 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling Wildfire Perimeter Evolution using Deep Neural Networks
Sep 08, 2020
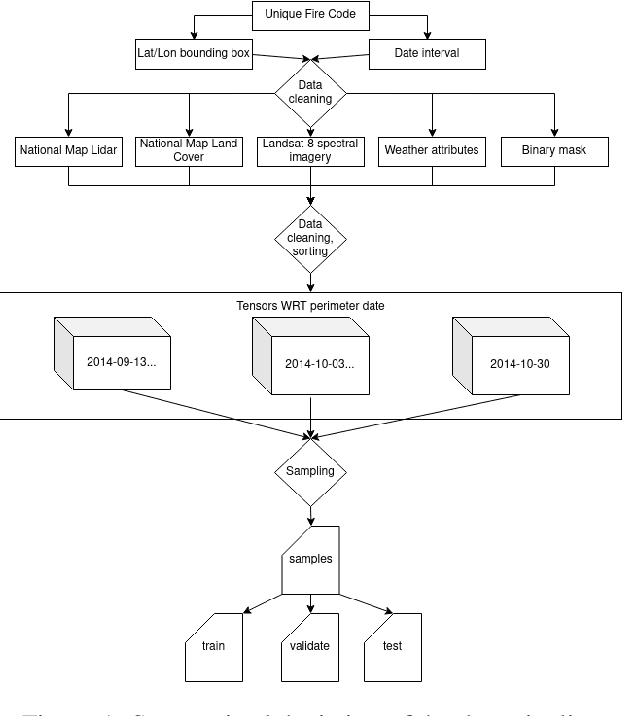
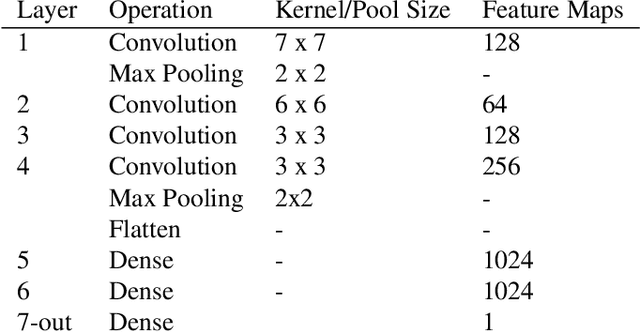

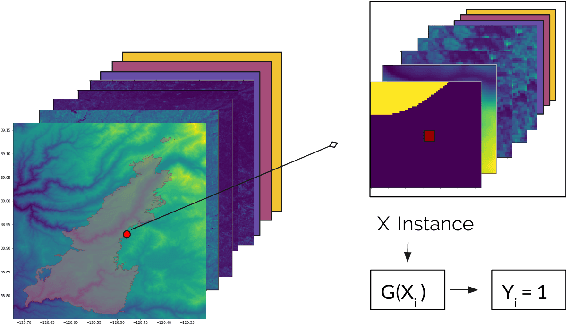
With the increased size and frequency of wildfire eventsworldwide, accurate real-time prediction of evolving wildfirefronts is a crucial component of firefighting efforts and for-est management practices. We propose a wildfire spreadingmodel that predicts the evolution of the wildfire perimeter in24 hour periods. The fire spreading simulation is based ona deep convolutional neural network (CNN) that is trainedon remotely sensed atmospheric and environmental time se-ries data. We show that the model is able to learn wildfirespreading dynamics from real historic data sets from a seriesof wildfires in the Western Sierra Nevada Mountains in Cal-ifornia. We validate the model on a previously unseen wild-fire and produce realistic results that significantly outperformhistoric alternatives with validation accuracies ranging from78% - 98%
Rosella: A Self-Driving Distributed Scheduler for Heterogeneous Clusters
Nov 10, 2020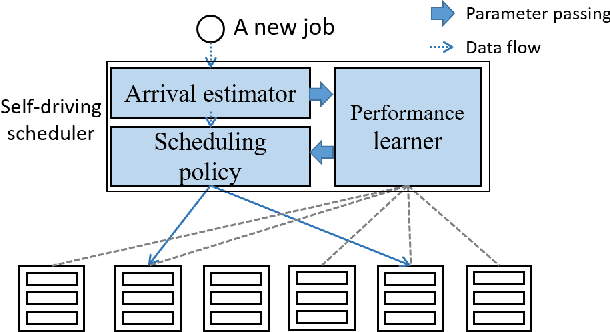
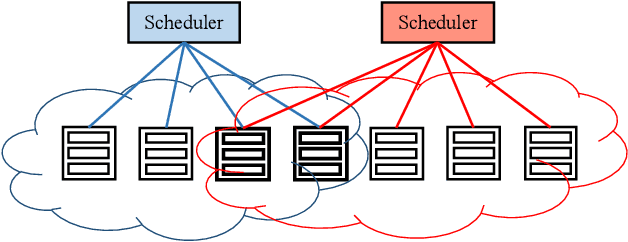
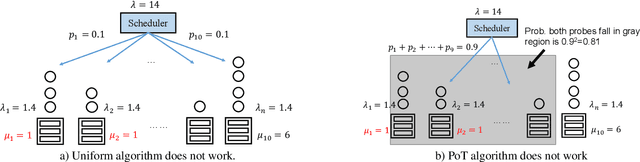
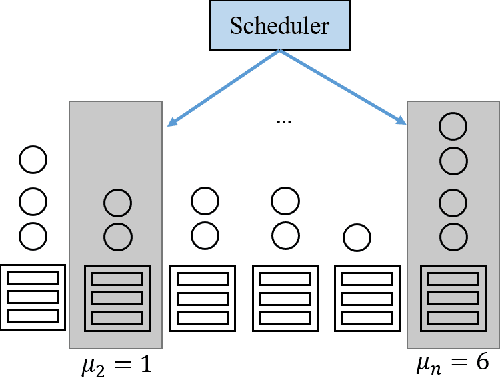
Large-scale interactive web services and advanced AI applications make sophisticated decisions in real-time, based on executing a massive amount of computation tasks on thousands of servers. Task schedulers, which often operate in heterogeneous and volatile environments, require high throughput, i.e., scheduling millions of tasks per second, and low latency, i.e., incurring minimal scheduling delays for millisecond-level tasks. Scheduling is further complicated by other users' workloads in a shared system, other background activities, and the diverse hardware configurations inside datacenters. We present Rosella, a new self-driving, distributed approach for task scheduling in heterogeneous clusters. Our system automatically learns the compute environment and adjust its scheduling policy in real-time. The solution provides high throughput and low latency simultaneously, because it runs in parallel on multiple machines with minimum coordination and only performs simple operations for each scheduling decision. Our learning module monitors total system load, and uses the information to dynamically determine optimal estimation strategy for the backends' compute-power. Our scheduling policy generalizes power-of-two-choice algorithms to handle heterogeneous workers, reducing the max queue length of $O(\log n)$ obtained by prior algorithms to $O(\log \log n)$. We implement a Rosella prototype and evaluate it with a variety of workloads. Experimental results show that Rosella significantly reduces task response times, and adapts to environment changes quickly.
