 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed storage algorithms with optimal tradeoffs
Jan 13, 2021
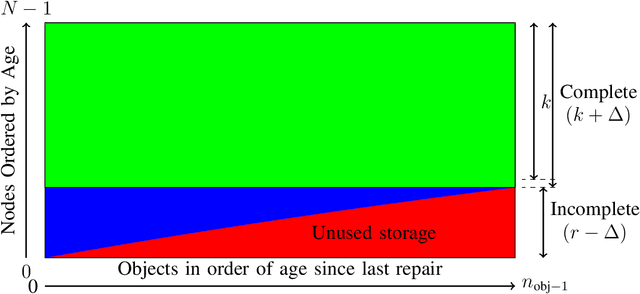
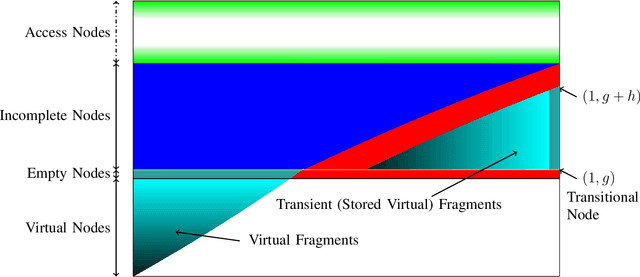
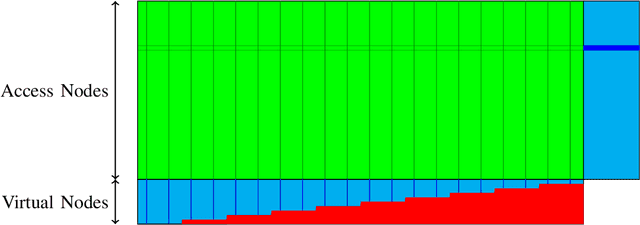
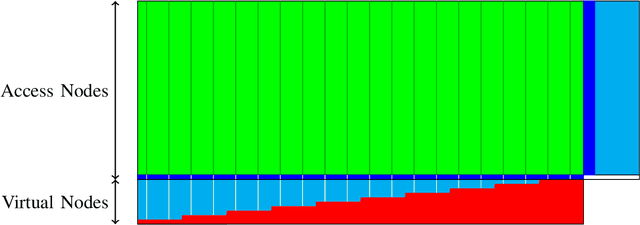
One of the primary objectives of a distributed storage system is to reliably store large amounts of source data for long durations using a large number $N$ of unreliable storage nodes, each with $c$ bits of storage capacity. Storage nodes fail randomly over time and are replaced with nodes of equal capacity initialized to zeroes, and thus bits are erased at some rate $e$. To maintain recoverability of the source data, a repairer continually reads data over a network from nodes at an average rate $r$, and generates and writes data to nodes based on the read data. The distributed storage source capacity is the maximum amount of source that can be reliably stored for long periods of time. Previous research shows that asymptotically the distributed storage source capacity is at most $\left(1-\frac{e}{2 \cdot r}\right) \cdot N \cdot c$ as $N$ and $r$ grow. In this work we introduce and analyze algorithms such that asymptotically the distributed storage source data capacity is at least the above equation. Thus, the above equation expresses a fundamental trade-off between network traffic and storage overhead to reliably store source data.
