 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing machine learning to reduce ensembles of geological models for oil and gas exploration
Oct 17, 2020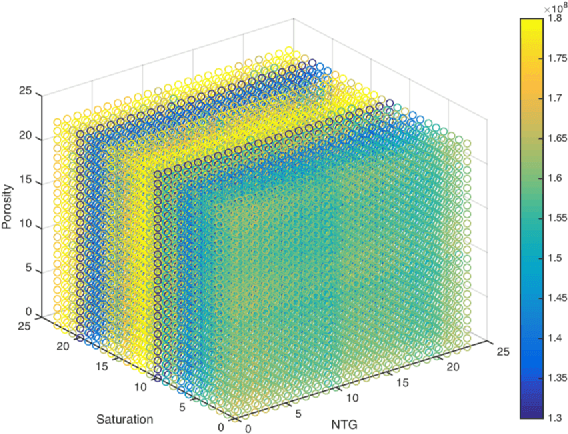
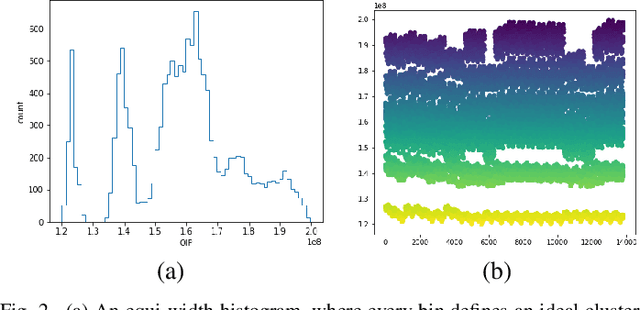
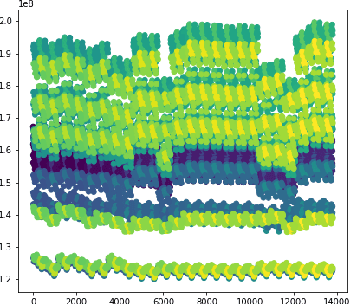
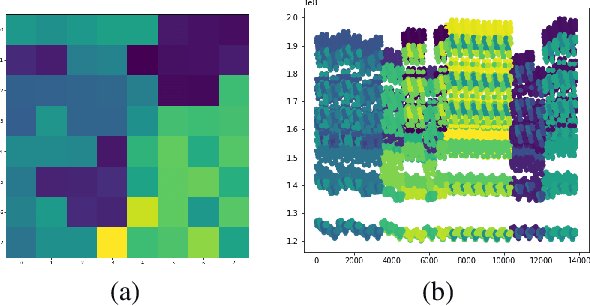
Exploration using borehole drilling is a key activity in determining the most appropriate locations for the petroleum industry to develop oil fields. However, estimating the amount of Oil In Place (OIP) relies on computing with a very significant number of geological models, which, due to the ever increasing capability to capture and refine data, is becoming infeasible. As such, data reduction techniques are required to reduce this set down to a smaller, yet still fully representative ensemble. In this paper we explore different approaches to identifying the key grouping of models, based on their most important features, and then using this information select a reduced set which we can be confident fully represent the overall model space. The result of this work is an approach which enables us to describe the entire state space using only 0.5\% of the models, along with a series of lessons learnt. The techniques that we describe are not only applicable to oil and gas exploration, but also more generally to the HPC community as we are forced to work with reduced data-sets due to the rapid increase in data collection capability.
* Pre-print in 2019 IEEE/ACM 5th International Workshop on Data Analysis and Reduction for Big Scientific Data (DRBSD-5) (pp. 42-49). IEEE
Machine learning on Crays to optimise petrophysical workflows in oil and gas exploration
Oct 01, 2020The oil and gas industry is awash with sub-surface data, which is used to characterize the rock and fluid properties beneath the seabed. This in turn drives commercial decision making and exploration, but the industry currently relies upon highly manual workflows when processing data. A key question is whether this can be improved using machine learning to complement the activities of petrophysicists searching for hydrocarbons. In this paper we present work done, in collaboration with Rock Solid Images (RSI), using supervised machine learning on a Cray XC30 to train models that streamline the manual data interpretation process. With a general aim of decreasing the petrophysical interpretation time down from over 7 days to 7 minutes, in this paper we describe the use of mathematical models that have been trained using raw well log data, for completing each of the four stages of a petrophysical interpretation workflow, along with initial data cleaning. We explore how the predictions from these models compare against the interpretations of human petrophysicists, along with numerous options and techniques that were used to optimise the prediction of our models. The power provided by modern supercomputers such as Cray machines is crucial here, but some popular machine learning framework are unable to take full advantage of modern HPC machines. As such we will also explore the suitability of the machine learning tools we have used, and describe steps we took to work round their limitations. The result of this work is the ability, for the first time, to use machine learning for the entire petrophysical workflow. Whilst there are numerous challenges, limitations and caveats, we demonstrate that machine learning has an important role to play in the processing of sub-surface data.