 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A New Mathematical Model for Controlled Pandemics Like COVID-19 : AI Implemented Predictions
Aug 24, 2020
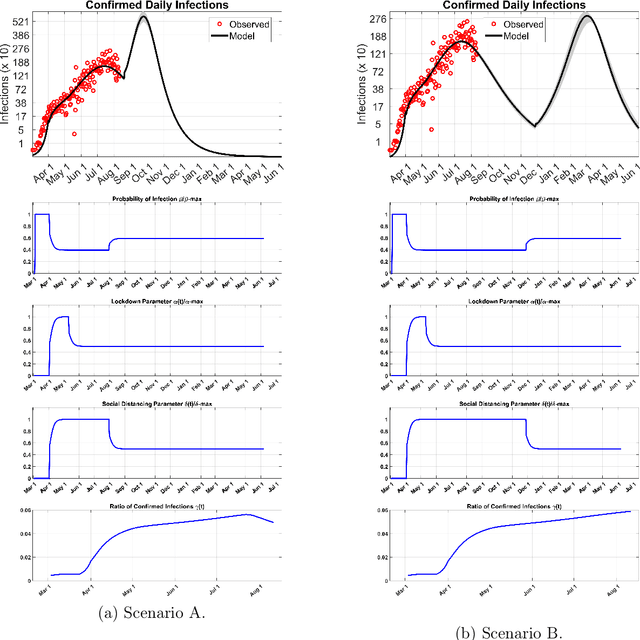
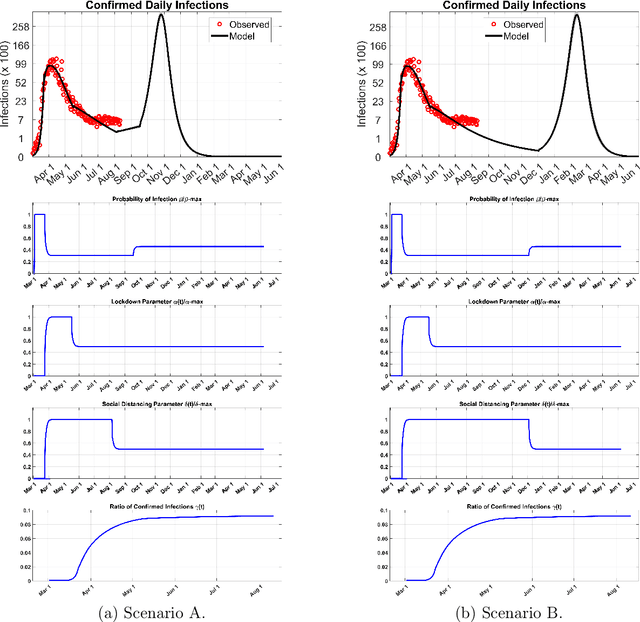
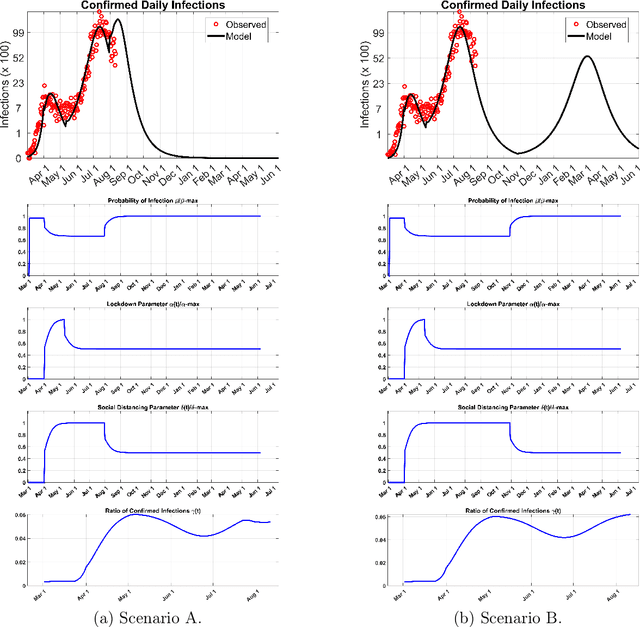
We present a new mathematical model to explicitly capture the effects that the three restriction measures: the lockdown date and duration, social distancing and masks, and, schools and border closing, have in controlling the spread of COVID-19 infections $i(r, t)$. Before restrictions were introduced, the random spread of infections as described by the SEIR model grew exponentially. The addition of control measures introduces a mixing of order and disorder in the system's evolution which fall under a different mathematical class of models that can eventually lead to critical phenomena. A generic analytical solution is hard to obtain. We use machine learning to solve the new equations for $i(r,t)$, the infections $i$ in any region $r$ at time $t$ and derive predictions for the spread of infections over time as a function of the strength of the specific measure taken and their duration. The machine is trained in all of the COVID-19 published data for each region, county, state, and country in the world. It utilizes optimization to learn the best-fit values of the model's parameters from past data in each region in the world, and it updates the predicted infections curves for any future restrictions that may be added or relaxed anywhere. We hope this interdisciplinary effort, a new mathematical model that predicts the impact of each measure in slowing down infection spread combined with the solving power of machine learning, is a useful tool in the fight against the current pandemic and potentially future ones.