Towards real-time unsupervised monocular depth estimation on CPU
Jul 31, 2018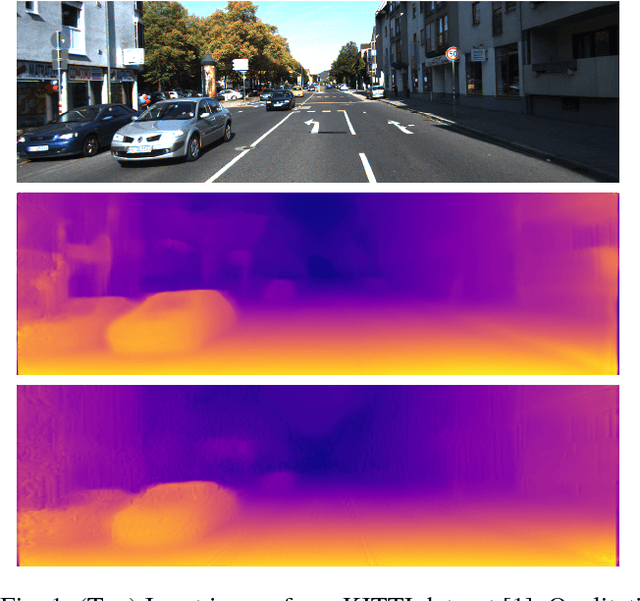
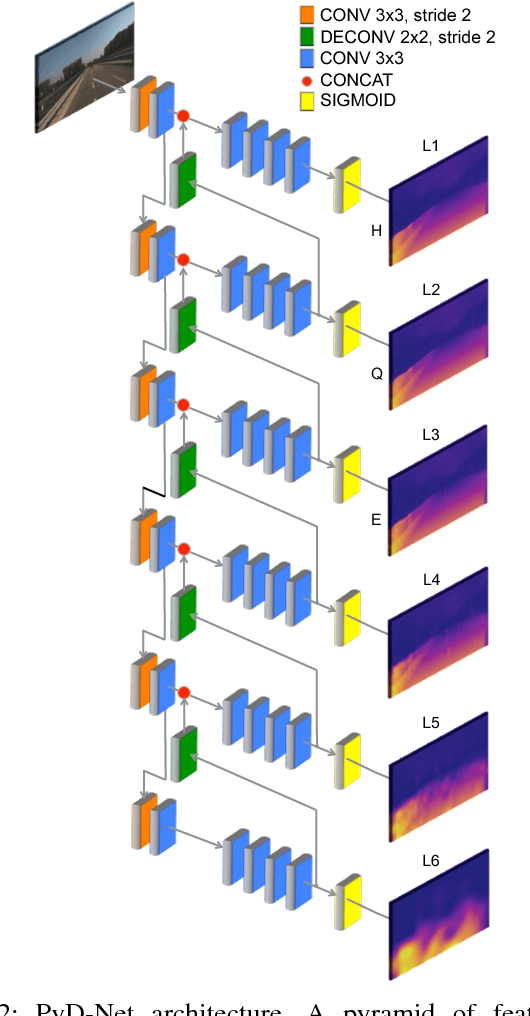
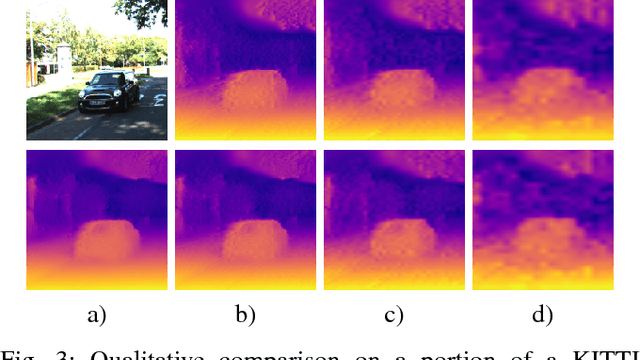
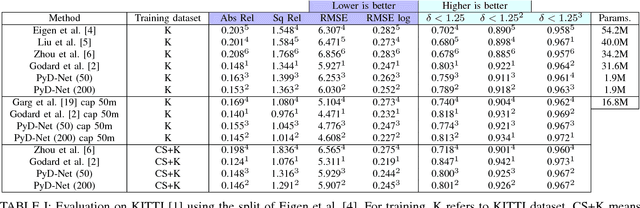
Unsupervised depth estimation from a single image is a very attractive technique with several implications in robotic, autonomous navigation, augmented reality and so on. This topic represents a very challenging task and the advent of deep learning enabled to tackle this problem with excellent results. However, these architectures are extremely deep and complex. Thus, real-time performance can be achieved only by leveraging power-hungry GPUs that do not allow to infer depth maps in application fields characterized by low-power constraints. To tackle this issue, in this paper we propose a novel architecture capable to quickly infer an accurate depth map on a CPU, even of an embedded system, using a pyramid of features extracted from a single input image. Similarly to state-of-the-art, we train our network in an unsupervised manner casting depth estimation as an image reconstruction problem. Extensive experimental results on the KITTI dataset show that compared to the top performing approach our network has similar accuracy but a much lower complexity (about 6% of parameters) enabling to infer a depth map for a KITTI image in about 1.7 s on the Raspberry Pi 3 and at more than 8 Hz on a standard CPU. Moreover, by trading accuracy for efficiency, our network allows to infer maps at about 2 Hz and 40 Hz respectively, still being more accurate than most state-of-the-art slower methods. To the best of our knowledge, it is the first method enabling such performance on CPUs paving the way for effective deployment of unsupervised monocular depth estimation even on embedded systems.
