 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Imagining The Road Ahead: Multi-Agent Trajectory Prediction via Differentiable Simulation
Apr 22, 2021
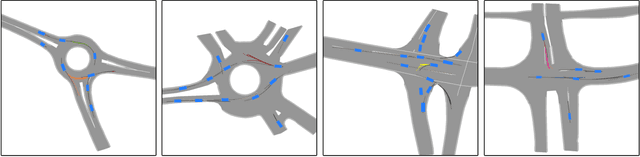
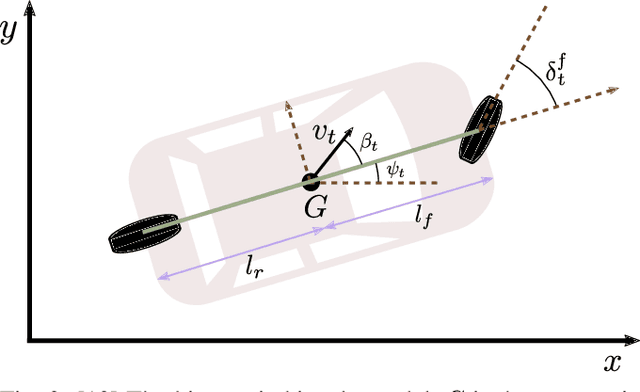
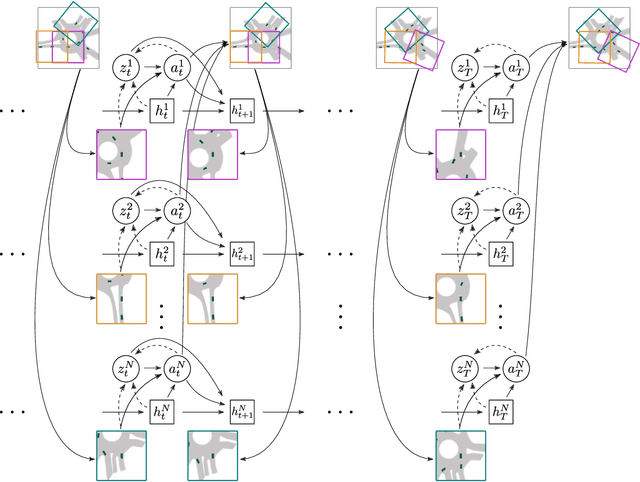
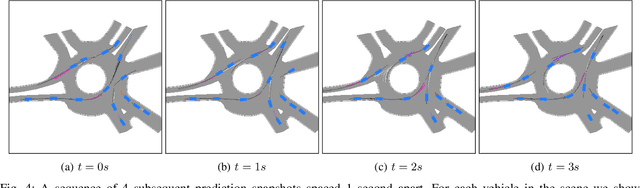
We develop a deep generative model built on a fully differentiable simulator for multi-agent trajectory prediction. Agents are modeled with conditional recurrent variational neural networks (CVRNNs), which take as input an ego-centric birdview image representing the current state of the world and output an action, consisting of steering and acceleration, which is used to derive the subsequent agent state using a kinematic bicycle model. The full simulation state is then differentiably rendered for each agent, initiating the next time step. We achieve state-of-the-art results on the INTERACTION dataset, using standard neural architectures and a standard variational training objective, producing realistic multi-modal predictions without any ad-hoc diversity-inducing losses. We conduct ablation studies to examine individual components of the simulator, finding that both the kinematic bicycle model and the continuous feedback from the birdview image are crucial for achieving this level of performance. We name our model ITRA, for "Imagining the Road Ahead".