A Maximum Independent Set Method for Scheduling Earth Observing Satellite Constellations
Aug 15, 2020
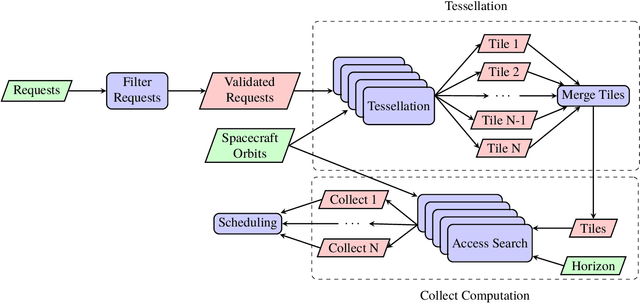
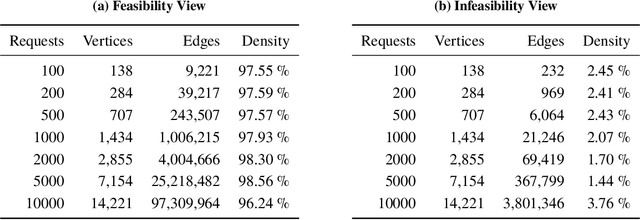
Operating Earth observing satellites requires efficient planning methods that coordinate activities of multiple spacecraft. The satellite task planning problem entails selecting actions that best satisfy mission objectives for autonomous execution. Task scheduling is often performed by human operators assisted by heuristic or rule-based planning tools. This approach does not efficiently scale to multiple assets as heuristics frequently fail to properly coordinate actions of multiple vehicles over long horizons. Additionally, the problem becomes more difficult to solve for large constellations as the complexity of the problem scales exponentially in the number of requested observations and linearly in the number of spacecraft. It is expected that new commercial optical and radar imaging constellations will require automated planning methods to meet stated responsiveness and throughput objectives. This paper introduces a new approach for solving the satellite scheduling problem by generating an infeasibility-based graph representation of the problem and finding a maximal independent set of vertices for the graph. The approach is tested on a scenarios of up to 10,000 requested imaging locations for the Skysat constellation of optical satellites as well as simulated constellations of up to 24 satellites. Performance is compared with contemporary graph-traversal and mixed-integer linear programming approaches. Empirical results demonstrate improvements in both the solution time along with the number of scheduled collections beyond baseline methods. For large problems, the maximum independent set approach is able find a feasible schedule with 8% more collections in 75% less time.