Sparse Approximate Solutions to Max-Plus Equations with Application to Multivariate Convex Regression
Nov 06, 2020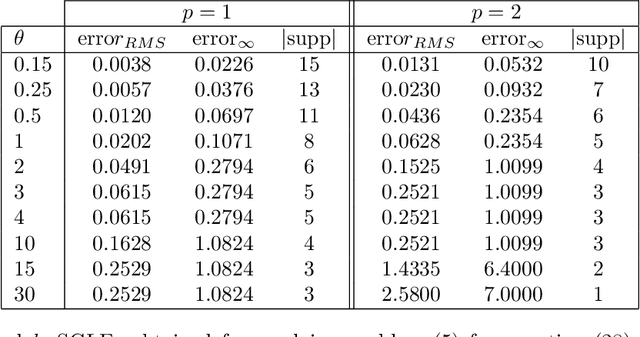
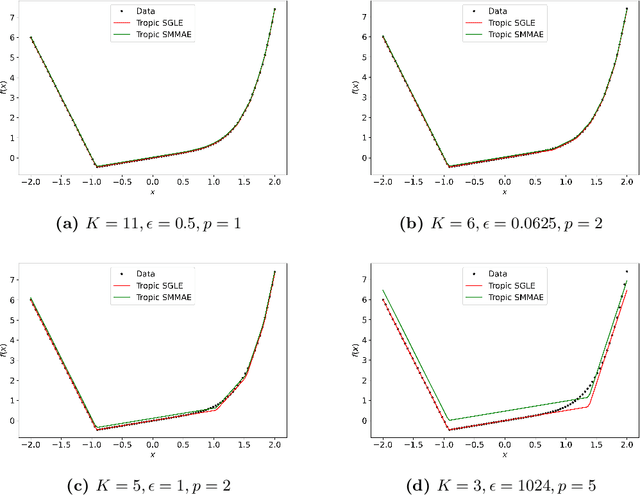
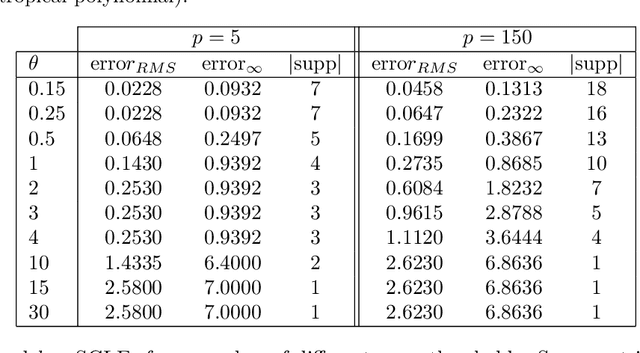
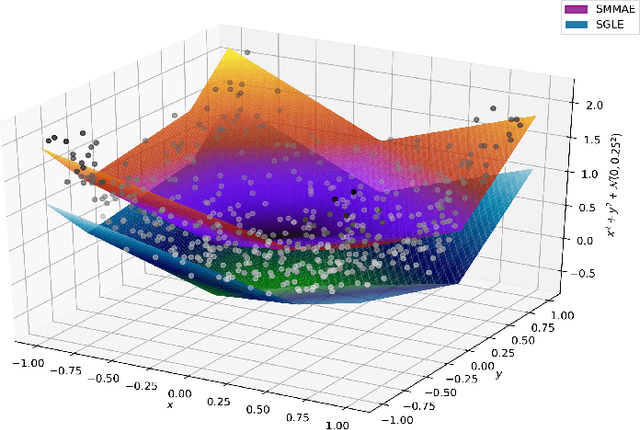
In this work, we study the problem of finding approximate, with minimum support set, solutions to matrix max-plus equations, which we call sparse approximate solutions. We show how one can obtain such solutions efficiently and in polynomial time for any $\ell_p$ approximation error. Based on these results, we propose a novel method for piecewise-linear fitting of convex multivariate functions, with optimality guarantees for the model parameters and an approximately minimum number of affine regions.