Control with adaptive Q-learning
Nov 03, 2020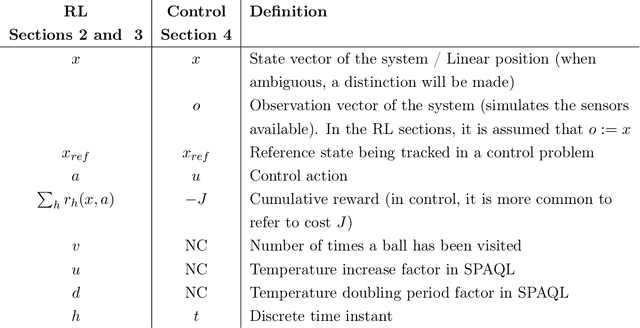
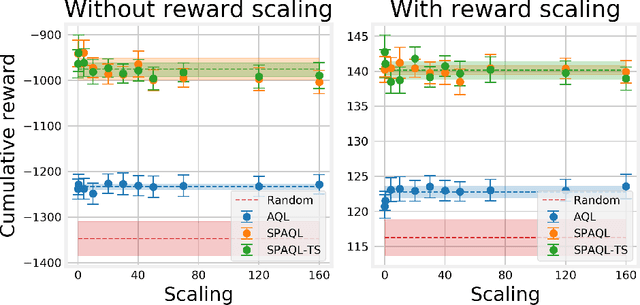

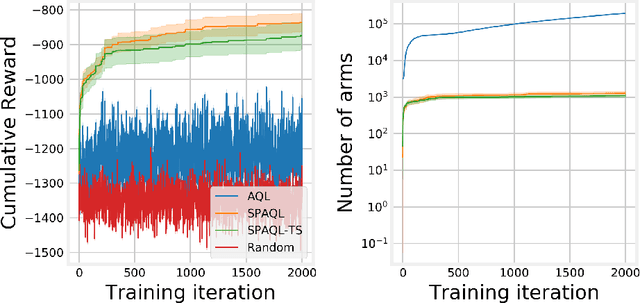
This paper evaluates adaptive Q-learning (AQL) and single-partition adaptive Q-learning (SPAQL), two algorithms for efficient model-free episodic reinforcement learning (RL), in two classical control problems (Pendulum and Cartpole). AQL adaptively partitions the state-action space of a Markov decision process (MDP), while learning the control policy, i. e., the mapping from states to actions. The main difference between AQL and SPAQL is that the latter learns time-invariant policies, where the mapping from states to actions does not depend explicitly on the time step. This paper also proposes the SPAQL with terminal state (SPAQL-TS), an improved version of SPAQL tailored for the design of regulators for control problems. The time-invariant policies are shown to result in a better performance than the time-variant ones in both problems studied. These algorithms are particularly fitted to RL problems where the action space is finite, as is the case with the Cartpole problem. SPAQL-TS solves the OpenAI Gym Cartpole problem, while also displaying a higher sample efficiency than trust region policy optimization (TRPO), a standard RL algorithm for solving control tasks. Moreover, the policies learned by SPAQL are interpretable, while TRPO policies are typically encoded as neural networks, and therefore hard to interpret. Yielding interpretable policies while being sample-efficient are the major advantages of SPAQL.
Neural Network-based Quantization for Network Automation
Mar 04, 2021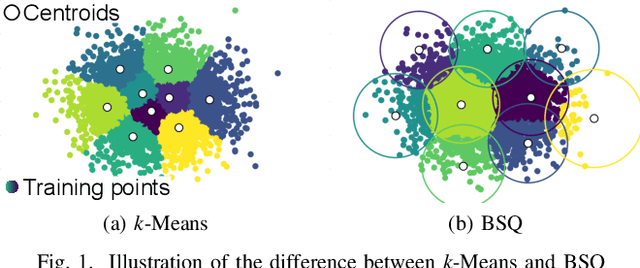
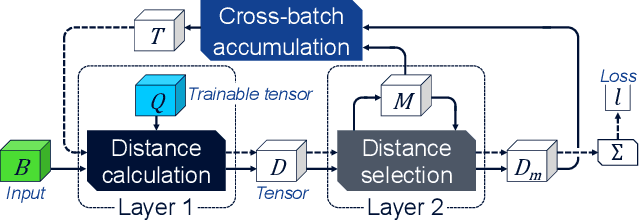
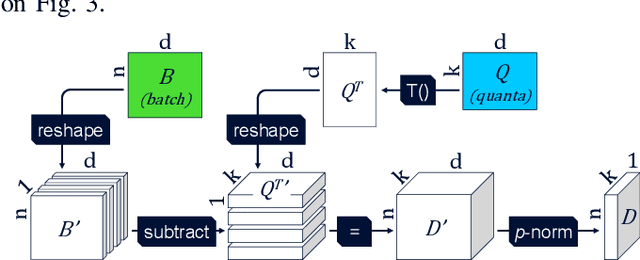
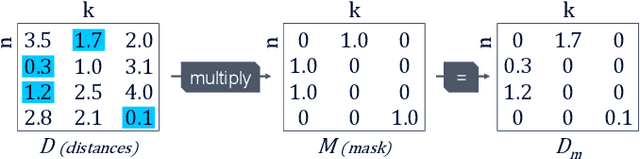
Deep Learning methods have been adopted in mobile networks, especially for network management automation where they provide means for advanced machine cognition. Deep learning methods utilize cutting-edge hardware and software tools, allowing complex cognitive algorithms to be developed. In a recent paper, we introduced the Bounding Sphere Quantization (BSQ) algorithm, a modification of the k-Means algorithm, that was shown to create better quantizations for certain network management use-cases, such as anomaly detection. However, BSQ required a significantly longer time to train than k-Means, a challenge which can be overcome with a neural network-based implementation. In this paper, we present such an implementation of BSQ that utilizes state-of-the-art deep learning tools to achieve a competitive training speed.
