 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Optimization in Games via Control Theory: Connecting Regret, Passivity and Poincaré Recurrence
Jun 15, 2021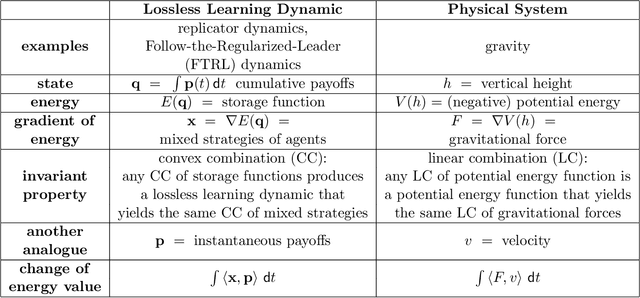



We present a novel control-theoretic understanding of online optimization and learning in games, via the notion of passivity. Passivity is a fundamental concept in control theory, which abstracts energy conservation and dissipation in physical systems. It has become a standard tool in analysis of general feedback systems, to which game dynamics belong. Our starting point is to show that all continuous-time Follow-the-Regularized-Leader (FTRL) dynamics, which include the well-known Replicator Dynamic, are lossless, i.e. it is passive with no energy dissipation. Interestingly, we prove that passivity implies bounded regret, connecting two fundamental primitives of control theory and online optimization. The observation of energy conservation in FTRL inspires us to present a family of lossless learning dynamics, each of which has an underlying energy function with a simple gradient structure. This family is closed under convex combination; as an immediate corollary, any convex combination of FTRL dynamics is lossless and thus has bounded regret. This allows us to extend the framework of Fox and Shamma [Games, 2013] to prove not just global asymptotic stability results for game dynamics, but Poincar\'e recurrence results as well. Intuitively, when a lossless game (e.g. graphical constant-sum game) is coupled with lossless learning dynamics, their feedback interconnection is also lossless, which results in a pendulum-like energy-preserving recurrent behavior, generalizing the results of Piliouras and Shamma [SODA, 2014] and Mertikopoulos, Papadimitriou and Piliouras [SODA, 2018].
Chaos, Extremism and Optimism: Volume Analysis of Learning in Games
May 28, 2020

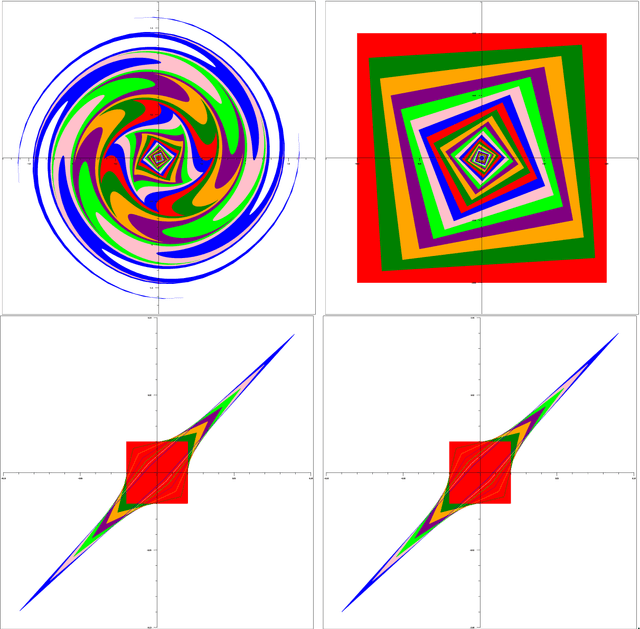
We present volume analyses of Multiplicative Weights Updates (MWU) and Optimistic Multiplicative Weights Updates (OMWU) in zero-sum as well as coordination games. Such analyses provide new insights into these game dynamical systems, which seem hard to achieve via the classical techniques within Computer Science and Machine Learning. The first step is to examine these dynamics not in their original space (simplex of actions) but in a dual space (aggregate payoff space of actions). The second step is to explore how the volume of a set of initial conditions evolves over time when it is pushed forward according to the algorithm. This is reminiscent of approaches in Evolutionary Game Theory where replicator dynamics, the continuous-time analogue of MWU, is known to always preserve volume in all games. Interestingly, when we examine discrete-time dynamics, both the choice of the game and the choice of the algorithm play a critical role. So whereas MWU expands volume in zero-sum games and is thus Lyapunov chaotic, we show that OMWU contracts volume, providing an alternative understanding for its known convergent behavior. However, we also prove a no-free-lunch type of theorem, in the sense that when examining coordination games the roles are reversed: OMWU expands volume exponentially fast, whereas MWU contracts. Using these tools, we prove two novel, rather negative properties of MWU in zero-sum games: (1) Extremism: even in games with unique fully mixed Nash equilibrium, the system recurrently gets stuck near pure-strategy profiles, despite them being clearly unstable from game theoretic perspective. (2) Unavoidability: given any set of good points (with your own interpretation of "good"), the system cannot avoid bad points indefinitely.