 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
Nov 25, 2020
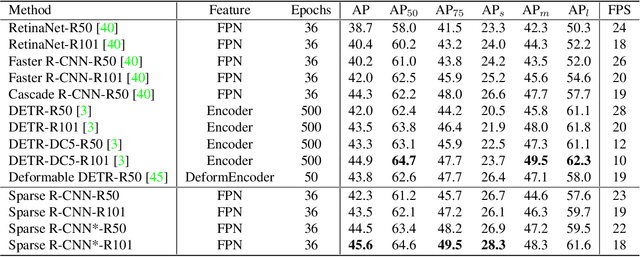
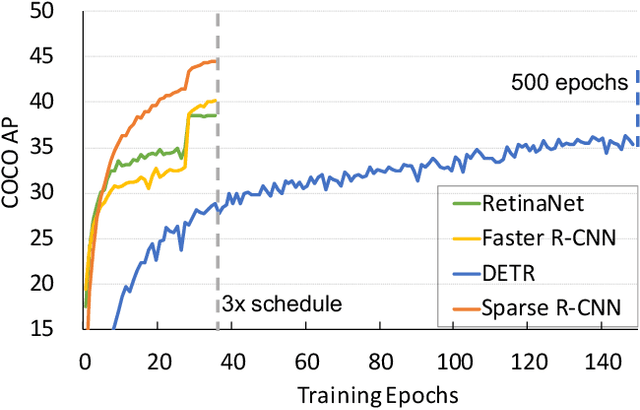

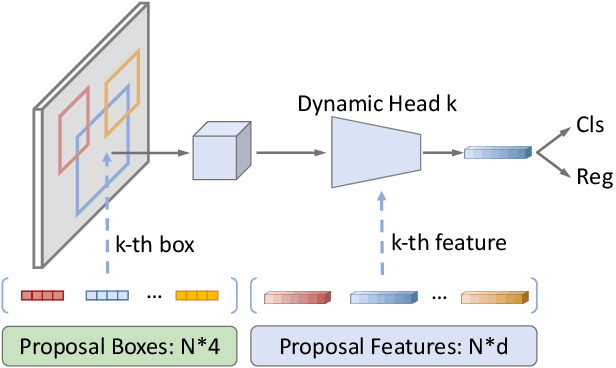
We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as $k$ anchor boxes pre-defined on all grids of image feature map of size $H\times W$. In our method, however, a fixed sparse set of learned object proposals, total length of $N$, are provided to object recognition head to perform classification and location. By eliminating $HWk$ (up to hundreds of thousands) hand-designed object candidates to $N$ (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 44.5 AP in standard $3\times$ training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors. The code is available at: https://github.com/PeizeSun/SparseR-CNN.
Summarizing Utterances from Japanese Assembly Minutes using Political Sentence-BERT-based Method for QA Lab-PoliInfo-2 Task of NTCIR-15
Oct 22, 2020
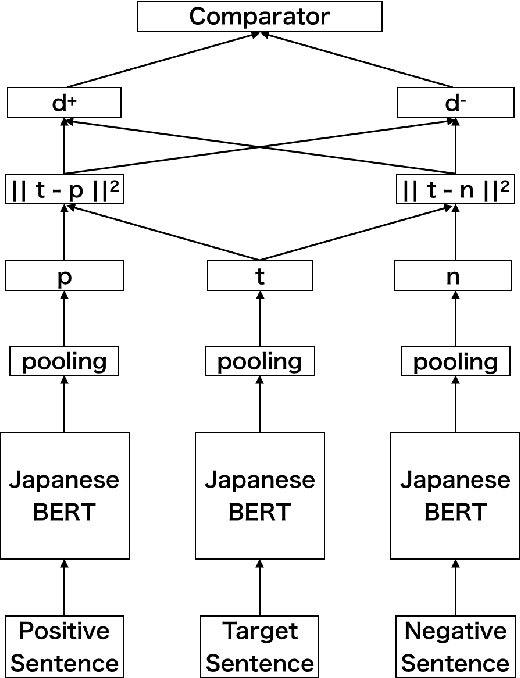
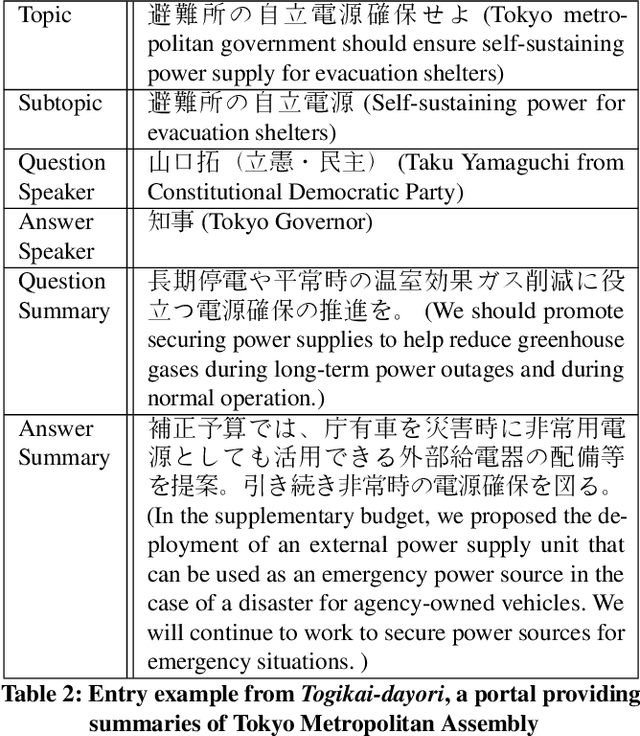

There are many discussions held during political meetings, and a large number of utterances for various topics is included in their transcripts. We need to read all of them if we want to follow speakers\' intentions or opinions about a given topic. To avoid such a costly and time-consuming process to grasp often longish discussions, NLP researchers work on generating concise summaries of utterances. Summarization subtask in QA Lab-PoliInfo-2 task of the NTCIR-15 addresses this problem for Japanese utterances in assembly minutes, and our team (SKRA) participated in this subtask. As a first step for summarizing utterances, we created a new pre-trained sentence embedding model, i.e. the Japanese Political Sentence-BERT. With this model, we summarize utterances without labelled data. This paper describes our approach to solving the task and discusses its results.
RotNet: Fast and Scalable Estimation of Stellar Rotation Periods Using Convolutional Neural Networks
Dec 04, 2020
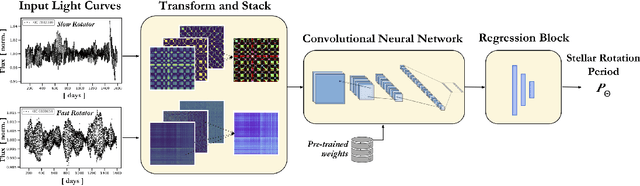