MC-LSTM: Mass-Conserving LSTM
Jan 13, 2021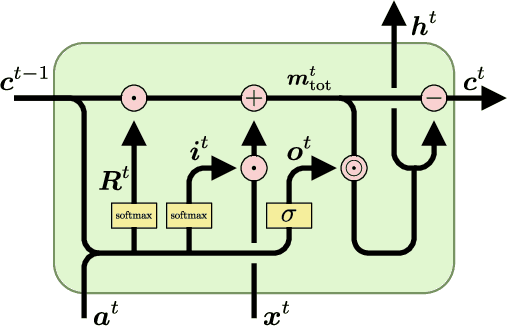
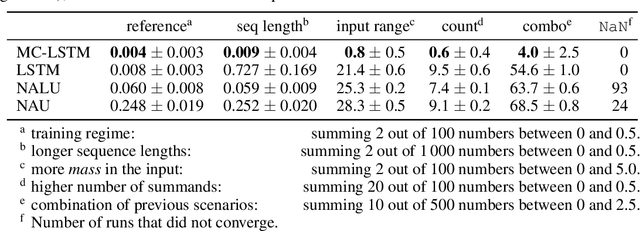
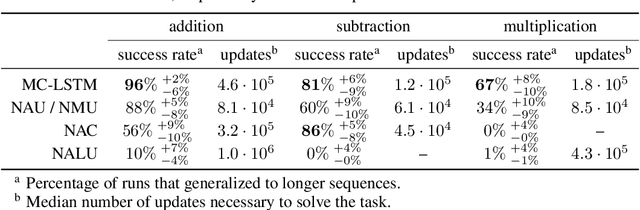
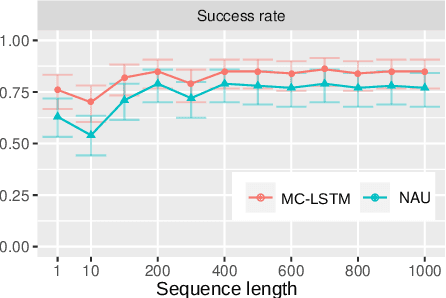
The success of Convolutional Neural Networks (CNNs) in computer vision is mainly driven by their strong inductive bias, which is strong enough to allow CNNs to solve vision-related tasks with random weights, meaning without learning. Similarly, Long Short-Term Memory (LSTM) has a strong inductive bias towards storing information over time. However, many real-world systems are governed by conservation laws, which lead to the redistribution of particular quantities -- e.g. in physical and economical systems. Our novel Mass-Conserving LSTM (MC-LSTM) adheres to these conservation laws by extending the inductive bias of LSTM to model the redistribution of those stored quantities. MC-LSTMs set a new state-of-the-art for neural arithmetic units at learning arithmetic operations, such as addition tasks, which have a strong conservation law, as the sum is constant over time. Further, MC-LSTM is applied to traffic forecasting, modelling a pendulum, and a large benchmark dataset in hydrology, where it sets a new state-of-the-art for predicting peak flows. In the hydrology example, we show that MC-LSTM states correlate with real-world processes and are therefore interpretable.
