 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration for Nonlinear Processes Using Online Gaussian Process Learning
May 10, 2026This paper proposes a safe data-driven control framework for nonlinear systems with partially known dynamics. The method ensures stability and constraint satisfaction during online learning, assuming only a stabilizable linear approximation of the process is available. Unmodeled nonlinear dynamics are captured by a Gaussian process residual learned in real time. Safety is enforced through a probabilistic control-invariant set derived from Lyapunov theory, guaranteeing high-probability stability. A convex quadratic program computes control inputs that maximize information gain while respecting probabilistic safety constraints. The framework provides finite-sample safety guarantees and allows adaptive expansion of the invariant set as uncertainty decreases. Numerical results validate the approach, demonstrating safe and informative exploration under model uncertainty: the safe set expands by about 30% while the Gaussian process root-mean-square error drops from 1.11 to 0.03.
HyperKKL: Learning KKL Observers for Non-Autonomous Nonlinear Systems via Hypernetwork-Based Input Conditioning
Mar 31, 2026Kazantzis-Kravaris/Luenberger (KKL) observers are a class of state observers for nonlinear systems that rely on an injective map to transform the nonlinear dynamics into a stable quasi-linear latent space, from where the state estimate is obtained in the original coordinates via a left inverse of the transformation map. Current learning-based methods for these maps are designed exclusively for autonomous systems and do not generalize well to controlled or non-autonomous systems. In this paper, we propose two learning-based designs of neural KKL observers for non-autonomous systems whose dynamics are influenced by exogenous inputs. To this end, a hypernetwork-based framework ($HyperKKL$) is proposed with two input-conditioning strategies. First, an augmented observer approach ($HyperKKL_{obs}$) adds input-dependent corrections to the latent observer dynamics while retaining static transformation maps. Second, a dynamic observer approach ($HyperKKL_{dyn}$) employs a hypernetwork to generate encoder and decoder weights that are input-dependent, yielding time-varying transformation maps. We derive a theoretical worst-case bound on the state estimation error. Numerical evaluations on four nonlinear benchmark systems show that input conditioning yields consistent improvements in estimation accuracy over static autonomous maps, with an average symmetric mean absolute percentage error (SMAPE) reduction of 29% across all non-zero input regimes.
From Words to Amino Acids: Does the Curse of Depth Persist?
Feb 25, 2026Protein language models (PLMs) have become widely adopted as general-purpose models, demonstrating strong performance in protein engineering and de novo design. Like large language models (LLMs), they are typically trained as deep transformers with next-token or masked-token prediction objectives on massive sequence corpora and are scaled by increasing model depth. Recent work on autoregressive LLMs has identified the Curse of Depth: later layers contribute little to the final output predictions. These findings naturally raise the question of whether a similar depth inefficiency also appears in PLMs, where many widely used models are not autoregressive, and some are multimodal, accepting both protein sequence and structure as input. In this work, we present a depth analysis of six popular PLMs across model families and scales, spanning three training objectives, namely autoregressive, masked, and diffusion, and quantify how layer contributions evolve with depth using a unified set of probing- and perturbation-based measurements. Across all models, we observe consistent depth-dependent patterns that extend prior findings on LLMs: later layers depend less on earlier computations and mainly refine the final output distribution, and these effects are increasingly pronounced in deeper models. Taken together, our results suggest that PLMs exhibit a form of depth inefficiency, motivating future work on more depth-efficient architectures and training methods.
Are Object-Centric Representations Better At Compositional Generalization?
Feb 18, 2026Compositional generalization, the ability to reason about novel combinations of familiar concepts, is fundamental to human cognition and a critical challenge for machine learning. Object-centric (OC) representations, which encode a scene as a set of objects, are often argued to support such generalization, but systematic evidence in visually rich settings is limited. We introduce a Visual Question Answering benchmark across three controlled visual worlds (CLEVRTex, Super-CLEVR, and MOVi-C) to measure how well vision encoders, with and without object-centric biases, generalize to unseen combinations of object properties. To ensure a fair and comprehensive comparison, we carefully account for training data diversity, sample size, representation size, downstream model capacity, and compute. We use DINOv2 and SigLIP2, two widely used vision encoders, as the foundation models and their OC counterparts. Our key findings reveal that (1) OC approaches are superior in harder compositional generalization settings; (2) original dense representations surpass OC only on easier settings and typically require substantially more downstream compute; and (3) OC models are more sample efficient, achieving stronger generalization with fewer images, whereas dense encoders catch up or surpass them only with sufficient data and diversity. Overall, object-centric representations offer stronger compositional generalization when any one of dataset size, training data diversity, or downstream compute is constrained.
