. We show that our solution allows us to significantly reduce screenee wait time while guaranteeing a bound on risk.
Emora STDM: A Versatile Framework for Innovative Dialogue System Development
Jun 11, 2020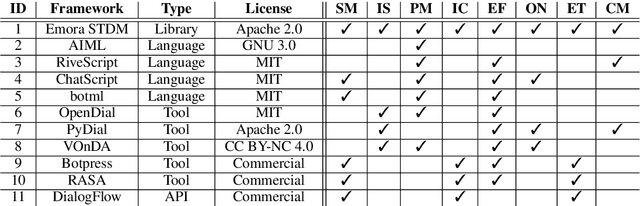
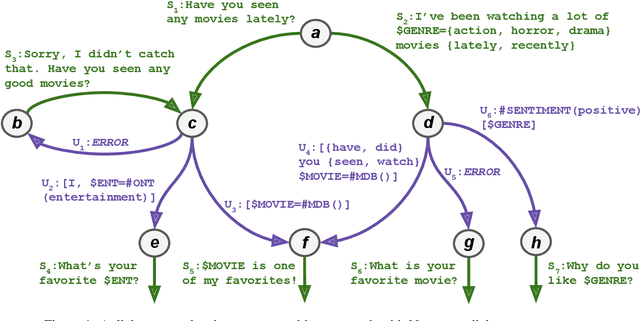
This demo paper presents Emora STDM (State Transition Dialogue Manager), a dialogue system development framework that provides novel workflows for rapid prototyping of chat-based dialogue managers as well as collaborative development of complex interactions. Our framework caters to a wide range of expertise levels by supporting interoperability between two popular approaches, state machine and information state, to dialogue management. Our Natural Language Expression package allows seamless integration of pattern matching, custom NLP modules, and database querying, that makes the workflows much more efficient. As a user study, we adopt this framework to an interdisciplinary undergraduate course where students with both technical and non-technical backgrounds are able to develop creative dialogue managers in a short period of time.
COVID-19 Pandemic Cyclic Lockdown Optimization Using Reinforcement Learning
Sep 10, 2020

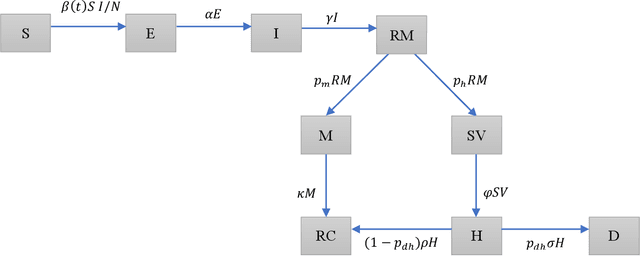
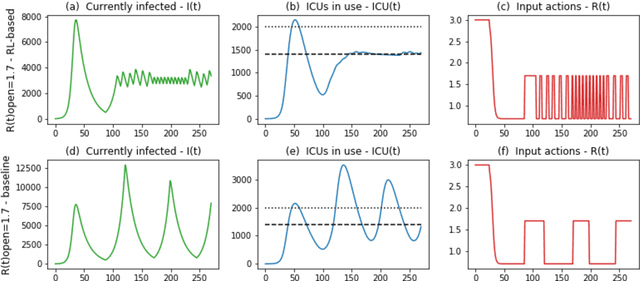
This work examines the use of reinforcement learning (RL) to optimize cyclic lockdowns, which is one of the methods available for control of the COVID-19 pandemic. The problem is structured as an optimal control system for tracking a reference value, corresponding to the maximum usage level of a critical resource, such as ICU beds. However, instead of using conventional optimal control methods, RL is used to find optimal control policies. A framework was developed to calculate optimal cyclic lockdown timings using an RL-based on-off controller. The RL-based controller is implemented as an RL agent that interacts with an epidemic simulator, implemented as an extended SEIR epidemic model. The RL agent learns a policy function that produces an optimal sequence of open/lockdown decisions such that goals specified in the RL reward function are optimized. Two concurrent goals were used: the first one is a public health goal that minimizes overshoots of ICU bed usage above an ICU bed threshold, and the second one is a socio-economic goal that minimizes the time spent under lockdowns. It is assumed that cyclic lockdowns are considered as a temporary alternative to extended lockdowns when a region faces imminent danger of overpassing resource capacity limits and when imposing an extended lockdown would cause severe social and economic consequences due to lack of necessary economic resources to support its affected population during an extended lockdown.
Tightening Exploration in Upper Confidence Reinforcement Learning
Apr 20, 2020
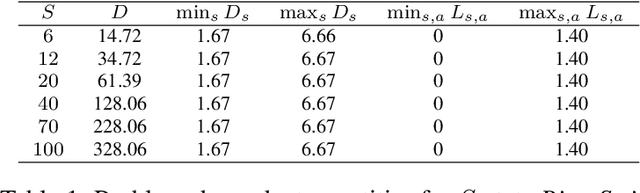
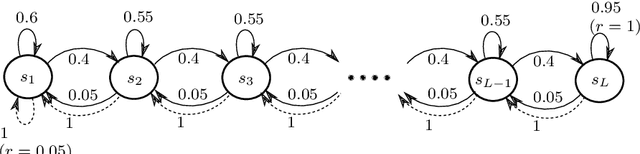

The upper confidence reinforcement learning (UCRL2) strategy introduced in (Jaksch et al., 2010) is a popular method to perform regret minimization in unknown discrete Markov Decision Processes under the average-reward criterion. Despite its nice and generic theoretical regret guarantees, this strategy and its variants have remained until now mostly theoretical as numerical experiments on simple environments exhibit long burn-in phases before the learning takes place. Motivated by practical efficiency, we present UCRL3, following the lines of UCRL2, but with two key modifications: First, it uses state-of-the-art time-uniform concentration inequalities, to compute confidence sets on the reward and transition distributions for each state-action pair. To further tighten exploration, we introduce an adaptive computation of the support of each transition distributions. This enables to revisit the extended value iteration procedure to optimize over distributions with reduced support by disregarding low probability transitions, while still ensuring near-optimism. We demonstrate, through numerical experiments on standard environments, that reducing exploration this way yields a substantial numerical improvement compared to UCRL2 and its variants. On the theoretical side, these key modifications enable to derive a regret bound for UCRL3 improving on UCRL2, that for the first time makes appear a notion of local diameter and effective support, thanks to variance-aware concentration bounds.