Designing for human-AI complementarity in K-12 education
Apr 02, 2021
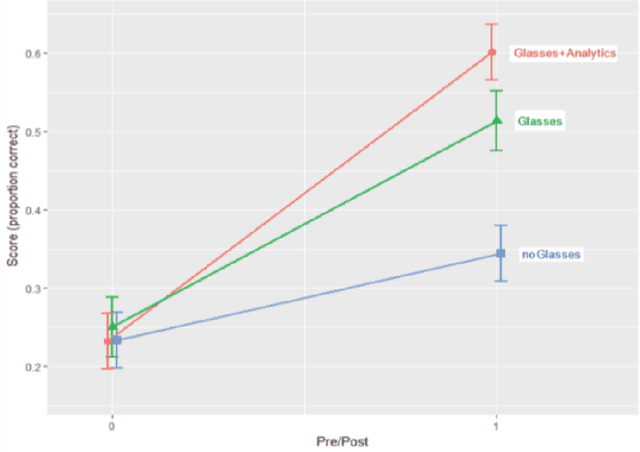
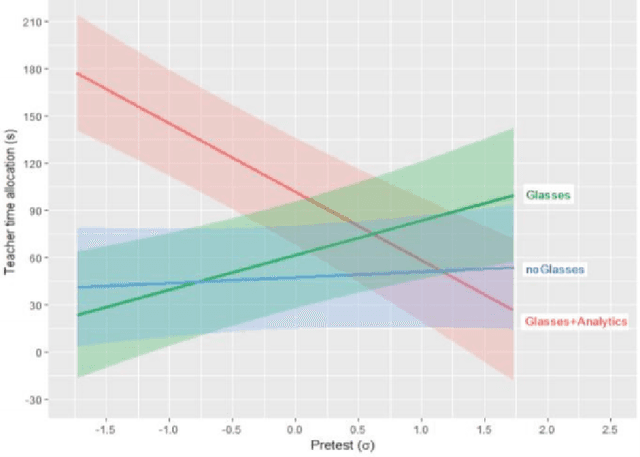
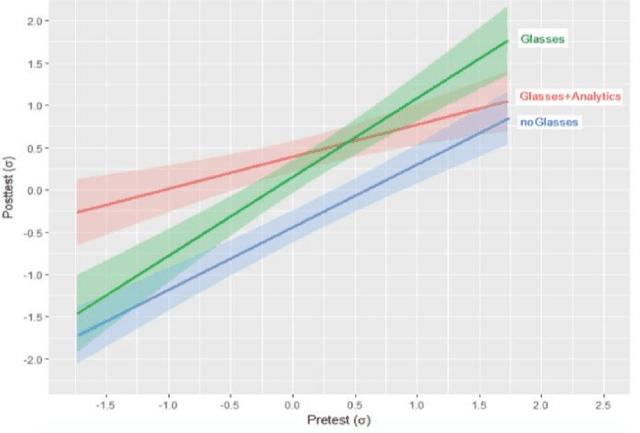
Recent work has explored how complementary strengths of humans and artificial intelligence (AI) systems might be productively combined. However, successful forms of human-AI partnership have rarely been demonstrated in real-world settings. We present the iterative design and evaluation of Lumilo, smart glasses that help teachers help their students in AI-supported classrooms by presenting real-time analytics about students' learning, metacognition, and behavior. Results from a field study conducted in K-12 classrooms indicate that students learn more when teachers and AI tutors work together during class. We discuss implications for the design of human-AI partnerships, arguing for participatory approaches to research in this area, and for principled approaches to studying human-AI decision-making in real-world contexts.
Neural Temporal Point Processes: A Review
Apr 08, 2021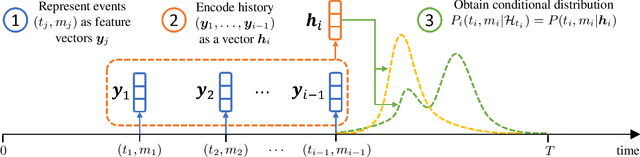
Temporal point processes (TPP) are probabilistic generative models for continuous-time event sequences. Neural TPPs combine the fundamental ideas from point process literature with deep learning approaches, thus enabling construction of flexible and efficient models. The topic of neural TPPs has attracted significant attention in the recent years, leading to the development of numerous new architectures and applications for this class of models. In this review paper we aim to consolidate the existing body of knowledge on neural TPPs. Specifically, we focus on important design choices and general principles for defining neural TPP models. Next, we provide an overview of application areas commonly considered in the literature. We conclude this survey with the list of open challenges and important directions for future work in the field of neural TPPs.
AdvantageNAS: Efficient Neural Architecture Search with Credit Assignment
Dec 11, 2020



Neural architecture search (NAS) is an approach for automatically designing a neural network architecture without human effort or expert knowledge. However, the high computational cost of NAS limits its use in commercial applications. Two recent NAS paradigms, namely one-shot and sparse propagation, which reduce the time and space complexities, respectively, provide clues for solving this problem. In this paper, we propose a novel search strategy for one-shot and sparse propagation NAS, namely AdvantageNAS, which further reduces the time complexity of NAS by reducing the number of search iterations. AdvantageNAS is a gradient-based approach that improves the search efficiency by introducing credit assignment in gradient estimation for architecture updates. Experiments on the NAS-Bench-201 and PTB dataset show that AdvantageNAS discovers an architecture with higher performance under a limited time budget compared to existing sparse propagation NAS. To further reveal the reliabilities of AdvantageNAS, we investigate it theoretically and find that it monotonically improves the expected loss and thus converges.