It's about time: Online Macrotask Sequencing in Expert Crowdsourcing
Jan 15, 2016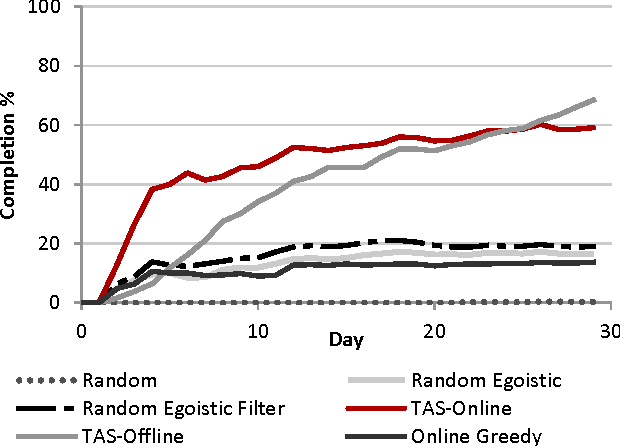
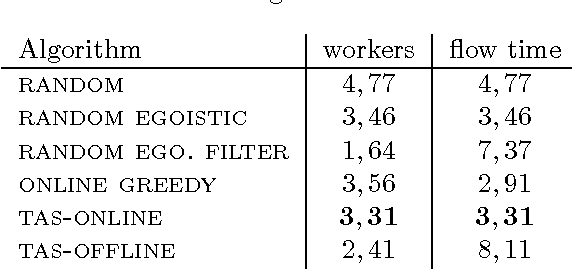
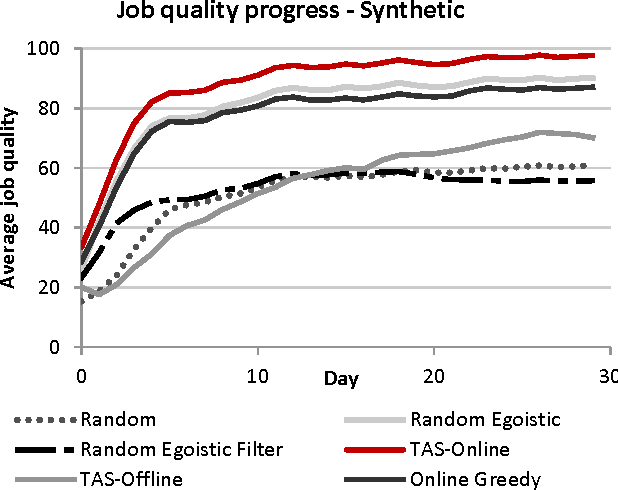
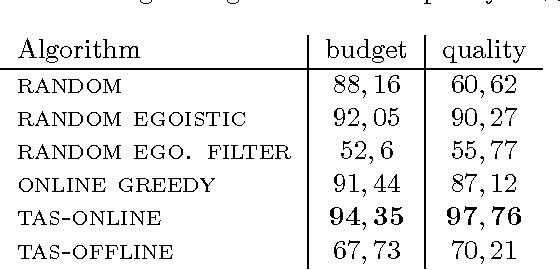
We introduce the problem of Task Assignment and Sequencing (TAS), which adds the timeline perspective to expert crowdsourcing optimization. Expert crowdsourcing involves macrotasks, like document writing, product design, or web development, which take more time than typical binary microtasks, require expert skills, assume varying degrees of knowledge over a topic, and require crowd workers to build on each other's contributions. Current works usually assume offline optimization models, which consider worker and task arrivals known and do not take into account the element of time. Realistically however, time is critical: tasks have deadlines, expert workers are available only at specific time slots, and worker/task arrivals are not known a-priori. Our work is the first to address the problem of optimal task sequencing for online, heterogeneous, time-constrained macrotasks. We propose tas-online, an online algorithm that aims to complete as many tasks as possible within budget, required quality and a given timeline, without future input information regarding job release dates or worker availabilities. Results, comparing tas-online to four typical benchmarks, show that it achieves more completed jobs, lower flow times and higher job quality. This work has practical implications for improving the Quality of Service of current crowdsourcing platforms, allowing them to offer cost, quality and time improvements for expert tasks.
