 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Next Generation Multitarget Trackers: Random Finite Set Methods vs Transformer-based Deep Learning
Apr 09, 2021
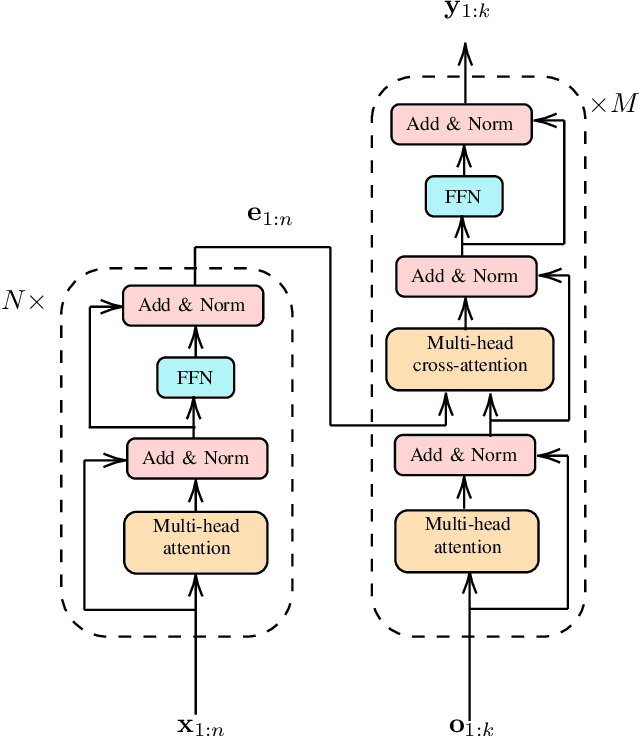
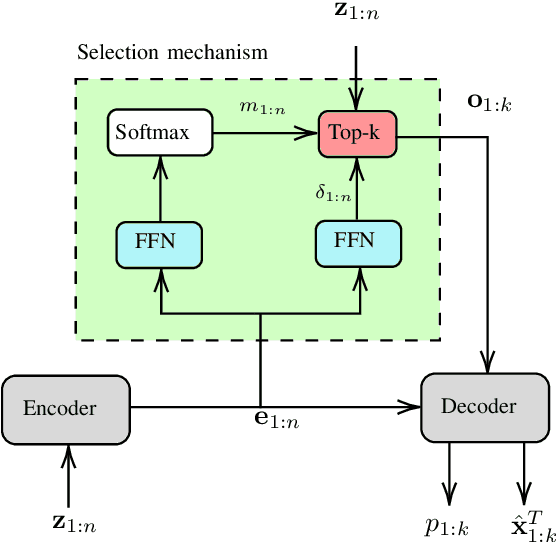
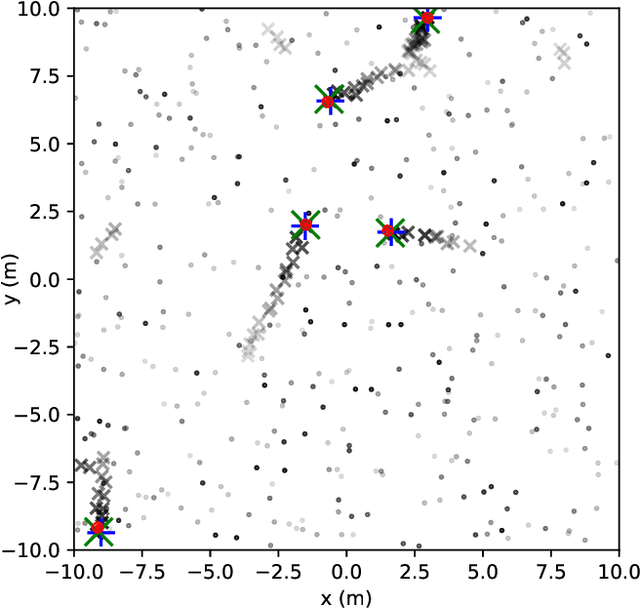
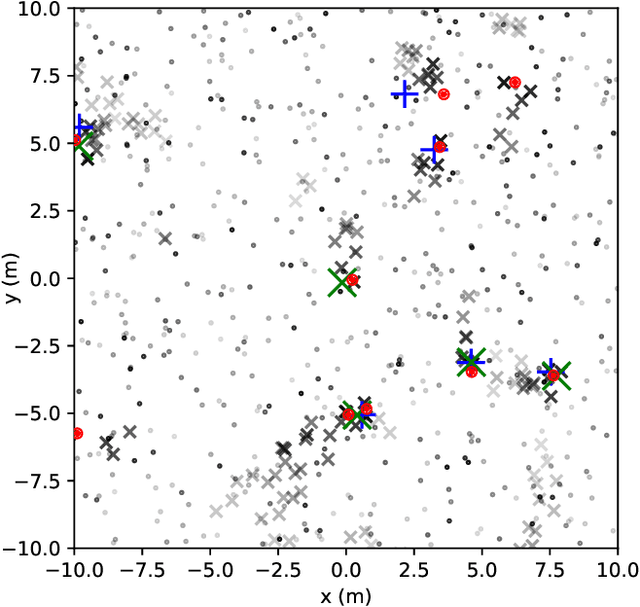
Multitarget Tracking (MTT) is the problem of tracking the states of an unknown number of objects using noisy measurements, with important applications to autonomous driving, surveillance, robotics, and others. In the model-based Bayesian setting, there are conjugate priors that enable us to express the multi-object posterior in closed form, which could theoretically provide Bayes-optimal estimates. However, the posterior involves a super-exponential growth of the number of hypotheses over time, forcing state-of-the-art methods to resort to approximations for remaining tractable, which can impact their performance in complex scenarios. Model-free methods based on deep-learning provide an attractive alternative, as they can, in principle, learn the optimal filter from data, but to the best of our knowledge were never compared to current state-of-the-art Bayesian filters, specially not in contexts where accurate models are available. In this paper, we propose a high-performing deep-learning method for MTT based on the Transformer architecture and compare it to two state-of-the-art Bayesian filters, in a setting where we assume the correct model is provided. Although this gives an edge to the model-based filters, it also allows us to generate unlimited training data. We show that the proposed model outperforms state-of-the-art Bayesian filters in complex scenarios, while matching their performance in simpler cases, which validates the applicability of deep-learning also in the model-based regime. The code for all our implementations is made available at https://github.com/JulianoLagana/MT3 .
