 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributed Bayesian Online Learning for Cooperative Manipulation
Apr 09, 2021
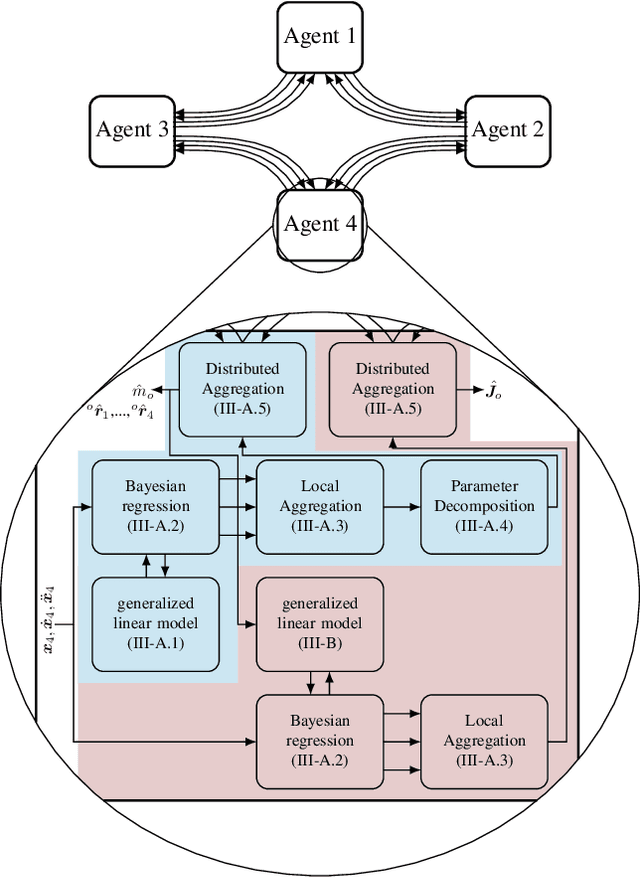
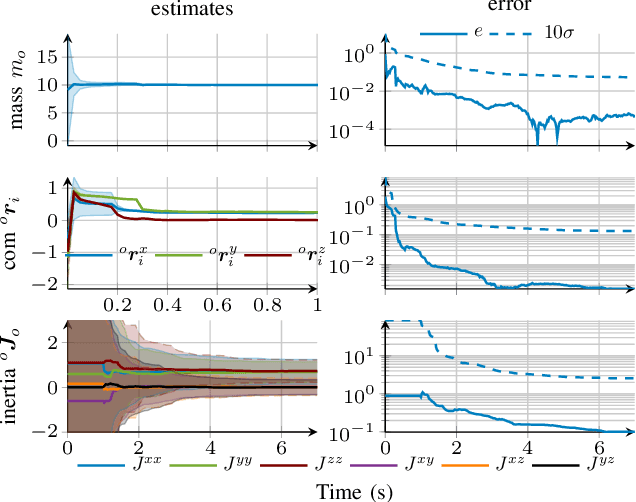
For tasks where the dynamics of multiple agents are physically coupled, e.g., in cooperative manipulation, the coordination between the individual agents becomes crucial, which requires exact knowledge of the interaction dynamics. This problem is typically addressed using centralized estimators, which can negatively impact the flexibility and robustness of the overall system. To overcome this shortcoming, we propose a novel distributed learning framework for the exemplary task of cooperative manipulation using Bayesian principles. Using only local state information each agent obtains an estimate of the object dynamics and grasp kinematics. These local estimates are combined using dynamic average consensus. Due to the strong probabilistic foundation of the method, each estimate of the object dynamics and grasp kinematics is accompanied by a measure of uncertainty, which allows to guarantee a bounded prediction error with high probability. Moreover, the Bayesian principles directly allow iterative learning with constant complexity, such that the proposed learning method can be used online in real-time applications. The effectiveness of the approach is demonstrated in a simulated cooperative manipulation task.