DeepObliviate: A Powerful Charm for Erasing Data Residual Memory in Deep Neural Networks
May 13, 2021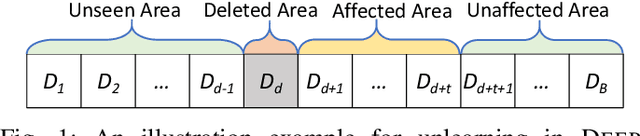
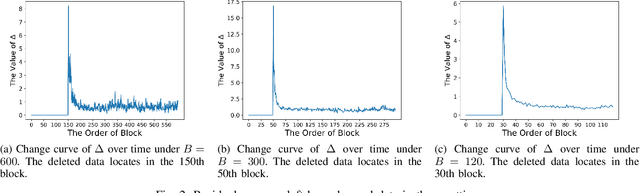
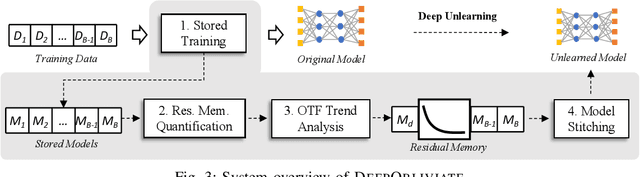
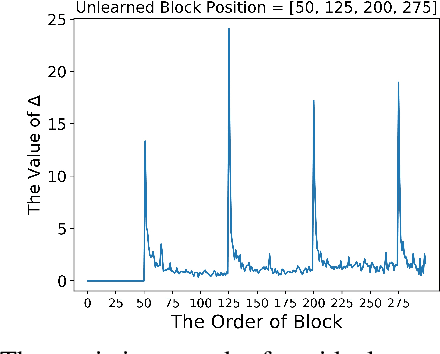
Machine unlearning has great significance in guaranteeing model security and protecting user privacy. Additionally, many legal provisions clearly stipulate that users have the right to demand model providers to delete their own data from training set, that is, the right to be forgotten. The naive way of unlearning data is to retrain the model without it from scratch, which becomes extremely time and resource consuming at the modern scale of deep neural networks. Other unlearning approaches by refactoring model or training data struggle to gain a balance between overhead and model usability. In this paper, we propose an approach, dubbed as DeepObliviate, to implement machine unlearning efficiently, without modifying the normal training mode. Our approach improves the original training process by storing intermediate models on the hard disk. Given a data point to unlearn, we first quantify its temporal residual memory left in stored models. The influenced models will be retrained and we decide when to terminate the retraining based on the trend of residual memory on-the-fly. Last, we stitch an unlearned model by combining the retrained models and uninfluenced models. We extensively evaluate our approach on five datasets and deep learning models. Compared to the method of retraining from scratch, our approach can achieve 99.0%, 95.0%, 91.9%, 96.7%, 74.1% accuracy rates and 66.7$\times$, 75.0$\times$, 33.3$\times$, 29.4$\times$, 13.7$\times$ speedups on the MNIST, SVHN, CIFAR-10, Purchase, and ImageNet datasets, respectively. Compared to the state-of-the-art unlearning approach, we improve 5.8% accuracy, 32.5$\times$ prediction speedup, and reach a comparable retrain speedup under identical settings on average on these datasets. Additionally, DeepObliviate can also pass the backdoor-based unlearning verification.
