 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Group-wise Variational Diffeomorphic Image Registration
Oct 01, 2020
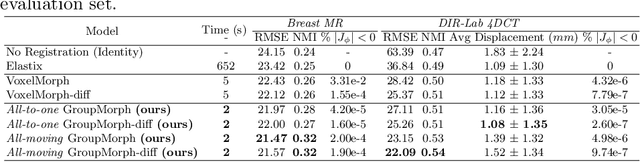
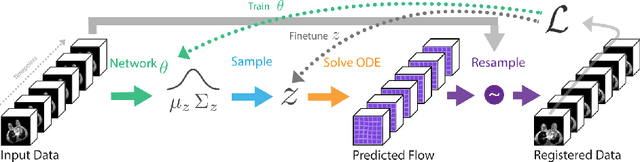
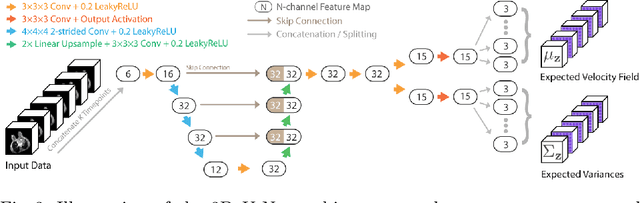
Deep neural networks are increasingly used for pair-wise image registration. We propose to extend current learning-based image registration to allow simultaneous registration of multiple images. To achieve this, we build upon the pair-wise variational and diffeomorphic VoxelMorph approach and present a general mathematical framework that enables both registration of multiple images to their geodesic average and registration in which any of the available images can be used as a fixed image. In addition, we provide a likelihood based on normalized mutual information, a well-known image similarity metric in registration, between multiple images, and a prior that allows for explicit control over the viscous fluid energy to effectively regularize deformations. We trained and evaluated our approach using intra-patient registration of breast MRI and Thoracic 4DCT exams acquired over multiple time points. Comparison with Elastix and VoxelMorph demonstrates competitive quantitative performance of the proposed method in terms of image similarity and reference landmark distances at significantly faster registration.
A Data-Efficient Deep Learning Based Smartphone Application For Detection Of Pulmonary Diseases Using Chest X-rays
Aug 19, 2020
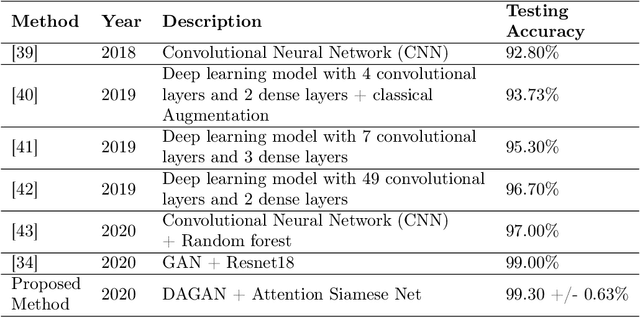
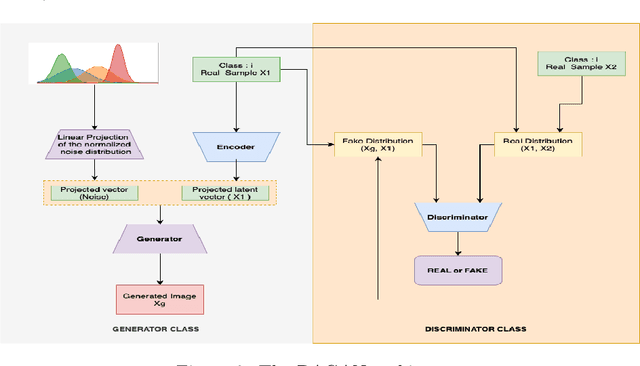

This paper introduces a paradigm of smartphone application based disease diagnostics that may completely revolutionise the way healthcare services are being provided. Although primarily aimed to assist the problems in rendering the healthcare services during the coronavirus pandemic, the model can also be extended to identify the exact disease that the patient is caught with from a broad spectrum of pulmonary diseases. The app inputs Chest X-Ray images captured from the mobile camera which is then relayed to the AI architecture in a cloud platform, and diagnoses the disease with state of the art accuracy. Doctors with a smartphone can leverage the application to save the considerable time that standard COVID-19 tests take for preliminary diagnosis. The scarcity of training data and class imbalance issues were effectively tackled in our approach by the use of Data Augmentation Generative Adversarial Network (DAGAN) and model architecture based as a Convolutional Siamese Network with attention mechanism. The backend model was tested for robustness us-ing publicly available datasets under two different classification scenarios(Binary/Multiclass) with minimal and noisy data. The model achieved pinnacle testing accuracy of 99.30% and 98.40% on the two respective scenarios, making it completely reliable for its users. On top of that a semi-live training scenario was introduced, which helps improve the app performance over time as data accumulates. Overall, the problems of generalisability of complex models and data inefficiency is tackled through the model architecture. The app based setting with semi live training helps in ease of access to reliable healthcare in the society, as well as help ineffective research of rare diseases in a minimal data setting.
