 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLAB: A Hybrid Inverse-Design Framework
May 23, 2025HiLAB (Hybrid inverse-design with Latent-space learning, Adjoint-based partial optimizations, and Bayesian optimization) is a new paradigm for inverse design of nanophotonic structures. Combining early-terminated topological optimization (TO) with a Vision Transformer-based variational autoencoder (VAE) and a Bayesian search, HiLAB addresses multi-functional device design by generating diverse freeform configurations at reduced simulation costs. Shortened adjoint-driven TO runs, coupled with randomized physical parameters, produce robust initial structures. These structures are compressed into a compact latent space by the VAE, enabling Bayesian optimization to co-optimize geometry and physical hyperparameters. Crucially, the trained VAE can be reused for alternative objectives or constraints by adjusting only the acquisition function. Compared to conventional TO pipelines prone to local optima, HiLAB systematically explores near-global optima with considerably fewer electromagnetic simulations. Even after accounting for training overhead, the total number of full simulations decreases by over an order of magnitude, accelerating the discovery of fabrication-friendly devices. Demonstrating its efficacy, HiLAB is used to design an achromatic beam deflector for red, green, and blue wavelengths, achieving balanced diffraction efficiencies of ~25% while mitigating chromatic aberrations-a performance surpassing existing demonstrations. Overall, HiLAB provides a flexible platform for robust, multi-parameter photonic designs and rapid adaptation to next-generation nanophotonic challenges.
Evaluating BM3D and NBNet: A Comprehensive Study of Image Denoising Across Multiple Datasets
Aug 11, 2024



This paper investigates image denoising, comparing traditional non-learning-based techniques, represented by Block-Matching 3D (BM3D), with modern learning-based methods, exemplified by NBNet. We assess these approaches across diverse datasets, including CURE-OR, CURE-TSR, SSID+, Set-12, and Chest-Xray, each presenting unique noise challenges. Our analysis employs seven Image Quality Assessment (IQA) metrics and examines the impact on object detection performance. We find that while BM3D excels in scenarios like blur challenges, NBNet is more effective in complex noise environments such as under-exposure and over-exposure. The study reveals the strengths and limitations of each method, providing insights into the effectiveness of different denoising strategies in varied real-world applications.
Knowledge AI: Fine-tuning NLP Models for Facilitating Scientific Knowledge Extraction and Understanding
Aug 04, 2024This project investigates the efficacy of Large Language Models (LLMs) in understanding and extracting scientific knowledge across specific domains and to create a deep learning framework: Knowledge AI. As a part of this framework, we employ pre-trained models and fine-tune them on datasets in the scientific domain. The models are adapted for four key Natural Language Processing (NLP) tasks: summarization, text generation, question answering, and named entity recognition. Our results indicate that domain-specific fine-tuning significantly enhances model performance in each of these tasks, thereby improving their applicability for scientific contexts. This adaptation enables non-experts to efficiently query and extract information within targeted scientific fields, demonstrating the potential of fine-tuned LLMs as a tool for knowledge discovery in the sciences.
Interpreting convolutional networks trained on textual data
Oct 20, 2020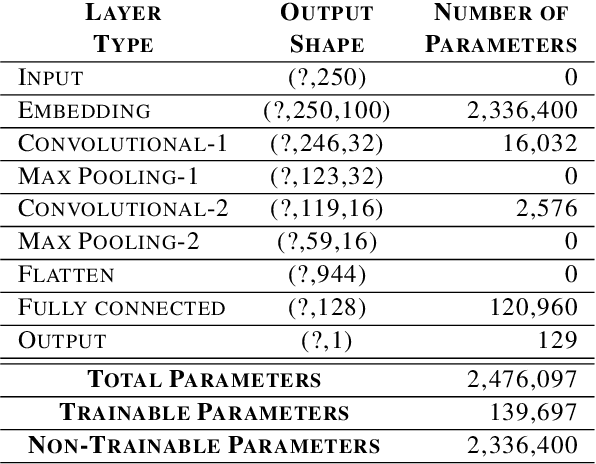
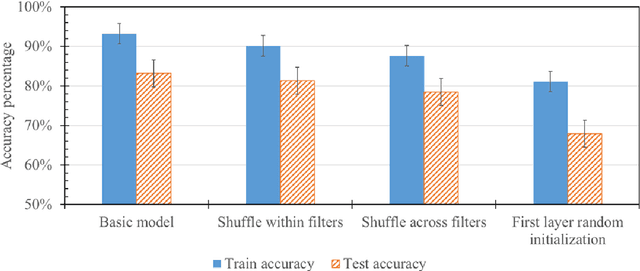

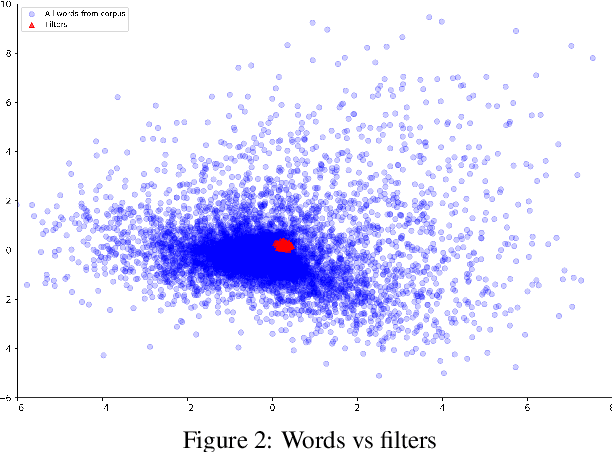
There have been many advances in the artificial intelligence field due to the emergence of deep learning. In almost all sub-fields, artificial neural networks have reached or exceeded human-level performance. However, most of the models are not interpretable. As a result, it is hard to trust their decisions, especially in life and death scenarios. In recent years, there has been a movement toward creating explainable artificial intelligence, but most work to date has concentrated on image processing models, as it is easier for humans to perceive visual patterns. There has been little work in other fields like natural language processing. In this paper, we train a convolutional model on textual data and analyze the global logic of the model by studying its filter values. In the end, we find the most important words in our corpus to our models logic and remove the rest (95%). New models trained on just the 5% most important words can achieve the same performance as the original model while reducing training time by more than half. Approaches such as this will help us to understand NLP models, explain their decisions according to their word choices, and improve them by finding blind spots and biases.