Real-Time Human Detection as an Edge Service Enabled by a Lightweight CNN
Apr 24, 2018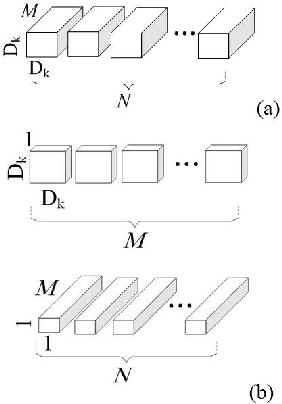
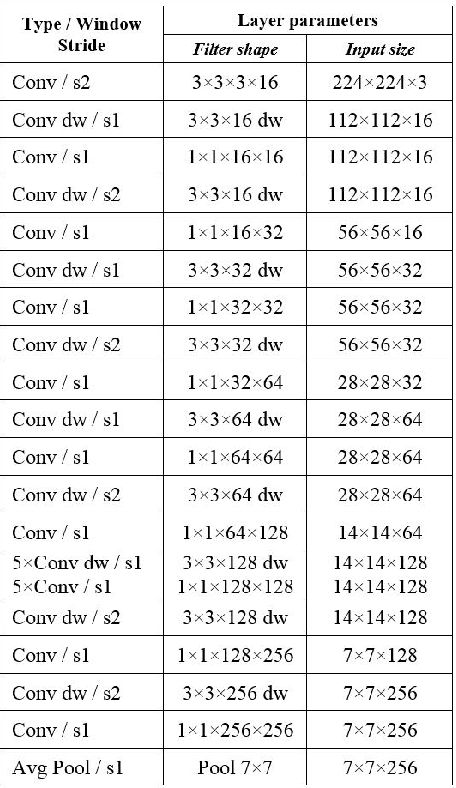


Edge computing allows more computing tasks to take place on the decentralized nodes at the edge of networks. Today many delay sensitive, mission-critical applications can leverage these edge devices to reduce the time delay or even to enable real time, online decision making thanks to their onsite presence. Human objects detection, behavior recognition and prediction in smart surveillance fall into that category, where a transition of a huge volume of video streaming data can take valuable time and place heavy pressure on communication networks. It is widely recognized that video processing and object detection are computing intensive and too expensive to be handled by resource limited edge devices. Inspired by the depthwise separable convolution and Single Shot Multi-Box Detector (SSD), a lightweight Convolutional Neural Network (LCNN) is introduced in this paper. By narrowing down the classifier's searching space to focus on human objects in surveillance video frames, the proposed LCNN algorithm is able to detect pedestrians with an affordable computation workload to an edge device. A prototype has been implemented on an edge node (Raspberry PI 3) using openCV libraries, and satisfactory performance is achieved using real world surveillance video streams. The experimental study has validated the design of LCNN and shown it is a promising approach to computing intensive applications at the edge.