Computational tool to study high dimensional dynamic in NMM
Sep 25, 2020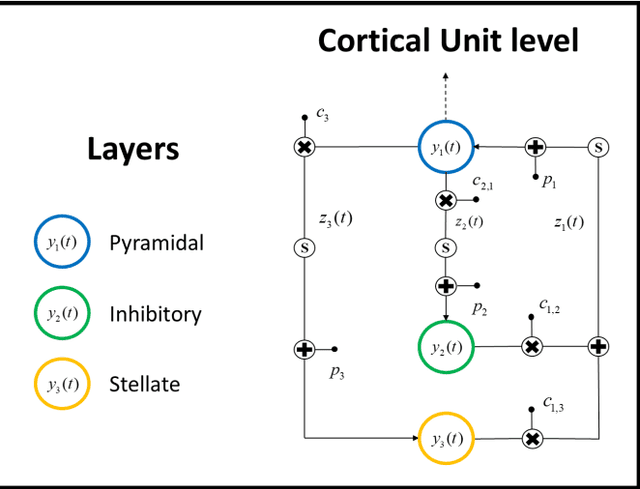
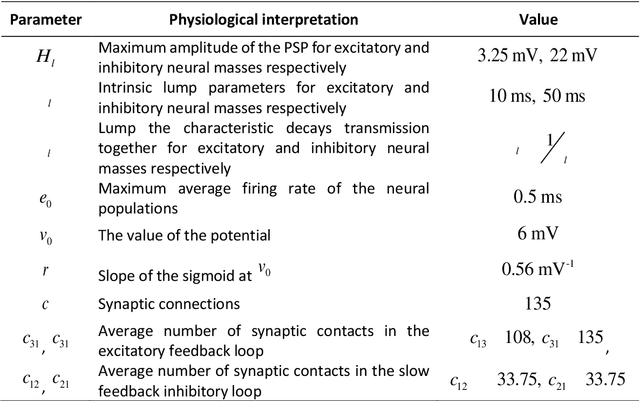
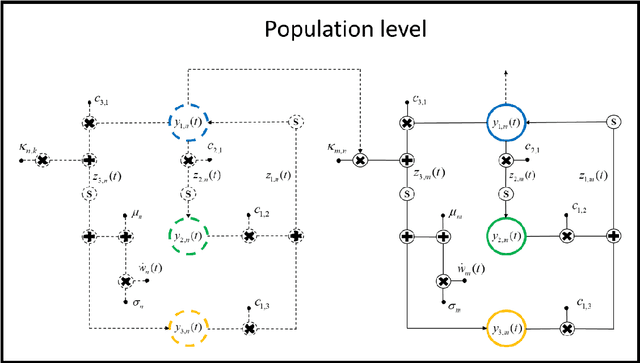

Neuroscience has shown great progress in recent years. Several of the theoretical bases have arisen from the examination of dynamic systems, using Neural Mass Models (NMMs). Due to the largescale brain dynamics of NMMs and the difficulty of studying nonlinear systems, the local linearization approach to discretize the state equation was used via an algebraic formulation, as it intervenes favorably in the speed and efficiency of numerical integration. To study the spacetime organization of the brain and generate more complex dynamics, three structural levels (cortical unit, population and system) were defined and assumed, in which the new assumed representation for conduction delays and new ways of connecting were defined. This is a new time-delay NMM, which can simulate several types of EEG activities since kinetics information was considered at three levels of complexity. Results obtained in this analysis provide additional theoretical foundations and indicate specific characteristics for understanding neurodynamic.