On Robust Optimal Transport: Computational Complexity, Low-rank Approximation, and Barycenter Computation
Feb 13, 2021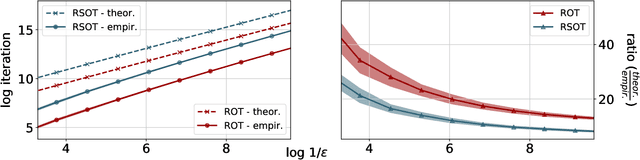
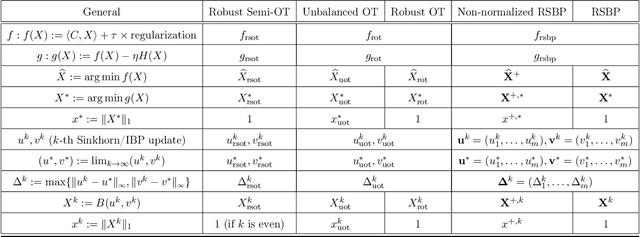
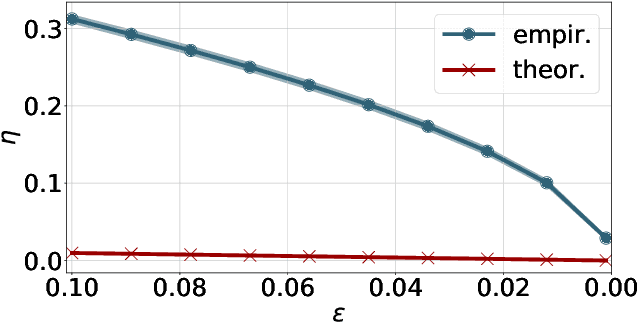
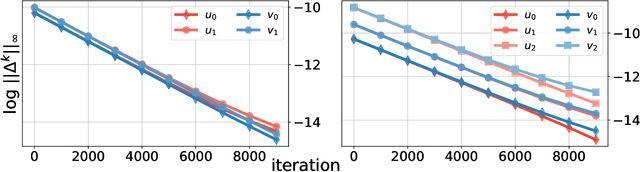
We consider two robust versions of optimal transport, named $\textit{Robust Semi-constrained Optimal Transport}$ (RSOT) and $\textit{Robust Unconstrained Optimal Transport}$ (ROT), formulated by relaxing the marginal constraints with Kullback-Leibler divergence. For both problems in the discrete settings, we propose Sinkhorn-based algorithms that produce $\varepsilon$-approximations of RSOT and ROT in $\widetilde{\mathcal{O}}(\frac{n^2}{\varepsilon})$ time, where $n$ is the number of supports of the probability distributions. Furthermore, to reduce the dependency of the complexity of the Sinkhorn-based algorithms on $n$, we apply Nystr\"{o}m method to approximate the kernel matrix in both RSOT and ROT by a matrix of rank $r$ before passing it to these Sinkhorn-based algorithms. We demonstrate that these new algorithms have $\widetilde{\mathcal{O}}(n r^2 + \frac{nr}{\varepsilon})$ runtime to obtain the RSOT and ROT $\varepsilon$-approximations. Finally, we consider a barycenter problem based on RSOT, named $\textit{Robust Semi-Constrained Barycenter}$ problem (RSBP), and develop a robust iterative Bregman projection algorithm, called $\textbf{Normalized-RobustIBP}$ algorithm, to solve the RSBP in the discrete settings of probability distributions. We show that an $\varepsilon$-approximated solution of the RSBP can be achieved in $\widetilde{\mathcal{O}}(\frac{mn^2}{\varepsilon})$ time using $\textbf{Normalized-RobustIBP}$ algorithm when $m = 2$, which is better than the previous complexity $\widetilde{\mathcal{O}}(\frac{mn^2}{\varepsilon^2})$ of IBP algorithm for approximating the Wasserstein barycenter. Extensive experiments confirm our theoretical results.
LSTM Networks for Data-Aware Remaining Time Prediction of Business Process Instances
Nov 10, 2017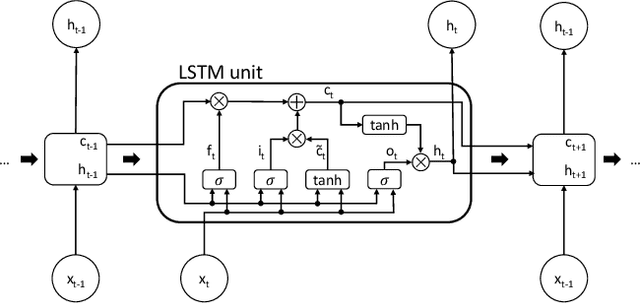
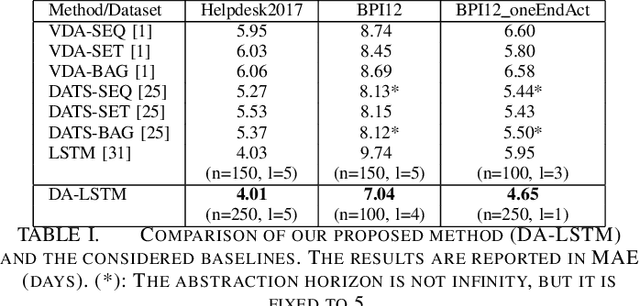
Predicting the completion time of business process instances would be a very helpful aid when managing processes under service level agreement constraints. The ability to know in advance the trend of running process instances would allow business managers to react in time, in order to prevent delays or undesirable situations. However, making such accurate forecasts is not easy: many factors may influence the required time to complete a process instance. In this paper, we propose an approach based on deep Recurrent Neural Networks (specifically LSTMs) that is able to exploit arbitrary information associated to single events, in order to produce an as-accurate-as-possible prediction of the completion time of running instances. Experiments on real-world datasets confirm the quality of our proposal.
