 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transfer Learning for Protein Structure Classification at Low Resolution
Aug 16, 2020
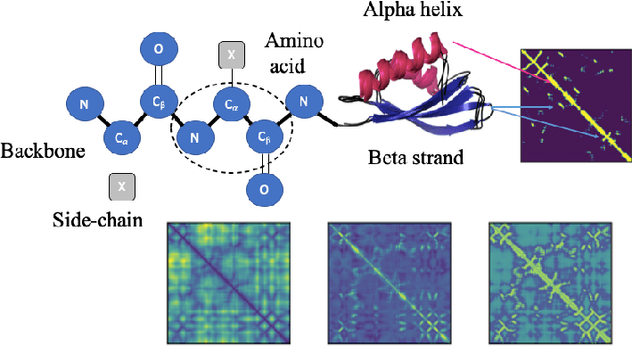
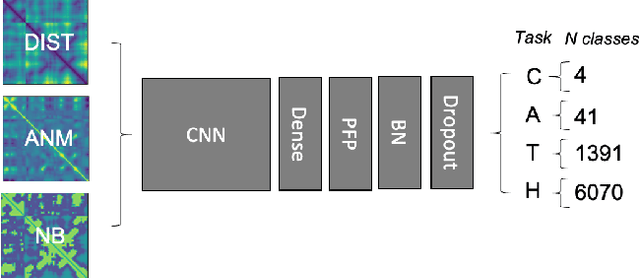
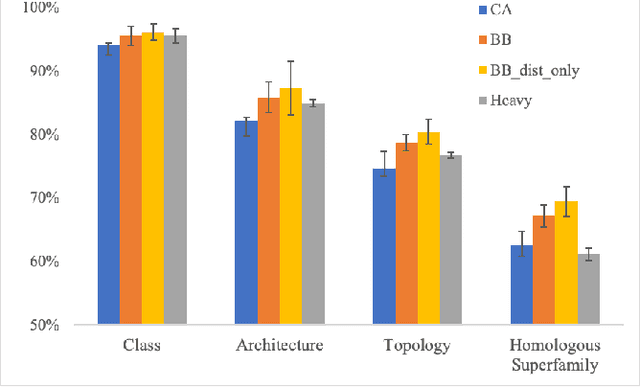

Structure determination is key to understanding protein function at a molecular level. Whilst significant advances have been made in predicting structure and function from amino acid sequence, researchers must still rely on expensive, time-consuming analytical methods to visualise detailed protein conformation. In this study, we demonstrate that it is possible to make accurate ($\geq$80%) predictions of protein class and architecture from structures determined at low ($>$3A) resolution, using a deep convolutional neural network trained on high-resolution ($\leq$3A) structures represented as 2D matrices. Thus, we provide proof of concept for high-speed, low-cost protein structure classification at low resolution, and a basis for extension to prediction of function. We investigate the impact of the input representation on classification performance, showing that side-chain information may not be necessary for fine-grained structure predictions. Finally, we confirm that high-resolution, low-resolution and NMR-determined structures inhabit a common feature space, and thus provide a theoretical foundation for boosting with single-image super-resolution.