Trajectory Planning for Autonomous Vehicles Using Hierarchical Reinforcement Learning
Nov 09, 2020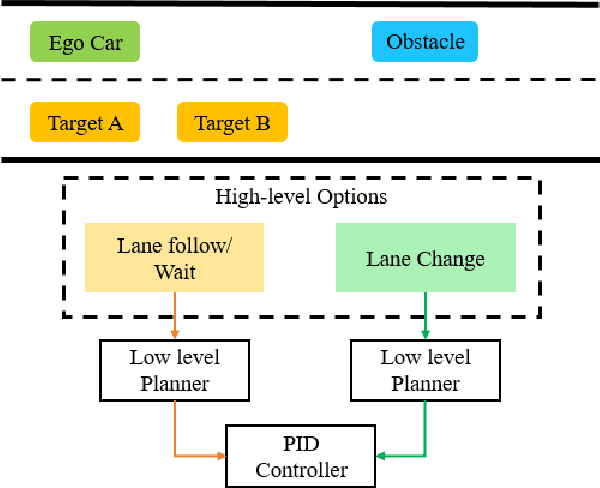
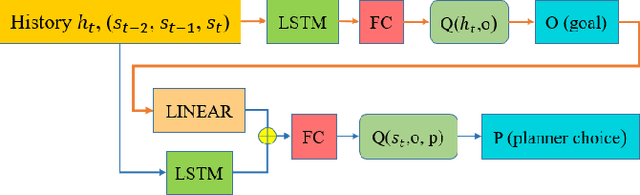
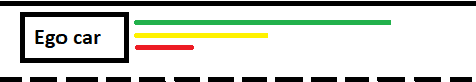
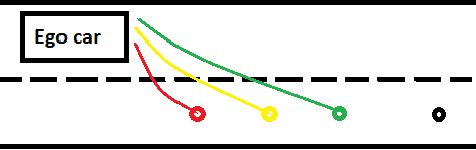
Planning safe trajectories under uncertain and dynamic conditions makes the autonomous driving problem significantly complex. Current sampling-based methods such as Rapidly Exploring Random Trees (RRTs) are not ideal for this problem because of the high computational cost. Supervised learning methods such as Imitation Learning lack generalization and safety guarantees. To address these problems and in order to ensure a robust framework, we propose a Hierarchical Reinforcement Learning (HRL) structure combined with a Proportional-Integral-Derivative (PID) controller for trajectory planning. HRL helps divide the task of autonomous vehicle driving into sub-goals and supports the network to learn policies for both high-level options and low-level trajectory planner choices. The introduction of sub-goals decreases convergence time and enables the policies learned to be reused for other scenarios. In addition, the proposed planner is made robust by guaranteeing smooth trajectories and by handling the noisy perception system of the ego-car. The PID controller is used for tracking the waypoints, which ensures smooth trajectories and reduces jerk. The problem of incomplete observations is handled by using a Long-Short-Term-Memory (LSTM) layer in the network. Results from the high-fidelity CARLA simulator indicate that the proposed method reduces convergence time, generates smoother trajectories, and is able to handle dynamic surroundings and noisy observations.
