 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Some Experiments with Real-Time Decision Algorithms
Feb 13, 2013
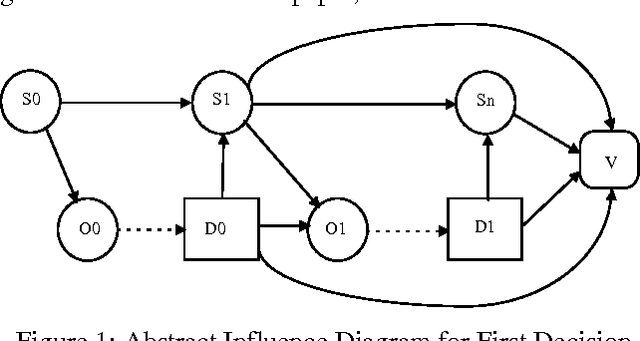
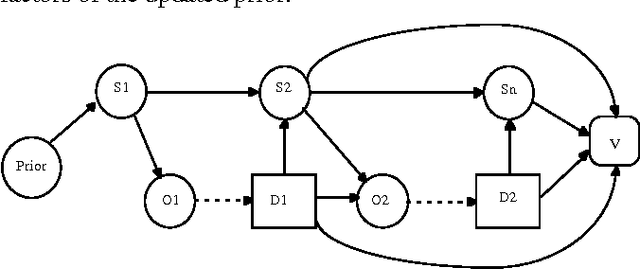
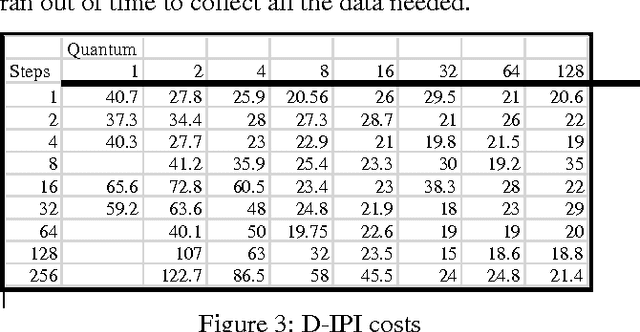
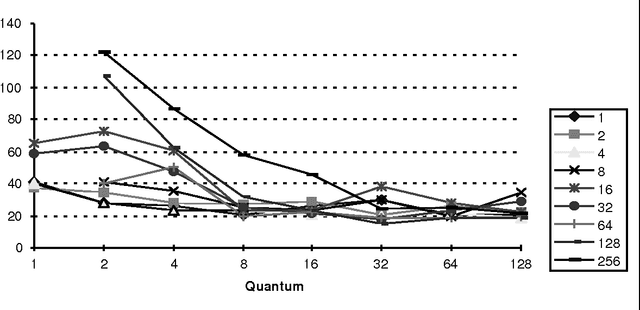
Real-time Decision algorithms are a class of incremental resource-bounded [Horvitz, 89] or anytime [Dean, 93] algorithms for evaluating influence diagrams. We present a test domain for real-time decision algorithms, and the results of experiments with several Real-time Decision Algorithms in this domain. The results demonstrate high performance for two algorithms, a decision-evaluation variant of Incremental Probabilisitic Inference [D'Ambrosio 93] and a variant of an algorithm suggested by Goldszmidt, [Goldszmidt, 95], PK-reduced. We discuss the implications of these experimental results and explore the broader applicability of these algorithms.
