 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Approximate Vector-Jacobian Products for Efficient Backpropagation
Feb 16, 2026In this work we introduce methods to reduce the computational and memory costs of training deep neural networks. Our approach consists in replacing exact vector-jacobian products by randomized, unbiased approximations thereof during backpropagation. We provide a theoretical analysis of the trade-off between the number of epochs needed to achieve a target precision and the cost reduction for each epoch. We then identify specific unbiased estimates of vector-jacobian products for which we establish desirable optimality properties of minimal variance under sparsity constraints. Finally we provide in-depth experiments on multi-layer perceptrons, BagNets and Visual Transfomers architectures. These validate our theoretical results, and confirm the potential of our proposed unbiased randomized backpropagation approach for reducing the cost of deep learning.
Variance-Reduced $(\varepsilon,δ)-$Unlearning using Forget Set Gradients
Feb 16, 2026In machine unlearning, $(\varepsilon,δ)-$unlearning is a popular framework that provides formal guarantees on the effectiveness of the removal of a subset of training data, the forget set, from a trained model. For strongly convex objectives, existing first-order methods achieve $(\varepsilon,δ)-$unlearning, but they only use the forget set to calibrate injected noise, never as a direct optimization signal. In contrast, efficient empirical heuristics often exploit the forget samples (e.g., via gradient ascent) but come with no formal unlearning guarantees. We bridge this gap by presenting the Variance-Reduced Unlearning (VRU) algorithm. To the best of our knowledge, VRU is the first first-order algorithm that directly includes forget set gradients in its update rule, while provably satisfying ($(\varepsilon,δ)-$unlearning. We establish the convergence of VRU and show that incorporating the forget set yields strictly improved rates, i.e. a better dependence on the achieved error compared to existing first-order $(\varepsilon,δ)-$unlearning methods. Moreover, we prove that, in a low-error regime, VRU asymptotically outperforms any first-order method that ignores the forget set.Experiments corroborate our theory, showing consistent gains over both state-of-the-art certified unlearning methods and over empirical baselines that explicitly leverage the forget set.
Adaptive collaboration for online personalized distributed learning with heterogeneous clients
Jul 09, 2025We study the problem of online personalized decentralized learning with $N$ statistically heterogeneous clients collaborating to accelerate local training. An important challenge in this setting is to select relevant collaborators to reduce gradient variance while mitigating the introduced bias. To tackle this, we introduce a gradient-based collaboration criterion, allowing each client to dynamically select peers with similar gradients during the optimization process. Our criterion is motivated by a refined and more general theoretical analysis of the All-for-one algorithm, proved to be optimal in Even et al. (2022) for an oracle collaboration scheme. We derive excess loss upper-bounds for smooth objective functions, being either strongly convex, non-convex, or satisfying the Polyak-Lojasiewicz condition; our analysis reveals that the algorithm acts as a variance reduction method where the speed-up depends on a sufficient variance. We put forward two collaboration methods instantiating the proposed general schema; and we show that one variant preserves the optimality of All-for-one. We validate our results with experiments on synthetic and real datasets.
When to Forget? Complexity Trade-offs in Machine Unlearning
Feb 24, 2025Machine Unlearning (MU) aims at removing the influence of specific data points from a trained model, striving to achieve this at a fraction of the cost of full model retraining. In this paper, we analyze the efficiency of unlearning methods and establish the first upper and lower bounds on minimax computation times for this problem, characterizing the performance of the most efficient algorithm against the most difficult objective function. Specifically, for strongly convex objective functions and under the assumption that the forget data is inaccessible to the unlearning method, we provide a phase diagram for the unlearning complexity ratio -- a novel metric that compares the computational cost of the best unlearning method to full model retraining. The phase diagram reveals three distinct regimes: one where unlearning at a reduced cost is infeasible, another where unlearning is trivial because adding noise suffices, and a third where unlearning achieves significant computational advantages over retraining. These findings highlight the critical role of factors such as data dimensionality, the number of samples to forget, and privacy constraints in determining the practical feasibility of unlearning.