Traversing Steep and Granular Martian Analog Slopes With a Dynamic Quadrupedal Robot
Jun 03, 2021
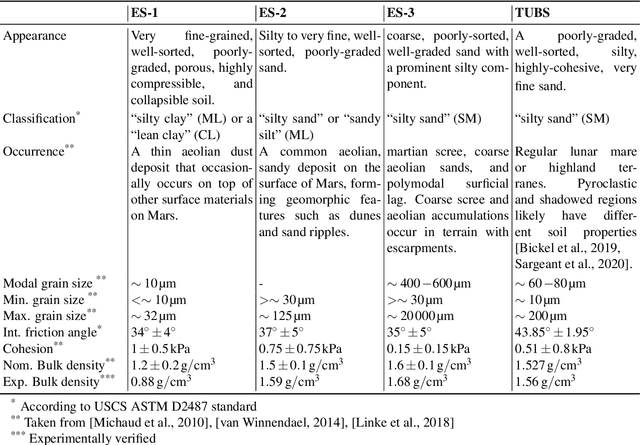
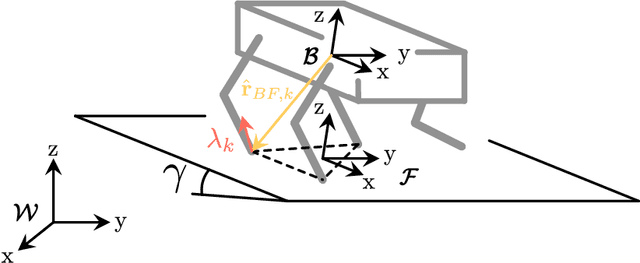
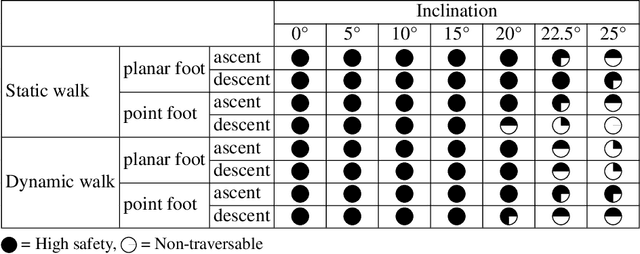
Celestial bodies such as the Moon and Mars are mainly covered by loose, granular soil, a notoriously challenging terrain to traverse with (wheeled) robotic systems. Here, we present experimental work on traversing steep, granular slopes with the dynamically walking quadrupedal robot SpaceBok. To adapt to the challenging environment, we developed passive-adaptive planar feet and optimized grouser pads to reduce sinkage and increase traction on planar and inclined granular soil. Single-foot experiments revealed that a large surface area of 110cm2 per foot reduces sinkage to an acceptable level even on highly collapsible soil (ES-1). Implementing several 12mm grouser blades increases traction by 22% to 66% on granular media compared to grouser-less designs. Together with a terrain-adapting walking controller, we validate - for the first time - static and dynamic locomotion on Mars analog slopes of up to 25{\deg}(the maximum of the testbed). We evaluated the performance between point- and planar feet and static and dynamic gaits regarding stability (safety), velocity, and energy consumption. We show that dynamic gaits are energetically more efficient than static gaits but are riskier on steep slopes. Our tests also revealed that planar feet's energy consumption drastically increases when the slope inclination approaches the soil's angle of internal friction due to shearing. Point feet are less affected by slippage due to their excessive sinkage, but in turn, are prone to instabilities and tripping. We present and discuss safe and energy-efficient global path-planning strategies for accessing steep topography on Mars based on our findings.
An Imprecise Probabilistic Estimator for the Transition Rate Matrix of a Continuous-Time Markov Chain
Jul 11, 2018We consider the problem of estimating the transition rate matrix of a continuous-time Markov chain from a finite-duration realisation of this process. We approach this problem in an imprecise probabilistic framework, using a set of prior distributions on the unknown transition rate matrix. The resulting estimator is a set of transition rate matrices that, for reasons of conjugacy, is easy to find. To determine the hyperparameters for our set of priors, we reconsider the problem in discrete time, where we can use the well-known Imprecise Dirichlet Model. In particular, we show how the limit of the resulting discrete-time estimators is a continuous-time estimator. It corresponds to a specific choice of hyperparameters and has an exceptionally simple closed-form expression.