Nonparametric Estimation in the Dynamic Bradley-Terry Model
Feb 28, 2020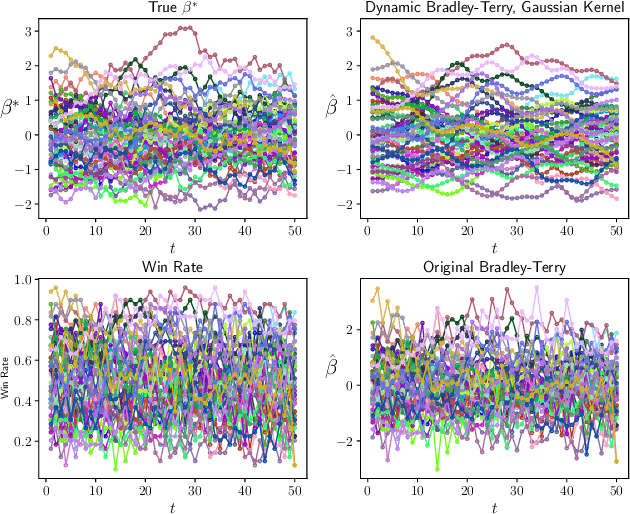
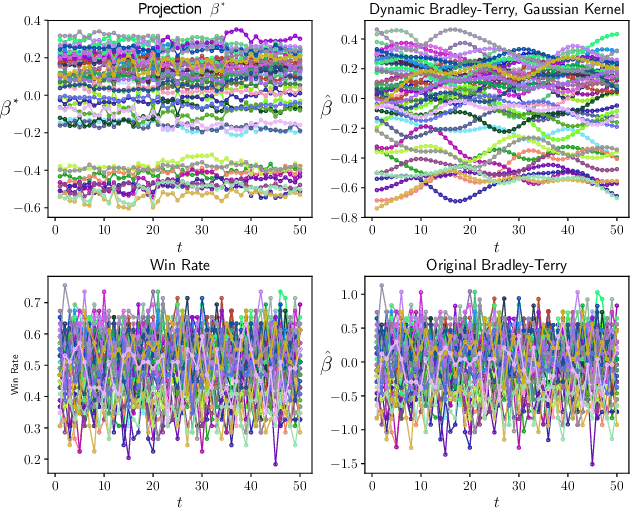

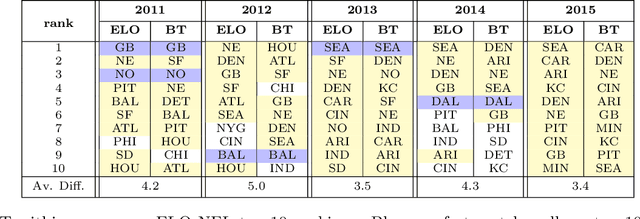
We propose a time-varying generalization of the Bradley-Terry model that allows for nonparametric modeling of dynamic global rankings of distinct teams. We develop a novel estimator that relies on kernel smoothing to pre-process the pairwise comparisons over time and is applicable in sparse settings where the Bradley-Terry may not be fit. We obtain necessary and sufficient conditions for the existence and uniqueness of our estimator. We also derive time-varying oracle bounds for both the estimation error and the excess risk in the model-agnostic setting where the Bradley-Terry model is not necessarily the true data generating process. We thoroughly test the practical effectiveness of our model using both simulated and real world data and suggest an efficient data-driven approach for bandwidth tuning.