Random Sparse Lifts: Construction, Analysis and Convergence of finite sparse networks
Jan 10, 2025



We present a framework to define a large class of neural networks for which, by construction, training by gradient flow provably reaches arbitrarily low loss when the number of parameters grows. Distinct from the fixed-space global optimality of non-convex optimization, this new form of convergence, and the techniques introduced to prove such convergence, pave the way for a usable deep learning convergence theory in the near future, without overparameterization assumptions relating the number of parameters and training samples. We define these architectures from a simple computation graph and a mechanism to lift it, thus increasing the number of parameters, generalizing the idea of increasing the widths of multi-layer perceptrons. We show that architectures similar to most common deep learning models are present in this class, obtained by sparsifying the weight tensors of usual architectures at initialization. Leveraging tools of algebraic topology and random graph theory, we use the computation graph's geometry to propagate properties guaranteeing convergence to any precision for these large sparse models.
In-depth Analysis of Low-rank Matrix Factorisation in a Federated Setting
Sep 13, 2024



We analyze a distributed algorithm to compute a low-rank matrix factorization on $N$ clients, each holding a local dataset $\mathbf{S}^i \in \mathbb{R}^{n_i \times d}$, mathematically, we seek to solve $min_{\mathbf{U}^i \in \mathbb{R}^{n_i\times r}, \mathbf{V}\in \mathbb{R}^{d \times r} } \frac{1}{2} \sum_{i=1}^N \|\mathbf{S}^i - \mathbf{U}^i \mathbf{V}^\top\|^2_{\text{F}}$. Considering a power initialization of $\mathbf{V}$, we rewrite the previous smooth non-convex problem into a smooth strongly-convex problem that we solve using a parallel Nesterov gradient descent potentially requiring a single step of communication at the initialization step. For any client $i$ in $\{1, \dots, N\}$, we obtain a global $\mathbf{V}$ in $\mathbb{R}^{d \times r}$ common to all clients and a local variable $\mathbf{U}^i$ in $\mathbb{R}^{n_i \times r}$. We provide a linear rate of convergence of the excess loss which depends on $\sigma_{\max} / \sigma_{r}$, where $\sigma_{r}$ is the $r^{\mathrm{th}}$ singular value of the concatenation $\mathbf{S}$ of the matrices $(\mathbf{S}^i)_{i=1}^N$. This result improves the rates of convergence given in the literature, which depend on $\sigma_{\max}^2 / \sigma_{\min}^2$. We provide an upper bound on the Frobenius-norm error of reconstruction under the power initialization strategy. We complete our analysis with experiments on both synthetic and real data.
Generalization Error of First-Order Methods for Statistical Learning with Generic Oracles
Jul 11, 2023In this paper, we provide a novel framework for the analysis of generalization error of first-order optimization algorithms for statistical learning when the gradient can only be accessed through partial observations given by an oracle. Our analysis relies on the regularity of the gradient w.r.t. the data samples, and allows to derive near matching upper and lower bounds for the generalization error of multiple learning problems, including supervised learning, transfer learning, robust learning, distributed learning and communication efficient learning using gradient quantization. These results hold for smooth and strongly-convex optimization problems, as well as smooth non-convex optimization problems verifying a Polyak-Lojasiewicz assumption. In particular, our upper and lower bounds depend on a novel quantity that extends the notion of conditional standard deviation, and is a measure of the extent to which the gradient can be approximated by having access to the oracle. As a consequence, our analysis provides a precise meaning to the intuition that optimization of the statistical learning objective is as hard as the estimation of its gradient. Finally, we show that, in the case of standard supervised learning, mini-batch gradient descent with increasing batch sizes and a warm start can reach a generalization error that is optimal up to a multiplicative factor, thus motivating the use of this optimization scheme in practical applications.
