 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Neural Network based Cascade Reconstruction for the IceCube Neutrino Observatory
Jan 27, 2021Continued improvements on existing reconstruction methods are vital to the success of high-energy physics experiments, such as the IceCube Neutrino Observatory. In IceCube, further challenges arise as the detector is situated at the geographic South Pole where computational resources are limited. However, to perform real-time analyses and to issue alerts to telescopes around the world, powerful and fast reconstruction methods are desired. Deep neural networks can be extremely powerful, and their usage is computationally inexpensive once the networks are trained. These characteristics make a deep learning-based approach an excellent candidate for the application in IceCube. A reconstruction method based on convolutional architectures and hexagonally shaped kernels is presented. The presented method is robust towards systematic uncertainties in the simulation and has been tested on experimental data. In comparison to standard reconstruction methods in IceCube, it can improve upon the reconstruction accuracy, while reducing the time necessary to run the reconstruction by two to three orders of magnitude.
Forget Me Not: Reducing Catastrophic Forgetting for Domain Adaptation in Reading Comprehension
Nov 01, 2019
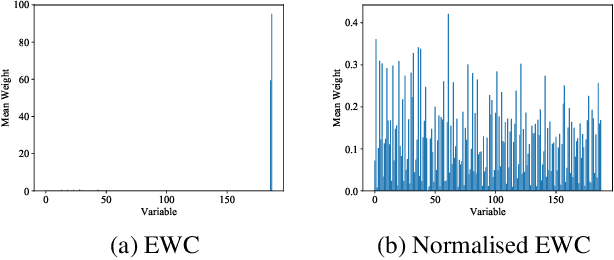
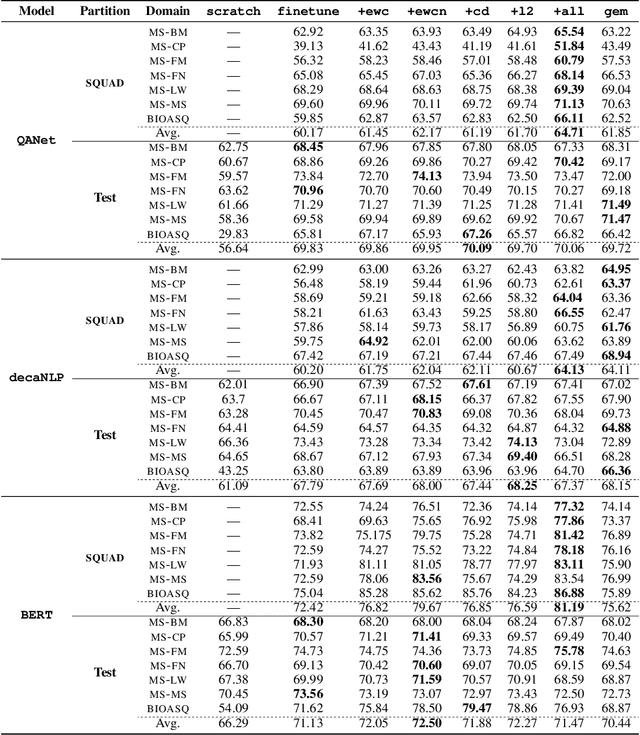
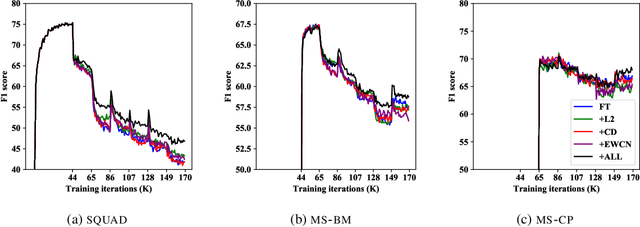
The creation of large-scale open domain reading comprehension data sets in recent years has enabled the development of end-to-end neural comprehension models with promising results. To use these models for domains with limited training data, one of the most effective approach is to first pretrain them on large out-of-domain source data and then fine-tune them with the limited target data. The caveat of this is that after fine-tuning the comprehension models tend to perform poorly in the source domain, a phenomenon known as catastrophic forgetting. In this paper, we explore methods that overcome catastrophic forgetting during fine-tuning without assuming access to data from the source domain. We introduce new auxiliary penalty terms and observe the best performance when a combination of auxiliary penalty terms is used to regularise the fine-tuning process for adapting comprehension models. To test our methods, we develop and release 6 narrow domain data sets that could potentially be used as reading comprehension benchmarks.