 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Planning with Explicit Latent Transitions
Feb 04, 2026Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain's transitions, while transfer across domain boundaries remains a bottleneck.
Data-Driven Goal Recognition Design for General Behavioral Agents
Apr 03, 2024Goal recognition design aims to make limited modifications to decision-making environments with the goal of making it easier to infer the goals of agents acting within those environments. Although various research efforts have been made in goal recognition design, existing approaches are computationally demanding and often assume that agents are (near-)optimal in their decision-making. To address these limitations, we introduce a data-driven approach to goal recognition design that can account for agents with general behavioral models. Following existing literature, we use worst-case distinctiveness ($\textit{wcd}$) as a measure of the difficulty in inferring the goal of an agent in a decision-making environment. Our approach begins by training a machine learning model to predict the $\textit{wcd}$ for a given environment and the agent behavior model. We then propose a gradient-based optimization framework that accommodates various constraints to optimize decision-making environments for enhanced goal recognition. Through extensive simulations, we demonstrate that our approach outperforms existing methods in reducing $\textit{wcd}$ and enhancing runtime efficiency in conventional setups, and it also adapts to scenarios not previously covered in the literature, such as those involving flexible budget constraints, more complex environments, and suboptimal agent behavior. Moreover, we have conducted human-subject experiments which confirm that our method can create environments that facilitate efficient goal recognition from real-world human decision-makers.
Selectively Sharing Experiences Improves Multi-Agent Reinforcement Learning
Nov 01, 2023We present a novel multi-agent RL approach, Selective Multi-Agent Prioritized Experience Relay, in which agents share with other agents a limited number of transitions they observe during training. The intuition behind this is that even a small number of relevant experiences from other agents could help each agent learn. Unlike many other multi-agent RL algorithms, this approach allows for largely decentralized training, requiring only a limited communication channel between agents. We show that our approach outperforms baseline no-sharing decentralized training and state-of-the art multi-agent RL algorithms. Further, sharing only a small number of highly relevant experiences outperforms sharing all experiences between agents, and the performance uplift from selective experience sharing is robust across a range of hyperparameters and DQN variants. A reference implementation of our algorithm is available at https://github.com/mgerstgrasser/super.
Value of Assistance for Grasping
Oct 22, 2023In many realistic settings, a robot is tasked with grasping an object without knowing its exact pose. Instead, the robot relies on a probabilistic estimation of the pose to decide how to attempt the grasp. We offer a novel Value of Assistance (VOA) measure for assessing the expected effect a specific observation will have on the robot's ability to successfully complete the grasp. Thus, VOA supports the decision of which sensing action would be most beneficial to the grasping task. We evaluate our suggested measures in both simulated and real-world robotic settings.
Value of Assistance for Mobile Agents
Aug 23, 2023Mobile robotic agents often suffer from localization uncertainty which grows with time and with the agents' movement. This can hinder their ability to accomplish their task. In some settings, it may be possible to perform assistive actions that reduce uncertainty about a robot's location. For example, in a collaborative multi-robot system, a wheeled robot can request assistance from a drone that can fly to its estimated location and reveal its exact location on the map or accompany it to its intended location. Since assistance may be costly and limited, and may be requested by different members of a team, there is a need for principled ways to support the decision of which assistance to provide to an agent and when, as well as to decide which agent to help within a team. For this purpose, we propose Value of Assistance (VOA) to represent the expected cost reduction that assistance will yield at a given point of execution. We offer ways to compute VOA based on estimations of the robot's future uncertainty, modeled as a Gaussian process. We specify conditions under which our VOA measures are valid and empirically demonstrate the ability of our measures to predict the agent's average cost reduction when receiving assistance in both simulated and real-world robotic settings.
Contextual Pre-Planning on Reward Machine Abstractions for Enhanced Transfer in Deep Reinforcement Learning
Jul 11, 2023Recent studies show that deep reinforcement learning (DRL) agents tend to overfit to the task on which they were trained and fail to adapt to minor environment changes. To expedite learning when transferring to unseen tasks, we propose a novel approach to representing the current task using reward machines (RM), state machine abstractions that induce subtasks based on the current task's rewards and dynamics. Our method provides agents with symbolic representations of optimal transitions from their current abstract state and rewards them for achieving these transitions. These representations are shared across tasks, allowing agents to exploit knowledge of previously encountered symbols and transitions, thus enhancing transfer. Our empirical evaluation shows that our representations improve sample efficiency and few-shot transfer in a variety of domains.