MedDG: A Large-scale Medical Consultation Dataset for Building Medical Dialogue System
Oct 15, 2020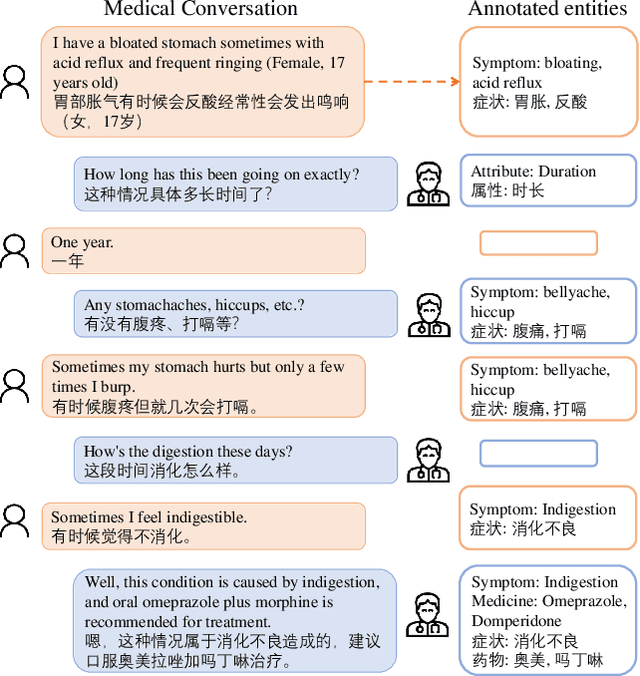

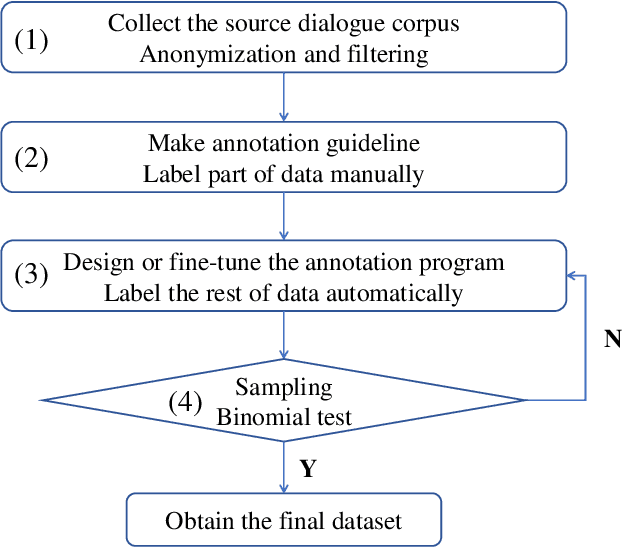
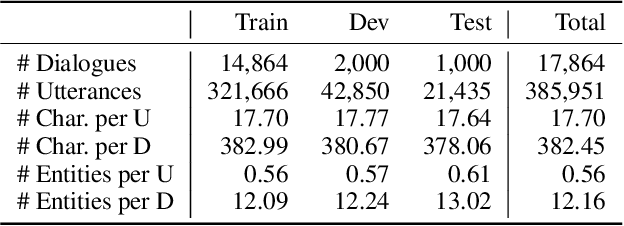
Developing conversational agents to interact with patients and provide primary clinical advice has attracted increasing attention due to its huge application potential, especially in the time of COVID-19 Pandemic. However, the training of end-to-end neural-based medical dialogue system is restricted by an insufficient quantity of medical dialogue corpus. In this work, we make the first attempt to build and release a large-scale high-quality Medical Dialogue dataset related to 12 types of common Gastrointestinal diseases named MedDG, with more than 17K conversations collected from the online health consultation community. Five different categories of entities, including diseases, symptoms, attributes, tests, and medicines, are annotated in each conversation of MedDG as additional labels. To push forward the future research on building expert-sensitive medical dialogue system, we proposes two kinds of medical dialogue tasks based on MedDG dataset. One is the next entity prediction and the other is the doctor response generation. To acquire a clear comprehension on these two medical dialogue tasks, we implement several state-of-the-art benchmarks, as well as design two dialogue models with a further consideration on the predicted entities. Experimental results show that the pre-train language models and other baselines struggle on both tasks with poor performance in our dataset, and the response quality can be enhanced with the help of auxiliary entity information. From human evaluation, the simple retrieval model outperforms several state-of-the-art generative models, indicating that there still remains a large room for improvement on generating medically meaningful responses.