A Convolutional Neural Network based Cascade Reconstruction for the IceCube Neutrino Observatory
Jan 27, 2021Continued improvements on existing reconstruction methods are vital to the success of high-energy physics experiments, such as the IceCube Neutrino Observatory. In IceCube, further challenges arise as the detector is situated at the geographic South Pole where computational resources are limited. However, to perform real-time analyses and to issue alerts to telescopes around the world, powerful and fast reconstruction methods are desired. Deep neural networks can be extremely powerful, and their usage is computationally inexpensive once the networks are trained. These characteristics make a deep learning-based approach an excellent candidate for the application in IceCube. A reconstruction method based on convolutional architectures and hexagonally shaped kernels is presented. The presented method is robust towards systematic uncertainties in the simulation and has been tested on experimental data. In comparison to standard reconstruction methods in IceCube, it can improve upon the reconstruction accuracy, while reducing the time necessary to run the reconstruction by two to three orders of magnitude.
baller2vec: A Multi-Entity Transformer For Multi-Agent Spatiotemporal Modeling
Feb 05, 2021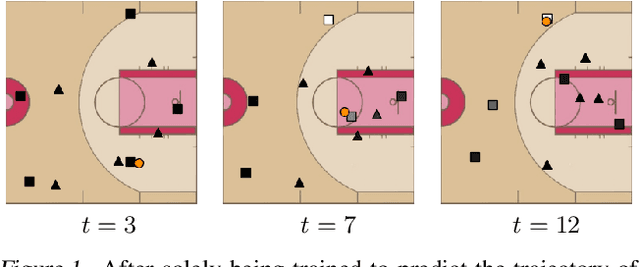
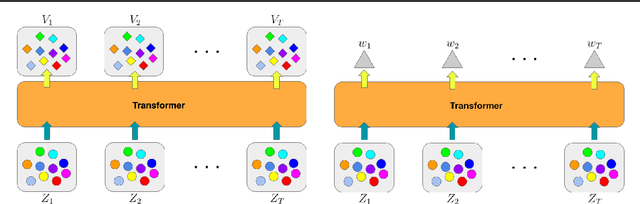
Multi-agent spatiotemporal modeling is a challenging task from both an algorithmic design and computational complexity perspective. Recent work has explored the efficacy of traditional deep sequential models in this domain, but these architectures are slow and cumbersome to train, particularly as model size increases. Further, prior attempts to model interactions between agents across time have limitations, such as imposing an order on the agents, or making assumptions about their relationships. In this paper, we introduce baller2vec, a multi-entity generalization of the standard Transformer that, with minimal assumptions, can simultaneously and efficiently integrate information across entities and time. We test the effectiveness of baller2vec for multi-agent spatiotemporal modeling by training it to perform two different basketball-related tasks: (1) simultaneously forecasting the trajectories of all players on the court and (2) forecasting the trajectory of the ball. Not only does baller2vec learn to perform these tasks well, it also appears to "understand" the game of basketball, encoding idiosyncratic qualities of players in its embeddings, and performing basketball-relevant functions with its attention heads.