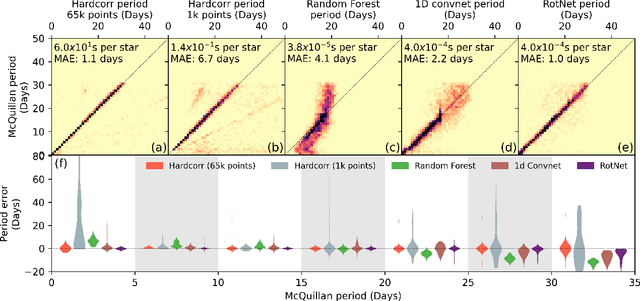
Magnetic activity in stars manifests as dark spots on their surfaces that modulate the brightness observed by telescopes. These light curves contain important information on stellar rotation. However, the accurate estimation of rotation periods is computationally expensive due to scarce ground truth information, noisy data, and large parameter spaces that lead to degenerate solutions. We harness the power of deep learning and successfully apply Convolutional Neural Networks to regress stellar rotation periods from Kepler light curves. Geometry-preserving time-series to image transformations of the light curves serve as inputs to a ResNet-18 based architecture which is trained through transfer learning. The McQuillan catalog of published rotation periods is used as ansatz to groundtruth. We benchmark the performance of our method against a random forest regressor, a 1D CNN, and the Auto-Correlation Function (ACF) - the current standard to estimate rotation periods. Despite limiting our input to fewer data points (1k), our model yields more accurate results and runs 350 times faster than ACF runs on the same number of data points and 10,000 times faster than ACF runs on 65k data points. With only minimal feature engineering our approach has impressive accuracy, motivating the application of deep learning to regress stellar parameters on an even larger scale
Stochastic sparse adversarial attacks
Nov 24, 2020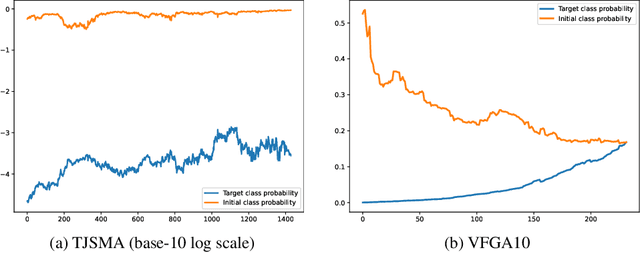
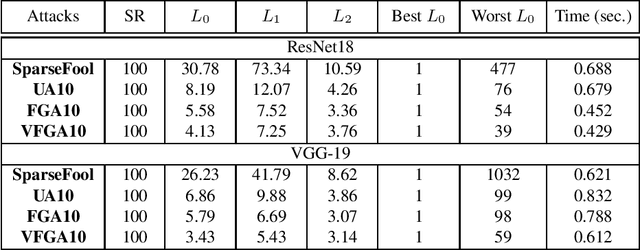

Adversarial attacks of neural network classifiers (NNC) and the use of random noises in these methods have stimulated a large number of works in recent years. However, despite all the previous investigations, existing approaches that rely on random noises to fool NNC have fallen far short of the-state-of-the-art adversarial methods performances. In this paper, we fill this gap by introducing stochastic sparse adversarial attacks (SSAA), standing as simple, fast and purely noise-based targeted and