Learning Spatio-Temporal Transformer for Visual Tracking
Mar 31, 2021In this paper, we present a new tracking architecture with an encoder-decoder transformer as the key component. The encoder models the global spatio-temporal feature dependencies between target objects and search regions, while the decoder learns a query embedding to predict the spatial positions of the target objects. Our method casts object tracking as a direct bounding box prediction problem, without using any proposals or predefined anchors. With the encoder-decoder transformer, the prediction of objects just uses a simple fully-convolutional network, which estimates the corners of objects directly. The whole method is end-to-end, does not need any postprocessing steps such as cosine window and bounding box smoothing, thus largely simplifying existing tracking pipelines. The proposed tracker achieves state-of-the-art performance on five challenging short-term and long-term benchmarks, while running at real-time speed, being 6x faster than Siam R-CNN. Code and models are open-sourced at https://github.com/researchmm/Stark.
Neural Transformation Learning for Deep Anomaly Detection Beyond Images
Mar 31, 2021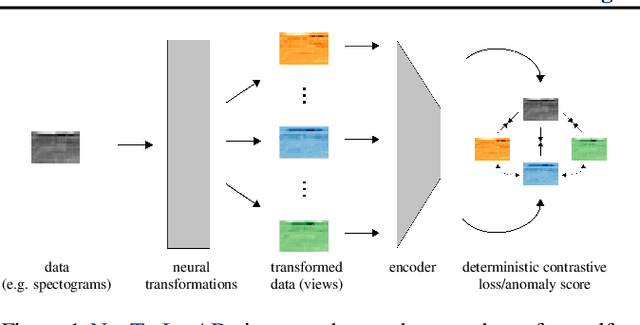

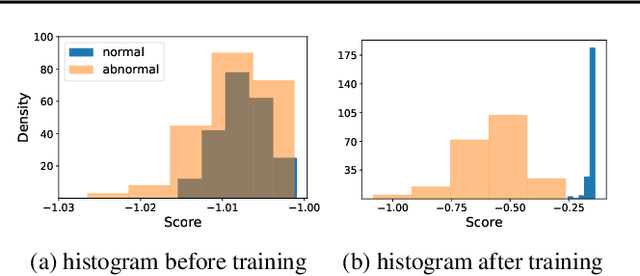
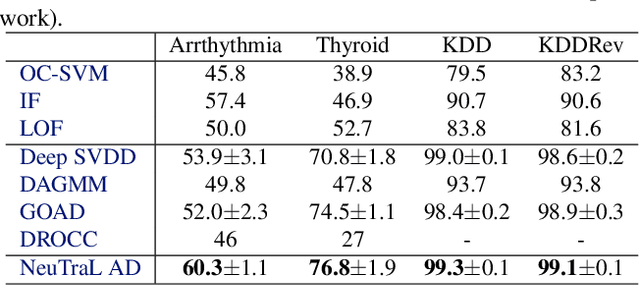
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series demonstrate that we significantly outperform existing methods on the one-vs.-rest setting but also on the more challenging n-vs.-rest anomaly-detection task. On tabular datasets from the medical and cyber-security domains, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
Low-dimensional Denoising Embedding Transformer for ECG Classification
Mar 31, 2021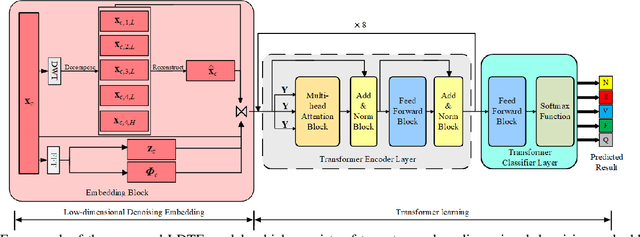

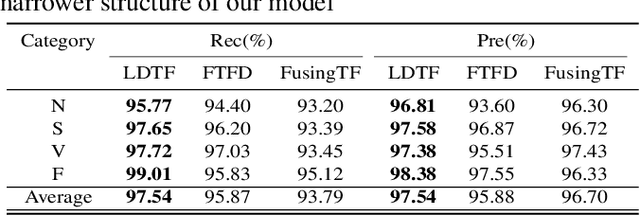
The transformer based model (e.g., FusingTF) has been employed recently for Electrocardiogram (ECG) signal classification. However, the high-dimensional embedding obtained via 1-D convolution and positional encoding can lead to the loss of the signal's own temporal information and a large amount of training parameters. In this paper, we propose a new method for ECG classification, called low-dimensional denoising embedding transformer (LDTF), which contains two components, i.e., low-dimensional denoising embedding (LDE) and transformer learning. In the LDE component, a low-dimensional representation of the signal is obtained in the time-frequency domain while preserving its own temporal information. And with the low dimensional embedding, the transformer learning is then used to obtain a deeper and narrower structure with fewer training parameters than that of the FusingTF. Experiments conducted on the MIT-BIH dataset demonstrates the effectiveness and the superior performance of our proposed method, as compared with state-of-the-art methods.