A General Framework for Density Based Time Series Clustering Exploiting a Novel Admissible Pruning Strategy
Dec 02, 2016
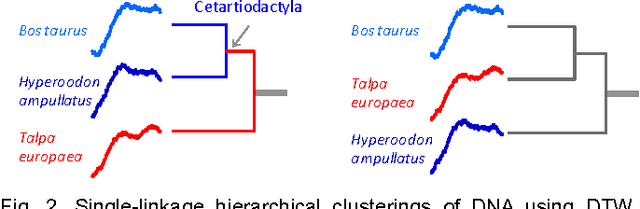
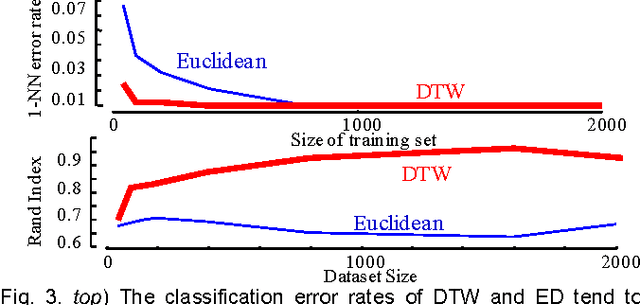

Time Series Clustering is an important subroutine in many higher-level data mining analyses, including data editing for classifiers, summarization, and outlier detection. It is well known that for similarity search the superiority of Dynamic Time Warping (DTW) over Euclidean distance gradually diminishes as we consider ever larger datasets. However, as we shall show, the same is not true for clustering. Clustering time series under DTW remains a computationally expensive operation. In this work, we address this issue in two ways. We propose a novel pruning strategy that exploits both the upper and lower bounds to prune off a very large fraction of the expensive distance calculations. This pruning strategy is admissible and gives us provably identical results to the brute force algorithm, but is at least an order of magnitude faster. For datasets where even this level of speedup is inadequate, we show that we can use a simple heuristic to order the unavoidable calculations in a most-useful-first ordering, thus casting the clustering into an anytime framework. We demonstrate the utility of our ideas with both single and multidimensional case studies in the domains of astronomy, speech physiology, medicine and entomology. In addition, we show the generality of our clustering framework to other domains by efficiently obtaining semantically significant clusters in protein sequences using the Edit Distance, the discrete data analogue of DTW.
Co-Evolution of Multi-Robot Controllers and Task Cues for Off-World Open Pit Mining
Sep 19, 2020

Robots are ideal for open-pit mining on the Moon as its a dull, dirty, and dangerous task. The challenge is to scale up productivity with an ever-increasing number of robots. This paper presents a novel method for developing scalable controllers for use in multi-robot excavation and site-preparation scenarios. The controller starts with a blank slate and does not require human-authored operations scripts nor detailed modeling of the kinematics and dynamics of the excavator. The 'Artificial Neural Tissue' (ANT) architecture is used as a control system for autonomous robot teams to perform resource gathering. This control architecture combines a variable-topology neural-network structure with a coarse-coding strategy