Direct and Real-Time Cardiovascular Risk Prediction
Dec 08, 2017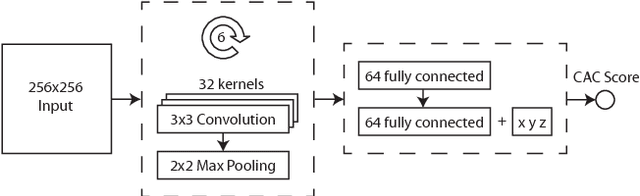

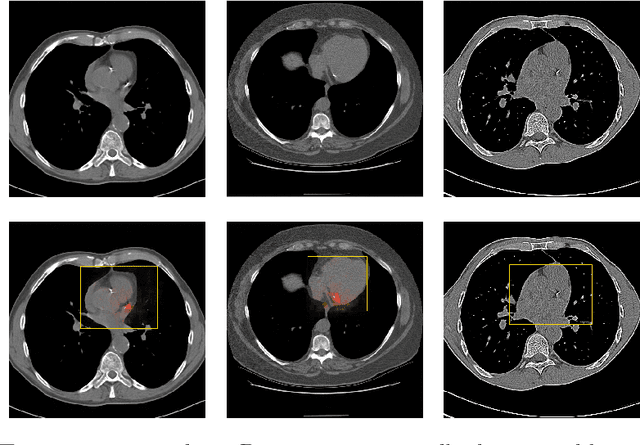
Coronary artery calcium (CAC) burden quantified in low-dose chest CT is a predictor of cardiovascular events. We propose an automatic method for CAC quantification, circumventing intermediate segmentation of CAC. The method determines a bounding box around the heart using a ConvNet for localization. Subsequently, a dedicated ConvNet analyzes axial slices within the bounding boxes to determine CAC quantity by regression. A dataset of 1,546 baseline CT scans was used from the National Lung Screening Trial with manually identified CAC. The method achieved an ICC of 0.98 between manual reference and automatically obtained Agatston scores. Stratification of subjects into five cardiovascular risk categories resulted in an accuracy of 85\% and Cohen's linearly weighted $\kappa$ of 0.90. The results demonstrate that real-time quantification of CAC burden in chest CT without the need for segmentation of CAC is possible.
Medical data wrangling with sequential variational autoencoders
Mar 12, 2021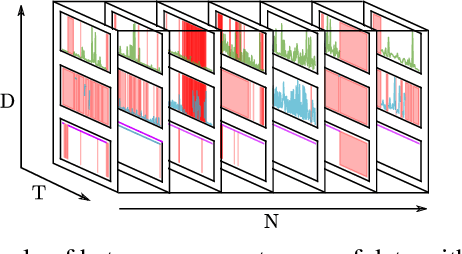

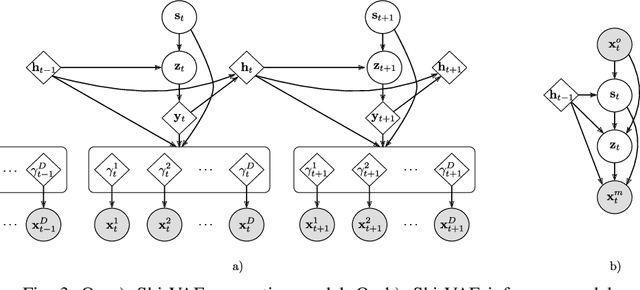
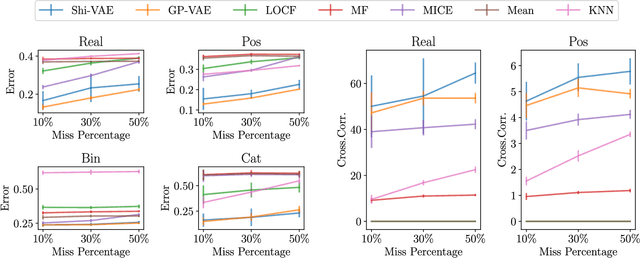
Medical data sets are usually corrupted by noise and missing data. These missing patterns are commonly assumed to be completely random, but in medical scenarios, the reality is that these patterns occur in bursts due to sensors that are off for some time or data collected in a misaligned uneven fashion, among other causes. This paper proposes to model medical data records with heterogeneous data types and bursty missing data using sequential variational autoencoders (VAEs). In particular, we propose a new methodology, the Shi-VAE, which extends the capabilities of VAEs to sequential streams of data with missing observations. We compare our model against state-of-the-art solutions in an intensive care unit database (ICU) and a dataset of passive human monitoring. Furthermore, we find that standard error metrics such as RMSE are not conclusive enough to assess temporal models and include in our analysis the cross-correlation between the ground truth and the imputed signal. We show that Shi-VAE achieves the best performance in terms of using both metrics, with lower computational complexity than the GP-VAE model, which is the state-of-the-art method for medical records.