Time and Activity Sequence Prediction of Business Process Instances
Feb 24, 2016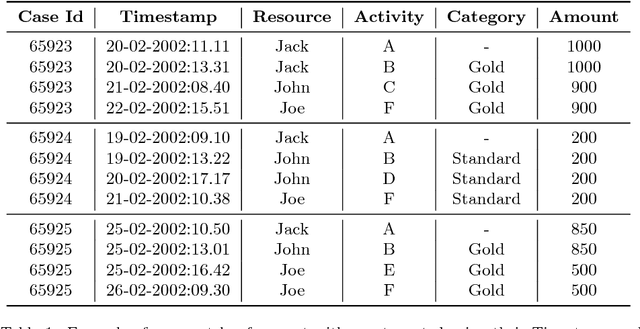
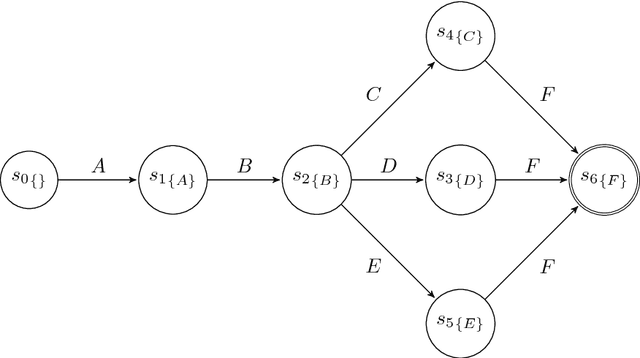
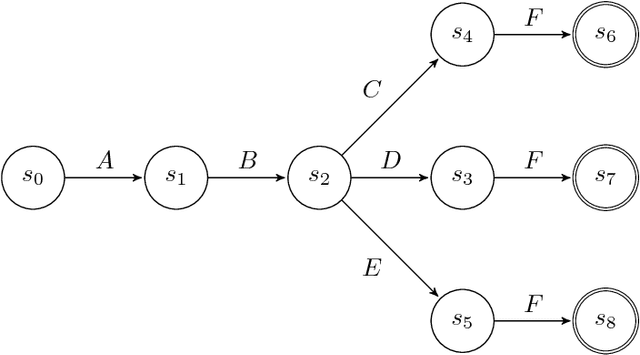

The ability to know in advance the trend of running process instances, with respect to different features, such as the expected completion time, would allow business managers to timely counteract to undesired situations, in order to prevent losses. Therefore, the ability to accurately predict future features of running business process instances would be a very helpful aid when managing processes, especially under service level agreement constraints. However, making such accurate forecasts is not easy: many factors may influence the predicted features. Many approaches have been proposed to cope with this problem but all of them assume that the underling process is stationary. However, in real cases this assumption is not always true. In this work we present new methods for predicting the remaining time of running cases. In particular we propose a method, assuming process stationarity, which outperforms the state-of-the-art and two other methods which are able to make predictions even with non-stationary processes. We also describe an approach able to predict the full sequence of activities that a running case is going to take. All these methods are extensively evaluated on two real case studies.
Hidden Markov Models for Pipeline Damage Detection Using Piezoelectric Transducers
Sep 30, 2020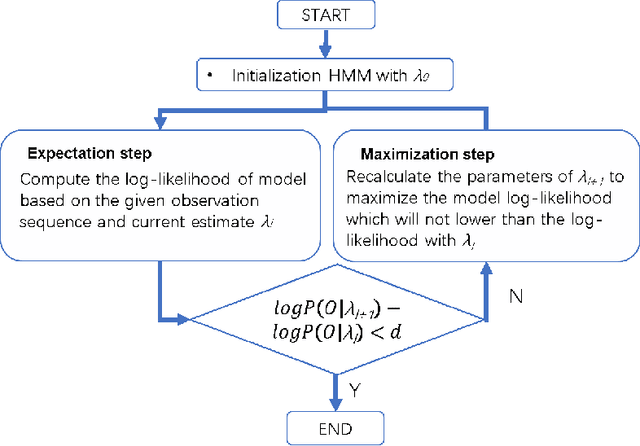
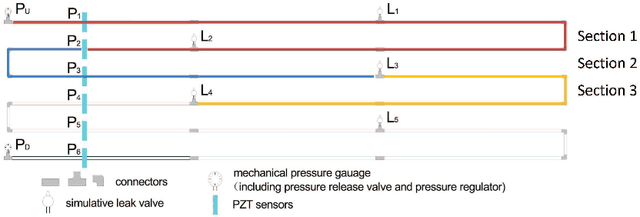
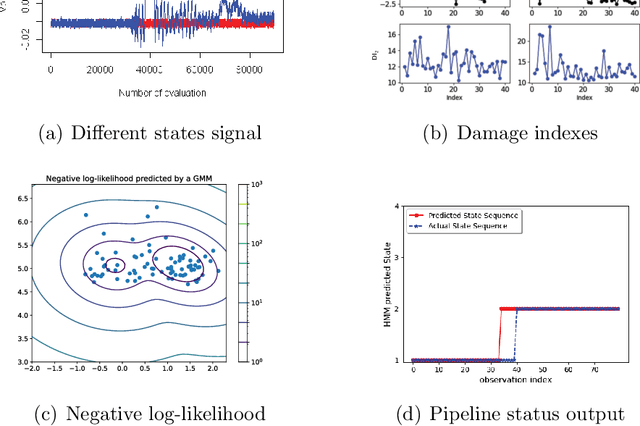
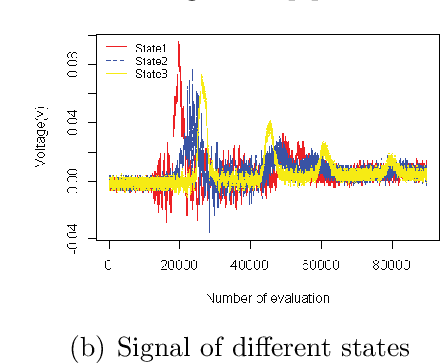
Oil and gas pipeline leakages lead to not only enormous economic loss but also environmental disasters. How to detect the pipeline damages including leakages and cracks has attracted much research attention. One of the promising leakage detection method is to use lead zirconate titanate (PZT) transducers to detect the negative pressure wave when leakage occurs. PZT transducers can generate and detect guided stress waves for crack detection also. However, the negative pressure waves or guided stress waves may not be easily detected with environmental interference, e.g., the oil and gas pipelines in offshore environment. In this paper, a Gaussian mixture