Cycle-free CycleGAN using Invertible Generator for Unsupervised Low-Dose CT Denoising
Apr 17, 2021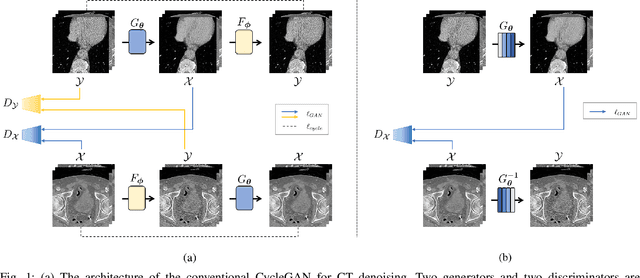
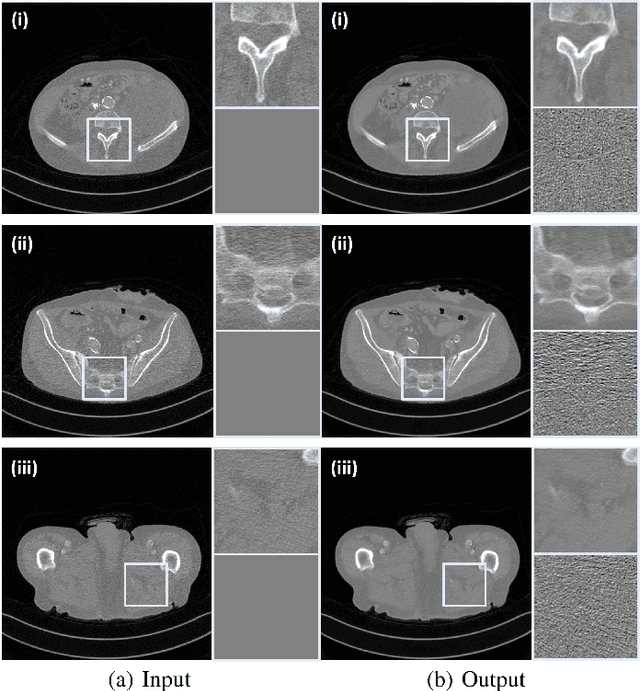
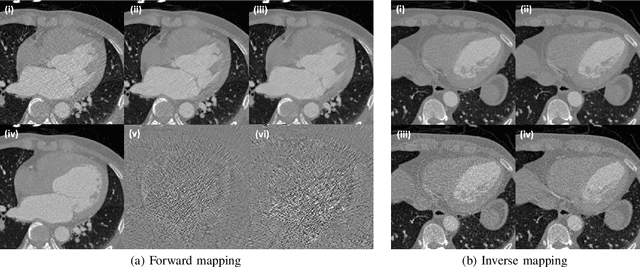
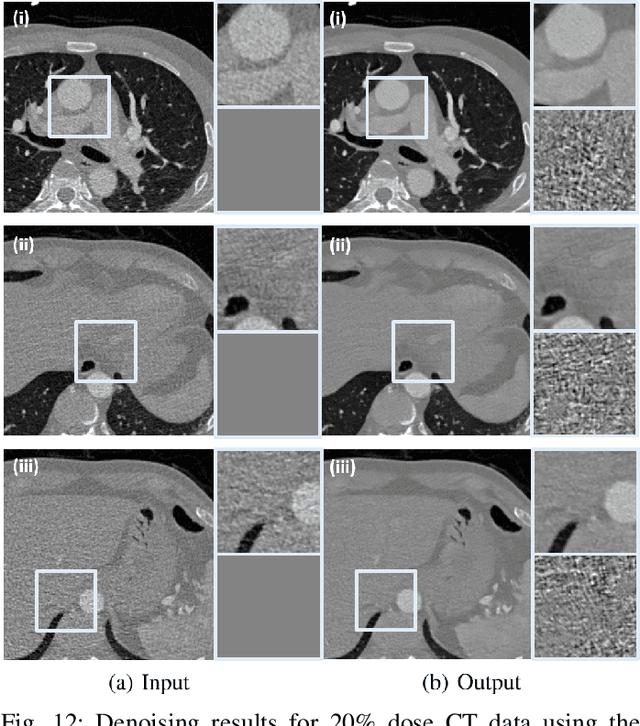
Recently, CycleGAN was shown to provide high-performance, ultra-fast denoising for low-dose X-ray computed tomography (CT) without the need for a paired training dataset. Although this was possible thanks to cycle consistency, CycleGAN requires two generators and two discriminators to enforce cycle consistency, demanding significant GPU resources and technical skills for training. A recent proposal of tunable CycleGAN with Adaptive Instance Normalization (AdaIN) alleviates the problem in part by using a single generator. However, two discriminators and an additional AdaIN code generator are still required for training. To solve this problem, here we present a novel cycle-free Cycle-GAN architecture, which consists of a single generator and a discriminator but still guarantees cycle consistency. The main innovation comes from the observation that the use of an invertible generator automatically fulfills the cycle consistency condition and eliminates the additional discriminator in the CycleGAN formulation. To make the invertible generator more effective, our network is implemented in the wavelet residual domain. Extensive experiments using various levels of low-dose CT images confirm that our method can significantly improve denoising performance using only 10% of learnable parameters and faster training time compared to the conventional CycleGAN.
What is the State of the Art of Computer Vision-Assisted Cytology? A Systematic Literature Review
May 24, 2021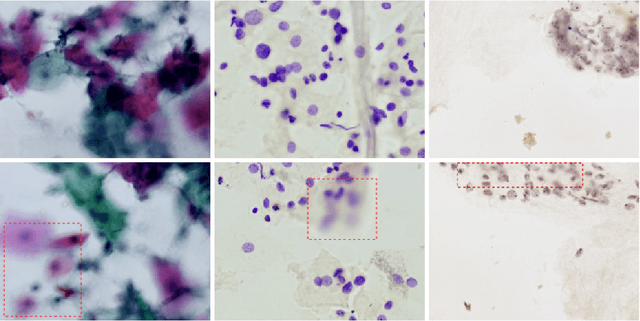

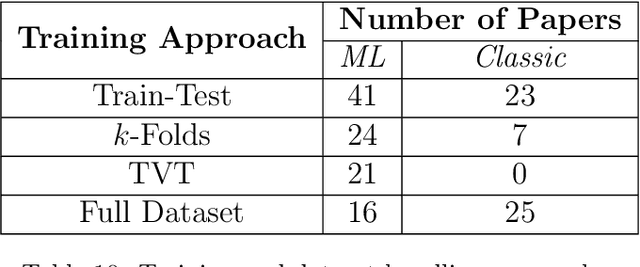

