 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Testbench Generation for LLM-Driven HDL Design and Verification-Oriented Data Curation
Jun 11, 2026Automated testbench generation has become a critical bottleneck in large language model (LLM)-driven Register Transfer Level (RTL) workflows, where large numbers of candidate designs must be verified rapidly and reliably. Existing prompt-based approaches treat testbench generation as unconstrained code synthesis, yielding stochastic outputs with high token cost, low reproducibility, and insufficient coverage. To address this gap, we present STG, a Structured Testbench Generation framework that exploits the inherent structure of hardware designs to generate deterministic testbenches. As a direct verification tool, STG runs 720x faster than an iterative LLM-based testbench generation flow and higher rate of successful compilation, achieves higher coverage, and reduces false-pass verdicts on incorrect DUTs. STG also helps identify errors in RTL generation benchmarks by exposing faulty benchmark testbenches. As a data curation engine, it is 11x faster than LLM-based filtering on a single CPU core with 127x less energy, and the resulting distilled models provide state-of-the-art performance in our multi-benchmark evaluation. As a test-time scaling oracle, it reduces node count by 14-47\%. Our models are available at https://huggingface.co/collections/AS-SiliconMind/siliconmind-v12.
EvolVE: Evolutionary Search for LLM-based Verilog Generation and Optimization
Jan 26, 2026Verilog's design cycle is inherently labor-intensive and necessitates extensive domain expertise. Although Large Language Models (LLMs) offer a promising pathway toward automation, their limited training data and intrinsic sequential reasoning fail to capture the strict formal logic and concurrency inherent in hardware systems. To overcome these barriers, we present EvolVE, the first framework to analyze multiple evolution strategies on chip design tasks, revealing that Monte Carlo Tree Search (MCTS) excels at maximizing functional correctness, while Idea-Guided Refinement (IGR) proves superior for optimization. We further leverage Structured Testbench Generation (STG) to accelerate the evolutionary process. To address the lack of complex optimization benchmarks, we introduce IC-RTL, targeting industry-scale problems derived from the National Integrated Circuit Contest. Evaluations establish EvolVE as the new state-of-the-art, achieving 98.1% on VerilogEval v2 and 92% on RTLLM v2. Furthermore, on the industry-scale IC-RTL suite, our framework surpasses reference implementations authored by contest participants, reducing the Power, Performance, Area (PPA) product by up to 66% in Huffman Coding and 17% in the geometric mean across all problems. The source code of the IC-RTL benchmark is available at https://github.com/weiber2002/ICRTL.
ResPerfNet: Deep Residual Learning for Regressional Performance Modeling of Deep Neural Networks
Dec 03, 2020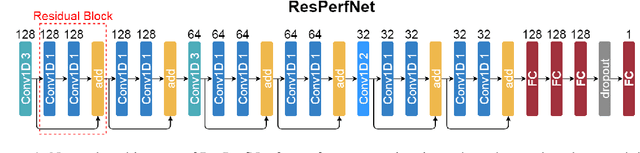

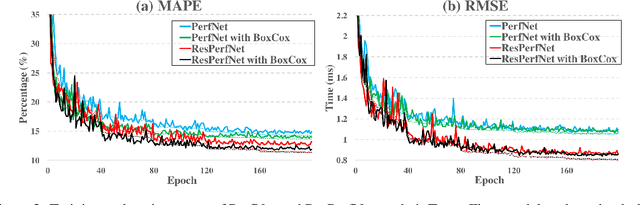

The rapid advancements of computing technology facilitate the development of diverse deep learning applications. Unfortunately, the efficiency of parallel computing infrastructures varies widely with neural network models, which hinders the exploration of the design space to find high-performance neural network architectures on specific computing platforms for a given application. To address such a challenge, we propose a deep learning-based method, ResPerfNet, which trains a residual neural network with representative datasets obtained on the target platform to predict the performance for a deep neural network. Our experimental results show that ResPerfNet can accurately predict the execution time of individual neural network layers and full network models on a variety of platforms. In particular, ResPerfNet achieves 8.4% of mean absolute percentage error for LeNet, AlexNet and VGG16 on the NVIDIA GTX 1080Ti, which is substantially lower than the previously published works.