model based hidden Markov model (GMM-HMM) method is proposed to detect the pipeline leakage and crack depth in changing environment and time-varying operational conditions. Leakages in different sections or crack depths are considered as different states in hidden Markov models (HMM). Laboratory experiments show that the GMM-HMM method can recognize the crack depth and leakage of pipeline such as whether there is a leakage, where the leakage is.
Chaos, Extremism and Optimism: Volume Analysis of Learning in Games
May 28, 2020

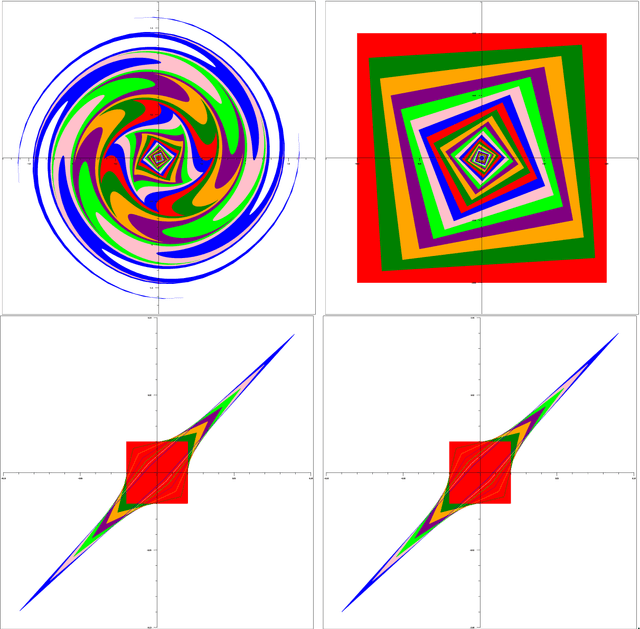
We present volume analyses of Multiplicative Weights Updates (MWU) and Optimistic Multiplicative Weights Updates (OMWU) in zero-sum as well as coordination games. Such analyses provide new insights into these game dynamical systems, which seem hard to achieve via the classical techniques within Computer Science and Machine Learning. The first step is to examine these dynamics not in their original space (simplex of actions) but in a dual space (aggregate payoff space of actions). The second step is to explore how the volume of a set of initial conditions evolves over time when it is pushed forward according to the algorithm. This is reminiscent of approaches in Evolutionary Game Theory where replicator dynamics, the continuous-time analogue of MWU, is known to always preserve volume in all games. Interestingly, when we examine discrete-time dynamics, both the choice of the game and the choice of the algorithm play a critical role. So whereas MWU expands volume in zero-sum games and is thus Lyapunov chaotic, we show that OMWU contracts volume, providing an alternative understanding for its known convergent behavior. However, we also prove a no-free-lunch type of theorem, in the sense that when examining coordination games the roles are reversed: OMWU expands volume exponentially fast, whereas MWU contracts. Using these tools, we prove two novel, rather negative properties of MWU in zero-sum games: (1) Extremism: even in games with unique fully mixed Nash equilibrium, the system recurrently gets stuck near pure-strategy profiles, despite them being clearly unstable from game theoretic perspective. (2) Unavoidability: given any set of good points (with your own interpretation of "good"), the system cannot avoid bad points indefinitely.