A Spectral Method for Activity Shaping in Continuous-Time Information Cascades
Sep 15, 2017
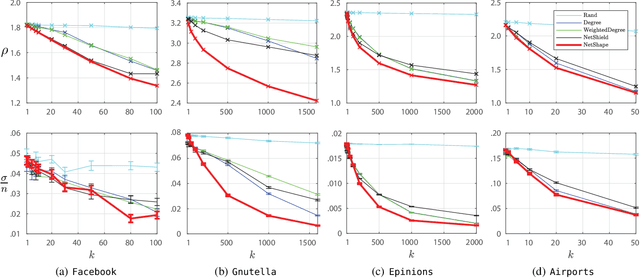
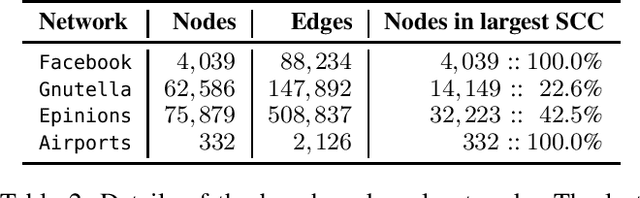
Information Cascades Model captures dynamical properties of user activity in a social network. In this work, we develop a novel framework for activity shaping under the Continuous-Time Information Cascades Model which allows the administrator for local control actions by allocating targeted resources that can alter the spread of the process. Our framework employs the optimization of the spectral radius of the Hazard matrix, a quantity that has been shown to drive the maximum influence in a network, while enjoying a simple convex relaxation when used to minimize the influence of the cascade. In addition, use-cases such as quarantine and node immunization are discussed to highlight the generality of the proposed activity shaping framework. Finally, we present the NetShape influence minimization method which is compared favorably to baseline and state-of-the-art approaches through simulations on real social networks.
Thinking While Moving: Deep Reinforcement Learning with Concurrent Control
Apr 13, 2020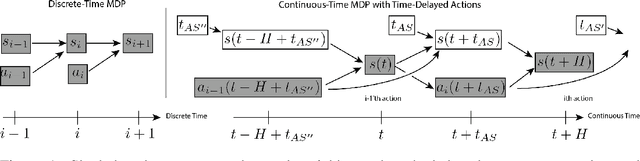
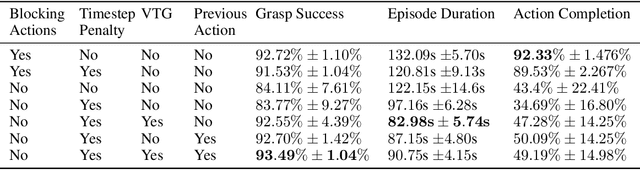
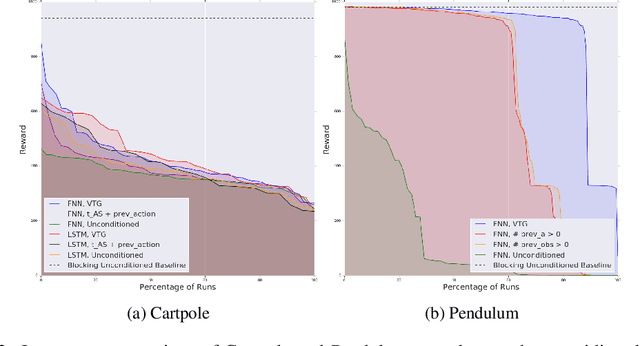

We study reinforcement learning in settings where sampling an action from the policy must be done concurrently with the time evolution of the controlled system, such as when a robot must decide on the next action while still performing the previous action. Much like a person or an animal, the robot must think and move at the same time, deciding on its next action before the previous one has completed. In order to develop an algorithmic framework for such concurrent control problems, we start with a continuous-time formulation of the Bellman equations, and then discretize them in a way that is aware of system delays. We instantiate this new class of approximate dynamic programming methods via a simple architectural extension to existing value-based deep reinforcement learning algorithms. We evaluate our methods on simulated benchmark tasks and a large-scale robotic grasping task where the robot must "think while moving".