Cytology is a low-cost and non-invasive diagnostic procedure employed to support the diagnosis of a broad range of pathologies. Computer Vision technologies, by automatically generating quantitative and objective descriptions of examinations' contents, can help minimize the chances of misdiagnoses and shorten the time required for analysis. To identify the state-of-art of computer vision techniques currently applied to cytology, we conducted a Systematic Literature Review. We analyzed papers published in the last 5 years. The initial search was executed in September 2020 and resulted in 431 articles. After applying the inclusion/exclusion criteria, 157 papers remained, which we analyzed to build a picture of the tendencies and problems present in this research area, highlighting the computer vision methods, staining techniques, evaluation metrics, and the availability of the used datasets and computer code. As a result, we identified that the most used methods in the analyzed works are deep learning-based (70 papers), while fewer works employ classic computer vision only (101 papers). The most recurrent metric used for classification and object detection was the accuracy (33 papers and 5 papers), while for segmentation it was the Dice Similarity Coefficient (38 papers). Regarding staining techniques, Papanicolaou was the most employed one (130 papers), followed by H&E (20 papers) and Feulgen (5 papers). Twelve of the datasets used in the papers are publicly available, with the DTU/Herlev dataset being the most used one. We conclude that there still is a lack of high-quality datasets for many types of stains and most of the works are not mature enough to be applied in a daily clinical diagnostic routine. We also identified a growing tendency towards adopting deep learning-based approaches as the methods of choice.