untargeted attacks of NNC. SSAA offer new examples of sparse (or $L_0$) attacks for which only few methods have been proposed previously. These attacks are devised by exploiting a small-time expansion idea widely used for Markov processes. Experiments on small and large datasets (CIFAR-10 and ImageNet) illustrate several advantages of SSAA in comparison with the-state-of-the-art methods. For instance, in the untargeted case, our method called voting folded Gaussian attack (VFGA) scales efficiently to ImageNet and achieves a significantly lower $L_0$ score than SparseFool (up to $\frac{1}{14}$ lower) while being faster. In the targeted setting, VFGA achives appealing results on ImageNet and is significantly much faster than Carlini-Wagner $L_0$ attack.
Bi-directional Domain Adaptation for Sim2Real Transfer of Embodied Navigation Agents
Nov 24, 2020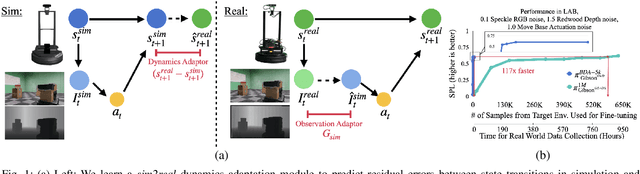


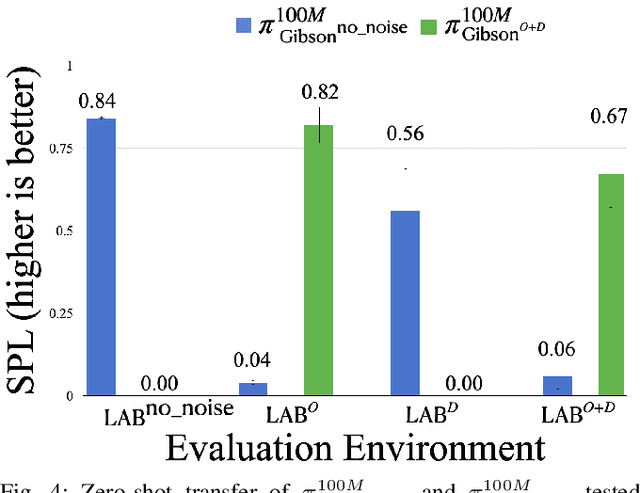
Deep reinforcement learning models are notoriously data hungry, yet real-world data is expensive and time consuming to obtain. The solution that many have turned to is to use simulation for training before deploying the robot in a real environment. Simulation offers the ability to train large numbers of robots in parallel, and offers an abundance of data. However, no simulation is perfect, and robots trained solely in simulation fail to generalize to the real-world, resulting in a "sim-vs-real gap". How can we overcome the trade-off between the abundance of less accurate, artificial data from simulators and the scarcity of reliable, real-world data? In this paper, we propose Bi-directional Domain Adaptation (BDA), a novel approach to bridge the sim-vs-real gap in both directions -- real2sim to bridge the visual domain gap, and sim2real to bridge the dynamics domain gap. We demonstrate the benefits of BDA on the task of PointGoal Navigation. BDA with only 5k real-world (state, action, next-state) samples matches the performance of a policy fine-tuned with ~600k samples, resulting in a speed-up of ~120x.