Interpreting convolutional networks trained on textual data
Oct 20, 2020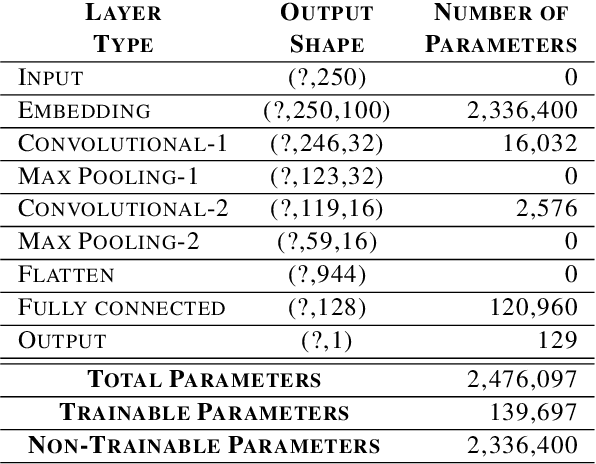
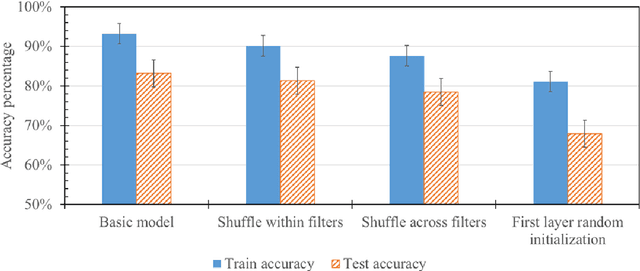

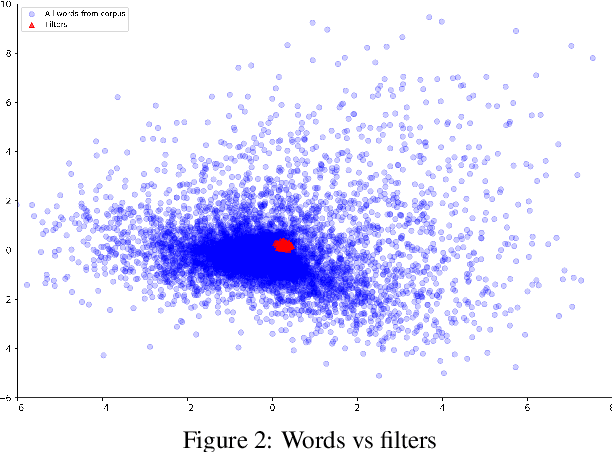
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.