A Multi-Plant Disease Diagnosis Method using Convolutional Neural Network
Nov 10, 2020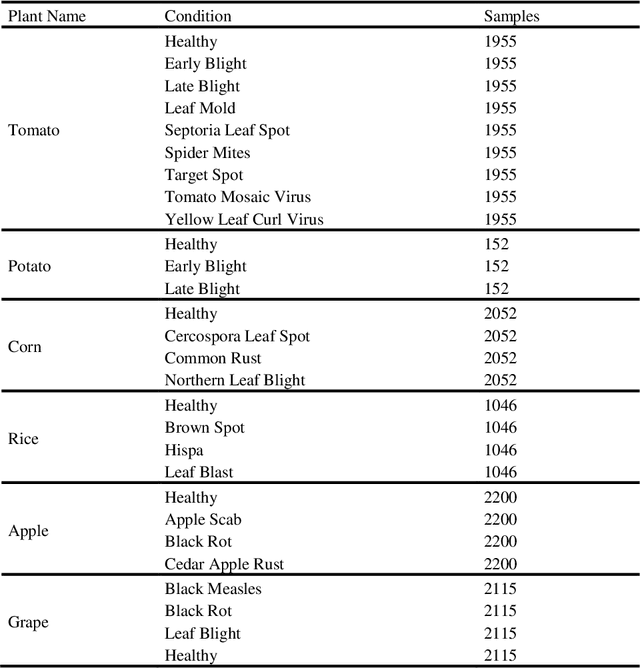

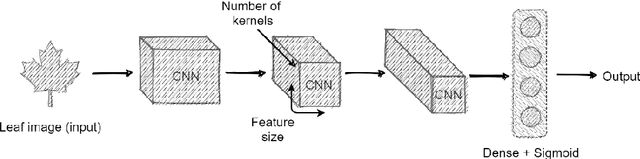
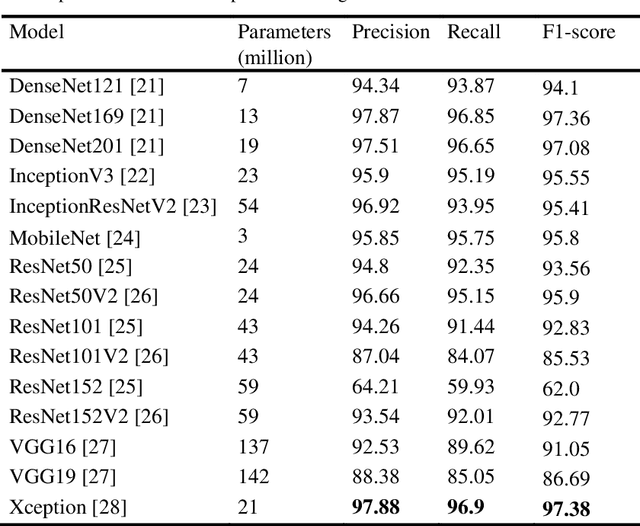
A disease that limits a plant from its maximal capacity is defined as plant disease. From the perspective of agriculture, diagnosing plant disease is crucial, as diseases often limit plants' production capacity. However, manual approaches to recognize plant diseases are often temporal, challenging, and time-consuming. Therefore, computerized recognition of plant diseases is highly desired in the field of agricultural automation. Due to the recent improvement of computer vision, identifying diseases using leaf images of a particular plant has already been introduced. Nevertheless, the most introduced model can only diagnose diseases of a specific plant. Hence, in this chapter, we investigate an optimal plant disease identification model combining the diagnosis of multiple plants. Despite relying on multi-class classification, the model inherits a multilabel classification method to identify the plant and the type of disease in parallel. For the experiment and evaluation, we collected data from various online sources that included leaf images of six plants, including tomato, potato, rice, corn, grape, and apple. In our investigation, we implement numerous popular convolutional neural network (CNN) architectures. The experimental results validate that the Xception and DenseNet architectures perform better in multi-label plant disease classification tasks. Through architectural investigation, we imply that skip connections, spatial convolutions, and shorter hidden layer connectivity cause better results in plant disease classification.