MoViNets: Mobile Video Networks for Efficient Video Recognition
Apr 18, 2021



We present Mobile Video Networks (MoViNets), a family of computation and memory efficient video networks that can operate on streaming video for online inference. 3D convolutional neural networks (CNNs) are accurate at video recognition but require large computation and memory budgets and do not support online inference, making them difficult to work on mobile devices. We propose a three-step approach to improve computational efficiency while substantially reducing the peak memory usage of 3D CNNs. First, we design a video network search space and employ neural architecture search to generate efficient and diverse 3D CNN architectures. Second, we introduce the Stream Buffer technique that decouples memory from video clip duration, allowing 3D CNNs to embed arbitrary-length streaming video sequences for both training and inference with a small constant memory footprint. Third, we propose a simple ensembling technique to improve accuracy further without sacrificing efficiency. These three progressive techniques allow MoViNets to achieve state-of-the-art accuracy and efficiency on the Kinetics, Moments in Time, and Charades video action recognition datasets. For instance, MoViNet-A5-Stream achieves the same accuracy as X3D-XL on Kinetics 600 while requiring 80% fewer FLOPs and 65% less memory. Code will be made available at https://github.com/tensorflow/models/tree/master/official/vision.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016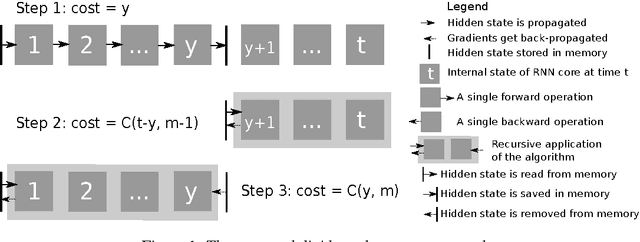