Decision-making at Unsignalized Intersection for Autonomous Vehicles: Left-turn Maneuver with Deep Reinforcement Learning
Aug 14, 2020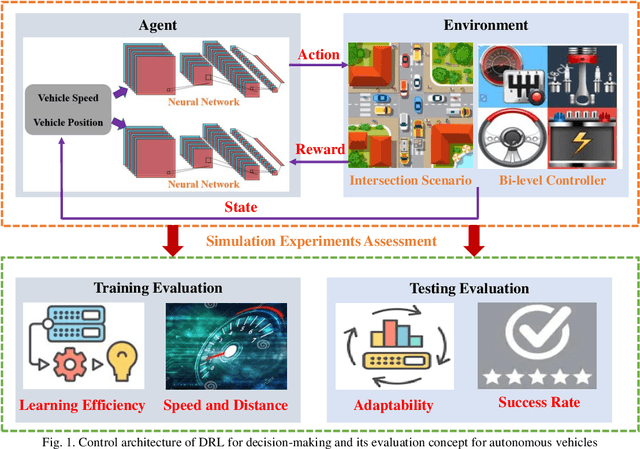
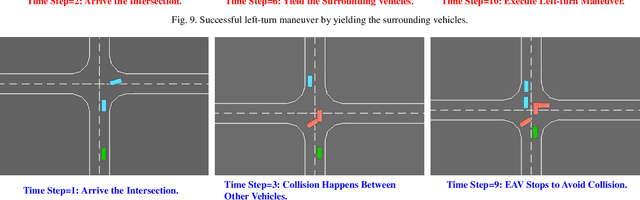
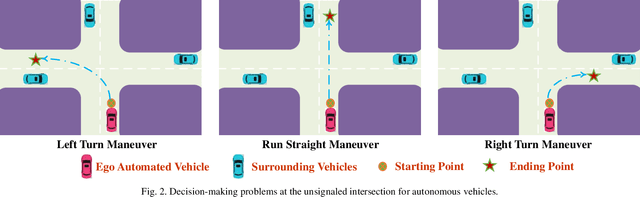
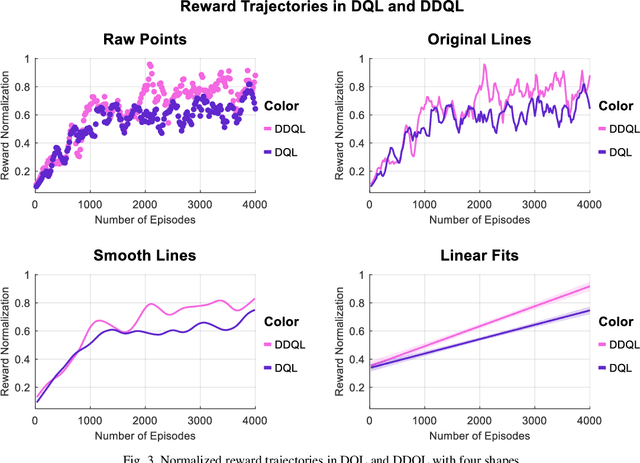
Decision-making module enables autonomous vehicles to reach appropriate maneuvers in the complex urban environments, especially the intersection situations. This work proposes a deep reinforcement learning (DRL) based left-turn decision-making framework at unsignalized intersection for autonomous vehicles. The objective of the studied automated vehicle is to make an efficient and safe left-turn maneuver at a four-way unsignalized intersection. The exploited DRL methods include deep Q-learning (DQL) and double DQL. Simulation results indicate that the presented decision-making strategy could efficaciously reduce the collision rate and improve transport efficiency. This work also reveals that the constructed left-turn control structure has a great potential to be applied in real-time.