Sequential Routing Framework: Fully Capsule Network-based Speech Recognition
Jul 23, 2020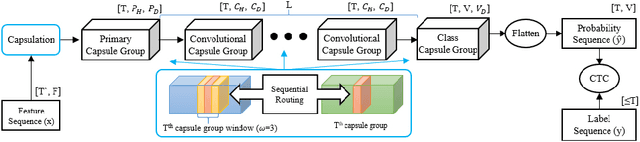
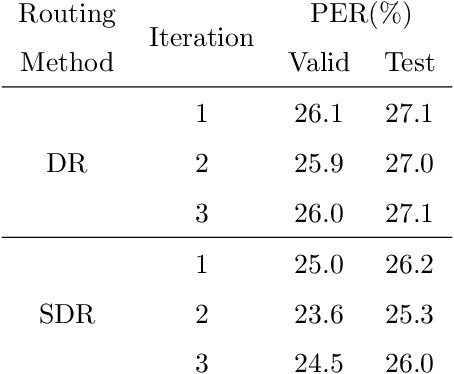
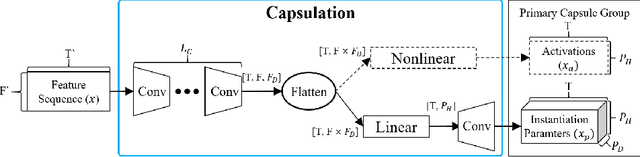
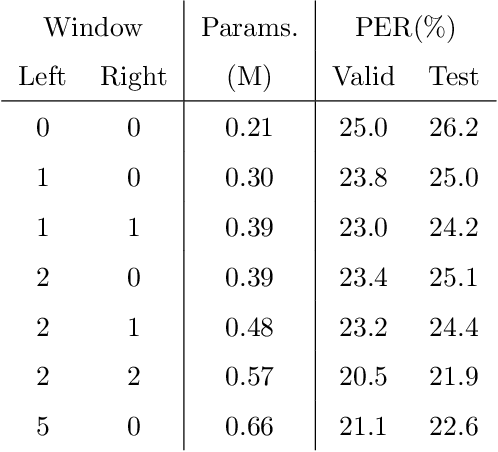
Capsule networks (CapsNets) have recently gotten attention as alternatives for convolutional neural networks (CNNs) with their greater hierarchical representation capabilities. In this paper, we introduce the sequential routing framework (SRF) which we believe is the first method to adapt a CapsNet-only structure to sequence-to-sequence recognition. In SRF, input sequences are capsulized then sliced by the window size. Each sliced window is classified to a label at the corresponding time through iterative routing mechanisms. Afterwards, training losses are computed using connectionist temporal classification (CTC). During routing, two kinds of information, learnable weights and iteration outputs are shared across the slices. By sharing the information, the required parameter numbers can be controlled by the given window size regardless of the length of sequences. Moreover, the method can minimize decoding speed degradation caused by the routing iterations since it can operate in a non-iterative manner at inference time without dropping accuracy. We empirically proved the validity of our method by performing phoneme sequence recognition tasks on the TIMIT corpus. The proposed method attains an 82.6% phoneme recognition rate. It is 0.8% more accurate than that of CNN-based CTC networks and on par with that of recurrent neural network transducers (RNN-Ts). Even more, the method requires less than half the parameters compared to the two architectures.