SparScene: Efficient Traffic Scene Representation via Sparse Graph Learning for Large-Scale Trajectory Generation
Dec 24, 2025Multi-agent trajectory generation is a core problem for autonomous driving and intelligent transportation systems. However, efficiently modeling the dynamic interactions between numerous road users and infrastructures in complex scenes remains an open problem. Existing methods typically employ distance-based or fully connected dense graph structures to capture interaction information, which not only introduces a large number of redundant edges but also requires complex and heavily parameterized networks for encoding, thereby resulting in low training and inference efficiency, limiting scalability to large and complex traffic scenes. To overcome the limitations of existing methods, we propose SparScene, a sparse graph learning framework designed for efficient and scalable traffic scene representation. Instead of relying on distance thresholds, SparScene leverages the lane graph topology to construct structure-aware sparse connections between agents and lanes, enabling efficient yet informative scene graph representation. SparScene adopts a lightweight graph encoder that efficiently aggregates agent-map and agent-agent interactions, yielding compact scene representations with substantially improved efficiency and scalability. On the motion prediction benchmark of the Waymo Open Motion Dataset (WOMD), SparScene achieves competitive performance with remarkable efficiency. It generates trajectories for more than 200 agents in a scene within 5 ms and scales to more than 5,000 agents and 17,000 lanes with merely 54 ms of inference time with a GPU memory of 2.9 GB, highlighting its superior scalability for large-scale traffic scenes.
Group Distributionally Robust Machine Learning under Group Level Distributional Uncertainty
Sep 10, 2025



The performance of machine learning (ML) models critically depends on the quality and representativeness of the training data. In applications with multiple heterogeneous data generating sources, standard ML methods often learn spurious correlations that perform well on average but degrade performance for atypical or underrepresented groups. Prior work addresses this issue by optimizing the worst-group performance. However, these approaches typically assume that the underlying data distributions for each group can be accurately estimated using the training data, a condition that is frequently violated in noisy, non-stationary, and evolving environments. In this work, we propose a novel framework that relies on Wasserstein-based distributionally robust optimization (DRO) to account for the distributional uncertainty within each group, while simultaneously preserving the objective of improving the worst-group performance. We develop a gradient descent-ascent algorithm to solve the proposed DRO problem and provide convergence results. Finally, we validate the effectiveness of our method on real-world data.
Closed-Loop Neural Operator-Based Observer of Traffic Density
Apr 07, 2025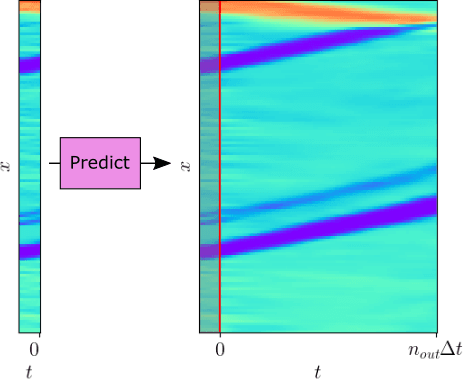
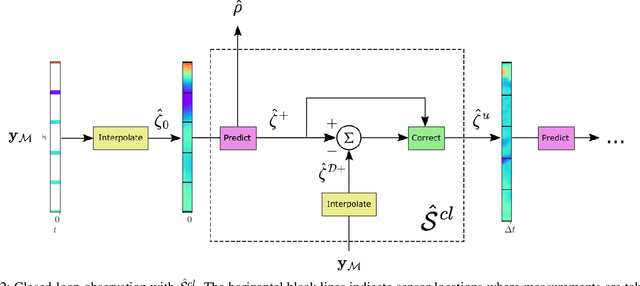
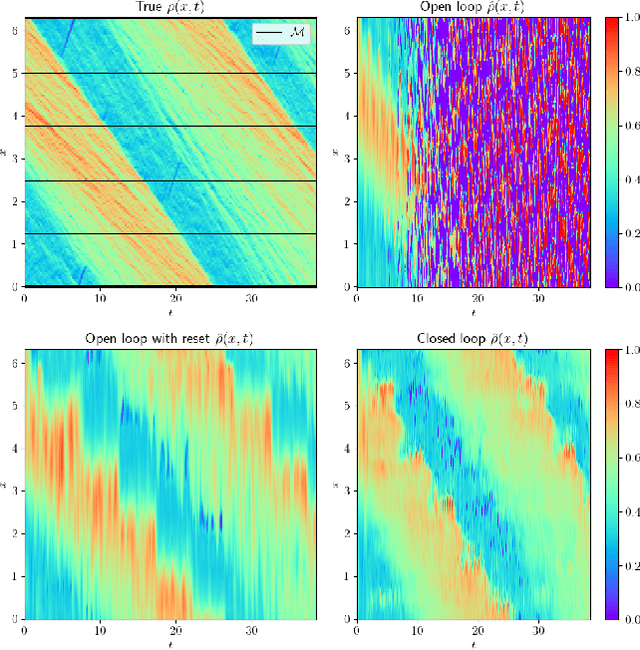
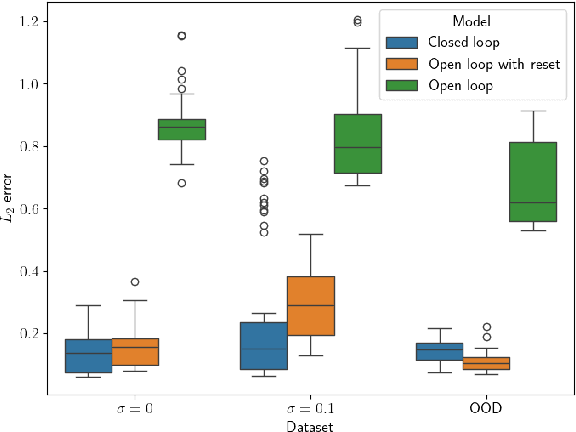
We consider the problem of traffic density estimation with sparse measurements from stationary roadside sensors. Our approach uses Fourier neural operators to learn macroscopic traffic flow dynamics from high-fidelity microscopic-level simulations. During inference, the operator functions as an open-loop predictor of traffic evolution. To close the loop, we couple the open-loop operator with a correction operator that combines the predicted density with sparse measurements from the sensors. Simulations with the SUMO software indicate that, compared to open-loop observers, the proposed closed-loop observer exhibit classical closed-loop properties such as robustness to noise and ultimate boundedness of the error. This shows the advantages of combining learned physics with real-time corrections, and opens avenues for accurate, efficient, and interpretable data-driven observers.