Online Domain Adaptation for Continuous Cross-Subject Liver Viability Evaluation Based on Irregular Thermal Data
Nov 24, 2020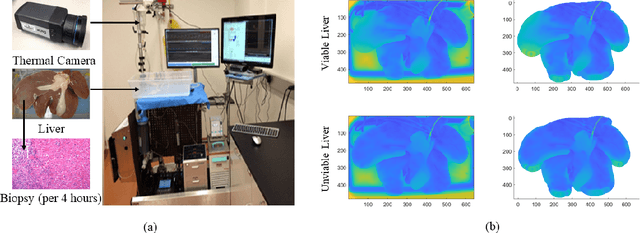

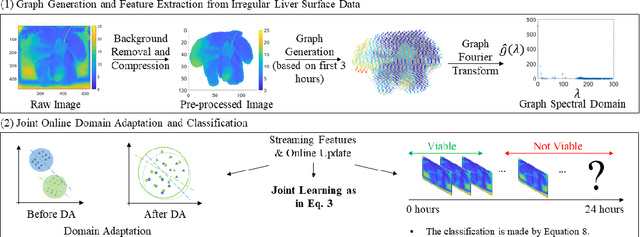
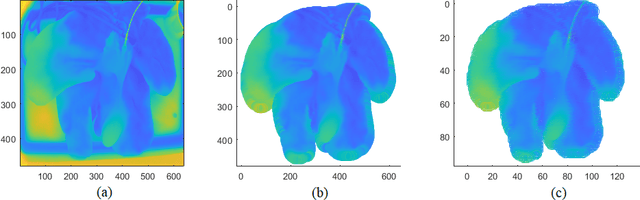
Accurate evaluation of liver viability during its procurement is a challenging issue and has traditionally been addressed by taking invasive biopsy on liver. Recently, people have started to investigate on the non-invasive evaluation of liver viability during its procurement using the liver surface thermal images. However, existing works include the background noise in the thermal images and do not consider the cross-subject heterogeneity of livers, thus the viability evaluation accuracy can be affected. In this paper, we propose to use the irregular thermal data of the pure liver region, and the cross-subject liver evaluation information (i.e., the available viability label information in cross-subject livers), for the real-time evaluation of a new liver's viability. To achieve this objective, we extract features of irregular thermal data based on tools from graph signal processing (GSP), and propose an online domain adaptation (DA) and classification framework using the GSP features of cross-subject livers. A multiconvex block coordinate descent based algorithm is designed to jointly learn the domain-invariant features during online DA and learn the classifier. Our proposed framework is applied to the liver procurement data, and classifies the liver viability accurately.
Motion Planning by Reinforcement Learning for an Unmanned Aerial Vehicle in Virtual Open Space with Static Obstacles
Sep 24, 2020

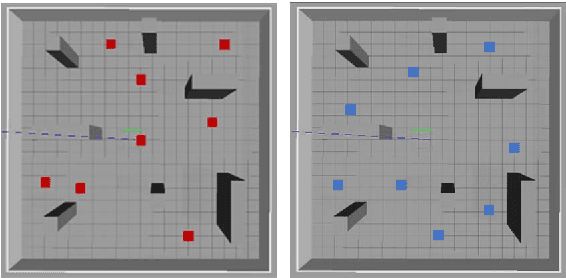

In this study, we applied reinforcement learning based on the proximal policy optimization algorithm to perform motion planning for an unmanned aerial vehicle (UAV) in an open space with static obstacles. The application of reinforcement learning through a real UAV has several limitations such as time and cost; thus, we used the Gazebo simulator to train a virtual quadrotor UAV in a virtual environment. As the reinforcement learning progressed, the mean reward and goal rate of the model were increased. Furthermore, the test of the trained model shows that the UAV reaches the goal with an 81% goal rate using the simple reward function suggested in this work.