Convergence beyond the over-parameterized regime using Rayleigh quotients
Jan 19, 2023In this paper, we present a new strategy to prove the convergence of deep learning architectures to a zero training (or even testing) loss by gradient flow. Our analysis is centered on the notion of Rayleigh quotients in order to prove Kurdyka-{\L}ojasiewicz inequalities for a broader set of neural network architectures and loss functions. We show that Rayleigh quotients provide a unified view for several convergence analysis techniques in the literature. Our strategy produces a proof of convergence for various examples of parametric learning. In particular, our analysis does not require the number of parameters to tend to infinity, nor the number of samples to be finite, thus extending to test loss minimization and beyond the over-parameterized regime.
Tight High Probability Bounds for Linear Stochastic Approximation with Fixed Stepsize
Jun 02, 2021This paper provides a non-asymptotic analysis of linear stochastic approximation (LSA) algorithms with fixed stepsize. This family of methods arises in many machine learning tasks and is used to obtain approximate solutions of a linear system $\bar{A}\theta = \bar{b}$ for which $\bar{A}$ and $\bar{b}$ can only be accessed through random estimates $\{({\bf A}_n, {\bf b}_n): n \in \mathbb{N}^*\}$. Our analysis is based on new results regarding moments and high probability bounds for products of matrices which are shown to be tight. We derive high probability bounds on the performance of LSA under weaker conditions on the sequence $\{({\bf A}_n, {\bf b}_n): n \in \mathbb{N}^*\}$ than previous works. However, in contrast, we establish polynomial concentration bounds with order depending on the stepsize. We show that our conclusions cannot be improved without additional assumptions on the sequence of random matrices $\{{\bf A}_n: n \in \mathbb{N}^*\}$, and in particular that no Gaussian or exponential high probability bounds can hold. Finally, we pay a particular attention to establishing bounds with sharp order with respect to the number of iterations and the stepsize and whose leading terms contain the covariance matrices appearing in the central limit theorems.
Lipschitz Normalization for Self-Attention Layers with Application to Graph Neural Networks
Mar 08, 2021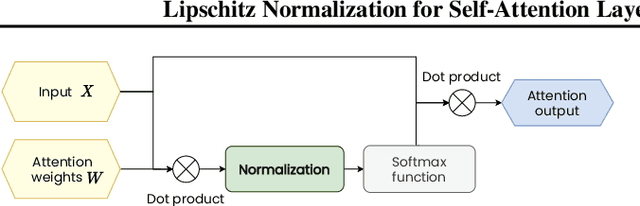

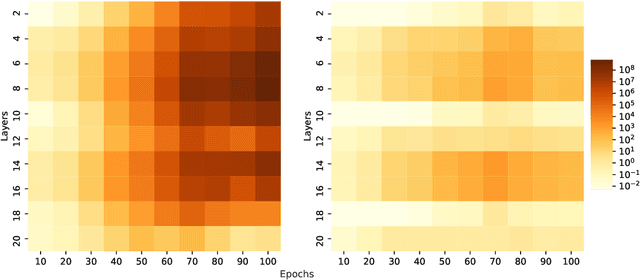
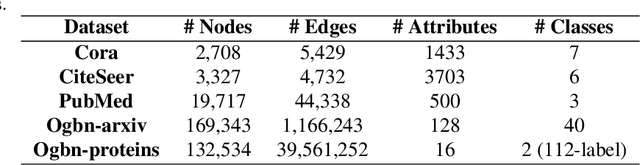
Attention based neural networks are state of the art in a large range of applications. However, their performance tends to degrade when the number of layers increases. In this work, we show that enforcing Lipschitz continuity by normalizing the attention scores can significantly improve the performance of deep attention models. First, we show that, for deep graph attention networks (GAT), gradient explosion appears during training, leading to poor performance of gradient-based training algorithms. To address this issue, we derive a theoretical analysis of the Lipschitz continuity of attention modules and introduce LipschitzNorm, a simple and parameter-free normalization for self-attention mechanisms that enforces the model to be Lipschitz continuous. We then apply LipschitzNorm to GAT and Graph Transformers and show that their performance is substantially improved in the deep setting (10 to 30 layers). More specifically, we show that a deep GAT model with LipschitzNorm achieves state of the art results for node label prediction tasks that exhibit long-range dependencies, while showing consistent improvements over their unnormalized counterparts in benchmark node classification tasks.