 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of Separation in Finite Gaussian Mixtures
Jun 15, 2026We study an open problem of understanding the effects of the minimum component separation on the convergence rates of parameter estimation in finite Gaussian mixtures. We address this by developing a unified geometric framework based on novel Hellinger lower bounds that directly relate discrepancies between mixture densities directly to Wasserstein distances between their underlying mixing measures, with explicit dependence on both the minimum separation and the minimum weight. Our approach combines carefully designed interpolation polynomials with confluent divided difference techniques to construct specialized moment-extraction test functions. When the number of components is known, these bounds uncover a localization phenomenon: the separation complexity is driven strictly by the spatial configuration of mixture components, namely, whether they are concentrated in a single cluster, partitioned into multiple clusters separated by a macroscopic gap, or arranged without any structural constraints. On the other hand, when the number of components becomes unknown and is over-specified, the separation complexity is slightly reduced, while the minimum mixture weight disappears entirely from the convergence rates due to a transition from first-order to second-order Wasserstein geometry. As a consequence, we obtain separation-dependent convergence rates that continuously interpolate between point-wise and uniform estimation regimes, thereby settling the fundamental limits of parameter recovery in finite Gaussian mixtures.
On Bayesian Softmax-Gated Mixture-of-Experts Models
Apr 22, 2026Mixture-of-experts models provide a flexible framework for learning complex probabilistic input-output relationships by combining multiple expert models through an input-dependent gating mechanism. These models have become increasingly prominent in modern machine learning, yet their theoretical properties in the Bayesian framework remain largely unexplored. In this paper, we study Bayesian mixture-of-experts models, focusing on the ubiquitous softmax-based gating mechanism. Specifically, we investigate the asymptotic behavior of the posterior distribution for three fundamental statistical tasks: density estimation, parameter estimation, and model selection. First, we establish posterior contraction rates for density estimation, both in the regimes with a fixed, known number of experts and with a random learnable number of experts. We then analyze parameter estimation and derive convergence guarantees based on tailored Voronoi-type losses, which account for the complex identifiability structure of mixture-of-experts models. Finally, we propose and analyze two complementary strategies for selecting the number of experts. Taken together, these results provide one of the first systematic theoretical analyses of Bayesian mixture-of-experts models with softmax gating, and yield several theory-grounded insights for practical model design.
Optimal Unconstrained Self-Distillation in Ridge Regression: Strict Improvements, Precise Asymptotics, and One-Shot Tuning
Feb 19, 2026Self-distillation (SD) is the process of retraining a student on a mixture of ground-truth labels and the teacher's own predictions using the same architecture and training data. Although SD has been empirically shown to often improve generalization, its formal guarantees remain limited. We study SD for ridge regression in unconstrained setting in which the mixing weight $ξ$ may be outside the unit interval. Conditioned on the training data and without any distributional assumptions, we prove that for any squared prediction risk (including out-of-distribution), the optimally mixed student strictly improves upon the ridge teacher for every regularization level $λ> 0$ at which the teacher ridge risk $R(λ)$ is nonstationary (i.e., $R'(λ) \neq 0$). We obtain a closed-form expression for the optimal mixing weight $ξ^\star(λ)$ for any value of $λ$ and show that it obeys the sign rule: $\operatorname{sign}(ξ^\star(λ))=-\operatorname{sign}(R'(λ))$. In particular, $ξ^\star(λ)$ can be negative, which is the case in over-regularized regimes. To quantify the risk improvement due to SD, we derive exact deterministic equivalents for the optimal SD risk in the proportional asymptotics regime (where the sample and feature sizes $n$ and $p$ both diverge but their aspect ratio $p/n$ converges) under general anisotropic covariance and deterministic signals. Our asymptotic analysis extends standard second-order ridge deterministic equivalents to their fourth-order analogs using block linearization, which may be of independent interest. From a practical standpoint, we propose a consistent one-shot tuning method to estimate $ξ^\star$ without grid search, sample splitting, or refitting. Experiments on real-world datasets and pretrained neural network features support our theory and the one-shot tuning method.