PT-Spike: A Precise-Time-Dependent Single Spike Neuromorphic Architecture with Efficient Supervised Learning
Mar 14, 2018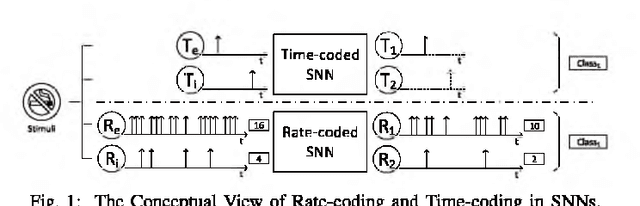
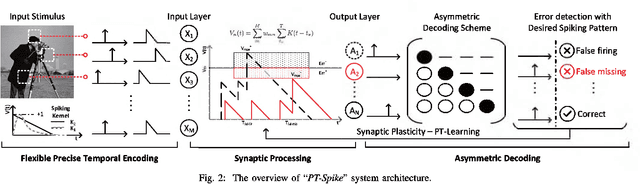
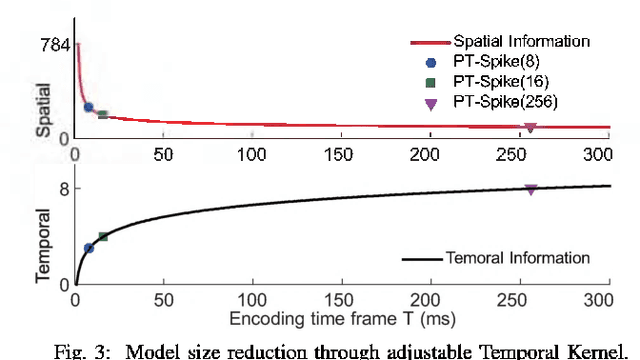

One of the most exciting advancements in AI over the last decade is the wide adoption of ANNs, such as DNN and CNN, in many real-world applications. However, the underlying massive amounts of computation and storage requirement greatly challenge their applicability in resource-limited platforms like the drone, mobile phone, and IoT devices etc. The third generation of neural network model--Spiking Neural Network (SNN), inspired by the working mechanism and efficiency of human brain, has emerged as a promising solution for achieving more impressive computing and power efficiency within light-weighted devices (e.g. single chip). However, the relevant research activities have been narrowly carried out on conventional rate-based spiking system designs for fulfilling the practical cognitive tasks, underestimating SNN's energy efficiency, throughput, and system flexibility. Although the time-based SNN can be more attractive conceptually, its potentials are not unleashed in realistic applications due to lack of efficient coding and practical learning schemes. In this work, a Precise-Time-Dependent Single Spike Neuromorphic Architecture, namely "PT-Spike", is developed to bridge this gap. Three constituent hardware-favorable techniques: precise single-spike temporal encoding, efficient supervised temporal learning, and fast asymmetric decoding are proposed accordingly to boost the energy efficiency and data processing capability of the time-based SNN at a more compact neural network model size when executing real cognitive tasks. Simulation results show that "PT-Spike" demonstrates significant improvements in network size, processing efficiency and power consumption with marginal classification accuracy degradation when compared with the rate-based SNN and ANN under the similar network configuration.
Log-time and Log-space Extreme Classification
Nov 07, 2016


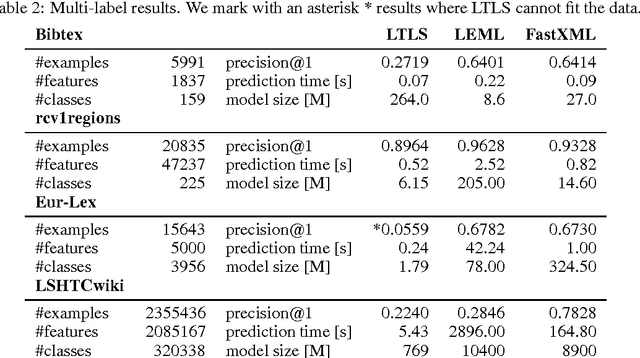
We present LTLS, a technique for multiclass and multilabel prediction that can perform training and inference in logarithmic time and space. LTLS embeds large classification problems into simple structured prediction problems and relies on efficient dynamic programming algorithms for inference. We train LTLS with stochastic gradient descent on a number of multiclass and multilabel datasets and show that despite its small memory footprint it is often competitive with existing approaches.