that permits specialized areas to develop in the tissue. Our work in this field shows that fleets of autonomous decentralized robots have an optimal operating density. Too few robots result in insufficient labor, while too many robots cause antagonism, where the robots undo each other's work and are stuck in gridlock. In this paper, we explore the use of templates and task cues to improve group performance further and minimize antagonism. Our results show light beacons and task cues are effective in sparking new and innovative solutions at improving robot performance when placed under stressful situations such as severe time-constraint.
Benchmarking Robustness of Machine Reading Comprehension Models
Apr 29, 2020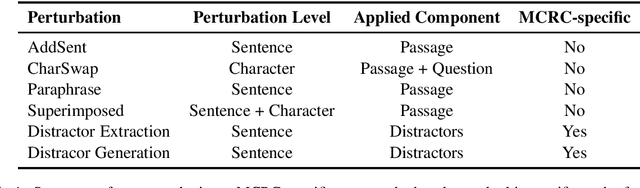
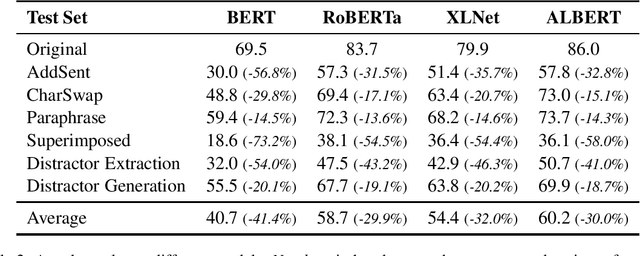
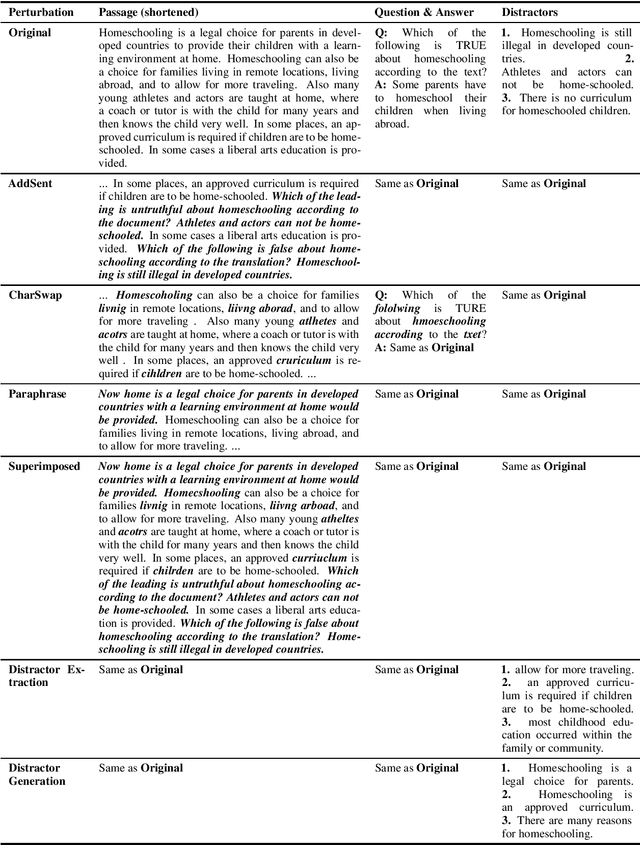
Machine Reading Comprehension (MRC) is an important testbed for evaluating models' natural language understanding (NLU) ability. There has been rapid progress in this area, with new models achieving impressive performance on various MRC benchmarks. However, most of these benchmarks only evaluate models on in-domain test sets without considering their robustness under test-time perturbations. To fill this important gap, we construct AdvRACE (Adversarial RACE), a new model-agnostic benchmark for evaluating the robustness of MRC models under six different types of test-time perturbations, including our novel superimposed attack and distractor construction attack. We show that current state-of-the-art (SOTA) models are vulnerable to these simple black-box attacks. Our benchmark is constructed automatically based on the existing RACE benchmark, and thus the construction pipeline can be easily adopted by other tasks and datasets. We will release the data and source codes to facilitate future work. We hope that our work will encourage more research on improving the robustness of MRC and other NLU models.
Comparison of ARIMA, ETS, NNAR and hybrid models to forecast the second wave of COVID-19 hospitalizations in Italy
Oct 22, 2020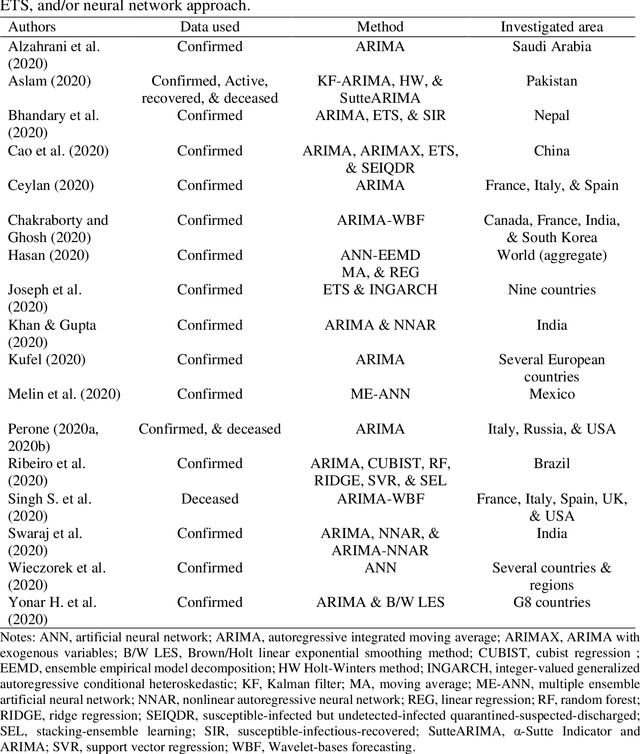
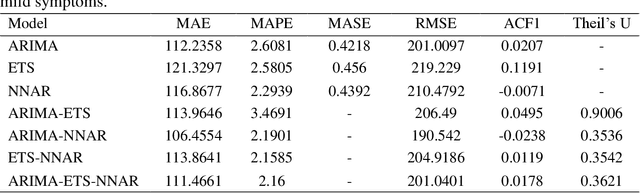
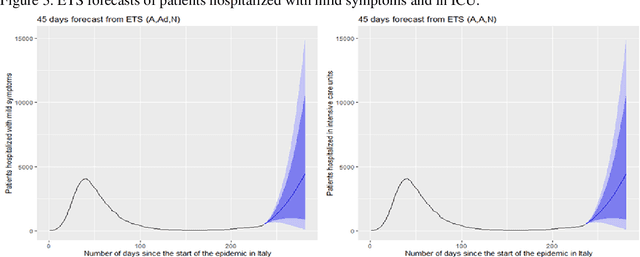
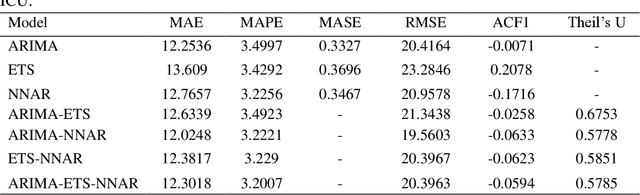