Machine learning on Crays to optimise petrophysical workflows in oil and gas exploration
Oct 01, 2020The oil and gas industry is awash with sub-surface data, which is used to characterize the rock and fluid properties beneath the seabed. This in turn drives commercial decision making and exploration, but the industry currently relies upon highly manual workflows when processing data. A key question is whether this can be improved using machine learning to complement the activities of petrophysicists searching for hydrocarbons. In this paper we present work done, in collaboration with Rock Solid Images (RSI), using supervised machine learning on a Cray XC30 to train models that streamline the manual data interpretation process. With a general aim of decreasing the petrophysical interpretation time down from over 7 days to 7 minutes, in this paper we describe the use of mathematical models that have been trained using raw well log data, for completing each of the four stages of a petrophysical interpretation workflow, along with initial data cleaning. We explore how the predictions from these models compare against the interpretations of human petrophysicists, along with numerous options and techniques that were used to optimise the prediction of our models. The power provided by modern supercomputers such as Cray machines is crucial here, but some popular machine learning framework are unable to take full advantage of modern HPC machines. As such we will also explore the suitability of the machine learning tools we have used, and describe steps we took to work round their limitations. The result of this work is the ability, for the first time, to use machine learning for the entire petrophysical workflow. Whilst there are numerous challenges, limitations and caveats, we demonstrate that machine learning has an important role to play in the processing of sub-surface data.
CellCycleGAN: Spatiotemporal Microscopy Image Synthesis of Cell Populations using Statistical Shape Models and Conditional GANs
Oct 22, 2020
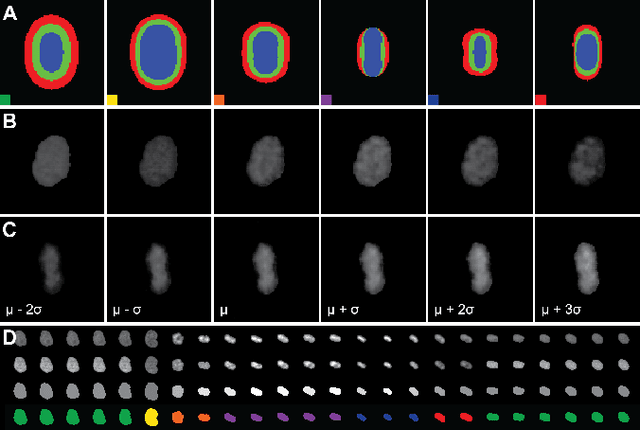
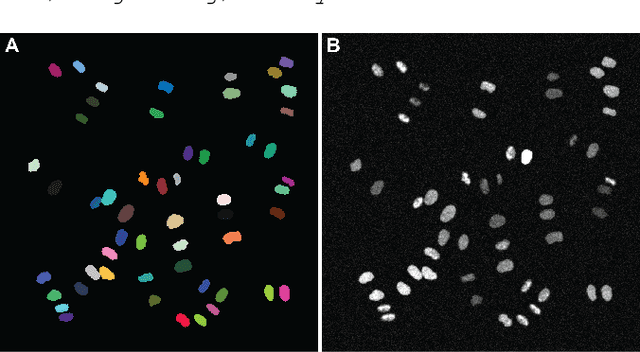
Automatic analysis of spatio-temporal microscopy images is inevitable for state-of-the-art research in the life sciences. Recent developments in deep learning provide powerful tools for automatic analyses of such image data, but heavily depend on the amount and quality of provided training data to perform well. To this end, we developed a new method for realistic generation of synthetic 2D+t microscopy image data of fluorescently labeled cellular nuclei. The method combines spatiotemporal statistical shape models of different cell cycle stages with a conditional GAN to generate time series of cell populations and provides instance-level control of cell cycle stage and the fluorescence intensity of generated cells. We show the effect of the GAN conditioning and create a set of synthetic images that can be readily used for training and benchmarking of cell segmentation and tracking approaches.