Improving Training Result of Partially Observable Markov Decision Process by Filtering Beliefs
Jan 05, 2021
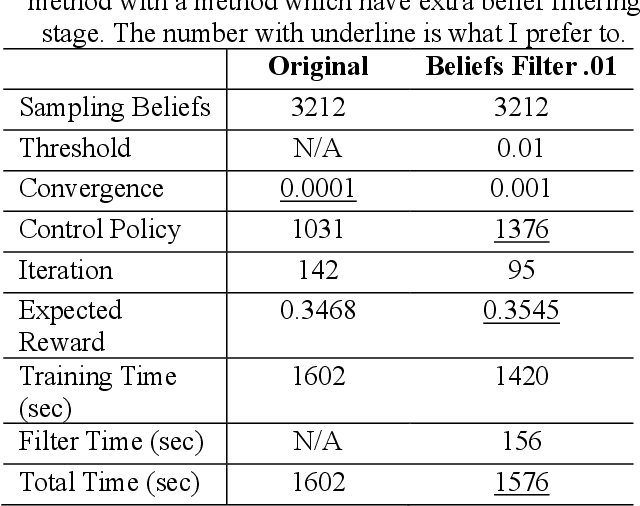
In this study I proposed a filtering beliefs method for improving performance of Partially Observable Markov Decision Processes(POMDPs), which is a method wildly used in autonomous robot and many other domains concerning control policy. My method search and compare every similar belief pair. Because a similar belief have insignificant influence on control policy, the belief is filtered out for reducing training time. The empirical results show that the proposed method outperforms the point-based approximate POMDPs in terms of the quality of training results as well as the efficiency of the method.
Model-based Learning Network for 3-D Localization in mmWave Communications
Mar 20, 2021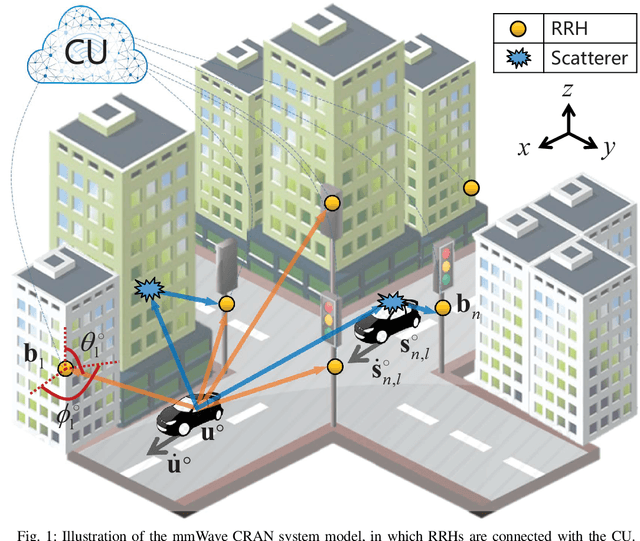
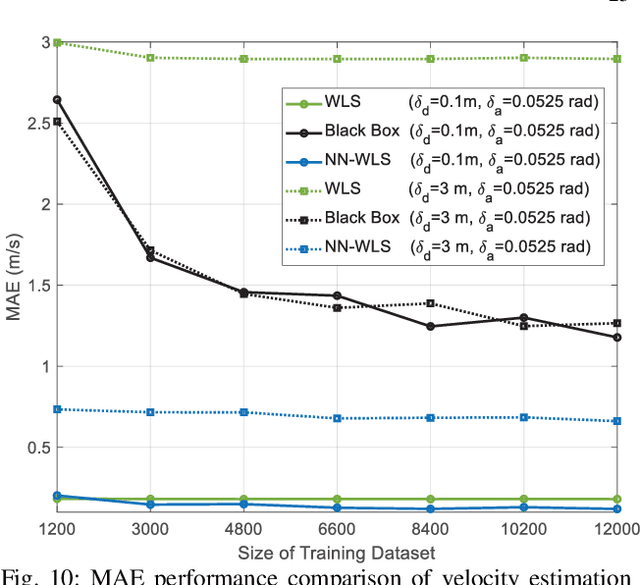
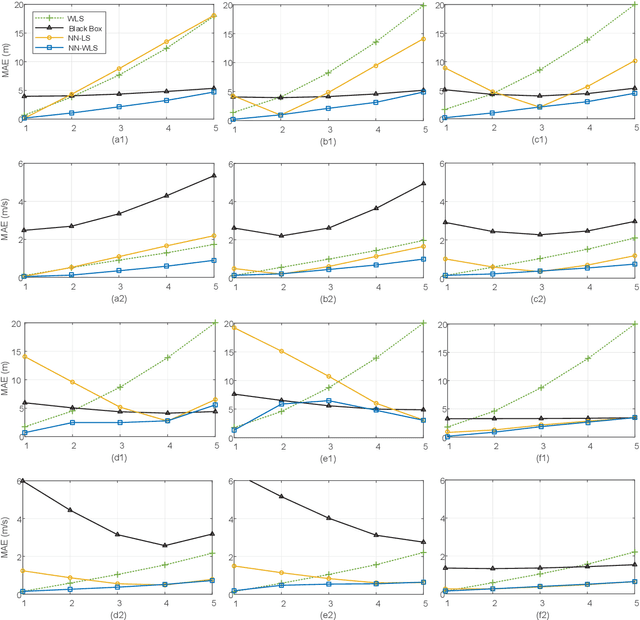
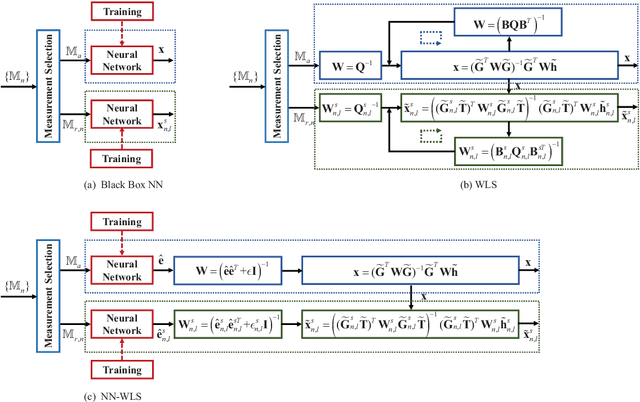
This study considers the joint location and velocity estimation of UE and scatterers in a three-dimensional mmWave CRAN architecture. Several existing works have achieved satisfactory results with neural networks (NNs) for localization. However, the black box NN localization method has limited performance and relies on a prohibitive amount of training data. Thus, we propose a model-based learning network for localization by combining NNs with geometric models. Specifically, we first develop an unbiased WLS estimator by utilizing hybrid delay/angular measurements, which determine the location and velocity of the UE in only one estimator, and can