Shallow-to-Deep Training for Neural Machine Translation
Oct 08, 2020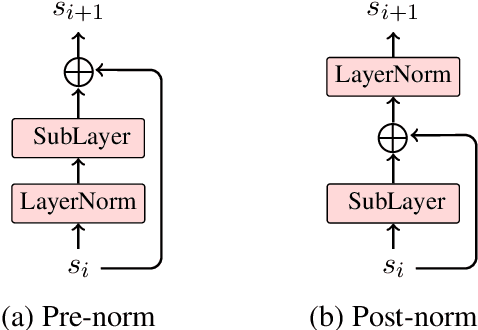
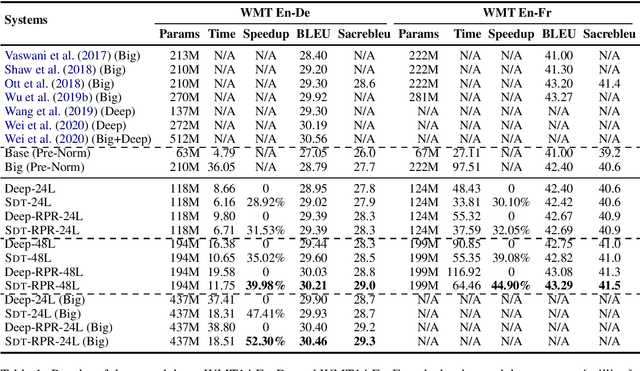
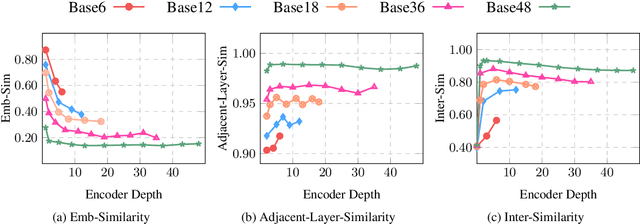

Deep encoders have been proven to be effective in improving neural machine translation (NMT) systems, but training an extremely deep encoder is time consuming. Moreover, why deep models help NMT is an open question. In this paper, we investigate the behavior of a well-tuned deep Transformer system. We find that stacking layers is helpful in improving the representation ability of NMT models and adjacent layers perform similarly. This inspires us to develop a shallow-to-deep training method that learns deep models by stacking shallow models. In this way, we successfully train a Transformer system with a 54-layer encoder. Experimental results on WMT'16 English-German and WMT'14 English-French translation tasks show that it is $1.4$ $\times$ faster than training from scratch, and achieves a BLEU score of $30.33$ and $43.29$ on two tasks. The code is publicly available at https://github.com/libeineu/SDT-Training/.
Reasoning at the Right Time Granularity
Jun 20, 2012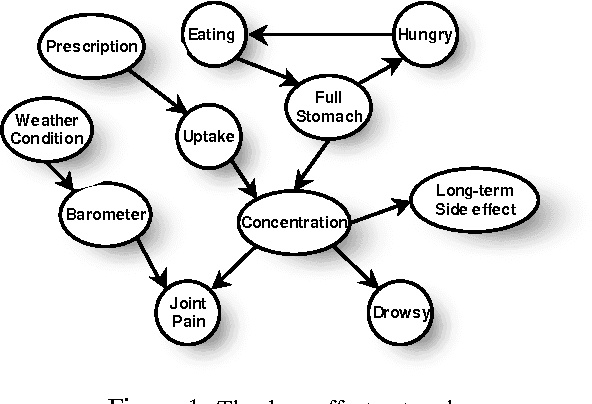
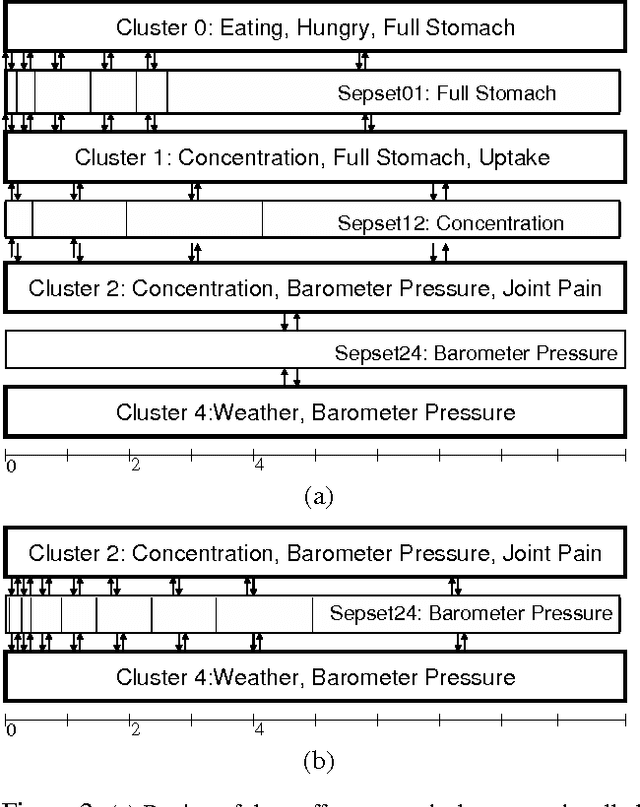
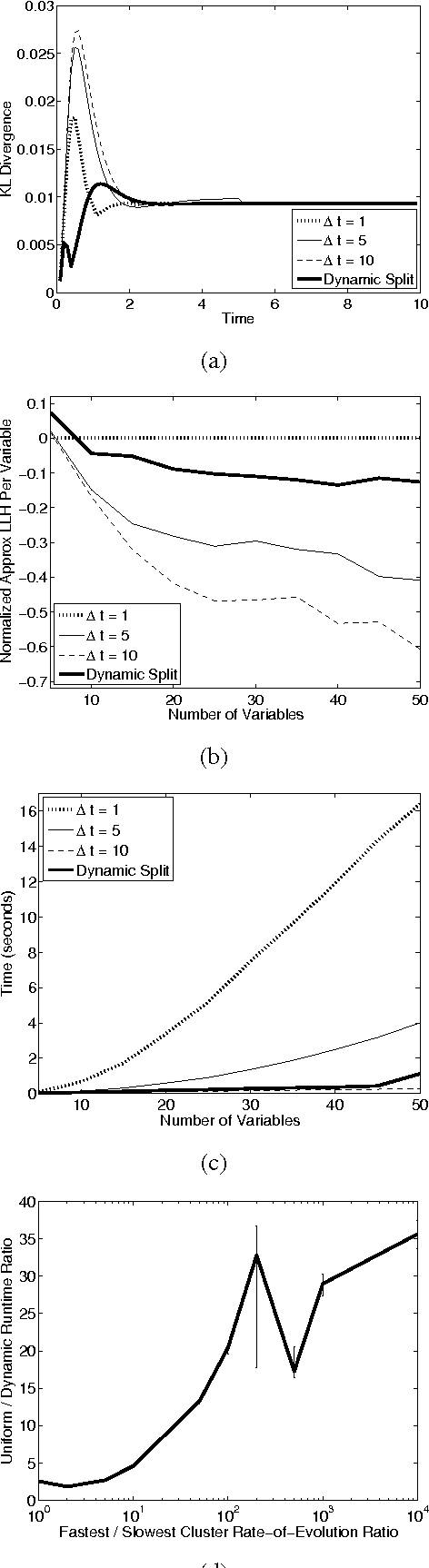
Most real-world dynamic systems are composed of different components that often evolve at very different rates. In traditional temporal graphical models, such as dynamic Bayesian networks, time is modeled at a fixed granularity, generally selected based on the rate at which the fastest component evolves. Inference must then be performed at this fastest granularity, potentially at significant computational cost. Continuous Time Bayesian Networks (CTBNs) avoid time-slicing in the representation by modeling the system as evolving continuously over time. The expectation-propagation (EP) inference algorithm of Nodelman et al. (2005) can then vary the inference granularity over time, but the granularity is uniform across all parts of the system, and must be selected in advance. In this paper, we provide a new EP algorithm that utilizes a general cluster graph architecture where clusters contain distributions that can overlap in both space (set of variables) and time. This architecture allows different parts of the system to be modeled at very different time granularities, according to their current rate of evolution. We also provide an information-theoretic criterion for dynamically re-partitioning the clusters during inference to tune the level of approximation to the current rate of evolution. This avoids the need to hand-select the appropriate granularity, and allows the granularity to adapt as information is transmitted across the network. We present experiments demonstrating that this approach can result in significant computational savings.