Overlapping Schwarz Decomposition for Nonlinear Optimal Control
May 15, 2020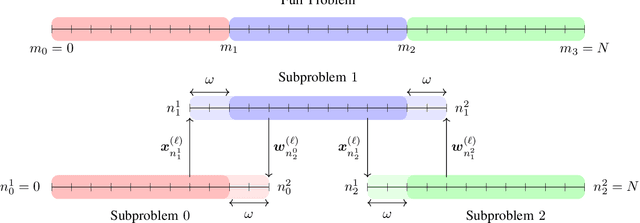
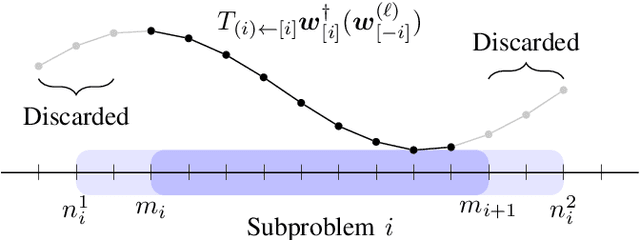
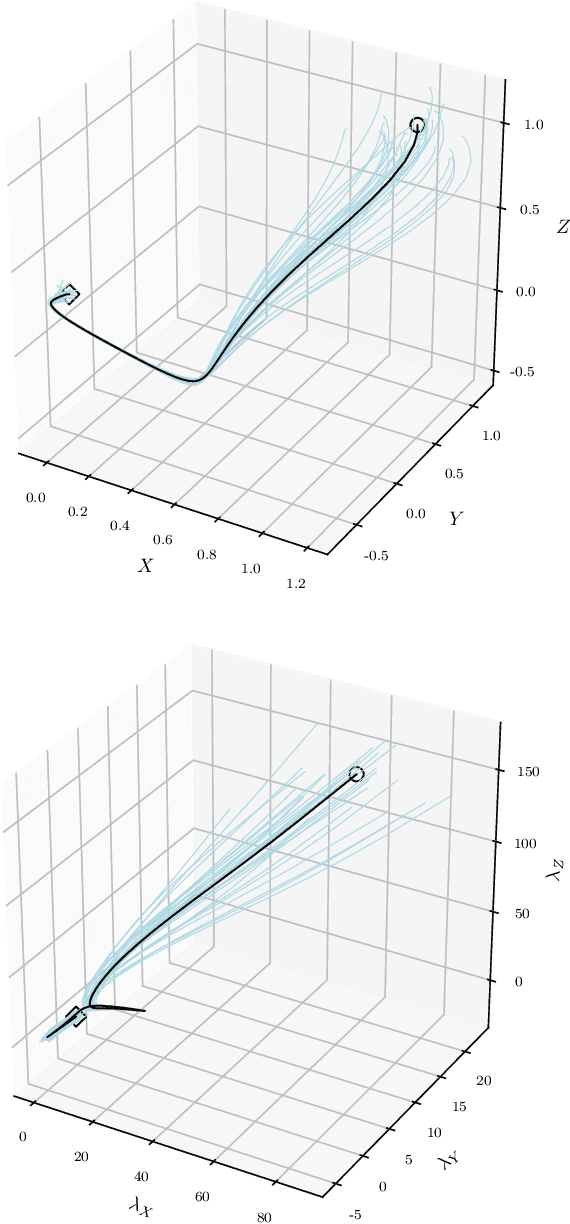
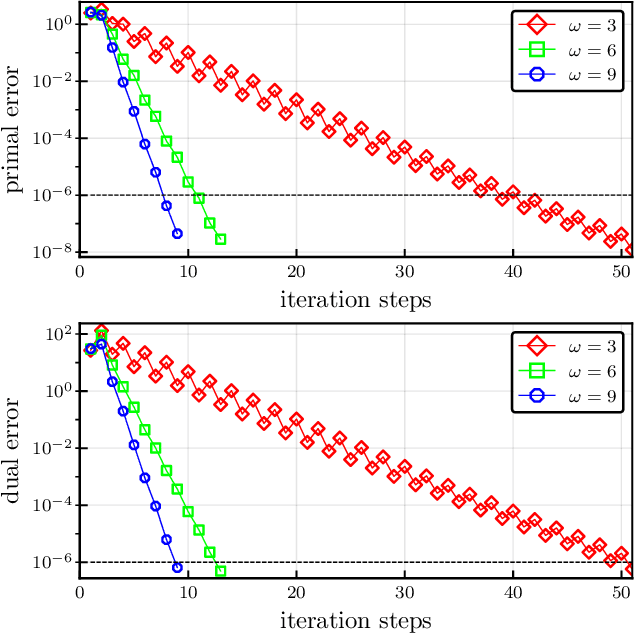
We present an overlapping Schwarz decomposition algorithm for solving nonlinear optimal control problems (OCPs). Our approach decomposes the time domain into a set of overlapping subdomains and solves subproblems defined over such subdomains in parallel. Convergence is attained by updating primal-dual information at the boundaries of the overlapping regions. We show that the algorithm exhibits local convergence and that the convergence rate improves exponentially with the size of the overlap. Our convergence results rely on a sensitivity result for OCPs that we call "asymptotic decay of sensitivity." Intuitively, this result states that impact of parametric perturbations at the boundaries of the time domain (initial and final time) decays exponentially as one moves away from the perturbation points. We show that this condition holds for nonlinear OCPs under a uniform second-order sufficient condition, a controllability condition, and a uniform boundedness condition. The approach is demonstrated by using a highly nonlinear quadrotor motion planning problem.