obtain the location and velocity of scatterers further. The proposed estimator can achieve the CRLB and outperforms state-of-the-art methods. Second, we establish a NN-assisted localization method (NN-WLS) by replacing the linear approximations in the proposed WLS localization model with NNs to learn higher-order error components, thereby enhancing the performance of the estimator. The solution possesses the powerful learning ability of the NN and the robustness of the proposed geometric model. Moreover, the ensemble learning is applied to improve the localization accuracy further. Comprehensive simulations show that the proposed NN-WLS is superior to the benchmark methods in terms of localization accuracy, robustness, and required time resources.
Meta-Regularization by Enforcing Mutual-Exclusiveness
Jan 24, 2021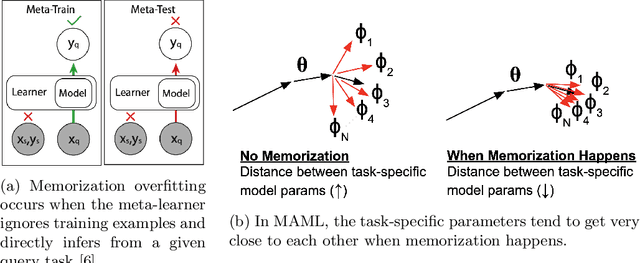
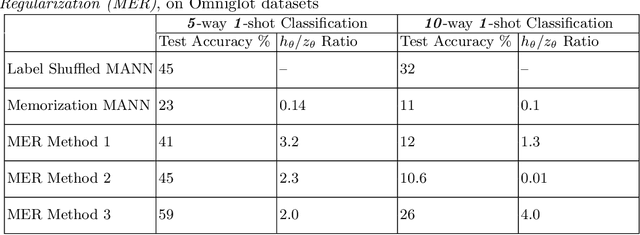
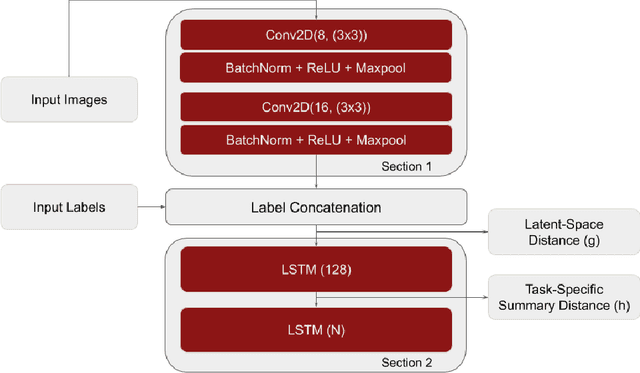
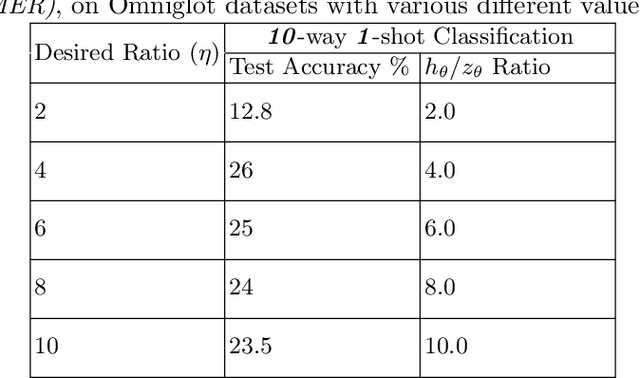
Meta-learning models have two objectives. First, they need to be able to make predictions over a range of task distributions while utilizing only a small amount of training data. Second, they also need to adapt to new novel unseen tasks at meta-test time again by using only a small amount of training data from that task. It is the second objective where meta-learning models fail for non-mutually exclusive tasks due to task overfitting. Given that guaranteeing mutually exclusive tasks is often difficult, there is a significant need for regularization methods that can help reduce the impact of task-memorization in meta-learning. For example, in the case of N-way, K-shot