Explainable Reinforcement Learning via Model Transforms
Sep 24, 2022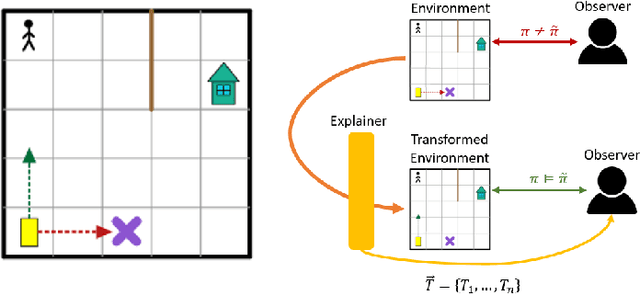
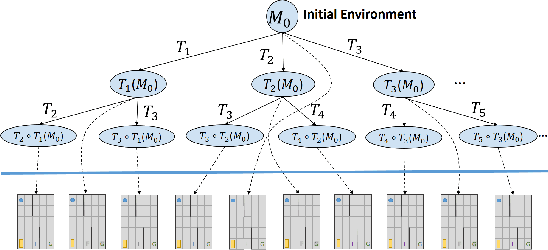
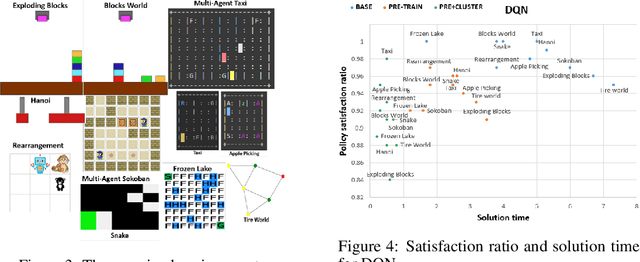
Understanding emerging behaviors of reinforcement learning (RL) agents may be difficult since such agents are often trained in complex environments using highly complex decision making procedures. This has given rise to a variety of approaches to explainability in RL that aim to reconcile discrepancies that may arise between the behavior of an agent and the behavior that is anticipated by an observer. Most recent approaches have relied either on domain knowledge, that may not always be available, on an analysis of the agent's policy, or on an analysis of specific elements of the underlying environment, typically modeled as a Markov Decision Process (MDP). Our key claim is that even if the underlying MDP is not fully known (e.g., the transition probabilities have not been accurately learned) or is not maintained by the agent (i.e., when using model-free methods), it can nevertheless be exploited to automatically generate explanations. For this purpose, we suggest using formal MDP abstractions and transforms, previously used in the literature for expediting the search for optimal policies, to automatically produce explanations. Since such transforms are typically based on a symbolic representation of the environment, they may represent meaningful explanations for gaps between the anticipated and actual agent behavior. We formally define this problem, suggest a class of transforms that can be used for explaining emergent behaviors, and suggest methods that enable efficient search for an explanation. We demonstrate the approach on a set of standard benchmarks.