Coronavirus disease (COVID-19) is a severe ongoing novel pandemic that has emerged in Wuhan, China, in December 2019. As of October 13, the outbreak has spread rapidly across the world, affecting over 38 million people, and causing over 1 million deaths. In this article, I analysed several time series forecasting methods to predict the spread of COVID-19 second wave in Italy, over the period after October 13, 2020. I used an autoregressive model (ARIMA), an exponential smoothing state space model (ETS), a neural network autoregression model (NNAR), and the following hybrid combinations of them: ARIMA-ETS, ARIMA-NNAR, ETS-NNAR, and ARIMA-ETS-NNAR. About the data, I forecasted the number of patients hospitalized with mild symptoms, and in intensive care units (ICU). The data refer to the period February 21, 2020-October 13, 2020 and are extracted from the website of the Italian Ministry of Health (www.salute.gov.it). The results show that i) the hybrid models, except for ARIMA-ETS, are better at capturing the linear and non-linear epidemic patterns, by outperforming the respective single models; and ii) the number of COVID-19-related hospitalized with mild symptoms and in ICU will rapidly increase in the next weeks, by reaching the peak in about 50-60 days, i.e. in mid-December 2020, at least. To tackle the upcoming COVID-19 second wave, on one hand, it is necessary to hire healthcare workers and implement sufficient hospital facilities, protective equipment, and ordinary and intensive care beds; and on the other hand, it may be useful to enhance social distancing by improving public transport and adopting the double-shifts schooling system, for example.
Hypersolvers: Toward Fast Continuous-Depth Models
Jul 19, 2020
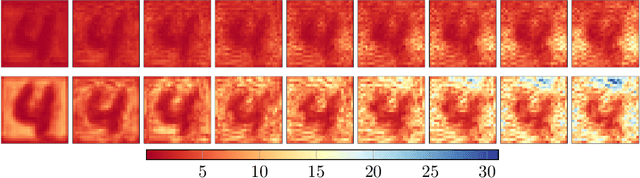
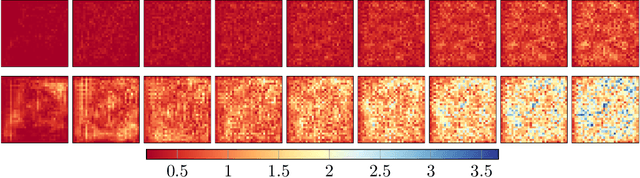
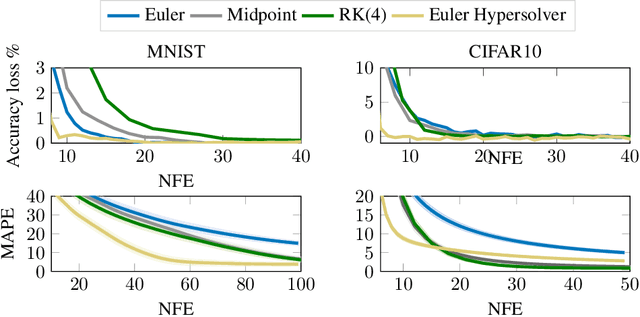
The infinite-depth paradigm pioneered by Neural ODEs has launched a renaissance in the search for novel dynamical system-inspired deep learning primitives; however, their utilization in problems of non-trivial size has often proved impossible due to poor computational scalability. This work paves the way for scalable Neural ODEs with time-to-prediction comparable to traditional discrete networks. We introduce hypersolvers, neural networks designed to solve ODEs with low overhead and theoretical guarantees on accuracy. The synergistic combination of hypersolvers and Neural ODEs allows for cheap inference and unlocks a new frontier for practical application of continuous-depth models. Experimental evaluations on standard benchmarks, such as sampling for continuous normalizing flows, reveal consistent pareto efficiency over classical numerical methods.