A Statistical Theory of Gated Attention through the Lens of Hierarchical Mixture of Experts
Feb 01, 2026Self-attention has greatly contributed to the success of the widely used Transformer architecture by enabling learning from data with long-range dependencies. In an effort to improve performance, a gated attention model that leverages a gating mechanism within the multi-head self-attention has recently been proposed as a promising alternative. Gated attention has been empirically demonstrated to increase the expressiveness of low-rank mapping in standard attention and even to eliminate the attention sink phenomenon. Despite its efficacy, a clear theoretical understanding of gated attention's benefits remains lacking in the literature. To close this gap, we rigorously show that each entry in a gated attention matrix or a multi-head self-attention matrix can be written as a hierarchical mixture of experts. By recasting learning as an expert estimation problem, we demonstrate that gated attention is more sample-efficient than multi-head self-attention. In particular, while the former needs only a polynomial number of data points to estimate an expert, the latter requires exponentially many data points to achieve the same estimation error. Furthermore, our analysis also provides a theoretical justification for why gated attention yields higher performance when a gate is placed at the output of the scaled dot product attention or the value map rather than at other positions in the multi-head self-attention architecture.
Rethinking Multinomial Logistic Mixture of Experts with Sigmoid Gating Function
Feb 01, 2026The sigmoid gate in mixture-of-experts (MoE) models has been empirically shown to outperform the softmax gate across several tasks, ranging from approximating feed-forward networks to language modeling. Additionally, recent efforts have demonstrated that the sigmoid gate is provably more sample-efficient than its softmax counterpart under regression settings. Nevertheless, there are three notable concerns that have not been addressed in the literature, namely (i) the benefits of the sigmoid gate have not been established under classification settings; (ii) existing sigmoid-gated MoE models may not converge to their ground-truth; and (iii) the effects of a temperature parameter in the sigmoid gate remain theoretically underexplored. To tackle these open problems, we perform a comprehensive analysis of multinomial logistic MoE equipped with a modified sigmoid gate to ensure model convergence. Our results indicate that the sigmoid gate exhibits a lower sample complexity than the softmax gate for both parameter and expert estimation. Furthermore, we find that incorporating a temperature into the sigmoid gate leads to a sample complexity of exponential order due to an intrinsic interaction between the temperature and gating parameters. To overcome this issue, we propose replacing the vanilla inner product score in the gating function with a Euclidean score that effectively removes that interaction, thereby substantially improving the sample complexity to a polynomial order.
Low-Dimensional Adaptation of Rectified Flow: A New Perspective through the Lens of Diffusion and Stochastic Localization
Jan 21, 2026In recent years, Rectified flow (RF) has gained considerable popularity largely due to its generation efficiency and state-of-the-art performance. In this paper, we investigate the degree to which RF automatically adapts to the intrinsic low dimensionality of the support of the target distribution to accelerate sampling. We show that, using a carefully designed choice of the time-discretization scheme and with sufficiently accurate drift estimates, the RF sampler enjoys an iteration complexity of order $O(k/\varepsilon)$ (up to log factors), where $\varepsilon$ is the precision in total variation distance and $k$ is the intrinsic dimension of the target distribution. In addition, we show that the denoising diffusion probabilistic model (DDPM) procedure is equivalent to a stochastic version of RF by establishing a novel connection between these processes and stochastic localization. Building on this connection, we further design a stochastic RF sampler that also adapts to the low-dimensionality of the target distribution under milder requirements on the accuracy of the drift estimates, and also with a specific time schedule. We illustrate with simulations on the synthetic data and text-to-image data experiments the improved performance of the proposed samplers implementing the newly designed time-discretization schedules.
On Minimax Estimation of Parameters in Softmax-Contaminated Mixture of Experts
May 24, 2025
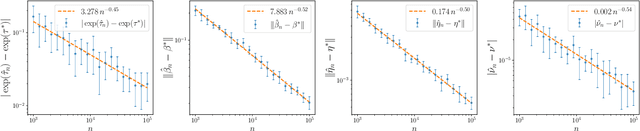
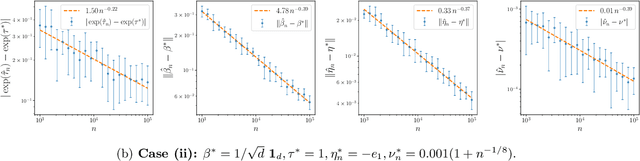
The softmax-contaminated mixture of experts (MoE) model is deployed when a large-scale pre-trained model, which plays the role of a fixed expert, is fine-tuned for learning downstream tasks by including a new contamination part, or prompt, functioning as a new, trainable expert. Despite its popularity and relevance, the theoretical properties of the softmax-contaminated MoE have remained unexplored in the literature. In the paper, we study the convergence rates of the maximum likelihood estimator of gating and prompt parameters in order to gain insights into the statistical properties and potential challenges of fine-tuning with a new prompt. We find that the estimability of these parameters is compromised when the prompt acquires overlapping knowledge with the pre-trained model, in the sense that we make precise by formulating a novel analytic notion of distinguishability. Under distinguishability of the pre-trained and prompt models, we derive minimax optimal estimation rates for all the gating and prompt parameters. By contrast, when the distinguishability condition is violated, these estimation rates become significantly slower due to their dependence on the prompt convergence rate to the pre-trained model. Finally, we empirically corroborate our theoretical findings through several numerical experiments.