classification problems, tasks becomes non-mutually exclusive when the labels associated with each task is fixed. Under this design, the model will simply memorize the class labels of all the training tasks, and thus will fail to recognize a new task (class) at meta-test time. A direct observable consequence of this memorization is that the meta-learning model simply ignores the task-specific training data in favor of directly classifying based on the test-data input. In our work, we propose a regularization technique for meta-learning models that gives the model designer more control over the information flow during meta-training. Our method consists of a regularization function that is constructed by maximizing the distance between task-summary statistics, in the case of black-box models and task specific network parameters in the case of optimization based models during meta-training. Our proposed regularization function shows an accuracy boost of $\sim$ $36\%$ on the Omniglot dataset for 5-way, 1-shot classification using black-box method and for 20-way, 1-shot classification problem using optimization-based method.
Encrypted Internet traffic classification using a supervised Spiking Neural Network
Jan 24, 2021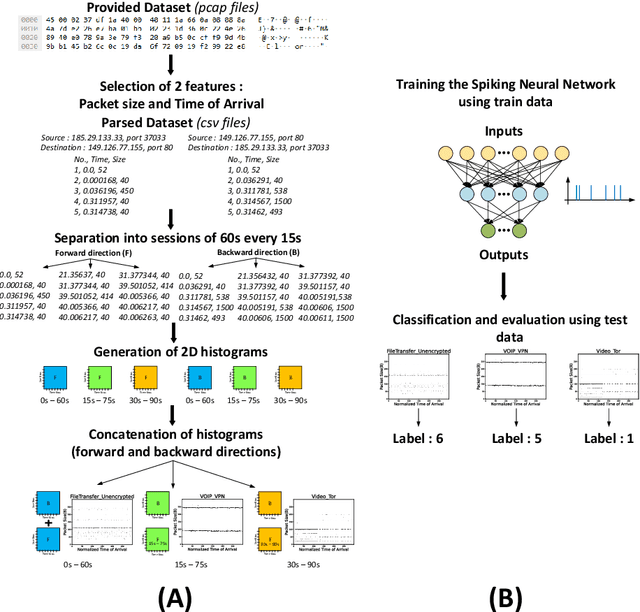
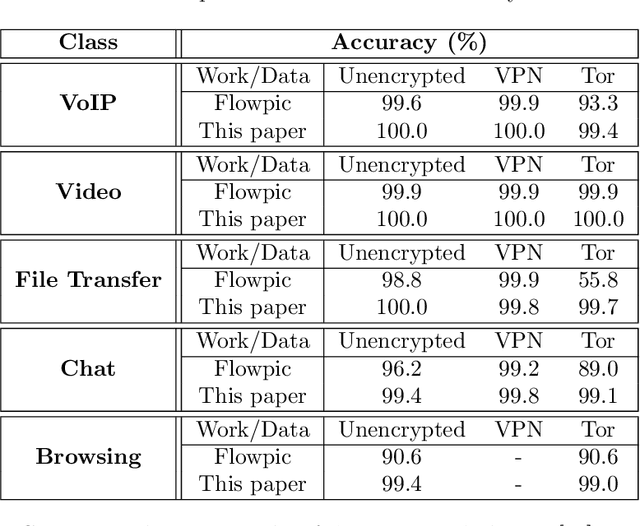
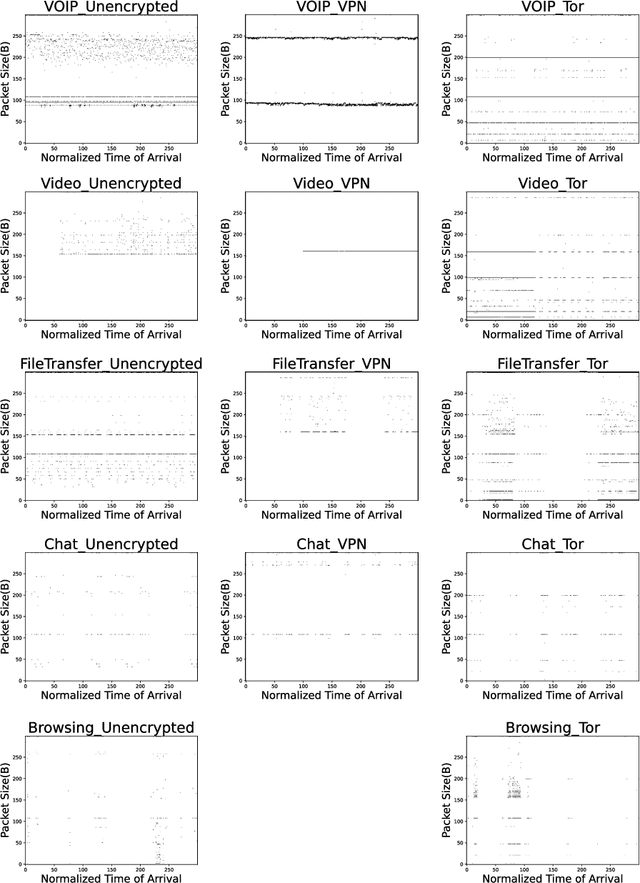
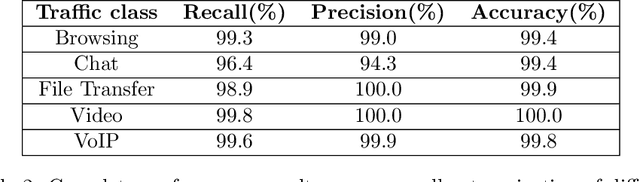
Internet traffic recognition is an essential tool for access providers since recognizing traffic categories related to different data packets transmitted on a network help them define adapted priorities. That means, for instance, high priority requirements for