Online Traffic Density Estimation using Physics-Informed Neural Networks
Apr 04, 2025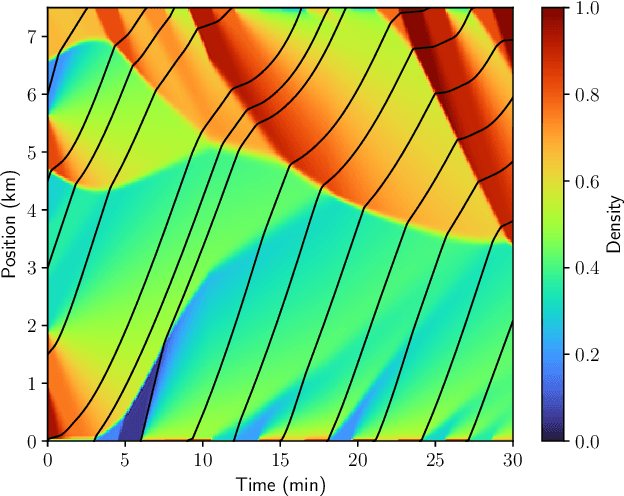



Recent works on the application of Physics-Informed Neural Networks to traffic density estimation have shown to be promising for future developments due to their robustness to model errors and noisy data. In this paper, we introduce a methodology for online approximation of the traffic density using measurements from probe vehicles in two settings: one using the Greenshield model and the other considering a high-fidelity traffic simulation. The proposed method continuously estimates the real-time traffic density in space and performs model identification with each new set of measurements. The density estimate is updated in almost real-time using gradient descent and adaptive weights. In the case of full model knowledge, the resulting algorithm has similar performance to the classical open-loop one. However, in the case of model mismatch, the iterative solution behaves as a closed-loop observer and outperforms the baseline method. Similarly, in the high-fidelity setting, the proposed algorithm correctly reproduces the traffic characteristics.
KKL Observer Synthesis for Nonlinear Systems via Physics-Informed Learning
Jan 20, 2025This paper proposes a novel learning approach for designing Kazantzis-Kravaris/Luenberger (KKL) observers for autonomous nonlinear systems. The design of a KKL observer involves finding an injective map that transforms the system state into a higher-dimensional observer state, whose dynamics is linear and stable. The observer's state is then mapped back to the original system coordinates via the inverse map to obtain the state estimate. However, finding this transformation and its inverse is quite challenging. We propose to sequentially approximate these maps by neural networks that are trained using physics-informed learning. We generate synthetic data for training by numerically solving the system and observer dynamics. Theoretical guarantees for the robustness of state estimation against approximation error and system uncertainties are provided. Additionally, a systematic method for optimizing observer performance through parameter selection is presented. The effectiveness of the proposed approach is demonstrated through numerical simulations on benchmark examples and its application to sensor fault detection and isolation in a network of Kuramoto oscillators using learned KKL observers.
Explainable Reinforcement Learning via Temporal Policy Decomposition
Jan 07, 2025



We investigate the explainability of Reinforcement Learning (RL) policies from a temporal perspective, focusing on the sequence of future outcomes associated with individual actions. In RL, value functions compress information about rewards collected across multiple trajectories and over an infinite horizon, allowing a compact form of knowledge representation. However, this compression obscures the temporal details inherent in sequential decision-making, presenting a key challenge for interpretability. We present Temporal Policy Decomposition (TPD), a novel explainability approach that explains individual RL actions in terms of their Expected Future Outcome (EFO). These explanations decompose generalized value functions into a sequence of EFOs, one for each time step up to a prediction horizon of interest, revealing insights into when specific outcomes are expected to occur. We leverage fixed-horizon temporal difference learning to devise an off-policy method for learning EFOs for both optimal and suboptimal actions, enabling contrastive explanations consisting of EFOs for different state-action pairs. Our experiments demonstrate that TPD generates accurate explanations that (i) clarify the policy's future strategy and anticipated trajectory for a given action and (ii) improve understanding of the reward composition, facilitating fine-tuning of the reward function to align with human expectations.