Toward Accurate Platform-Aware Performance Modeling for Deep Neural Networks
Dec 01, 2020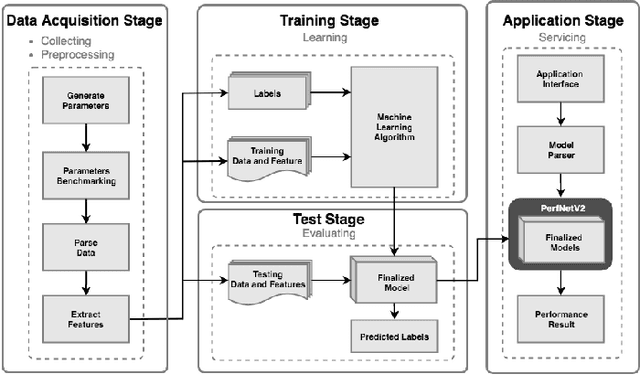
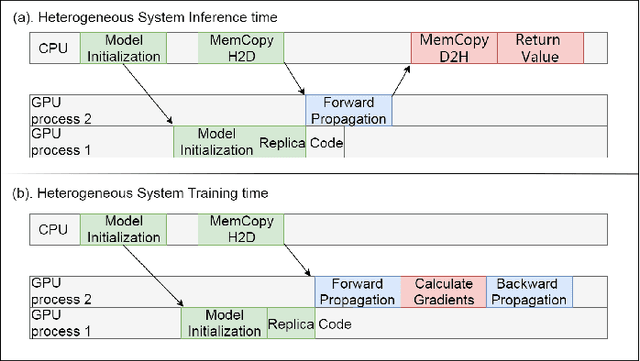
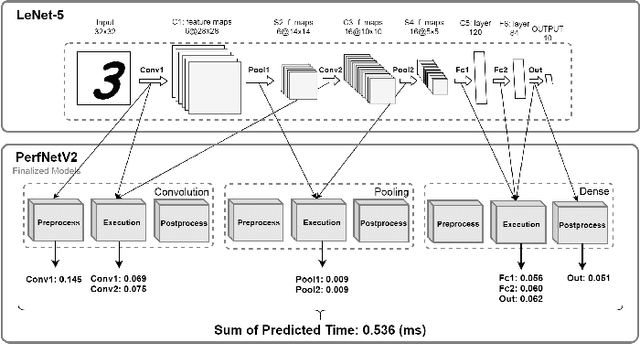
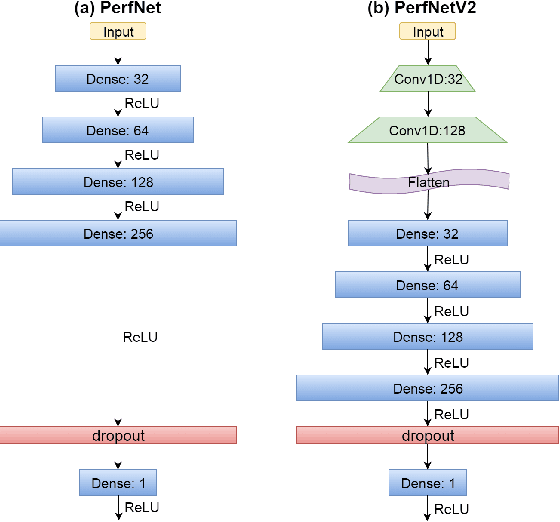
In this paper, we provide a fine-grain machine learning-based method, PerfNetV2, which improves the accuracy of our previous work for modeling the neural network performance on a variety of GPU accelerators. Given an application, the proposed method can be used to predict the inference time and training time of the convolutional neural networks used in the application, which enables the system developer to optimize the performance by choosing the neural networks and/or incorporating the hardware accelerators to deliver satisfactory results in time. Furthermore, the proposed method is capable of predicting the performance of an unseen or non-existing device, e.g. a new GPU which has a higher operating frequency with less processor cores, but more memory capacity. This allows a system developer to quickly search the hardware design space and/or fine-tune the system configuration. Compared to the previous works, PerfNetV2 delivers more accurate results by modeling detailed host-accelerator interactions in executing the full neural networks and improving the architecture of the machine learning model used in the predictor. Our case studies show that PerfNetV2 yields a mean absolute percentage error within 13.1% on LeNet, AlexNet, and VGG16 on NVIDIA GTX-1080Ti, while the error rate on a previous work published in ICBD 2018 could be as large as 200%.