Neural Enhancement in Content Delivery Systems: The State-of-the-Art and Future Directions
Oct 12, 2020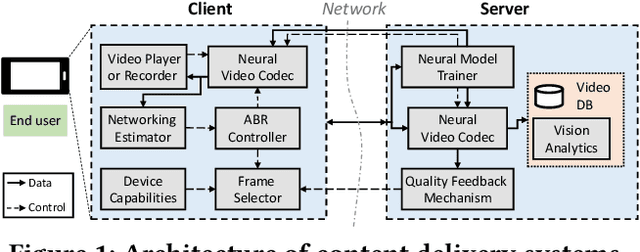


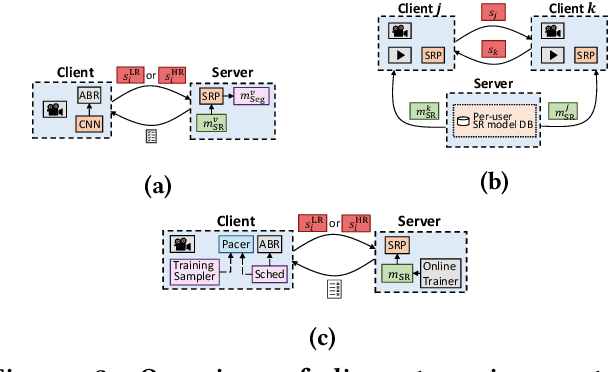
Internet-enabled smartphones and ultra-wide displays are transforming a variety of visual apps spanning from on-demand movies and 360-degree videos to video-conferencing and live streaming. However, robustly delivering visual content under fluctuating networking conditions on devices of diverse capabilities remains an open problem. In recent years, advances in the field of deep learning on tasks such as super-resolution and image enhancement have led to unprecedented performance in generating high-quality images from low-quality ones, a process we refer to as neural enhancement. In this paper, we survey state-of-the-art content delivery systems that employ neural enhancement as a key component in achieving both fast response time and high visual quality. We first present the deployment challenges of neural enhancement models. We then cover systems targeting diverse use-cases and analyze their design decisions in overcoming technical challenges. Moreover, we present promising directions based on the latest insights from deep learning research to further boost the quality of experience of these systems.
Accelerating Text Mining Using Domain-Specific Stop Word Lists
Nov 18, 2020
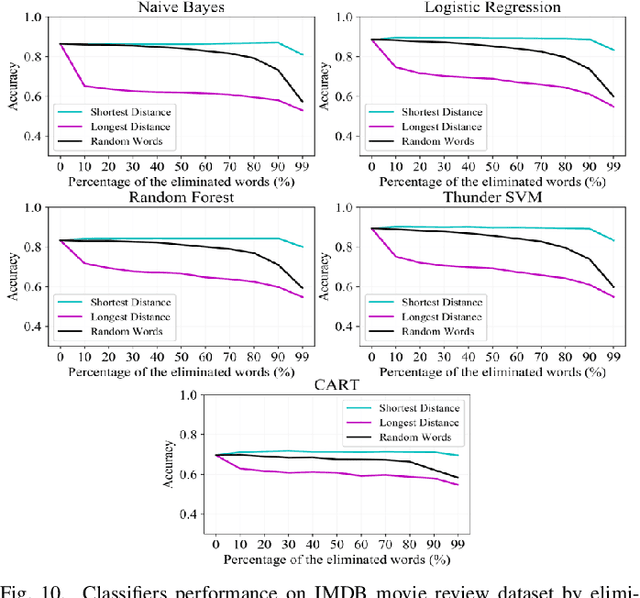
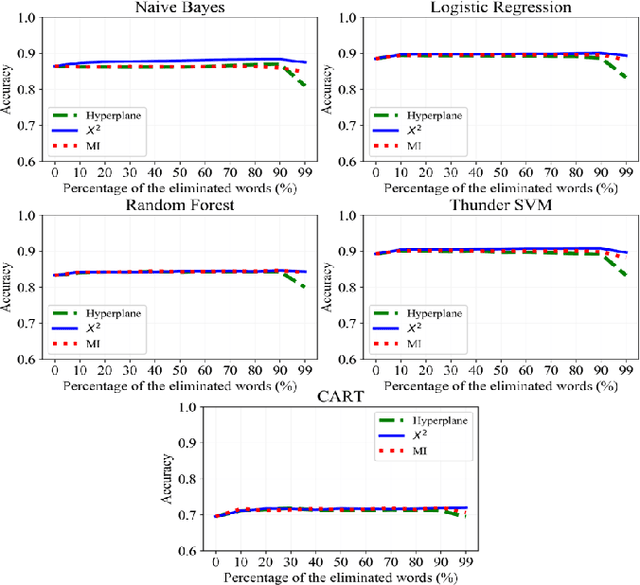
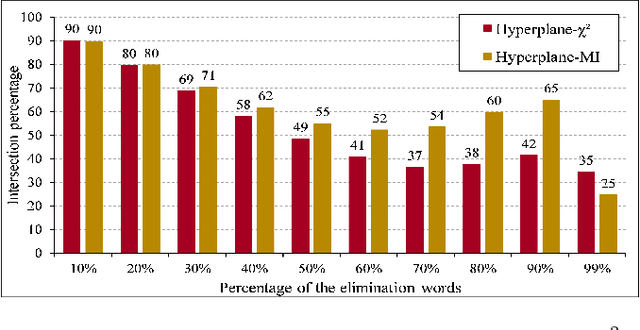
Text preprocessing is an essential step in text mining. Removing words that can negatively impact the quality of prediction algorithms or are not informative enough is a crucial storage-saving technique in text indexing and results in improved computational efficiency. Typically, a generic stop word list is applied to a dataset regardless of the domain. However, many common words are different from one domain to another but have no significance within a particular domain. Eliminating domain-specific common words in a corpus reduces the dimensionality of the feature space, and improves the performance of text mining tasks. In this paper, we present a novel mathematical approach for the automatic extraction of domain-specific words called the hyperplane-based approach. This new approach depends on the notion of low dimensional representation of the word in vector space and its distance from hyperplane. The hyperplane-based approach can significantly reduce text dimensionality by eliminating irrelevant features. We compare the hyperplane-based approach with other feature selection methods, namely \c{hi}2 and mutual information. An experimental study is performed on three different datasets and five classification algorithms, and measure the dimensionality reduction and the increase in the classification performance. Results indicate that the hyperplane-based approach can reduce the dimensionality of the corpus by 90% and outperforms mutual information. The computational time to identify the domain-specific words is significantly lower than mutual information.