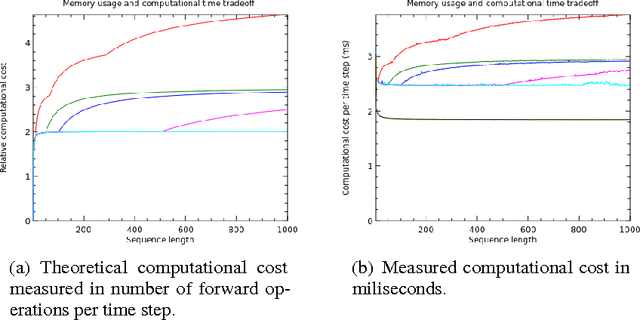
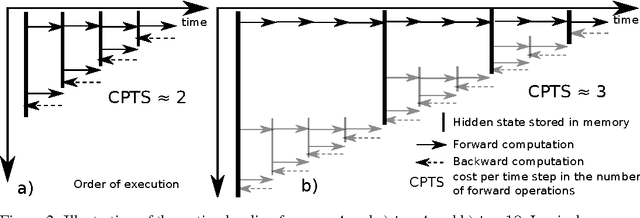
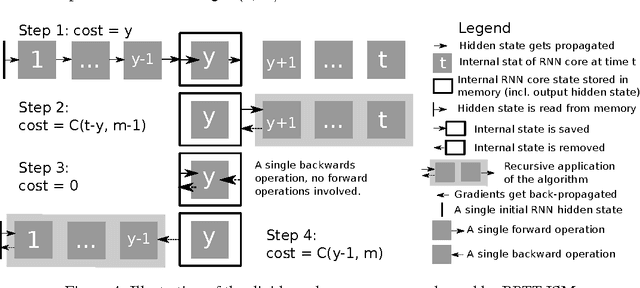
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.
Geospatial Transformations for Ground-Based Sky Imaging Systems
Mar 09, 2021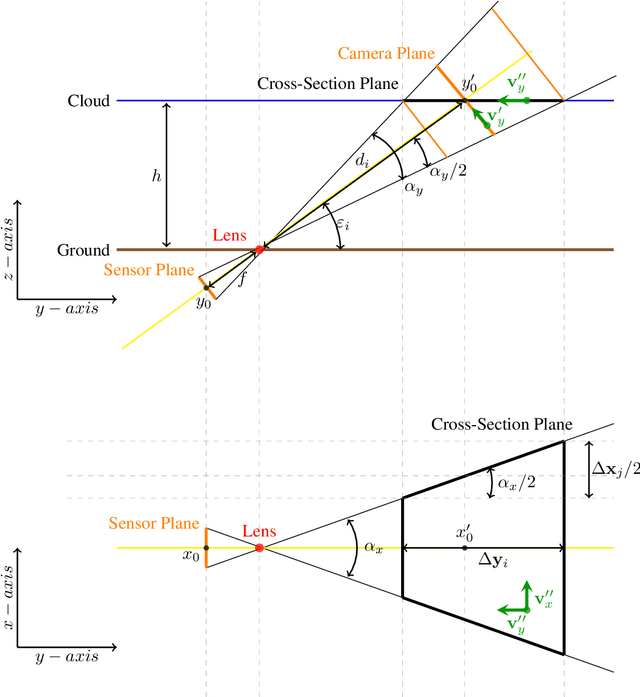
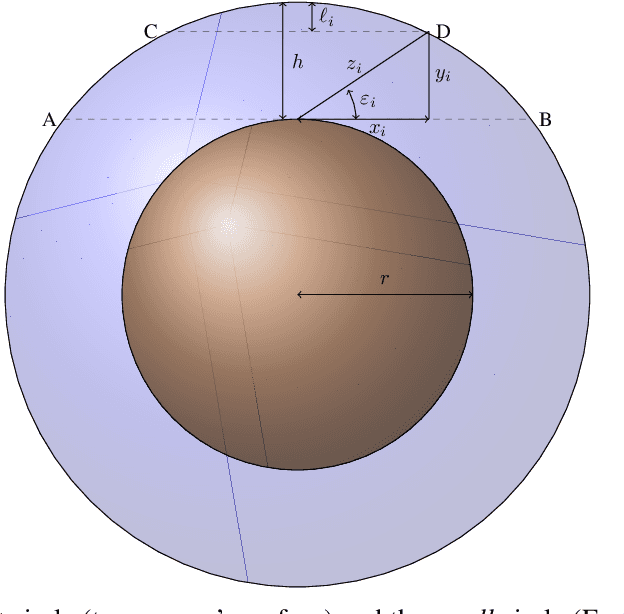
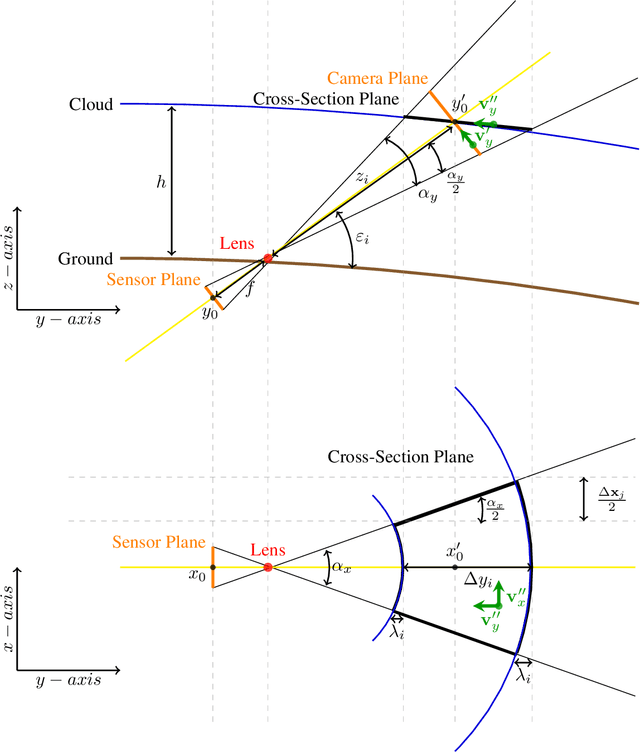

Sky imaging systems use lenses to acquire images concentrating light beams in an imager. The light beams received by the sky imager have an elevation angle with respect to the normal of the device. This produces that the image pixels contain information from different areas of the sky within the imaging system Field Of View (FOV). The area of the field of view contained in the pixels increases as the elevation angle of the incident light beams decreases. When the sky imagers are mounted on a solar tracker incidence angle of the light beam on a pixel varies over time. This investigation introduces a transformation that projects the original euclidean frame of the imager plane to the geospatial frame atmosphere cross-section plane form when the sky imager field of view intersects the tropopause.