Promoting Resilience in Multi-Agent Reinforcement Learning via Confusion-Based Communication
Nov 12, 2021
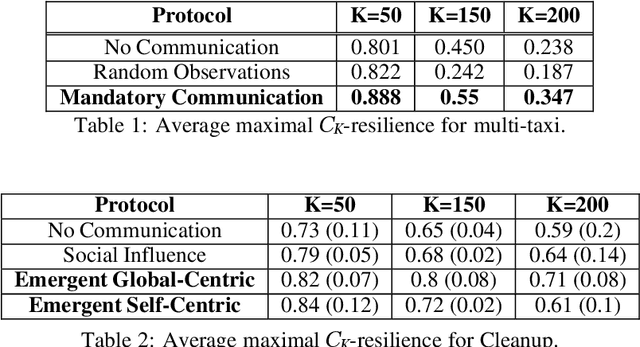
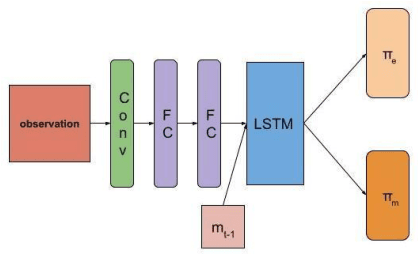
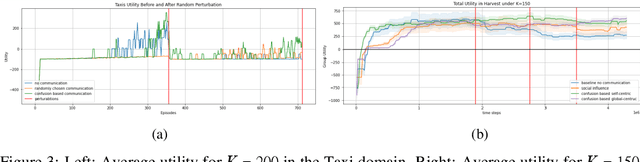
Recent advances in multi-agent reinforcement learning (MARL) provide a variety of tools that support the ability of agents to adapt to unexpected changes in their environment, and to operate successfully given their environment's dynamic nature (which may be intensified by the presence of other agents). In this work, we highlight the relationship between a group's ability to collaborate effectively and the group's resilience, which we measure as the group's ability to adapt to perturbations in the environment. To promote resilience, we suggest facilitating collaboration via a novel confusion-based communication protocol according to which agents broadcast observations that are misaligned with their previous experiences. We allow decisions regarding the width and frequency of messages to be learned autonomously by agents, which are incentivized to reduce confusion. We present empirical evaluation of our approach in a variety of MARL settings.
Designing Environments Conducive to Interpretable Robot Behavior
Jul 02, 2020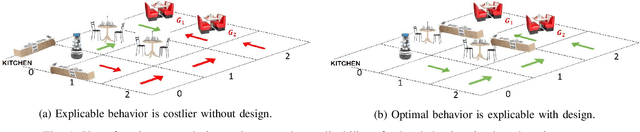
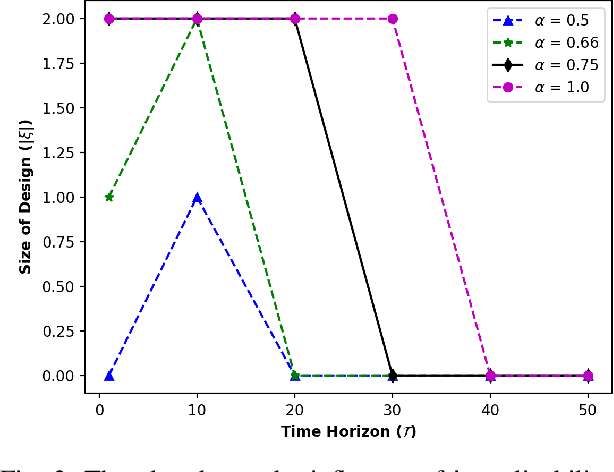
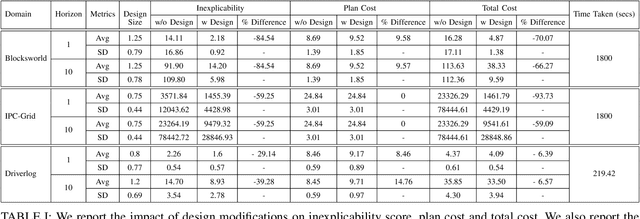
Designing robots capable of generating interpretable behavior is a prerequisite for achieving effective human-robot collaboration. This means that the robots need to be capable of generating behavior that aligns with human expectations and, when required, provide explanations to the humans in the loop. However, exhibiting such behavior in arbitrary environments could be quite expensive for robots, and in some cases, the robot may not even be able to exhibit the expected behavior. Given structured environments (like warehouses and restaurants), it may be possible to design the environment so as to boost the interpretability of the robot's behavior or to shape the human's expectations of the robot's behavior. In this paper, we investigate the opportunities and limitations of environment design as a tool to promote a type of interpretable behavior -- known in the literature as explicable behavior. We formulate a novel environment design framework that considers design over multiple tasks and over a time horizon. In addition, we explore the longitudinal aspect of explicable behavior and the trade-off that arises between the cost of design and the cost of generating explicable behavior over a time horizon.