High Quality Remote Sensing Image Super-Resolution Using Deep Memory Connected Network
Oct 01, 2020
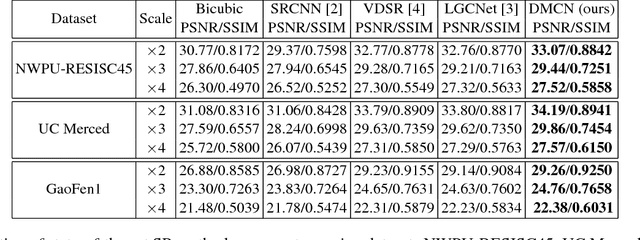
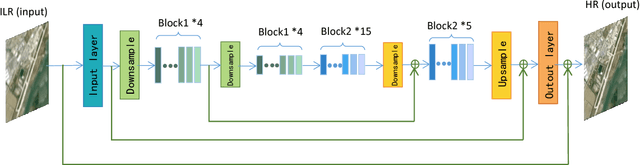

Single image super-resolution is an effective way to enhance the spatial resolution of remote sensing image, which is crucial for many applications such as target detection and image classification. However, existing methods based on the neural network usually have small receptive fields and ignore the image detail. We propose a novel method named deep memory connected network (DMCN) based on a convolutional neural network to reconstruct high-quality super-resolution images. We build local and global memory connections to combine image detail with environmental information. To further reduce parameters and ease time-consuming, we propose downsampling units, shrinking the spatial size of feature maps. We test DMCN on three remote sensing datasets with different spatial resolution. Experimental results indicate that our method yields promising improvements in both accuracy and visual performance over the current state-of-the-art.
GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
Mar 23, 2019
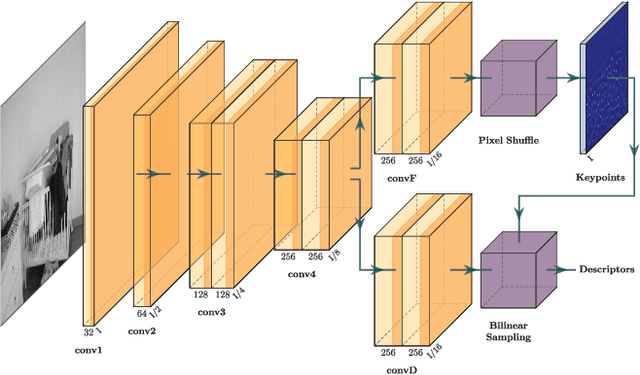
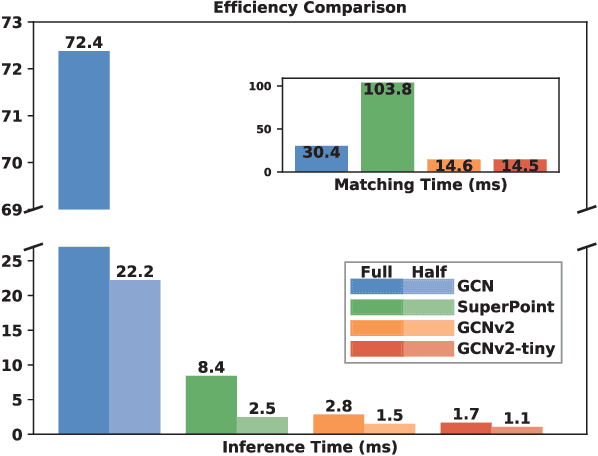
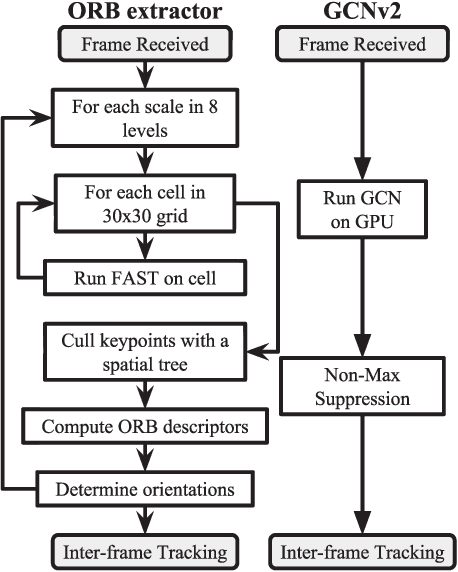
In this paper, we present a deep learning-based network, GCNv2, for generation of keypoints and descriptors. GCNv2 is built on our previous method, GCN, a network trained for 3D projective geometry. GCNv2 is designed with a binary descriptor vector as the ORB feature so that it can easily replace ORB in systems such as ORB-SLAM. GCNv2 significantly improves the computational efficiency over GCN that was only able to run on desktop hardware. We show how a modified version of ORB-SLAM using GCNv2 features runs on a Jetson TX2, an embdded low-power platform. Experimental results show that GCNv2 retains almost the same accuracy as GCN and that it is robust enough to use for control of a flying drone.