Toward Accurate Platform-Aware Performance Modeling for Deep Neural Networks
Dec 01, 2020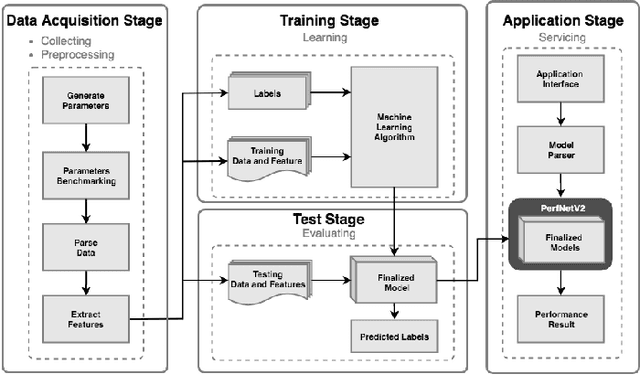
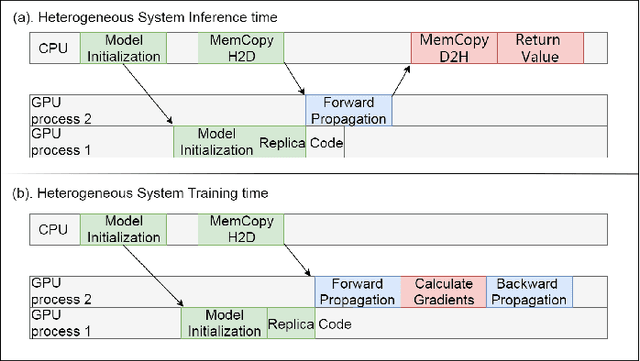
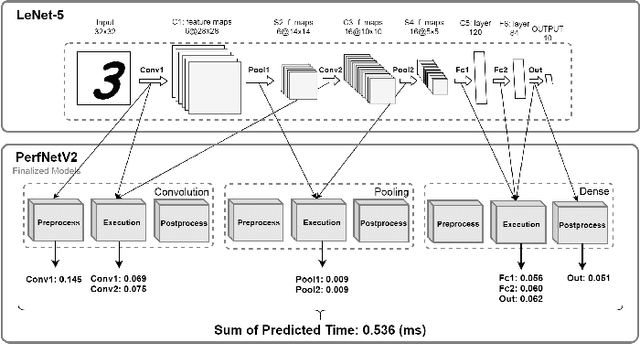
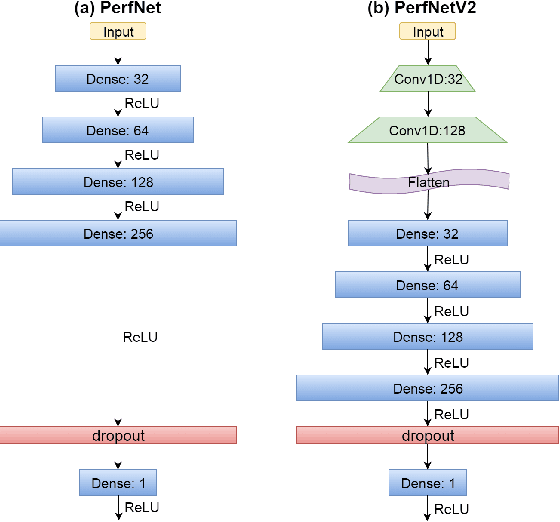
In this paper, we provide a fine-grain machine learning-based method, PerfNetV2, which improves the accuracy of our previous work for modeling the neural network performance on a variety of GPU accelerators. Given an application, the proposed method can be used to predict the inference time and training time of the convolutional neural networks used in the application, which enables the system developer to optimize the performance by choosing the neural networks and/or incorporating the hardware accelerators to deliver satisfactory results in time. Furthermore, the proposed method is capable of predicting the performance of an unseen or non-existing device, e.g. a new GPU which has a higher operating frequency with less processor cores, but more memory capacity. This allows a system developer to quickly search the hardware design space and/or fine-tune the system configuration. Compared to the previous works, PerfNetV2 delivers more accurate results by modeling detailed host-accelerator interactions in executing the full neural networks and improving the architecture of the machine learning model used in the predictor. Our case studies show that PerfNetV2 yields a mean absolute percentage error within 13.1% on LeNet, AlexNet, and VGG16 on NVIDIA GTX-1080Ti, while the error rate on a previous work published in ICBD 2018 could be as large as 200%.
Generic Variance Bounds on Estimation and Prediction Errors in Time Series Analysis: An Entropy Perspective
Apr 15, 2019In this paper, we obtain generic bounds on the variances of estimation and prediction errors in time series analysis via an information-theoretic approach. It is seen in general that the error bounds are determined by the conditional entropy of the data point to be estimated or predicted given the side information or past observations. Additionally, we discover that in order to achieve the prediction error bounds asymptotically, the necessary and sufficient condition is that the "innovation" is asymptotically white Gaussian. When restricted to Gaussian processes and 1-step prediction, our bounds are shown to reduce to the Kolmogorov-Szeg\"o formula and Wiener-Masani formula known from linear prediction theory.