Experimental Design for Regret Minimization in Linear Bandits
Nov 01, 2020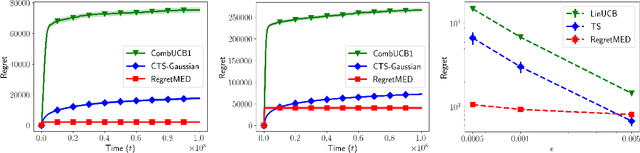

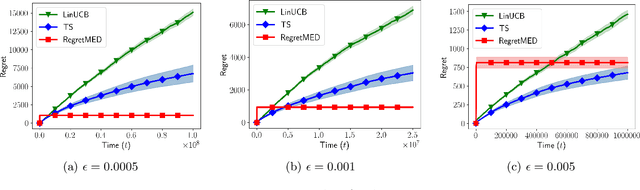
In this paper we propose a novel experimental design-based algorithm to minimize regret in online stochastic linear and combinatorial bandits. While existing literature tends to focus on optimism-based algorithms--which have been shown to be suboptimal in many cases--our approach carefully plans which action to take by balancing the tradeoff between information gain and reward, overcoming the failures of optimism. In addition, we leverage tools from the theory of suprema of empirical processes to obtain regret guarantees that scale with the Gaussian width of the action set, avoiding wasteful union bounds. We provide state-of-the-art finite time regret guarantees and show that our algorithm can be applied in both the bandit and semi-bandit feedback regime. In the combinatorial semi-bandit setting, we show that our algorithm is computationally efficient and relies only on calls to a linear maximization oracle. In addition, we show that with slight modification our algorithm can be used for pure exploration, obtaining state-of-the-art pure exploration guarantees in the semi-bandit setting. Finally, we provide, to the best of our knowledge, the first example where optimism fails in the semi-bandit regime, and show that in this setting our algorithm succeeds.
Statistical Query Lower Bounds for Tensor PCA
Aug 10, 2020In the Tensor PCA problem introduced by Richard and Montanari (2014), one is given a dataset consisting of $n$ samples $\mathbf{T}_{1:n}$ of i.i.d. Gaussian tensors of order $k$ with the promise that $\mathbb{E}\mathbf{T}_1$ is a rank-1 tensor and $\|\mathbb{E} \mathbf{T}_1\| = 1$. The goal is to estimate $\mathbb{E} \mathbf{T}_1$. This problem exhibits a large conjectured hard phase when $k>2$: When $d \lesssim n \ll d^{\frac{k}{2}}$ it is information theoretically possible to estimate $\mathbb{E} \mathbf{T}_1$, but no polynomial time estimator is known. We provide a sharp analysis of the optimal sample complexity in the Statistical Query (SQ) model and show that SQ algorithms with polynomial query complexity not only fail to solve Tensor PCA in the conjectured hard phase, but also have a strictly sub-optimal sample complexity compared to some polynomial time estimators such as the Richard-Montanari spectral estimator. Our analysis reveals that the optimal sample complexity in the SQ model depends on whether $\mathbb{E} \mathbf{T}_1$ is symmetric or not. For symmetric, even order tensors, we also isolate a sample size regime in which it is possible to test if $\mathbb{E} \mathbf{T}_1 = \mathbf{0}$ or $\mathbb{E}\mathbf{T}_1 \neq \mathbf{0}$ with polynomially many queries but not estimate $\mathbb{E}\mathbf{T}_1$. Our proofs rely on the Fourier analytic approach of Feldman, Perkins and Vempala (2018) to prove sharp SQ lower bounds.