Generalized Grasping for Mechanical Grippers for Unknown Objects with Partial Point Cloud Representations
Jun 23, 2020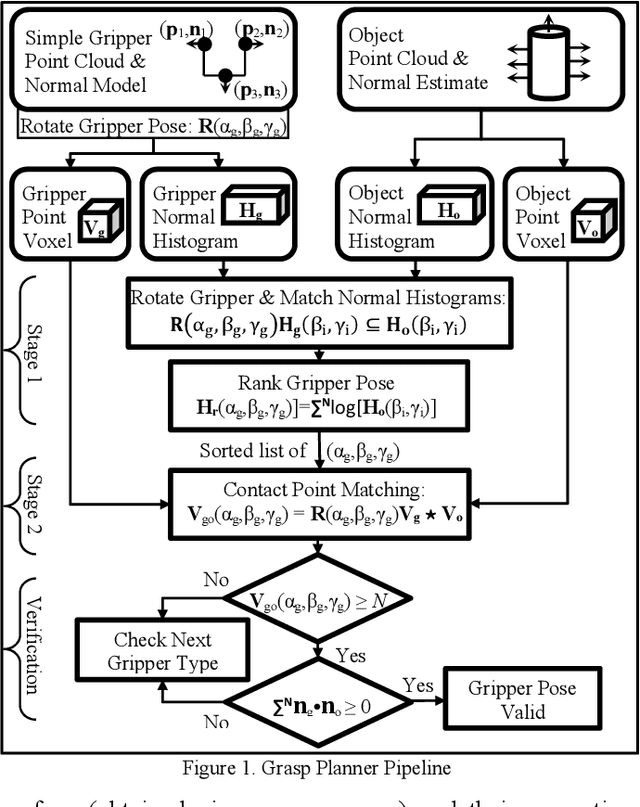
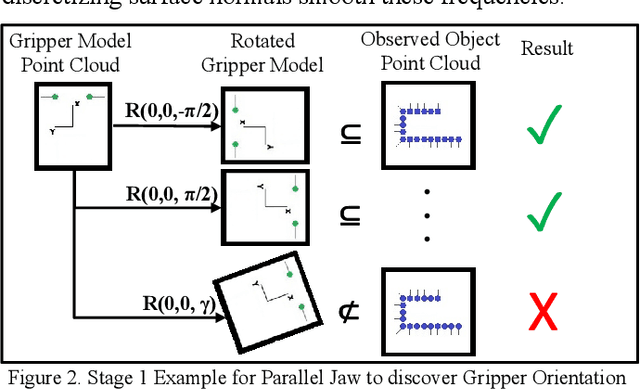
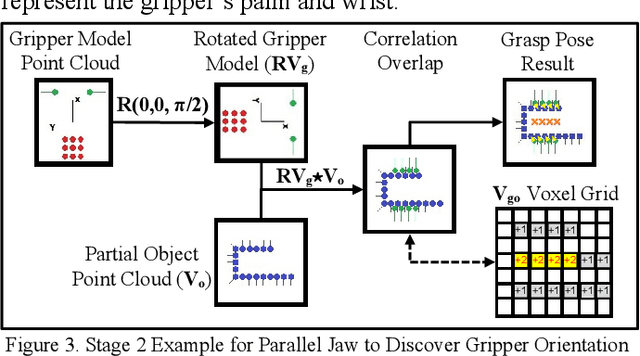
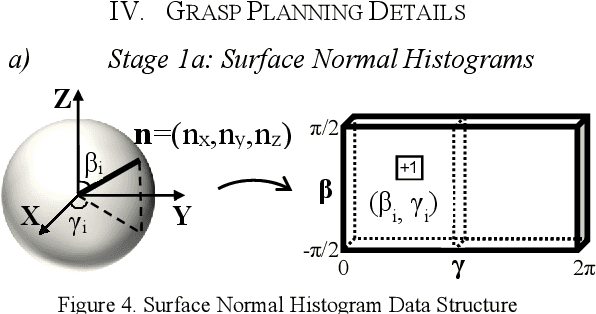
We present a generalized grasping algorithm that uses point clouds (i.e. a group of points and their respective surface normals) to discover grasp pose solutions for multiple grasp types, executed by a mechanical gripper, in near real-time. The algorithm introduces two ideas: 1) a histogram of finger contact normals is used to represent a grasp 'shape' to guide a gripper orientation search in a histogram of object(s) surface normals, and 2) voxel grid representations of gripper and object(s) are cross-correlated to match finger contact points, i.e. grasp 'size', to discover a grasp pose. Constraints, such as collisions with neighbouring objects, are optionally incorporated in the cross-correlation computation. We show via simulations and experiments that 1) grasp poses for three grasp types can be found in near real-time, 2) grasp pose solutions are consistent with respect to voxel resolution changes for both partial and complete point cloud scans, and 3) a planned grasp is executed with a mechanical gripper.
GraphFL: A Federated Learning Framework for Semi-Supervised Node Classification on Graphs
Dec 08, 2020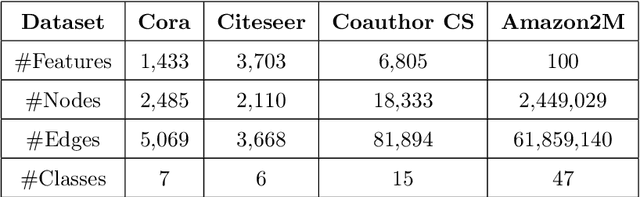
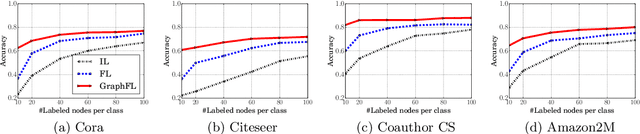
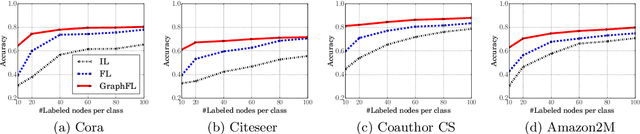
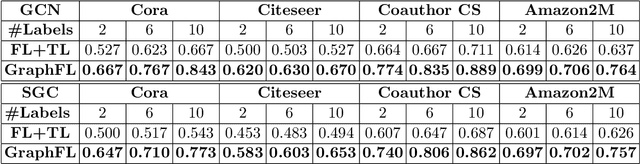