an audio conference and low ones for a file transfer, to enhance user experience. As internet traffic becomes increasingly encrypted, the mainstream classic traffic recognition technique, payload inspection, is rendered ineffective. This paper uses machine learning techniques for encrypted traffic classification, looking only at packet size and time of arrival. Spiking neural networks (SNN), largely inspired by how biological neurons operate, were used for two reasons. Firstly, they are able to recognize time-related data packet features. Secondly, they can be implemented efficiently on neuromorphic hardware with a low energy footprint. Here we used a very simple feedforward SNN, with only one fully-connected hidden layer, and trained in a supervised manner using the newly introduced method known as Surrogate Gradient Learning. Surprisingly, such a simple SNN reached an accuracy of 95.9% on ISCX datasets, outperforming previous approaches. Besides better accuracy, there is also a very significant improvement on simplicity: input size, number of neurons, trainable parameters are all reduced by one to four orders of magnitude. Next, we analyzed the reasons for this good accuracy. It turns out that, beyond spatial (i.e. packet size) features, the SNN also exploits temporal ones, mostly the nearly synchronous (within a 200ms range) arrival times of packets with certain sizes. Taken together, these results show that SNNs are an excellent fit for encrypted internet traffic classification: they can be more accurate than conventional artificial neural networks (ANN), and they could be implemented efficiently on low power embedded systems.