Representing Deep Neural Networks Latent Space Geometries with Graphs
Nov 14, 2020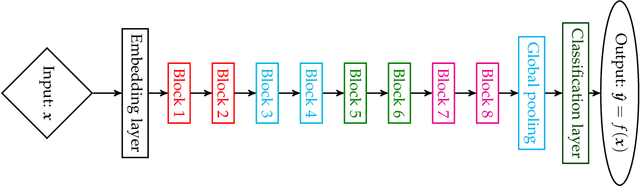

Deep Learning (DL) has attracted a lot of attention for its ability to reach state-of-the-art performance in many machine learning tasks. The core principle of DL methods consists in training composite architectures in an end-to-end fashion, where inputs are associated with outputs trained to optimize an objective function. Because of their compositional nature, DL architectures naturally exhibit several intermediate representations of the inputs, which belong to so-called latent spaces. When treated individually, these intermediate representations are most of the time unconstrained during the learning process, as it is unclear which properties should be favored. However, when processing a batch of inputs concurrently, the corresponding set of intermediate representations exhibit relations (what we call a geometry) on which desired properties can be sought. In this work, we show that it is possible to introduce constraints on these latent geometries to address various problems. In more details, we propose to represent geometries by constructing similarity graphs from the intermediate representations obtained when processing a batch of inputs. By constraining these Latent Geometry Graphs (LGGs), we address the three following problems: i) Reproducing the behavior of a teacher architecture is achieved by mimicking its geometry, ii) Designing efficient embeddings for classification is achieved by targeting specific geometries, and iii) Robustness to deviations on inputs is achieved via enforcing smooth variation of geometry between consecutive latent spaces. Using standard vision benchmarks, we demonstrate the ability of the proposed geometry-based methods in solving the considered problems.
Open Question Answering over Tables and Text
Oct 20, 2020

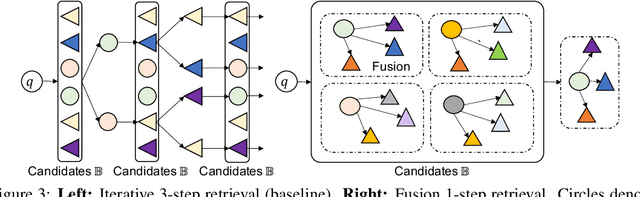
In open question answering (QA), the answer to a question is produced by retrieving and then analyzing documents that might contain answers to the question. Most open QA systems have considered only retrieving information from unstructured text. Here we consider for the first time open QA over both tabular and textual data and present a new large-scale dataset Open Table-Text Question Answering (OTT-QA) to evaluate performance on this task. Most questions in OTT-QA require multi-hop inference across tabular data and unstructured text, and the evidence required to answer a question can be distributed in different ways over these two types of input, making evidence retrieval challenging---our baseline model using an iterative retriever and BERT-based reader achieves an exact match score less than 10%. We then propose two novel techniques to address the challenge of retrieving and aggregating evidence for OTT-QA. The first technique is to use "early fusion" to group multiple highly relevant tabular and textual units into a fused block, which provides more context for the retriever to search for. The second technique is to use a cross-block reader to model the cross-dependency between multiple retrieved evidences with global-local sparse attention. Combining these two techniques improves the score significantly, to above 27%.
Bridging the Gap between Conversational Reasoning and Interactive Recommendation
Oct 20, 2020


There have been growing interests in building a conversational recommender system, where the system simultaneously interacts with the user and explores the user's preference throughout conversational interactions. Recommendation and conversation were usually treated as two separate modules with limited information exchange in existing works, which hinders the capability of both systems: (1) dialog merely incorporated recommendation entities without being guided by an explicit recommendation-oriented policy; (2) recommendation utilized dialog only as a form of interaction instead of improving recommendation effectively. To address the above issues, we propose a novel recommender dialog model: CR-Walker. In order to view the two separate systems within a unified framework, we seek high-level mapping between hierarchical dialog acts and multi-hop knowledge graph reasoning. The model walks on a large-scale knowledge graph to form a reasoning tree at each turn, then mapped to dialog acts to guide response generation. With such a mapping mechanism as a bridge between recommendation and conversation, our framework maximizes the mutual benefit between two systems: dialog as an enhancement to recommendation quality and explainability, recommendation as a goal and enrichment to dialog semantics. Quantitative evaluation shows that our model excels in conversation informativeness and recommendation effectiveness, at the same time explainable on the policy level.