Grey-box Adversarial Attack And Defence For Sentiment Classification
Mar 22, 2021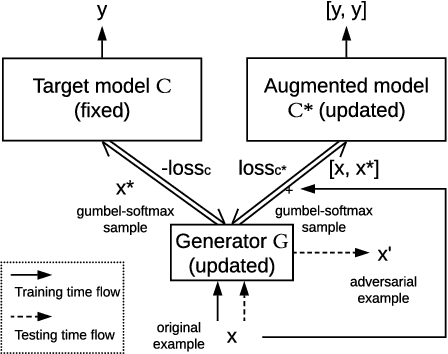
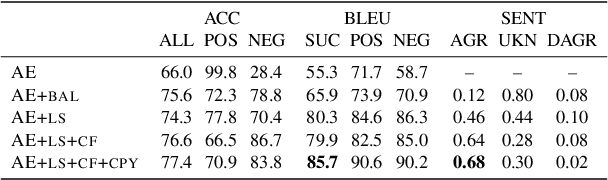
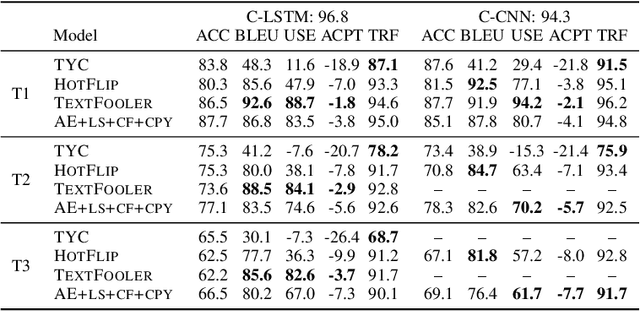
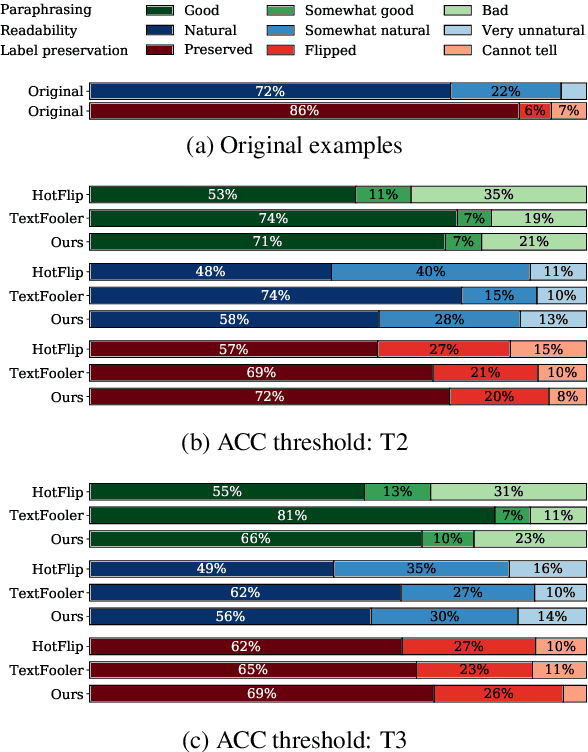
We introduce a grey-box adversarial attack and defence framework for sentiment classification. We address the issues of differentiability, label preservation and input reconstruction for adversarial attack and defence in one unified framework. Our results show that once trained, the attacking model is capable of generating high-quality adversarial examples substantially faster (one order of magnitude less in time) than state-of-the-art attacking methods. These examples also preserve the original sentiment according to human evaluation. Additionally, our framework produces an improved classifier that is robust in defending against multiple adversarial attacking methods. Code is available at: https://github.com/ibm-aur-nlp/adv-def-text-dist.
Changing Model Behavior at Test-Time Using Reinforcement Learning
Feb 24, 2017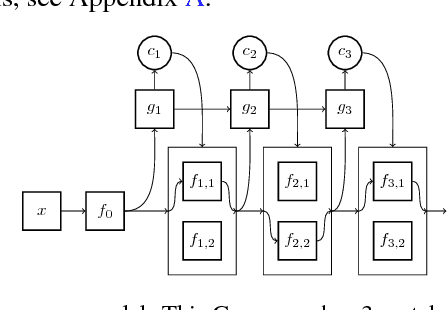
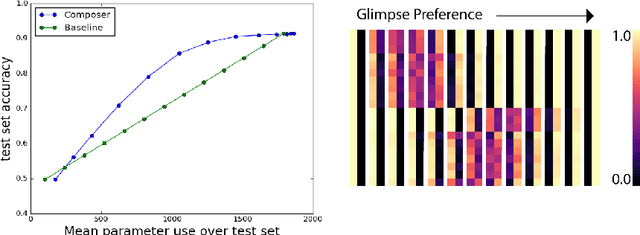

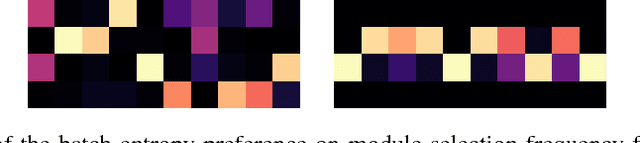
Machine learning models are often used at test-time subject to constraints and trade-offs not present at training-time. For example, a computer vision model operating on an embedded device may need to perform real-time inference, or a translation model operating on a cell phone may wish to bound its average compute time in order to be power-efficient. In this work we describe a mixture-of-experts model and show how to change its test-time resource-usage on a per-input basis using reinforcement learning. We test our method on a small MNIST-based example.