Audio Transformers:Transformer Architectures For Large Scale Audio Understanding. Adieu Convolutions
May 01, 2021
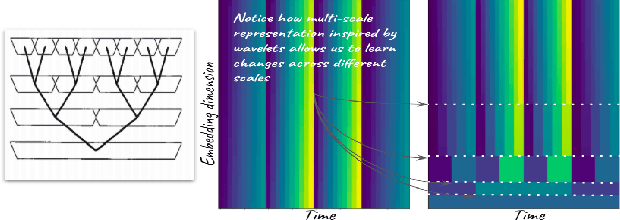
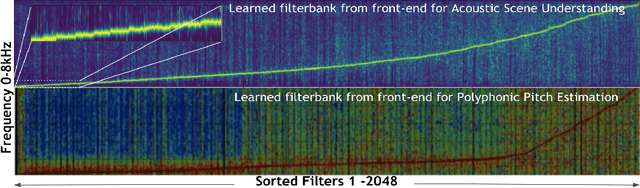
Over the past two decades, CNN architectures have produced compelling models of sound perception and cognition, learning hierarchical organizations of features. Analogous to successes in computer vision, audio feature classification can be optimized for a particular task of interest, over a wide variety of datasets and labels. In fact similar architectures designed for image understanding have proven effective for acoustic scene analysis. Here we propose applying Transformer based architectures without convolutional layers to raw audio signals. On a standard dataset of Free Sound 50K,comprising of 200 categories, our model outperforms convolutional models to produce state of the art results. This is significant as unlike in natural language processing and computer vision, we do not perform unsupervised pre-training for outperforming convolutional architectures. On the same training set, with respect mean aver-age precision benchmarks, we show a significant improvement. We further improve the performance of Transformer architectures by using techniques such as pooling inspired from convolutional net-work designed in the past few years. In addition, we also show how multi-rate signal processing ideas inspired from wavelets, can be applied to the Transformer embeddings to improve the results. We also show how our models learns a non-linear non constant band-width filter-bank, which shows an adaptable time frequency front end representation for the task of audio understanding, different from other tasks e.g. pitch estimation.
Learning to Persuade on the Fly: Robustness Against Ignorance
Feb 19, 2021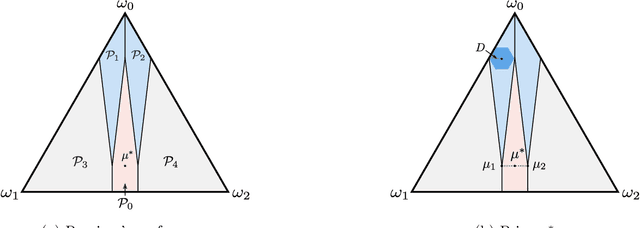

We study a repeated persuasion setting between a sender and a receiver, where at each time $t$, the sender observes a payoff-relevant state drawn independently and identically from an unknown prior distribution, and shares state information with the receiver, who then myopically chooses an action. As in the standard setting, the sender seeks to persuade the receiver into choosing actions that are aligned with the sender's preference by selectively sharing information about the state. However, in contrast to the standard models, the sender does not know the prior, and has to persuade while gradually learning the prior on the fly. We study the sender's learning problem of making persuasive action recommendations to achieve low regret against the optimal persuasion mechanism with the knowledge of the prior distribution. Our main positive result is an algorithm that, with high probability, is persuasive across all rounds and achieves $O(\sqrt{T\log T})$ regret, where $T$ is the horizon length. The core philosophy behind the design of our algorithm is to leverage robustness against the sender's ignorance of the prior. Intuitively, at each time our algorithm maintains a set of candidate priors, and chooses a persuasion scheme that is simultaneously persuasive for all of them. To demonstrate the effectiveness of our algorithm, we further prove that no algorithm can achieve regret better than $\Omega(\sqrt{T})$, even if the persuasiveness requirements were significantly relaxed. Therefore, our algorithm achieves optimal regret for the sender's learning problem up to terms logarithmic in $T$.