Designing Environments Conducive to Interpretable Robot Behavior
Jul 02, 2020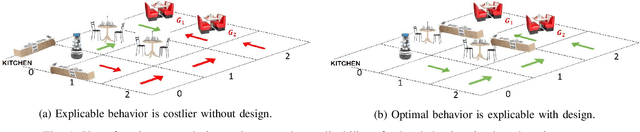
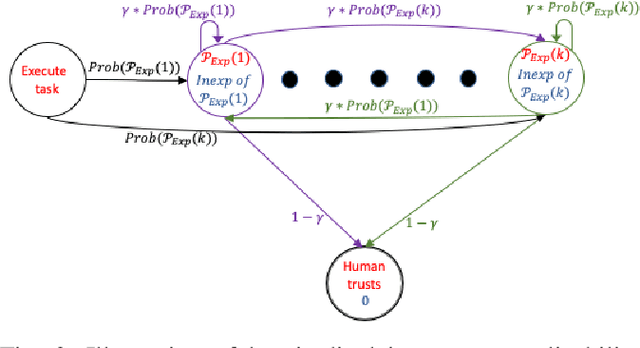
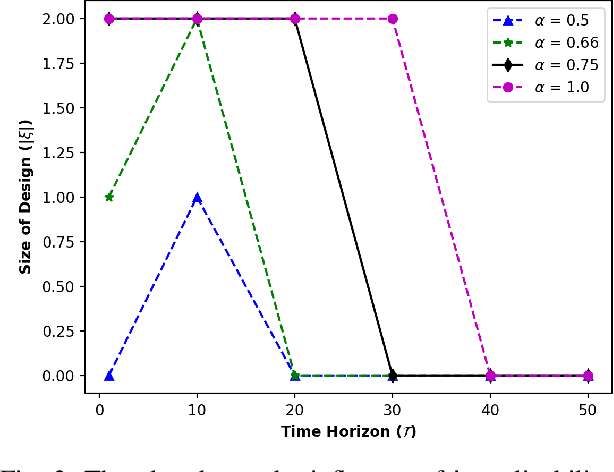
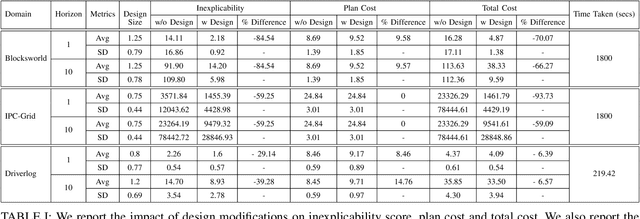
Designing robots capable of generating interpretable behavior is a prerequisite for achieving effective human-robot collaboration. This means that the robots need to be capable of generating behavior that aligns with human expectations and, when required, provide explanations to the humans in the loop. However, exhibiting such behavior in arbitrary environments could be quite expensive for robots, and in some cases, the robot may not even be able to exhibit the expected behavior. Given structured environments (like warehouses and restaurants), it may be possible to design the environment so as to boost the interpretability of the robot's behavior or to shape the human's expectations of the robot's behavior. In this paper, we investigate the opportunities and limitations of environment design as a tool to promote a type of interpretable behavior -- known in the literature as explicable behavior. We formulate a novel environment design framework that considers design over multiple tasks and over a time horizon. In addition, we explore the longitudinal aspect of explicable behavior and the trade-off that arises between the cost of design and the cost of generating explicable behavior over a time horizon.