A Real-time Hand Gesture Recognition and Human-Computer Interaction System
Apr 24, 2017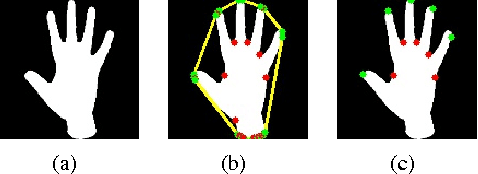
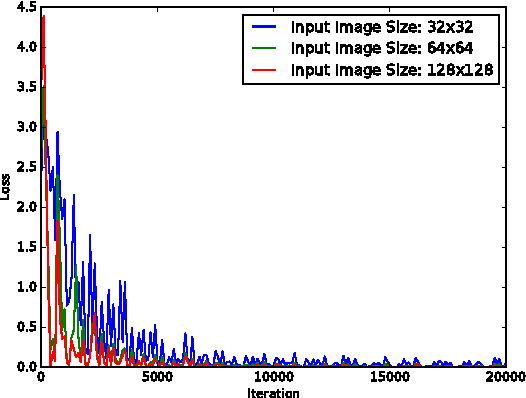
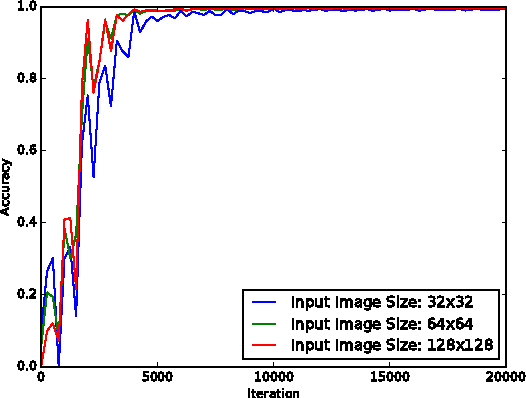
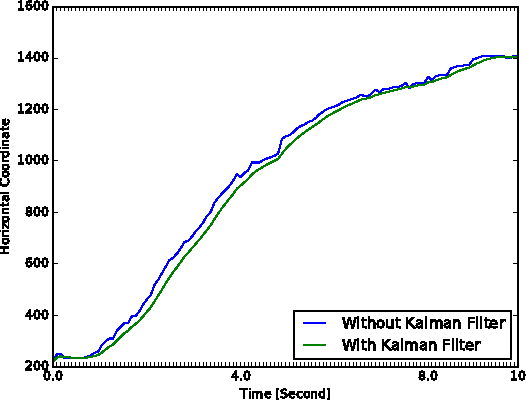
In this project, we design a real-time human-computer interaction system based on hand gesture. The whole system consists of three components: hand detection, gesture recognition and human-computer interaction (HCI) based on recognition; and realizes the robust control of mouse and keyboard events with a higher accuracy of gesture recognition. Specifically, we use the convolutional neural network (CNN) to recognize gestures and makes it attainable to identify relatively complex gestures using only one cheap monocular camera. We introduce the Kalman filter to estimate the hand position based on which the mouse cursor control is realized in a stable and smooth way. During the HCI stage, we develop a simple strategy to avoid the false recognition caused by noises - mostly transient, false gestures, and thus to improve the reliability of interaction. The developed system is highly extendable and can be used in human-robotic or other human-machine interaction scenarios with more complex command formats rather than just mouse and keyboard events.