An Efficient Active Set Algorithm for Covariance Based Joint Data and Activity Detection for Massive Random Access with Massive MIMO
Feb 06, 2021
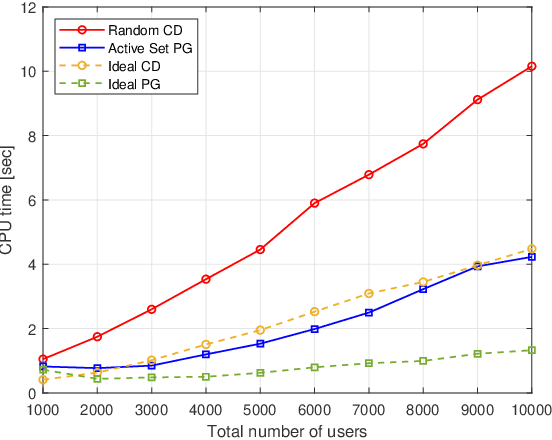
This paper proposes a computationally efficient algorithm to solve the joint data and activity detection problem for massive random access with massive multiple-input multiple-output (MIMO). The BS acquires the active devices and their data by detecting the transmitted preassigned nonorthogonal signature sequences. This paper employs a covariance based approach that formulates the detection problem as a maximum likelihood estimation (MLE) problem. To efficiently solve the problem, this paper designs a novel iterative algorithm with low complexity in the regime where the device activity pattern is sparse $\unicode{x2013}$ a key feature that existing algorithmic designs have not previously exploited for reducing complexity. Specifically, at each iteration, the proposed algorithm focuses on only a small subset of all potential sequences, namely the active set, which contains a few most likely active sequences (i.e., transmitted sequences by all active devices), and performs the detection for the sequences in the active set. The active set is carefully selected at each iteration based on the current detection result and the first-order optimality condition of the MLE problem. Simulation results show that the proposed active set algorithm enjoys significantly better computational efficiency (in terms of the CPU time) than the state-of-the-art algorithms.
UAV-Enabled Wireless Power Transfer: A Tutorial Overview
Feb 27, 2021

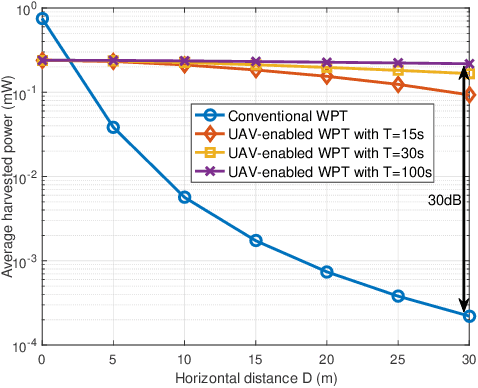
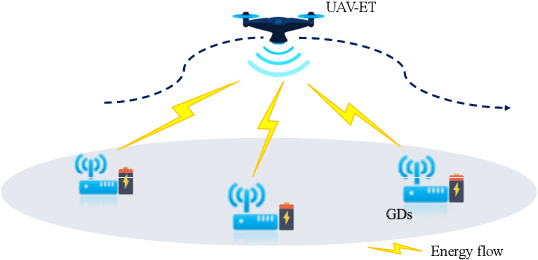
Unmanned aerial vehicle (UAV)-enabled wireless power transfer (WPT) has recently emerged as a promising technique to provide sustainable energy supply for widely distributed low-power ground devices (GDs) in large-scale wireless networks. Compared with the energy transmitters (ETs) in conventional WPT systems which are deployed at fixed locations, UAV-mounted aerial ETs can fly flexibly in the three-dimensional (3D) space to charge nearby GDs more efficiently. This paper provides a tutorial overview on UAV-enabled WPT and its appealing applications, in particular focusing on how to exploit UAVs' controllable mobility via their 3D trajectory design to maximize the amounts of energy transferred to all GDs in a wireless network with fairness. First, we consider the single-UAV-enabled WPT scenario with one UAV wirelessly charging multiple GDs at known locations. To solve the energy maximization problem in this case, we present a general trajectory design framework consisting of three innovative approaches to optimize the UAV trajectory, which are multi-location hovering, successive-hover-and-fly, and time-quantization-based optimization, respectively. Next, we consider the multi-UAV-enabled WPT scenario where multiple UAVs cooperatively charge many GDs in a large area. Building upon the single-UAV trajectory design, we propose two efficient schemes to jointly optimize multiple UAVs' trajectories, based on the principles of UAV swarming and GD clustering, respectively. Furthermore, we consider two important extensions of UAV-enabled WPT, namely UAV-enabled wireless powered communication networks (WPCN) and UAV-enabled wireless powered mobile edge computing (MEC).