On DeepSeekMoE: Statistical Benefits of Shared Experts and Normalized Sigmoid Gating
May 16, 2025Mixture of experts (MoE) methods are a key component in most large language model architectures, including the recent series of DeepSeek models. Compared to other MoE implementations, DeepSeekMoE stands out because of two unique features: the deployment of a shared expert strategy and of the normalized sigmoid gating mechanism. Despite the prominent role of DeepSeekMoE in the success of the DeepSeek series of models, there have been only a few attempts to justify theoretically the value of the shared expert strategy, while its normalized sigmoid gating has remained unexplored. To bridge this gap, we undertake a comprehensive theoretical study of these two features of DeepSeekMoE from a statistical perspective. We perform a convergence analysis of the expert estimation task to highlight the gains in sample efficiency for both the shared expert strategy and the normalized sigmoid gating, offering useful insights into the design of expert and gating structures. To verify empirically our theoretical findings, we carry out several experiments on both synthetic data and real-world datasets for (vision) language modeling tasks. Finally, we conduct an extensive empirical analysis of the router behaviors, ranging from router saturation, router change rate, to expert utilization.
Convergence Rates for Softmax Gating Mixture of Experts
Mar 05, 2025



Mixture of experts (MoE) has recently emerged as an effective framework to advance the efficiency and scalability of machine learning models by softly dividing complex tasks among multiple specialized sub-models termed experts. Central to the success of MoE is an adaptive softmax gating mechanism which takes responsibility for determining the relevance of each expert to a given input and then dynamically assigning experts their respective weights. Despite its widespread use in practice, a comprehensive study on the effects of the softmax gating on the MoE has been lacking in the literature. To bridge this gap in this paper, we perform a convergence analysis of parameter estimation and expert estimation under the MoE equipped with the standard softmax gating or its variants, including a dense-to-sparse gating and a hierarchical softmax gating, respectively. Furthermore, our theories also provide useful insights into the design of sample-efficient expert structures. In particular, we demonstrate that it requires polynomially many data points to estimate experts satisfying our proposed \emph{strong identifiability} condition, namely a commonly used two-layer feed-forward network. In stark contrast, estimating linear experts, which violate the strong identifiability condition, necessitates exponentially many data points as a result of intrinsic parameter interactions expressed in the language of partial differential equations. All the theoretical results are substantiated with a rigorous guarantee.
Uncertainty quantification for Markov chains with application to temporal difference learning
Feb 19, 2025Markov chains are fundamental to statistical machine learning, underpinning key methodologies such as Markov Chain Monte Carlo (MCMC) sampling and temporal difference (TD) learning in reinforcement learning (RL). Given their widespread use, it is crucial to establish rigorous probabilistic guarantees on their convergence, uncertainty, and stability. In this work, we develop novel, high-dimensional concentration inequalities and Berry-Esseen bounds for vector- and matrix-valued functions of Markov chains, addressing key limitations in existing theoretical tools for handling dependent data. We leverage these results to analyze the TD learning algorithm, a widely used method for policy evaluation in RL. Our analysis yields a sharp high-probability consistency guarantee that matches the asymptotic variance up to logarithmic factors. Furthermore, we establish a $O(T^{-\frac{1}{4}}\log T)$ distributional convergence rate for the Gaussian approximation of the TD estimator, measured in convex distance. These findings provide new insights into statistical inference for RL algorithms, bridging the gaps between classical stochastic approximation theory and modern reinforcement learning applications.