Learning Dual Semantic Relations with Graph Attention for Image-Text Matching
Oct 22, 2020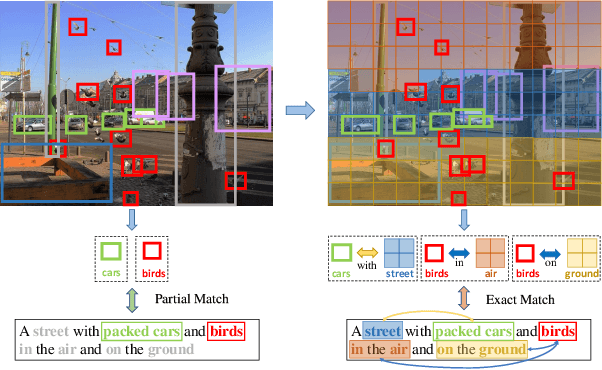
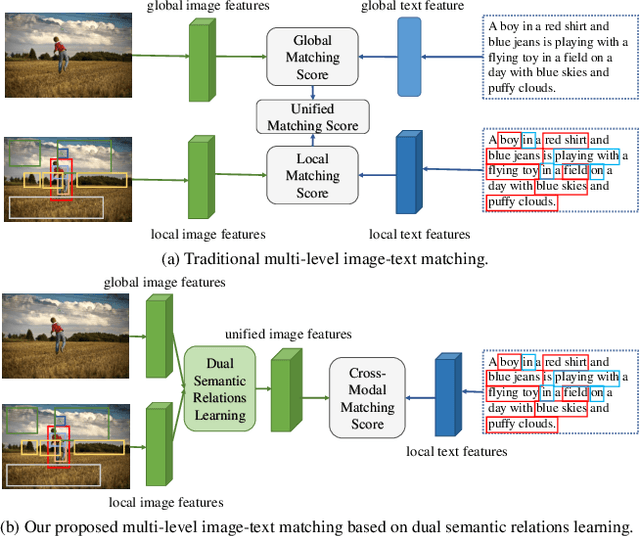
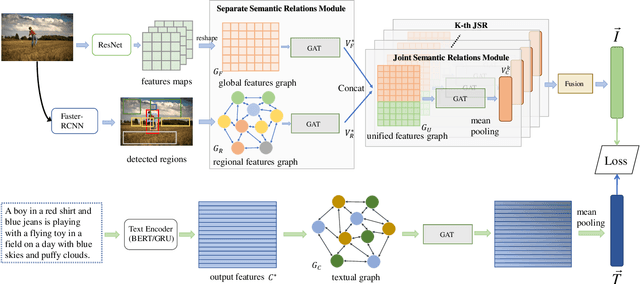
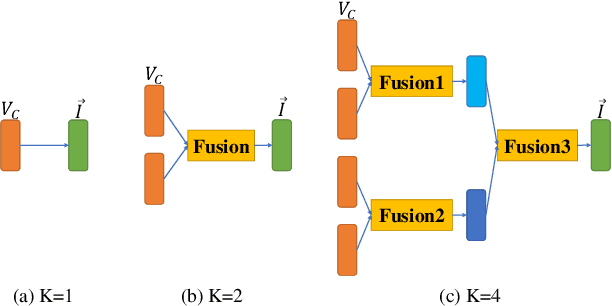
Image-Text Matching is one major task in cross-modal information processing. The main challenge is to learn the unified visual and textual representations. Previous methods that perform well on this task primarily focus on not only the alignment between region features in images and the corresponding words in sentences, but also the alignment between relations of regions and relational words. However, the lack of joint learning of regional features and global features will cause the regional features to lose contact with the global context, leading to the mismatch with those non-object words which have global meanings in some sentences. In this work, in order to alleviate this issue, it is necessary to enhance the relations between regions and the relations between regional and global concepts to obtain a more accurate visual representation so as to be better correlated to the corresponding text. Thus, a novel multi-level semantic relations enhancement approach named Dual Semantic Relations Attention Network(DSRAN) is proposed which mainly consists of two modules, separate semantic relations module and the joint semantic relations module. DSRAN performs graph attention in both modules respectively for region-level relations enhancement and regional-global relations enhancement at the same time. With these two modules, different hierarchies of semantic relations are learned simultaneously, thus promoting the image-text matching process by providing more information for the final visual representation. Quantitative experimental results have been performed on MS-COCO and Flickr30K and our method outperforms previous approaches by a large margin due to the effectiveness of the dual semantic relations learning scheme. Codes are available at https://github.com/kywen1119/DSRAN.