Graph-based semi-supervised node classification (GraphSSC) has wide applications, ranging from networking and security to data mining and machine learning, etc. However, existing centralized GraphSSC methods are impractical to solve many real-world graph-based problems, as collecting the entire graph and labeling a reasonable number of labels is time-consuming and costly, and data privacy may be also violated. Federated learning (FL) is an emerging learning paradigm that enables collaborative learning among multiple clients, which can mitigate the issue of label scarcity and protect data privacy as well. Therefore, performing GraphSSC under the FL setting is a promising solution to solve real-world graph-based problems. However, existing FL methods 1) perform poorly when data across clients are non-IID, 2) cannot handle data with new label domains, and 3) cannot leverage unlabeled data, while all these issues naturally happen in real-world graph-based problems. To address the above issues, we propose the first FL framework, namely GraphFL, for semi-supervised node classification on graphs. Our framework is motivated by meta-learning methods. Specifically, we propose two GraphFL methods to respectively address the non-IID issue in graph data and handle the tasks with new label domains. Furthermore, we design a self-training method to leverage unlabeled graph data. We adopt representative graph neural networks as GraphSSC methods and evaluate GraphFL on multiple graph datasets. Experimental results demonstrate that GraphFL significantly outperforms the compared FL baseline and GraphFL with self-training can obtain better performance.