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021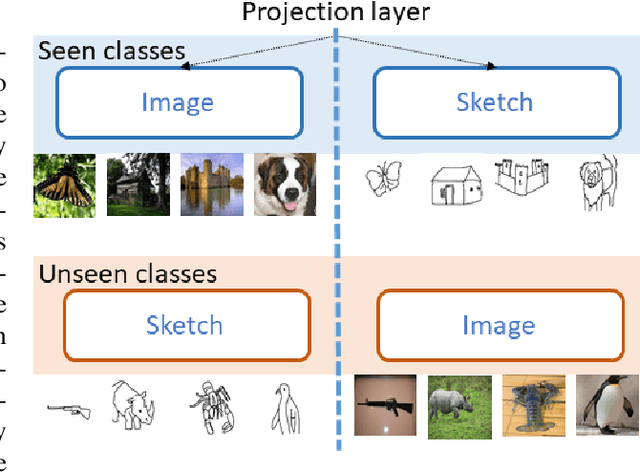
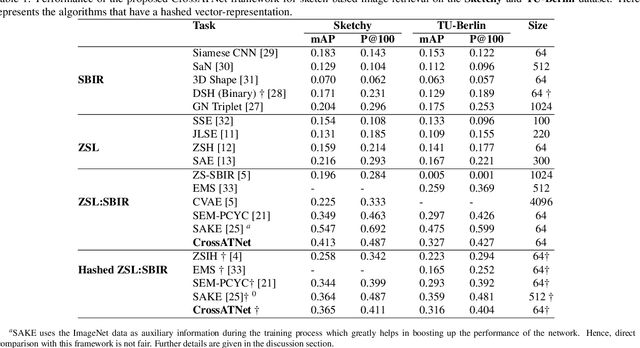
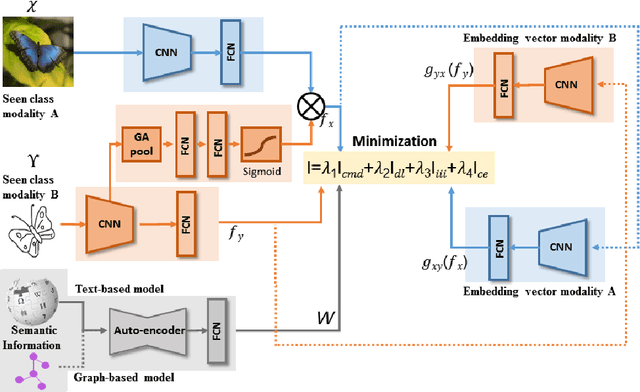
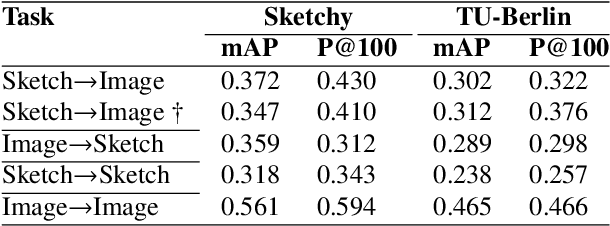
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
Self-Taught Semi-Supervised Anomaly Detection on Upper Limb X-rays
Feb 22, 2021
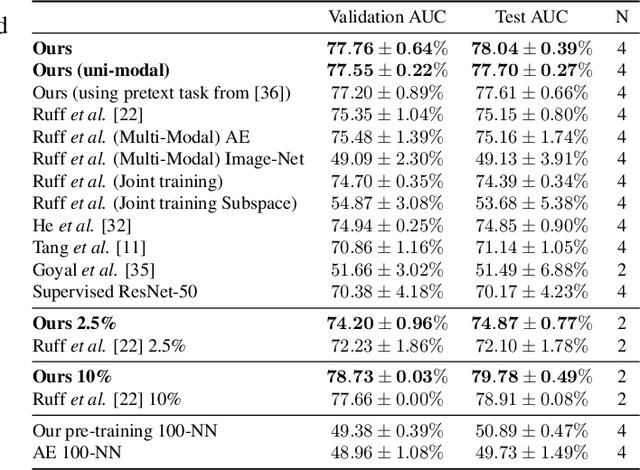
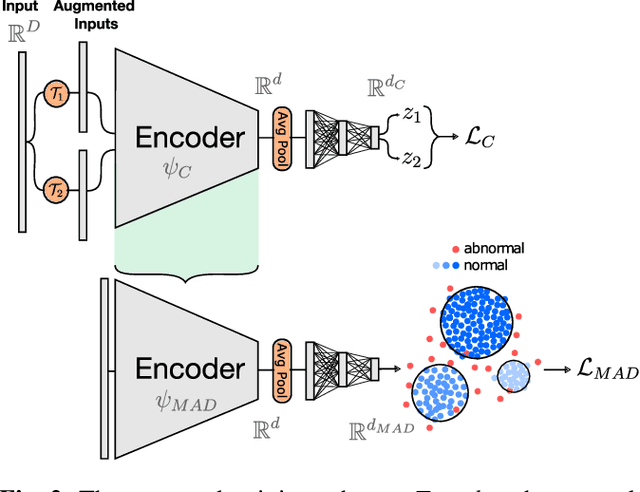
Detecting anomalies in musculoskeletal radiographs is of paramount importance for large-scale screening in the radiology workflow. Supervised deep networks take for granted a large number of annotations by radiologists, which is often prohibitively very time-consuming to acquire. Moreover, supervised systems are tailored to closed set scenarios, e.g., trained models suffer from overfitting to previously seen rare anomalies at training. Instead, our approach's rationale is to use task agnostic pretext tasks to leverage unlabeled data based on a cross-sample similarity measure. Besides, we formulate a complex distribution of data from normal class within our framework to avoid a potential bias on the side of anomalies. Through extensive experiments, we show that our method outperforms baselines across unsupervised and self-supervised anomaly detection settings on a real-world medical dataset, the MURA dataset. We also provide rich ablation studies to analyze each training stage's effect and loss terms on the final performance.