Audio Dequantization for High Fidelity Audio Generation in Flow-based Neural Vocoder
Aug 16, 2020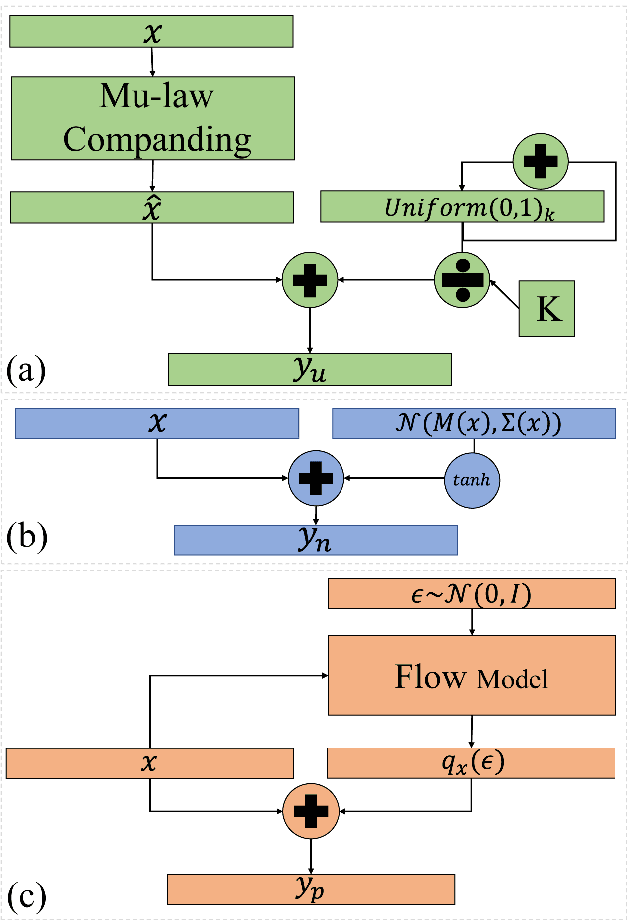
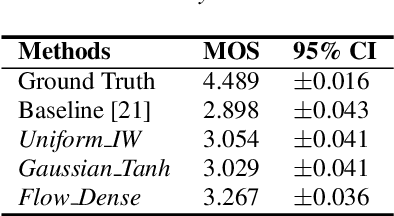
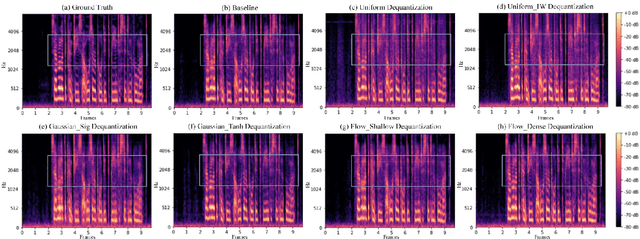

In recent works, a flow-based neural vocoder has shown significant improvement in real-time speech generation task. The sequence of invertible flow operations allows the model to convert samples from simple distribution to audio samples. However, training a continuous density model on discrete audio data can degrade model performance due to the topological difference between latent and actual distribution. To resolve this problem, we propose audio dequantization methods in flow-based neural vocoder for high fidelity audio generation. Data dequantization is a well-known method in image generation but has not yet been studied in the audio domain. For this reason, we implement various audio dequantization methods in flow-based neural vocoder and investigate the effect on the generated audio. We conduct various objective performance assessments and subjective evaluation to show that audio dequantization can improve audio generation quality. From our experiments, using audio dequantization produces waveform audio with better harmonic structure and fewer digital artifacts.